Wprowadzenie do MapReduce w Big Data
MapReduce to efektywny, przyspieszony i oszczędny sposób na tworzenie aplikacji.
Ten model wykorzystuje zaawansowane mechanizmy, takie jak przetwarzanie współbieżne i lokalizacja danych, przynosząc szereg korzyści programistom i przedsiębiorstwom.
Jednakże, przy tak wielu dostępnych modelach i platformach programistycznych, wybór odpowiedniego rozwiązania bywa skomplikowany.
W kontekście Big Data, decyzja nie może być przypadkowa. Trzeba wybrać technologie, które sprostają analizie ogromnych zbiorów danych.
MapReduce stanowi tutaj doskonałą odpowiedź.
W tym opracowaniu przybliżę, czym w istocie jest MapReduce i jakie korzyści może on przynieść.
Zacznijmy!
Czym jest MapReduce?
MapReduce to paradygmat programowania, a zarazem struktura oprogramowania, będąca częścią platformy Apache Hadoop. Umożliwia on tworzenie aplikacji zdolnych do równoległego przetwarzania gigantycznych ilości danych na tysiącach węzłów (tworzących klastry lub siatki), z zachowaniem odporności na błędy i wysokiej niezawodności.
Przetwarzanie danych odbywa się w miejscu ich przechowywania, czyli w bazie danych lub systemie plików. MapReduce może współpracować z systemem plików Hadoop (HDFS), aby uzyskać dostęp i zarządzać dużymi zasobami danych.
Framework ten został zapoczątkowany w 2004 roku przez Google, a następnie spopularyzowany przez Apache Hadoop. Stanowi warstwę przetwarzania, czyli silnik Hadoop, w którym działają programy MapReduce tworzone w różnych językach, takich jak Java, C++, Python i Ruby.
Programy MapReduce, pracujące w chmurze obliczeniowej, działają równolegle, co czyni je idealnymi do analizy danych na dużą skalę.
Celem MapReduce jest rozbicie zadania na mniejsze, równoległe podzadania, przy wykorzystaniu funkcji "mapuj" i "redukuj". Każde zadanie jest mapowane, a następnie redukowane do zestawu równoważnych zadań, co pozwala na zmniejszenie obciążenia obliczeniowego i sieciowego w obrębie klastra.
Przykład: Wyobraźmy sobie przygotowywanie posiłku dla sporej grupy gości. Próba samodzielnego przygotowania wszystkich dań i wykonania wszystkich procesów byłaby chaotyczna i czasochłonna.
Zaangażowanie kilku znajomych lub współpracowników (nie gości), którzy pomogą w przygotowaniu posiłku, przydzielając poszczególne procesy do różnych osób, które mogą pracować jednocześnie, zdecydowanie przyspieszy i ułatwi cały proces, pozwalając na podanie posiłku na czas.
MapReduce działa na podobnej zasadzie, wykorzystując rozproszone zadania i przetwarzanie równoległe, aby zapewnić szybszy i prostszy sposób realizacji zadań.
Apache Hadoop pozwala programistom wykorzystać MapReduce do wykonywania modeli na dużych, rozproszonych zbiorach danych, stosując zaawansowane techniki uczenia maszynowego i statystyczne, w celu identyfikacji wzorców, prognozowania, korelacji i nie tylko.
Funkcje MapReduce
Kluczowe funkcje MapReduce obejmują:
- Interfejs użytkownika: Zapewnia intuicyjny interfejs, prezentujący szczegółowe informacje o każdym aspekcie frameworka. Ułatwia to konfigurację, implementację i dostrajanie zadań.

- Ładunek: Aplikacje wykorzystują interfejsy Mapper i Reducer, umożliwiające realizację funkcji mapowania i redukcji. Mapper przetwarza wejściowe pary klucz-wartość, przekształcając je w pośrednie pary klucz-wartość. Reduktor redukuje pośrednie pary klucz-wartość, posiadające wspólny klucz, na mniejsze wartości. Funkcja reduktora składa się z trzech etapów: sortowania, tasowania i redukcji.
- Partitioner: Zarządza podziałem pośrednich kluczy wyjściowych z etapu mapowania.
- Reporter: Funkcja służąca do raportowania postępów, aktualizacji liczników i ustawiania komunikatów statusu.
- Liczniki: Reprezentują globalne liczniki zdefiniowane w aplikacji MapReduce.
- OutputCollector: Funkcja zbierająca dane wyjściowe z Mapper lub Reducer, zamiast danych pośrednich.
- RecordWriter: Zapisuje dane wyjściowe, czyli pary klucz-wartość, do pliku wynikowego.
- DistributedCache: Efektywnie dystrybuuje większe pliki tylko do odczytu, specyficzne dla danej aplikacji.
- Kompresja danych: Programista może kompresować zarówno dane wyjściowe zadań, jak i pośrednie dane wyjściowe z etapu mapowania.
- Pomijanie uszkodzonych rekordów: Umożliwia pominięcie uszkodzonych rekordów podczas przetwarzania danych wejściowych. Ta funkcjonalność jest kontrolowana przez klasę SkipBadRecords.
- Debugowanie: Oferuje możliwość uruchamiania skryptów zdefiniowanych przez użytkownika i włączania debugowania. W przypadku niepowodzenia zadania MapReduce, można uruchomić skrypt debugowania w celu znalezienia przyczyny problemu.
Architektura MapReduce
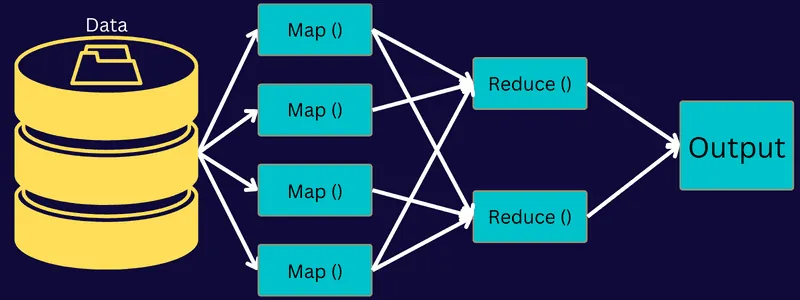
Przyjrzyjmy się architekturze MapReduce, analizując jej komponenty:
- Zadanie: W MapReduce zadaniem jest właściwe polecenie, które klient MapReduce chce wykonać. Składa się z szeregu mniejszych zadań, które po połączeniu dają zadanie końcowe.
- Serwer historii zadań: Jest to proces demona, przechowujący całą historię aplikacji lub zadań, w tym logi generowane przed i po wykonaniu zadania.
- Klient: Klient (program lub interfejs API) przekazuje zadanie do MapReduce w celu wykonania. W systemie MapReduce jeden lub wielu klientów może na bieżąco przesyłać zadania do menedżera MapReduce w celu przetworzenia.
- MapReduce Master: Menedżer MapReduce dzieli zadanie na szereg mniejszych części, zapewniając równoległe wykonanie zadań.
- Części zadania: Podzadania lub części zadania powstają w wyniku podziału zadania podstawowego. Są one przetwarzane, a następnie łączone, tworząc finalne zadanie.
- Dane wejściowe: Zbiór danych przekazywany do MapReduce w celu przetworzenia zadań.
- Dane wyjściowe: Końcowy rezultat uzyskany po przetworzeniu zadania.
Istotą działania architektury jest przesłanie zadania przez klienta do MapReduce Master, który dzieli je na mniejsze, równorzędne części. Umożliwia to przyspieszenie przetwarzania, ponieważ mniejsze zadania zajmują mniej czasu niż zadanie jako całość.
Należy jednak unikać nadmiernego dzielenia zadania na zbyt małe części, ponieważ w takim przypadku obciążenie związane z zarządzaniem podziałami może okazać się zbyt duże, marnując cenny czas.
Następnie mniejsze części zadania są przekazywane do etapów Map i Reduce. Etapy te realizują program oparty na konkretnym przypadku użycia, nad którym pracuje zespół. Programista tworzy kod na bazie logiki, mającej na celu realizację określonych wymagań.
Dane wejściowe trafiają do etapu mapowania, gdzie na ich podstawie generowane są pary klucz-wartość. Dane te są tymczasowo przechowywane na dysku lokalnym, aby uniknąć replikacji, zamiast umieszczać je w HDFS.
Po zakończeniu etapu mapowania dane wyjściowe mogą być usunięte. Zapisywanie ich do HDFS i tworzenie replik nie byłoby w tym przypadku efektywne. Wyjście każdego zadania mapowania jest przekazywane do zadania redukcji na maszynie, na której to zadanie jest uruchomione.
Następnie dane wyjściowe są łączone i przekazywane do funkcji redukcji zdefiniowanej przez użytkownika. Na koniec przetworzone dane są zapisywane do HDFS.
W procesie może być wykonywanych wiele zadań mapowania i redukcji, w zależności od końcowego celu. Algorytmy mapowania i redukcji są optymalizowane pod kątem minimalnej złożoności czasowej i przestrzennej.
Ponieważ MapReduce opiera się głównie na zadaniach mapowania i redukcji, kluczowe jest, aby dowiedzieć się o nich więcej. Przeanalizujmy zatem fazy MapReduce, aby lepiej zrozumieć te zagadnienia.
Fazy MapReduce
Mapowanie
W tej fazie dane wejściowe są przekształcane na pary klucz-wartość. Klucz może na przykład odnosić się do identyfikatora adresu, a wartość do rzeczywistej wartości tego adresu.
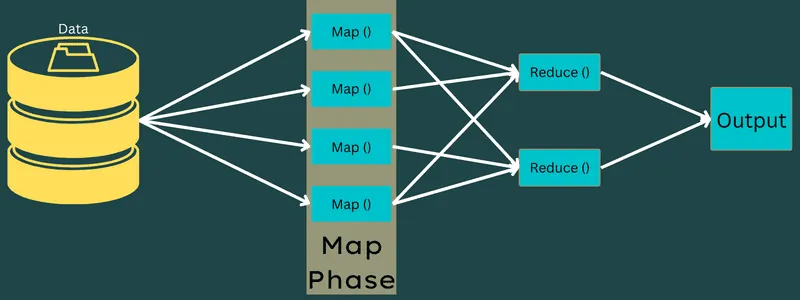
Faza ta składa się z dwóch etapów: podziałów i mapowania. Podziały to mniejsze fragmenty zadania, wydzielone z zadania głównego. Są one również nazywane podziałami wejściowymi. Podział danych wejściowych to porcja danych, która jest wykorzystywana przez etap mapowania.
Następnie następuje etap mapowania. Jest to pierwsza faza podczas realizacji programu MapReduce. Dane zawarte w każdym podziale są przekazywane do funkcji mapowania w celu przetworzenia i wygenerowania danych wyjściowych.
Funkcja Map(), działając na wejściowych parach klucz-wartość w pamięci, generuje pośrednie pary klucz-wartość. Ta nowa para będzie działała jako dane wejściowe przekazywane do funkcji Reduce() lub reduktora.
Redukcja
Pośrednie pary klucz-wartość, uzyskane w fazie mapowania, są danymi wejściowymi dla funkcji redukcji. Podobnie jak w fazie mapowania, występują dwa etapy: tasowanie i redukcja.
Pary klucz-wartość są sortowane i tasowane w celu przekazania do reduktora. Następnie reduktor grupuje lub agreguje dane zgodnie z parą klucz-wartość, w oparciu o algorytm reduktora napisany przez programistę.
W tej fazie wartości z etapu tasowania są łączone w celu uzyskania wartości wyjściowej. Faza ta podsumowuje cały zestaw danych.
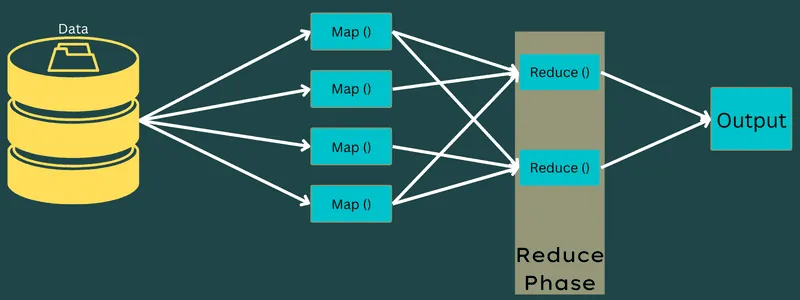
Cały proces wykonywania zadań Map i Reduce jest kontrolowany przez pewne podmioty. Są to:
- Job Tracker: Pełni rolę menedżera odpowiedzialnego za całość wykonania przesłanego zadania. Śledzenie zadań zarządza wszystkimi zadaniami i zasobami w klastrze. Ponadto, moduł śledzenia zadań planuje każde zadanie mapowania dodane do modułu śledzenia zadań, które działa w określonym węźle danych.
- Task Tracker: Wykonuje zadania zgodnie z instrukcjami Job Trackera. Task Tracker jest wdrażany na każdym węźle klastra wykonującym zadania mapowania i redukcji.
Zadanie jest dzielone na mniejsze zadania, uruchamiane na różnych węzłach danych klastra. Job Tracker koordynuje zadanie, planując zadania i uruchamiając je na wielu węzłach danych. Task Tracker na każdym węźle wykonuje mniejsze części zadania i zarządza każdym z nich.
Ponadto, moduły śledzenia zadań przesyłają raporty postępów do modułu śledzenia zadań. Task Tracker regularnie wysyła sygnał „bicia serca” do Job Trackera, informując go o stanie systemu. W przypadku awarii, Job Tracker jest w stanie przenieść zadanie do innego Task Trackera.
Faza wyjściowa: W tej fazie otrzymywane są ostateczne pary klucz-wartość wygenerowane przez Reduktora. Formatowanie danych wyjściowych umożliwia przetłumaczenie par klucz-wartość i zapisanie ich do pliku za pomocą narzędzia do zapisywania rekordów.
Dlaczego warto korzystać z MapReduce?
Oto zalety MapReduce, które tłumaczą jego użyteczność w aplikacjach Big Data:
Przetwarzanie równoległe

W MapReduce zadanie może być podzielone na różne węzły, gdzie każdy węzeł jednocześnie obsługuje część zadania. Dzielenie większych zadań na mniejsze zmniejsza ich złożoność. Równoległe działanie zadań na różnych komputerach, zamiast na jednej maszynie, znacząco przyspiesza przetwarzanie danych.
Lokalizacja danych
W MapReduce jednostka przetwarzająca jest przenoszona do danych, a nie odwrotnie.
Tradycyjnie, dane były dostarczane do jednostki przetwarzającej. Jednak wraz z szybkim wzrostem ilości danych, podejście to zaczęło generować szereg problemów, takich jak wysokie koszty, czasochłonność, obciążenie węzła nadrzędnego, częste awarie i spadek wydajności sieci.
MapReduce rozwiązuje te problemy poprzez przeniesienie jednostki przetwarzającej do danych. Dane są rozdzielane między węzły, gdzie każdy z nich przetwarza swoją porcję.
Pozwala to na zmniejszenie kosztów i skrócenie czasu przetwarzania, gdyż każdy węzeł działa równolegle z przydzieloną mu częścią danych. Dodatkowo, obciążenie węzłów jest zrównoważone, co zapobiega ich przeciążeniu.
Bezpieczeństwo

Model MapReduce zapewnia wysoki poziom bezpieczeństwa. Chroni aplikacje przed nieautoryzowanym dostępem do danych, jednocześnie zwiększając bezpieczeństwo całego klastra.
Skalowalność i elastyczność
MapReduce to wysoce skalowalna platforma. Umożliwia uruchamianie aplikacji na niewielkiej liczbie maszyn, jak i na tysiącach maszyn, przetwarzając dane o rozmiarach terabajtów. Zapewnia elastyczność przetwarzania danych, które mogą być ustrukturyzowane, częściowo ustrukturyzowane lub nieustrukturyzowane, w dowolnym formacie i rozmiarze.
Prostota
Programy MapReduce można pisać w różnych językach programowania, takich jak Java, R, Perl, Python i inne. Ułatwia to naukę i pisanie programów, umożliwiając jednocześnie realizację wymagań dotyczących przetwarzania danych.
Zastosowania MapReduce
- Indeksowanie pełnotekstowe: MapReduce jest używany do indeksowania pełnotekstowego. Mapper mapuje każde słowo lub frazę w dokumencie, a Reduktor zapisuje wszystkie zmapowane elementy do indeksu.
- Obliczanie PageRank: Google wykorzystuje MapReduce do obliczania PageRank.
- Analiza dziennika: MapReduce może analizować pliki dziennika. Może podzielić duży plik dziennika na fragmenty, podczas gdy program mapujący wyszukuje dostępne strony internetowe.
W przypadku znalezienia strony internetowej w dzienniku, para klucz-wartość jest przekazywana do reduktora. Kluczem jest strona internetowa, a wartością indeks „1”. Reduktor agreguje pary klucz-wartość, a wynik to liczba odwiedzin dla każdej strony internetowej.

- Reverse Web-Link Graph: Framework ten znajduje zastosowanie również w analizie Reverse Web-Link Graph. Funkcja Map() zwraca docelowy adres URL i źródło, pobierając dane wejściowe ze źródła lub strony internetowej.
Następnie funkcja Reduce() agreguje listę wszystkich źródłowych adresów URL powiązanych z docelowym adresem URL, a na koniec zwraca źródła i cel.
- Liczenie słów: MapReduce jest używany do liczenia, ile razy dane słowo występuje w dokumencie.
- Globalne ocieplenie: Organizacje, rządy i firmy mogą korzystać z MapReduce w celu rozwiązania problemów związanych z globalnym ociepleniem.
Można na przykład zbadać wzrost temperatury oceanu. W tym celu można zebrać dane z całego świata, w tym wysoką temperaturę, niską temperaturę, szerokość i długość geograficzną, datę, godzinę itp. W celu obliczenia danych wyjściowych, można użyć MapReduce.
- Testy leków: Tradycyjnie, naukowcy zajmujący się danymi i matematycy pracowali razem nad opracowaniem nowego leku. Dzięki algorytmom i MapReduce, działy IT w organizacjach mogą łatwo rozwiązywać problemy, które wcześniej wymagały Superkomputerów, doktorów nauk itp. Teraz można łatwo sprawdzić skuteczność leku dla grupy pacjentów.
- Inne zastosowania: MapReduce umożliwia przetwarzanie dużych ilości danych, które nie mieszczą się w relacyjnej bazie danych. Wykorzystuje narzędzia data science, które mogą być uruchamiane na różnych, rozproszonych zbiorach danych, co wcześniej było możliwe tylko na jednym komputerze.
Dzięki swojej niezawodności i prostocie, MapReduce znajduje zastosowanie w wojsku, biznesie, nauce i innych obszarach.
Podsumowanie
MapReduce może okazać się przełomową technologią. Jest nie tylko szybszy i prostszy, ale także opłacalny i mniej czasochłonny. Biorąc pod uwagę jego zalety i rosnące zastosowanie, prawdopodobnie będzie on częściej wykorzystywany w różnych branżach i organizacjach.
Warto również zapoznać się z zasobami do nauki Big Data i Hadoop.
