
Komputery osiągnęły obecnie szczyt i wciąż rosną. W ciągu ostatnich 3 dekad maszyny ewoluowały i ulepszały całą masę, zwłaszcza pod względem mocy obliczeniowej i wielozadaniowości.
Czy możesz sobie wyobrazić, jak szalony może być wzrost wydajności, jeśli zadania są dzielone między wiele maszyn i wykonywane równolegle? Nazywa się to przetwarzaniem rozproszonym. To jak praca zespołowa dla komputerów.
Jednak możesz się zastanawiać, dlaczego omawiamy tę kwestię przetwarzania rozproszonego. Ponieważ przetwarzanie rozproszone i Amazon EMR (Elastic MapReduce) są bardzo powiązane. Oznacza to, że EMR firmy AWS wykorzystuje zasady przetwarzania rozproszonego do przetwarzania i analizowania dużych ilości danych w chmurze.
Dzięki Amazon EMR możesz teraz analizować i przetwarzać duże zbiory danych przy użyciu wybranej struktury przetwarzania rozproszonego w instancjach S3.
Spis treści:
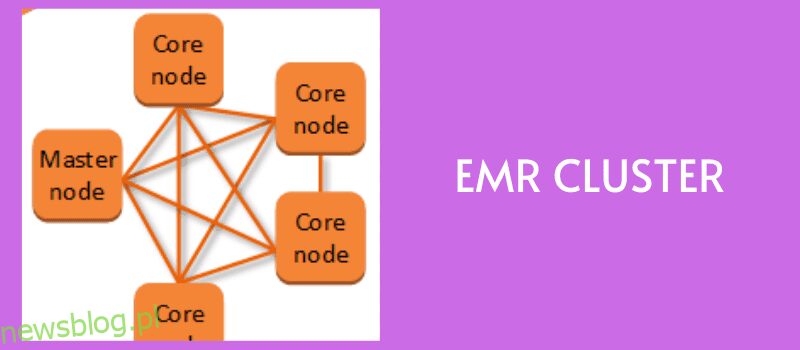
Jak działa Amazon EMR?
Źródło: aws.amazon.com
Po pierwsze, wprowadź dane do dowolnego magazynu danych, takiego jak Amazon S3, DynamoDB lub inne platformy pamięci masowej AWS, ponieważ wszystkie one dobrze integrują się z EMR.
Teraz będziesz potrzebować platformy Big Data do przetwarzania i analizowania tych danych. Mając do wyboru różne platformy big data, takie jak Apache Spark, Hadoop, Hive i Presto, możesz wybrać tę, która odpowiada Twoim wymaganiom i przesłać ją do wybranego magazynu danych.
Klaster EMR instancji EC2 jest tworzony w celu równoległego przetwarzania i analizowania danych. Możesz skonfigurować liczbę węzłów i inne szczegóły, aby utworzyć klaster.
Twoja podstawowa pamięć masowa dystrybuuje dane i struktury do tych węzłów, gdzie fragmenty danych są przetwarzane indywidualnie, a wyniki są łączone.
Po uzyskaniu wyników możesz zakończyć działanie klastra, aby zwolnić wszystkie przydzielone zasoby.
Korzyści z Amazon EMR
Firmy, zarówno małe, jak i duże, zawsze rozważają przyjęcie opłacalnych rozwiązań. Dlaczego więc nie przystępny cenowo Amazon EMR? Kiedy może uprościć uruchamianie różnych platform big data w AWS, zapewniając wygodny sposób przetwarzania i analizowania danych przy jednoczesnej oszczędności pieniędzy.
✅ Elastyczność: Możesz odgadnąć jej naturę za pomocą terminu „Elastic MapReduce”. Termin mówi – w oparciu o wymagania, Amazon EMR umożliwia łatwą zmianę rozmiaru klastrów ręcznie lub automatycznie. Na przykład możesz teraz potrzebować 200 instancji do przetworzenia żądań, a po godzinie lub dwóch może to wzrosnąć do 600 instancji. Tak więc Amazon EMR jest najlepszy, gdy potrzebujesz tylko skalowalności, aby dostosować się do szybkich zmian popytu.
✅ Magazyny danych: niezależnie od tego, czy jest to Amazon S3, rozproszony system plików Hadoop, Amazon DynamoDB, czy inne magazyny danych AWS, Amazon EMR bezproblemowo się z nim integruje.
✅ Narzędzia do przetwarzania danych: Amazon EMR obsługuje różne platformy big data, w tym Apache Spark, Hive, Hadoop i Presto. Co więcej, możesz uruchamiać algorytmy i narzędzia do głębokiego uczenia się i uczenia maszynowego na tym frameworku.
✅ Opłacalność: w przeciwieństwie do innych produktów komercyjnych, Amazon EMR pozwala płacić tylko za zasoby, z których korzystasz co godzinę. Ponadto możesz wybierać spośród różnych modeli cenowych, które są zgodne z Twoim budżetem.
✅ Dostosowanie klastra: Framework pozwala dostosować każdą instancję klastra. Możesz także sparować platformę big data z idealnym typem klastra. Na przykład instancje oparte na Apache Spark i Graviton2 to zabójcza kombinacja zapewniająca zoptymalizowaną wydajność w EMR.
✅ Kontrola dostępu: Możesz wykorzystać narzędzia AWS Identity and Access Management (IAM) do kontrolowania uprawnień w EMR. Na przykład możesz zezwolić określonym użytkownikom na edytowanie klastra, podczas gdy inni mogą tylko wyświetlać klaster.
✅ Integracja: Integracja EMR ze wszystkimi innymi usługami AWS przebiega bezproblemowo. Dzięki temu możesz uzyskać moc serwerów wirtualnych, solidne zabezpieczenia, rozszerzalną pojemność i możliwości analityczne w EMR.
Przypadki użycia Amazon EMR
# 1. Nauczanie maszynowe

Analizuj dane za pomocą uczenia maszynowego i uczenia głębokiego w Amazon EMR. Na przykład uruchamianie różnych algorytmów na danych związanych ze zdrowiem w celu śledzenia wielu wskaźników zdrowotnych, takich jak wskaźnik masy ciała, tętno, ciśnienie krwi, procent tłuszczu itp., Ma kluczowe znaczenie dla opracowania urządzenia do śledzenia kondycji. Wszystko to można wykonać na instancjach EMR szybciej i wydajniej.
#2. Dokonuj dużych przekształceń
Sprzedawcy zwykle pobierają duże ilości danych cyfrowych, aby analizować zachowania klientów i usprawniać działalność. Na tej samej linii Amazon EMR będzie wydajny w pobieraniu dużych zbiorów danych i przeprowadzaniu dużych transformacji za pomocą Spark.
#3. Eksploracja danych

Czy chcesz zająć się zbiorem danych, którego przetwarzanie zajmuje dużo czasu? Amazon EMR jest przeznaczony wyłącznie do eksploracji danych i analizy predykcyjnej złożonych zestawów danych, zwłaszcza w przypadku danych nieustrukturyzowanych. Co więcej, jego architektura klastrowa doskonale nadaje się do przetwarzania równoległego.
#4. Cele badawcze
Przeprowadź badania, korzystając z ekonomicznej i wydajnej platformy o nazwie Amazon EMR. Ze względu na swoją skalowalność rzadko występują problemy z wydajnością podczas uruchamiania dużych zestawów danych w EMR. Tak więc ta struktura jest wysoce dostosowana do badań dużych zbiorów danych i laboratoriów analitycznych.
#5. Przesyłanie strumieniowe w czasie rzeczywistym
Kolejną ważną zaletą Amazon EMR jest obsługa przesyłania strumieniowego w czasie rzeczywistym. Twórz skalowalne potoki przesyłania strumieniowego danych w czasie rzeczywistym do gier online, strumieniowego przesyłania wideo, monitorowania ruchu i handlu akcjami za pomocą Apache Kafka i Apache Flink na Amazon EMR.
Czym różni się EMR od Amazon Glue i Redshift?
AWS EMR kontra klej
Dwie potężne usługi AWS – Amazon EMR i Amazon Glue zyskały lojalną uwagę w postępowaniu z Twoimi danymi.
Wydobywanie danych z różnych źródeł, przekształcanie i ładowanie ich do hurtowni danych jest szybkie i wydajne dzięki Amazon Glue, podczas gdy Amazon EMR pomaga przetwarzać aplikacje Big Data za pomocą Hadoop, Spark, Hive itp.,
Zasadniczo AWS Glue pozwala zbierać i przygotowywać dane do analizy, a Amazon EMR pozwala je przetwarzać.
EMR kontra przesunięcie ku czerwieni
Wyobraź sobie, że konsekwentnie poruszasz się po swoich danych i z łatwością wysyłasz do nich zapytania. SQL jest czymś, czego często używasz do tego celu. Na tej samej linii Redshift oferuje zoptymalizowane usługi przetwarzania analitycznego online, aby łatwo wyszukiwać duże ilości danych za pomocą SQL.
Podczas przechowywania danych będziesz mieć dostęp do wysoce skalowalnych, bezpiecznych i dostępnych usług Amazon EMR, które korzystają z zewnętrznych dostawców pamięci masowej, takich jak S3 i DynamoDB. Natomiast Redshift ma własną warstwę danych, umożliwiającą przechowywanie danych w formacie kolumnowym.
Podejścia do optymalizacji kosztów Amazon EMR

# 1. Przyjdź ze sformatowanymi danymi
Im większe dane, tym dłużej trwa ich przetwarzanie. Co więcej, podawanie nieprzetworzonych danych bezpośrednio do klastra czyni go jeszcze bardziej złożonym, co wymaga więcej czasu na znalezienie części, którą zamierzasz przetworzyć.
Tak więc sformatowane dane zawierają metadane dotyczące kolumn, typu danych, rozmiaru i nie tylko, dzięki którym można zaoszczędzić czas na wyszukiwaniach i agregacjach.
Zmniejsz także rozmiar danych, wykorzystując techniki kompresji danych, ponieważ stosunkowo łatwiej jest przetwarzać mniejsze zbiory danych.
#2. Korzystaj z niedrogich usług pamięci masowej
Wykorzystanie ekonomicznych usług podstawowej pamięci masowej ogranicza główne wydatki na EMR. Amazon s3 to prosta i niedroga usługa przechowywania danych wejściowych i wyjściowych. Jego model pay-as-you-go pobiera opłaty tylko za rzeczywiście wykorzystane miejsce.
#3. Właściwe rozmiary instancji
Korzystanie z odpowiednich instancji o odpowiednich rozmiarach może znacznie zmniejszyć budżet wydawany na EMR. Instancje EC2 są zwykle naliczane za sekundę, a cena zależy od ich rozmiaru, ale niezależnie od tego, czy używasz dużego klastra 0,7x, czy 0,36x dużego, koszt zarządzania nimi jest taki sam. Efektywne wykorzystanie większych maszyn jest więc opłacalne w porównaniu z używaniem wielu małych maszyn.
#4. Wykryj instancje
Spotowe instancje to świetna opcja na zakup niewykorzystanych zasobów EC2 po obniżonych cenach. W porównaniu z instancjami na żądanie są one tańsze, ale nie są trwałe, ponieważ można je odzyskać, gdy popyt wzrośnie. Są więc elastyczne pod względem odporności na uszkodzenia, ale nie nadają się do długotrwałych zadań.
#5. Automatyczne skalowanie
Jego funkcja automatycznego skalowania to wszystko, czego potrzebujesz, aby uniknąć zbyt dużych lub niewymiarowych klastrów. Pozwala to wybrać odpowiednią liczbę i typ instancji w klastrze na podstawie obciążenia, optymalizując koszty.
Ostatnie słowa
Chmura i technologia big data nie mają końca, dzięki czemu masz nieskończoną liczbę narzędzi i platform do nauki i wdrażania. Jedną z takich pojedynczych platform do wykorzystania zarówno dużych zbiorów danych, jak i chmury jest Amazon EMR, ponieważ upraszcza uruchamianie platform dużych zbiorów danych w celu przetwarzania i analizowania dużych zbiorów danych.
Aby pomóc Ci rozpocząć pracę z EMR, w tym artykule dowiesz się, co to jest, jakie przynosi korzyści, jak działa, przypadki użycia i opłacalne podejścia.
Następnie sprawdź wszystko, co musisz wiedzieć o AWS Athena.