Zrozumienie przetwarzania bezserwerowego dla początkujących
Kiedy mowa o obliczeniach bezserwerowych, wiele osób błędnie zakłada, że w tym podejściu nie ma fizycznych serwerów, które umożliwiają uruchamianie kodu i realizację zadań programistycznych. To powszechne nieporozumienie.
Po obaleniu tego mitu, możesz zastanawiać się, skąd wzięła się nazwa "bezserwerowy".
Podpowiem: określenie "bezserwerowy" nie oznacza braku serwerów, ale odnosi się do sposobu, w jaki są one zarządzane i wdrażane.
Brzmi zagmatwanie?
Właśnie dlatego zgłębimy temat serverless i powiązanych z nim pojęć, aby rozwiać wszelkie wątpliwości. Trzeba przyznać, że serverless zyskuje na popularności. Szacuje się, że rynek rozwiązań bezserwerowych osiągnie 7,7 mld USD do 2021 roku, w porównaniu z 1,9 mld USD w 2016 roku.
Przyjrzyjmy się więc bliżej technologii bezserwerowej i spróbujmy zrozumieć przyczyny jej popularności.
Czym jest przetwarzanie bezserwerowe?
Przetwarzanie bezserwerowe, inaczej serverless, to model wykonywania kodu oparty na chmurze. Dostawcy usług chmurowych na żądanie dostarczają moc obliczeniową i samodzielnie zarządzają serwerami, zamiast obciążać tym klientów lub programistów. Łączy w sobie usługi, strategie i praktyki, które ułatwiają programistom tworzenie aplikacji w chmurze, pozwalając im skupić się na kodzie, a nie na administracji serwerami.
Poczynając od alokacji zasobów, przez planowanie pojemności, zarządzanie, konfigurację i skalowanie, aż po poprawki, aktualizacje i konserwację – dostawca usług chmurowych (np. AWS lub Google Cloud Platform) przejmuje całą odpowiedzialność za typowe zadania związane z infrastrukturą. Dzięki temu programiści mogą w pełni skoncentrować się na logice biznesowej swoich procesów i aplikacji.
Architektura bezserwerowa nie przechowuje zasobów obliczeniowych w sposób ciągły; obliczenia odbywają się w krótkich cyklach. Gdy aplikacja nie jest używana, nie są do niej przydzielane żadne zasoby. W efekcie płacisz jedynie za faktycznie zużyte zasoby.
Głównym założeniem modelu serverless jest uproszczenie procesu wdrażania kodu. Często współdziała on z tradycyjnymi podejściami, takimi jak mikrousługi. Po wdrożeniu rozwiązania bezserwerowego aplikacje, które z niego korzystają, zaczynają szybko reagować na żądania i automatycznie skalują się w górę lub w dół, dostosowując się do potrzeb.
Przetwarzanie bezserwerowe wykorzystuje model sterowany zdarzeniami do określania wymagań dotyczących skalowania. Programiści nie muszą już przewidywać obciążenia aplikacji, aby określić, ile serwerów lub przepustowości jest potrzebnych. Mogą elastycznie zwiększać zasoby w miarę rosnących potrzeb i zmniejszać je w dowolnym momencie, bez zbędnych komplikacji.
Ewolucja technologii bezserwerowej
Tradycyjne systemy napotykały na wyzwania związane ze skalowalnością i elastycznością w procesie tworzenia i wdrażania aplikacji. Wraz z rosnącym zapotrzebowaniem na wysokiej jakości aplikacje i krótkim czasem wprowadzania ich na rynek, pojawiła się potrzeba stworzenia lepszego systemu, który zapewniłby większą skalowalność i elastyczność. To z kolei doprowadziło do rozwoju przetwarzania w chmurze i modeli bezserwerowych.
Model bezserwerowy ewoluował etapami, od monolitycznych systemów, przez mikrousługi, aż do architektury bezserwerowej, określanej też jako funkcja jako usługa (FaaS).
- Architektura monolityczna to tradycyjne, scentralizowane podejście do tworzenia oprogramowania. Charakteryzuje się ścisłym powiązaniem komponentów, gdzie każdy z nich kompiluje i wykonuje kod. Awaria jednej usługi może skutkować zatrzymaniem całego serwera aplikacji i wszystkich działających na nim usług.
- Architektura mikrousług to zbiór mniejszych, niezależnych usług w ramach jednej aplikacji. Każda z nich jest wdrażana osobno i realizuje określoną funkcję. Pozwala to na szybkie wdrażanie aplikacji na dużą skalę i zapewnia programistom elastyczność, dzięki wykorzystaniu infrastruktury jako usługi (IaaS) i platformy jako usługi (PaaS). Trudność w tym modelu polega na wyborze między PaaS a IaaS.
- Architektura bezserwerowa to najnowszy etap ewolucji przetwarzania w chmurze. Oferuje jeszcze większą skalowalność i elastyczność. Zamiast IaaS i PaaS wykorzystuje FaaS i backend jako usługę (BaaS). Aplikacje wdrażane są w miarę potrzeb, wraz z odpowiednimi zasobami. Programiści nie muszą zarządzać serwerami i mogą wstrzymać płatności, gdy kod przestaje być wykonywany.
Cechy charakterystyczne przetwarzania bezserwerowego
Poniżej przedstawiamy najważniejsze cechy charakterystyczne przetwarzania bezserwerowego:
- Aplikacje bezserwerowe składają się z niezależnych funkcji i małych fragmentów kodu.
- Kod uruchamiany jest tylko na żądanie, najczęściej w bezstanowym kontenerze, i płynnie skaluje się w zależności od zapotrzebowania.
- Klienci nie muszą zajmować się zarządzaniem serwerami.
- Wykorzystuje model wykonania oparty na zdarzeniach, gdzie środowisko obliczeniowe tworzone jest w momencie uruchomienia funkcji lub otrzymania zdarzenia, które wymaga realizacji żądania.
- Oferuje elastyczną skalowalność. Możliwe jest łatwe skalowanie w górę lub w dół, a po zakończeniu działania kodu infrastruktura przestaje pracować, generując oszczędności. W przypadku kontynuowania działania funkcji, skalowanie może być nieograniczone.
- Dostępne są zarządzane usługi chmurowe, które ułatwiają realizację złożonych zadań, takich jak przechowywanie plików, kolejkowanie, bazy danych itp.
Jak działa technologia bezserwerowa?
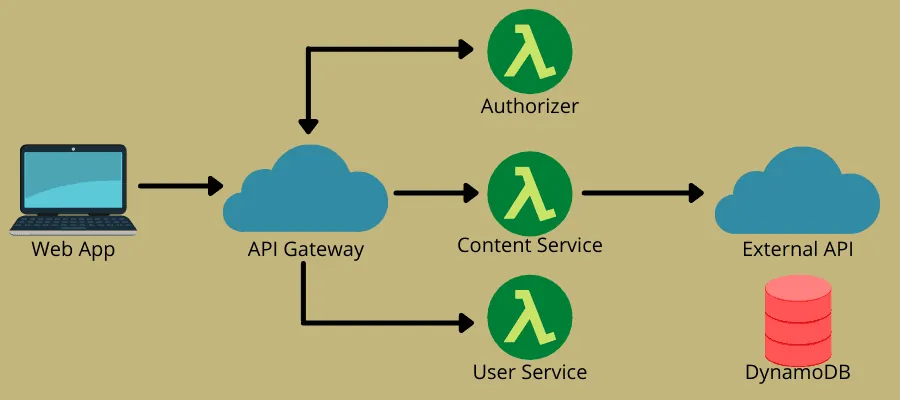
Architektura bezserwerowa łączy w sobie dwie główne koncepcje: funkcję jako usługę (FaaS) i backend jako usługę (BaaS). Bazuje przede wszystkim na FaaS, która umożliwia uruchamianie kodu bez konieczności pełnej alokacji instancji. FaaS obejmuje bezstanowe, sterowane zdarzeniami i skalowalne funkcje po stronie serwera, którymi w pełni zarządzają dostawcy usług chmurowych.
Ten model pozwala zespołom DevOps skupić się na logice biznesowej kodu. Wystarczy zdefiniować zdarzenie, które uruchomi funkcję, np. żądanie HTTP. Dostawca chmury wykonuje funkcję i przesyła wyniki do aplikacji, z którą korzystają użytkownicy.
Model bezserwerowy zapewnia oszczędność kosztów i wygodę dzięki automatycznemu skalowaniu, pracy na żądanie i płatności zgodnie z rzeczywistym użyciem. Coraz więcej firm i zespołów DevOps decyduje się na wdrożenie tej technologii.
Kto i dlaczego korzysta z serverless?
Serverless to jedna z najszybciej rozwijających się technologii w tworzeniu oprogramowania. Eliminuje potrzebę zarządzania i udostępniania infrastruktury.
Jest szczególnie przydatna dla:
- Organizacje, które chcą osiągnąć większą skalowalność i elastyczność, przy jednoczesnej poprawie testowalności aplikacji.
- Programiści, którzy chcą skrócić czas wprowadzania produktu na rynek, tworząc zwinne i wydajne aplikacje.
- Firmy, które nie potrzebują, aby ich serwery działały przez cały czas. W razie potrzeby mogą wywoływać funkcje na żądanie, co pozwala na obniżenie kosztów.
- Organizacje, które chcą tworzyć wydajne aplikacje w chmurze i uprościć migrację do chmury.
- Programiści, którzy chcą zminimalizować opóźnienia i zapewnić użytkownikom szybki dostęp do wybranych funkcji lub aplikacji.
- Firmy, które nie dysponują wystarczającymi zasobami do obsługi złożonej infrastruktury IT. Przejście na przetwarzanie bezserwerowe automatyzuje rozwiązywanie problemów i nie wymaga stałej konserwacji.
Do znanych użytkowników technologii bezserwerowej należą m.in. Slack, Coca-Cola i Netflix.
Ze względu na unikalne właściwości, model bezserwerowy doskonale sprawdza się w wielu zastosowaniach, takich jak:
- Aplikacje internetowe: umożliwia tworzenie szybkich i skalowalnych aplikacji internetowych, które szybko reagują na potrzeby użytkowników. Jest to idealne rozwiązanie dla bezstanowych aplikacji, które mogą być uruchamiane natychmiast i dla aplikacji, które muszą poradzić sobie z nieprzewidywalnymi skokami obciążenia.
- Backend API: W środowisku bezserwerowym każda funkcja może być łatwo przekształcona w punkt końcowy HTTP, gotowy do wykorzystania przez klientów. Te funkcje, nazywane działaniami internetowymi, mogą być zestawiane w kompleksowe interfejsy API. Bramy API dodatkowo zwiększają bezpieczeństwo, obsługę domen, ograniczanie liczby zapytań i autoryzację OAuth.
- Mikrousługi: Technologia serverless jest szeroko stosowana w modelu mikrousług, który polega na budowaniu małych usług, które realizują pojedynczą funkcję i komunikują się ze sobą za pomocą interfejsów API. Chociaż mikrousługi można tworzyć przy użyciu kontenerów oprogramowania i PaaS, rozwiązanie bezserwerowe jest bardziej wydajne. Ułatwia tworzenie mniejszych fragmentów kodu, oferuje szybkie wdrażanie, automatyczne skalowanie i elastyczne ceny, które nie obciążają użytkowników, gdy zasoby nie są używane.
- Przetwarzanie danych: Technologia bezserwerowa doskonale nadaje się do przetwarzania danych, takich jak wideo, audio, obrazy i tekst. Jest korzystna dla różnych zadań, takich jak walidacja danych, transformacja, wzbogacanie, czyszczenie, normalizacja audio i przetwarzanie plików PDF. Można ją wykorzystać do przetwarzania obrazów, które obejmuje wyostrzanie, obracanie, generowanie miniatur i redukcję szumów. Inne zastosowania to transkodowanie wideo i optyczne rozpoznawanie znaków (OCR).
- Przetwarzanie strumieniowe/wsadowe: Możliwe jest tworzenie wydajnych aplikacji do przesyłania strumieniowego i potoków danych przy użyciu FaaS i baz danych z Apache Kafka. Model bezserwerowy sprawdza się w różnych procesach pozyskiwania strumieni, w tym danych z dzienników aplikacji, czujników IoT, logiki biznesowej i rynków finansowych.
- Obliczenia równoległe: Serverless doskonale nadaje się do zadań związanych z obliczeniami równoległymi, gdzie wiele zadań jest wykonywanych jednocześnie w celu realizacji określonego zadania. Może to obejmować wyszukiwanie danych, przetwarzanie, operacje na mapach, skrobanie sieci, przetwarzanie genomu, czy dostrajanie hiperparametrów.
- Inne zastosowania: Serverless jest wykorzystywany w różnorodnych aplikacjach, takich jak zarządzanie relacjami z klientami (CRM), finanse, chatboty oraz Business Intelligence i analityka.
Warto pamiętać, że tryb bezserwerowy nie zawsze jest idealnym rozwiązaniem. Duże aplikacje o przewidywalnym i stałym obciążeniu mogą odnieść większe korzyści z tradycyjnej architektury systemu, wykorzystującej dedykowane serwery, zarządzane lub samodzielnie. Ponadto, przejście na zupełnie nową architekturę może być kosztowne i trudne dla organizacji z tradycyjnymi konfiguracjami i starszymi systemami.
Zalety i wady przetwarzania bezserwerowego
Jak każde rozwiązanie, architektura bezserwerowa ma swoje zalety i wady. Przed podjęciem decyzji o jej wdrożeniu warto poznać obie strony, aby ocenić, czy będzie odpowiednia dla Twojej organizacji.
Zalety 👍
Oto niektóre zalety architektury bezserwerowej:
Opłacalność
Serverless może być bardziej ekonomiczny niż zakup lub wynajem serwerów, gdzie płacisz za zasoby, nawet gdy nie są one wykorzystywane.
W serverless stosowany jest model płatności za faktyczne zużycie. Płacisz tylko za przydzieloną pamięć i czas działania kodu, bez ponoszenia kosztów za czas bezczynności.
W rezultacie oszczędzasz na kosztach operacyjnych związanych z instalacją, licencjami, konserwacją, aktualizacjami i wsparciem. Brak sprzętu serwerowego redukuje również koszty pracy.
Skalowalność
Systemy bezserwerowe charakteryzują się wysoką skalowalnością, ponieważ zasoby można skalować w górę lub w dół w dowolnym momencie, w zależności od zapotrzebowania. Z tego powodu nazywane są również "elastycznymi".
Programiści nie muszą poświęcać czasu na konfigurowanie systemów, automatycznego skalowania ani ich dostrajanie. Wybrany dostawca usług w chmurze zarządza tym wszystkim. Ponadto, programiści z małych zespołów mogą samodzielnie uruchamiać swój kod, bez pomocy inżynierów wsparcia.
Redukcja opóźnień
Aplikacje bezserwerowe nie są hostowane na jednym serwerze źródłowym, a kod może być uruchamiany w dowolnej lokalizacji. Jeśli wybrany dostawca chmury to obsługuje, funkcje aplikacji mogą być uruchamiane na serwerach położonych blisko użytkowników końcowych. Dzięki temu zmniejsza się opóźnienie, ze względu na mniejszą odległość między żądaniami użytkownika i serwerem.
Wydajność
Model bezserwerowy zwiększa wydajność programistów, ponieważ nie muszą oni zarządzać serwerami. Nie muszą również zajmować się obsługą żądań HTTP lub wielowątkowością w kodzie.
Upraszcza to tworzenie backendu dzięki FaaS, gdzie kod jest reprezentowany przez funkcje sterowane zdarzeniami. Pozwala to zaoszczędzić czas, który można wykorzystać na udoskonalanie kodu i aplikacji.
Szybsze wdrażanie aplikacji
W przypadku rozwiązania bezserwerowego programiści nie muszą konfigurować zaplecza ani przesyłać kodu na serwer, aby wdrożyć nową wersję aplikacji. Mogą też szybko przesyłać kod w mniejszych porcjach, co ułatwia wprowadzanie nowych produktów.
Możliwość wdrażania kodu w sposób ciągły lub krok po kroku, ze względu na brak monolitycznej architektury, pozwala na szybkie poprawianie błędów, aktualizowanie i dodawanie nowych funkcji w aplikacjach.
Do innych zalet należy zaliczyć ekologiczne przetwarzanie (mniejsze zużycie energii dzięki serwerom uruchamianym na żądanie), łatwiejsze tworzenie aplikacji z wbudowanymi integracjami oraz krótszy czas wprowadzania na rynek.
Wady 👎
Teraz przyjrzyjmy się wadom przetwarzania bezserwerowego:
Wydajność
Rzadziej używany kod bezserwerowy może charakteryzować się większymi opóźnieniami odpowiedzi niż kod działający w sposób ciągły na serwerach dedykowanych, kontenerach oprogramowania lub maszynach wirtualnych (VM). Dzieje się tak dlatego, że potrzebuje on czasu na ponowne uruchomienie.
Trudności w debugowaniu i testowaniu
Trzeba wiedzieć, jak działa kod po wdrożeniu. Testowanie kodu w środowisku bezserwerowym jest utrudnione. Dodatkowo, ze względu na brak wglądu w procesy zaplecza i podział aplikacji na mniejsze funkcje, debugowanie staje się bardziej skomplikowane.
Problemy z bezpieczeństwem
Wzrost liczby zaawansowanych cyberataków stanowi problem. Nie jest jednak możliwe pełne zbadanie bezpieczeństwa dostawcy usług chmurowych. Powierzenie im wrażliwych danych, które są przechowywane w aplikacjach, wiąże się z ryzykiem.
Brak odpowiedniości dla długotrwałych procesów
Serverless jest opłacalny, ale nie dla wszystkich typów aplikacji. Jeśli aplikacja wymaga długotrwałych procesów, koszt jej uruchomienia, ze względu na czas i zużyte zasoby, może być bardzo wysoki. W takich przypadkach bardziej opłacalne może być skorzystanie z hostingu dedykowanego.
Do innych wad rozwiązania bezserwerowego zaliczyć należy trudności w przechodzeniu od jednego dostawcy do drugiego oraz problemy z prywatnością.
Kluczowe terminy w architekturze bezserwerowej
Dyskusja o serverless nie byłaby kompletna bez omówienia kluczowych terminów. FaaS i BaaS to dwa najważniejsze pojęcia, które przyczyniły się do rozwoju technologii bezserwerowej. Do zbudowania systemu bezserwerowego potrzebna jest baza danych, system pamięci masowej, stos technologii, odpowiednia struktura i inne elementy. Przyjrzyjmy się im bliżej.
Funkcja jako usługa (FaaS)
FaaS jest głównym elementem technologii bezserwerowej. Model ten umożliwia uruchamianie kodu w odpowiedzi na zdarzenie. Logika aplikacji jest umieszczana w kontenerach oprogramowania, wykonywana na żądanie i zarządzana przez platformę chmurową.
W porównaniu do BaaS, FaaS daje programistom większą kontrolę nad tworzeniem niestandardowych aplikacji, zamiast polegania na gotowych bibliotekach.
Kontenery oprogramowania, w których wdrażany jest kod, są bezstanowe, co upraszcza integrację danych, a sam kod działa krócej. Programiści mogą wywoływać aplikacje bezserwerowe za pomocą interfejsów API, wykorzystując FaaS, którym dostawcy chmury zarządzają za pośrednictwem API Gateway.
Backend jako usługa (BaaS)
BaaS jest podobne do FaaS, ponieważ oba wymagają zewnętrznego dostawcy. W tym modelu dostawca chmury zapewnia usługi zaplecza, takie jak przechowywanie danych, aby pomóc programistom skupić się na kodzie frontendu. Aplikacje BaaS nie muszą być jednak sterowane zdarzeniami ani działać na brzegu, jak ma to miejsce w przypadku aplikacji bezserwerowych.
Dobrym przykładem BaaS jest AWS Lambda. Programiści wykorzystują kod bezserwerowy w kontenerach z Lambdą, która zapewnia wytyczne dotyczące przesyłania kodu. Automatyzuje również procesy wprowadzania kodu do kontenerów oprogramowania i oferuje usługę zarządzaną.
Stos bezserwerowy
Podobnie jak inne technologie oprogramowania, architektura bezserwerowa również wykorzystuje stos technologiczny. Łączy on różne elementy, które są niezbędne do stworzenia systemu lub aplikacji bezserwerowej.
Stos bezserwerowy obejmuje:
- Język programowania: Programiści mogą wybrać jeden z języków, np. Java, JavaScript, Python, C#, Go, Node.js, F#. Wybór zależy od dostawcy usług chmurowych.
- Framework bezserwerowy: Framework dostarcza szkielet lub strukturę kodu. Dostępnych jest wiele frameworków, które ułatwiają budowanie, pakowanie, kompilację i wdrażanie kodu w chmurze. Frameworki bezserwerowe przyspieszają proces kodowania, upraszczają skalowanie i skracają czas konfiguracji. Przykłady frameworków serwerowych to Apex i AWS Serverless Application Model.
- Bezserwerowe bazy danych: Służą do przechowywania danych, do których dostęp uzyskuje kod. Są też potrzebne do interakcji z funkcjami wywoływanymi przez wyzwalacze. Te bazy danych działają podobnie jak funkcje bezserwerowe, ale przechowują dane przez nieokreślony czas. Przykłady baz danych bezserwerowych to DynamoDB, Azure Cosmos DB, Aurora Serverless i Cloud Firestore.
- Zestaw wyzwalaczy: Pomagają w uruchamianiu kodu, podobnie jak żądania HTTP.
- Kontenery oprogramowania: Usprawniają model bezserwerowy i umożliwiają tworzenie kontenerowych mikrousług bez komplikacji. Pełnią też funkcję repozytorium kodu i ułatwiają programistom pisanie kodu dla różnych platform.
- Bramy API: Działają jak proxy dla akcji internetowych. Oferują routing HTTP, limity liczby zapytań, przeglądanie dzienników użycia API, identyfikatory klientów itp.
Jak wdrożyć i zoptymalizować model Serverless?
Przejście na technologię bezserwerową wiąże się ze znacznymi zmianami w aplikacjach, technologii, kosztach, bezpieczeństwie i korzyściach.
W przypadku startupów lub małych firm przyspieszy to wprowadzenie produktu na rynek i ułatwi wdrażanie aktualizacji dzięki uproszczonemu testowaniu, debugowaniu, zbieraniu opinii i rozwiązywaniu problemów, co przyczyni się do powstania dopracowanej aplikacji.
Większe organizacje mogą skorzystać z większej skalowalności, która zaspokoi potrzeby użytkowników, jednak będzie to wymagało sporych nakładów finansowych.
Dlatego najlepiej jest dokładnie ocenić zalety i wady rozwiązania bezserwerowego, biorąc pod uwagę specyfikę firmy i jej wymagania. Jeśli myślisz o poważnym wdrożeniu tej technologii, zacznij od:
- Zrozumienia swoich potrzeb i określenia odpowiedniego stosu technologii bezserwerowych
- Wyboru dostawcy usług, np. Google Cloud Functions, Azure Functions lub AWS Lambda
- Wyposażenia zespołu w narzędzia do monitorowania wydajności i działania systemu. Obserwuj całkowitą liczbę żądań, ograniczenia, błędy, wskaźniki sukcesu, czas trwania żądań i opóźnienia.
Dostawcy usług bezserwerowych

Na rynku dostępnych jest wielu dostawców usług bezserwerowych. Oto niektórzy z najlepszych:
- AWS Lambda: Jest idealna dla organizacji, które już korzystają z usług AWS. Integruje się z wieloma usługami do przechowywania, przesyłania strumieniowego i baz danych.
- Microsoft Azure Functions: Jeśli korzystasz z Visual Studio Code, ten dostawca będzie dla ciebie odpowiedni. Współpracuje z DevOps i Azure Pipelines dla CI/CD. Obsługuje też Durable Functions dla funkcji stanowych i oferuje zintegrowane monitorowanie.
- Google Cloud Functions: Jeśli korzystasz z usług Google, ten dostawca będzie odpowiedni. Obsługuje aplikacje JS, Go i Python, umożliwia uruchamianie funkcji z Asystenta Google lub GCP i oferuje wbudowane skalowanie.
- IBM Cloud Functions: Jeśli chcesz przejść na model bezserwerowy oparty na Apache OpenWhisk, IBM Cloud Functions jest dla Ciebie. Obejmuje monitorowanie wydajności, wyzwalanie zdarzeń z interfejsu API REST lub usług chmurowych IBM oraz integruje się z bramą IBM API Gateway do zarządzania punktami końcowymi.
- Knative: Jeśli korzystasz z usług na Kubernetes, ten dostawca jest odpowiedni. Jest wspierany przez Google, Red Hat, IBM i innych.
- Cloudflare Workers: Jest dobry dla aplikacji wymagających wysokiej responsywności, szczególnie aplikacji JavaScript. Obsługuje Workers KV do przechowywania danych i WebAssembly, aby ułatwić kompilację i dostarczanie wielu języków. Dodatkowo, sieć z 193 centrami danych poprawia opóźnienia i szybkość reakcji.
Podsumowanie: Przyszłość technologii bezserwerowej
Przetwarzanie bezserwerowe rozwija się w odpowiedzi na rosnące zapotrzebowanie na wysoce skalowalne aplikacje. Oferuje wiele korzyści, takich jak wygoda, efektywność kosztowa, wyższa wydajność i inne.
Zgodnie z badaniem O’Reilly, 40% respondentów pracuje w firmach, które wdrożyły architekturę bezserwerową.
Chociaż technologia serverless nadal budzi pewne obawy związane z opóźnieniami spowodowanymi zimnym startem, testowaniem i debugowaniem, dostawcy usług chmurowych pracują nad ich wyeliminowaniem. W przyszłości możemy spodziewać się jeszcze bardziej wyrafinowanej formy technologii bezserwerowej, która zaoferuje jeszcze więcej korzyści. Przewiduje się, że popularność i wykorzystanie modelu bezserwerowego będzie nadal rosło.
Może Cię również zainteresować: Siedem sposobów, w jakie przetwarzanie bezserwerowe jest technologią wschodzącą
