Analiza danych to dziedzina dostępna dla każdego, kto lubi rozwiązywać zawiłe problemy i odkrywać ukryte zależności w pozornym chaosie.
Jest to trochę jak poszukiwanie pojedynczych igieł w stertach siana, z tym że specjaliści od danych nie muszą przy tym brudzić sobie rąk. Korzystając z zaawansowanych narzędzi, prezentujących kolorowe wykresy i analizując ogromne zbiory liczb, zagłębiają się w dane, aby wyciągnąć z nich cenne wnioski, które mają istotne znaczenie biznesowe.
Standardowy zestaw narzędzi analityka danych powinien obejmować przynajmniej jedno narzędzie z każdej z wymienionych kategorii: relacyjne bazy danych, nierelacyjne bazy danych NoSQL, platformy do przetwarzania dużych zbiorów danych (Big Data), narzędzia do wizualizacji, narzędzia do pobierania danych ze stron internetowych (web scraping), języki programowania, zintegrowane środowiska programistyczne (IDE) oraz narzędzia do uczenia głębokiego.
Relacyjne bazy danych
Relacyjna baza danych to zbiór danych zorganizowanych w tabele, które posiadają określone atrybuty. Tabele te można łączyć ze sobą poprzez definiowanie relacji i ograniczeń, tworząc w ten sposób model danych. Do pracy z relacyjnymi bazami danych najczęściej używa się języka SQL (Structured Query Language).
Aplikacje służące do zarządzania strukturą i danymi w relacyjnych bazach danych nazywane są RDBMS (Relational DataBase Management Systems). Istnieje wiele takich systemów, jednak ostatnio te najbardziej istotne zaczęły koncentrować się na dziedzinie analizy danych, dodając funkcje do obsługi repozytoriów Big Data i wykorzystywania technik takich jak analiza i uczenie maszynowe.
Serwer SQL
System RDBMS firmy Microsoft jest rozwijany od ponad 20 lat, stale poszerzając swoje funkcje korporacyjne. Od wersji 2016 SQL Server oferuje zestaw usług, które obejmują obsługę wbudowanego kodu R. SQL Server 2017 idzie o krok dalej, zmieniając nazwę swoich usług R na usługi języka maszynowego i dodając wsparcie dla języka Python (o tych dwóch językach powiemy więcej poniżej).
Te istotne zmiany sprawiają, że SQL Server staje się atrakcyjny dla analityków danych, którzy niekoniecznie posiadają doświadczenie w języku Transact SQL, natywnym języku zapytań w Microsoft SQL Server.
SQL Server nie jest darmowym produktem. Można zakupić licencje na jego instalację na serwerze Windows (cena zależy od liczby jednoczesnych użytkowników) lub korzystać z niego jako płatnej usługi w chmurze Microsoft Azure. Nauka Microsoft SQL Server jest przystępna.
MySQL
W obszarze oprogramowania open source MySQL jest najpopularniejszym systemem RDBMS. Chociaż obecnie właścicielem jest firma Oracle, nadal jest dostępny bezpłatnie na licencji GNU General Public License. Większość aplikacji internetowych wykorzystuje MySQL jako podstawowe repozytorium danych, ze względu na jego zgodność ze standardem SQL.
Na jego popularność wpływają również łatwe procedury instalacji, rozbudowana społeczność programistów, obszerna dokumentacja i dostępność narzędzi firm trzecich, takich jak phpMyAdmin, które upraszczają codzienne czynności związane z zarządzaniem bazą. Mimo że MySQL nie oferuje natywnych funkcji analizy danych, jego otwartość pozwala na integrację z dowolnym narzędziem do wizualizacji, raportowania i analizy biznesowej.
PostgreSQL
Kolejną opcją RDBMS o otwartym kodzie źródłowym jest PostgreSQL. Mimo że nie jest tak popularny jak MySQL, PostgreSQL wyróżnia się elastycznością, możliwością rozbudowy i obsługą zaawansowanych zapytań, wykraczających poza podstawowe instrukcje takie jak SELECT, WHERE i GROUP BY.
Dzięki tym właściwościom zyskuje popularność wśród specjalistów zajmujących się danymi. Dodatkowym atutem jest obsługa różnych środowisk, co umożliwia jego wykorzystanie w chmurze, w środowiskach lokalnych (on-premise) lub w kombinacji obu, czyli w tak zwanym środowisku hybrydowym.
PostgreSQL potrafi łączyć przetwarzanie analityczne online (OLAP) z przetwarzaniem transakcji online (OLTP), działając w trybie zwanym hybrydowym przetwarzaniem transakcyjnym/analitycznym (HTAP). Jest również dobrze przystosowany do pracy z Big Data, dzięki dodatkom PostGIS dla danych geograficznych i JSON-B dla dokumentów. PostgreSQL obsługuje również dane nieustrukturyzowane, co sprawia, że może być zaliczany zarówno do baz danych SQL, jak i NoSQL.
Bazy danych NoSQL
Ten rodzaj repozytorium danych, zwany również nierelacyjnymi bazami danych, zapewnia szybszy dostęp do danych o strukturze nietabelarycznej. Przykładami takich struktur są m.in. grafy, dokumenty, szerokie kolumny i pary klucz-wartość. Bazy danych NoSQL mogą zrezygnować z pełnej spójności danych na rzecz innych korzyści, takich jak dostępność, partycjonowanie i szybkość dostępu.
W bazach danych NoSQL nie jest używany język SQL, dlatego jedynym sposobem na zadawanie zapytań do tego typu baz jest stosowanie języków niższego poziomu. Nie ma jednego standardowego języka, który byłby powszechnie akceptowany jak SQL. Poza tym nie istnieją standardowe specyfikacje dla NoSQL. Dlatego, paradoksalnie, niektóre bazy danych NoSQL zaczynają dodawać obsługę zapytań w języku SQL.
MongoDB
MongoDB jest popularnym systemem baz danych NoSQL, który przechowuje dane w formacie dokumentów JSON. Koncentruje się na skalowalności i elastyczności przechowywania danych w sposób nieustrukturyzowany. Oznacza to, że nie ma ustalonej listy pól, której należy przestrzegać we wszystkich przechowywanych elementach. Co więcej, struktura danych może być zmieniana w czasie, co w relacyjnej bazie danych wiąże się z dużym ryzykiem dla działających aplikacji.

Technologia w MongoDB umożliwia indeksowanie, tworzenie zapytań ad-hoc i agregację, co stanowi solidną podstawę do analizy danych. Rozproszona natura bazy danych zapewnia wysoką dostępność, skalowalność i dystrybucję geograficzną bez konieczności stosowania zaawansowanych narzędzi.
Redis
Redis to kolejna opcja open-source z kategorii NoSQL. Jest to w zasadzie magazyn struktur danych, który działa w pamięci i oprócz świadczenia usług bazodanowych pełni także rolę pamięci podręcznej i brokera komunikatów.

Obsługuje wiele niekonwencjonalnych struktur danych, w tym skróty, indeksy geoprzestrzenne, listy i posortowane zbiory. Jest dobrze dostosowany do analizy danych dzięki wysokiej wydajności w zadaniach wymagających dużych zbiorów danych, takich jak obliczanie przecięć zbiorów, sortowanie długich list lub generowanie złożonych rankingów. Wyjątkowa wydajność Redisa wynika z jego działania w pamięci. Można go skonfigurować tak, aby dane były utrwalane selektywnie.
Platformy Big Data
Załóżmy, że musisz przeanalizować dane generowane przez użytkowników Facebooka w ciągu miesiąca. Mowa tu o zdjęciach, filmach, wiadomościach i wszystkim innym. Biorąc pod uwagę, że każdego dnia do tej sieci społecznościowej dodawane jest ponad 500 terabajtów danych, trudno jest sobie wyobrazić objętość danych z całego miesiąca.
Aby skutecznie pracować z tak ogromną ilością danych, potrzebna jest odpowiednia platforma, która umożliwia obliczanie statystyk w środowisku rozproszonym. Na rynku dominują dwie platformy: Hadoop i Spark.
Hadoop
Jako platforma do przetwarzania Big Data, Hadoop zajmuje się złożonością związaną z wyszukiwaniem, przetwarzaniem i przechowywaniem ogromnych zbiorów danych. Hadoop działa w środowisku rozproszonym, składającym się z klastrów komputerów przetwarzających proste algorytmy. Algorytm o nazwie MapReduce dzieli duże zadania na mniejsze części, a następnie rozdziela je między dostępne klastry.

Hadoop jest zalecany w przypadku repozytoriów danych klasy korporacyjnej, które wymagają szybkiego dostępu i wysokiej dostępności, a wszystko to przy niskich kosztach. Jednak wymaga administratora Linuksa z dogłębną znajomością Hadoopa, aby utrzymać sprawność i działanie infrastruktury.
Spark
Hadoop nie jest jedyną dostępną platformą do pracy z dużymi zbiorami danych. Inną ważną platformą w tej dziedzinie jest Spark. Silnik Spark został zaprojektowany tak, aby pod względem szybkości analizy i łatwości obsługi przewyższał Hadoop. Najwyraźniej osiągnął ten cel: niektóre porównania pokazują, że Spark działa do 10 razy szybciej niż Hadoop podczas pracy z dyskiem i 100 razy szybciej podczas pracy w pamięci. Wymaga również mniejszej liczby maszyn do przetworzenia takiej samej ilości danych.

Oprócz szybkości, kolejną zaletą Sparka jest obsługa przetwarzania strumieniowego. Ten rodzaj przetwarzania danych, zwany również przetwarzaniem w czasie rzeczywistym, obejmuje ciągłe wprowadzanie i wyprowadzanie danych.
Narzędzia do wizualizacji
Wśród analityków danych krąży żart, że jeśli wystarczająco długo „torturujesz” dane, to one „przyznają się” do tego, co chcesz wiedzieć. W tym kontekście „tortury” oznaczają manipulowanie danymi poprzez ich przekształcanie i filtrowanie w celu lepszej wizualizacji. W tym miejscu do akcji wkraczają narzędzia do wizualizacji danych. Narzędzia te pobierają wstępnie przetworzone dane z różnych źródeł i prezentują ujawnione prawidłowości w formie graficznej i zrozumiałej dla użytkownika.
Do tej kategorii zalicza się wiele różnych narzędzi. Niezależnie od preferencji, najczęściej stosowanym jest Microsoft Excel i jego narzędzia do tworzenia wykresów. Wykresy w Excelu są dostępne dla każdego użytkownika tego programu, jednak ich funkcjonalność jest ograniczona. Podobnie sytuacja wygląda w przypadku innych arkuszy kalkulacyjnych, takich jak Arkusze Google i Libre Office. W tym miejscu skupimy się na bardziej specjalistycznych narzędziach, które zostały dostosowane do potrzeb analizy biznesowej (BI) i analizy danych.
Power BI
Firma Microsoft stosunkowo niedawno wypuściła swoją aplikację do wizualizacji Power BI. Potrafi ona pobierać dane z różnych źródeł, takich jak pliki tekstowe, bazy danych, arkusze kalkulacyjne i wiele internetowych usług danych, w tym Facebook i Twitter, i wykorzystywać je do generowania pulpitów nawigacyjnych wypełnionych wykresami, tabelami, mapami i innymi elementami wizualnymi. Elementy pulpitu nawigacyjnego są interaktywne, co oznacza, że można kliknąć serię danych na wykresie, aby ją wybrać i użyć jako filtra dla pozostałych elementów na pulpicie.
Usługa Power BI to połączenie aplikacji desktopowej dla systemu Windows (część pakietu Office 365), aplikacji webowej oraz usługi online do publikowania pulpitów nawigacyjnych w sieci i udostępniania ich użytkownikom. Usługa umożliwia tworzenie i zarządzanie uprawnieniami, co pozwala na przyznanie dostępu do pulpitów tylko wybranym osobom.
Tableau
Tableau to kolejna opcja do tworzenia interaktywnych pulpitów nawigacyjnych z kombinacji wielu źródeł danych. Oferuje również wersję desktopową, wersję internetową i usługę online do udostępniania stworzonych pulpitów. Jak twierdzą twórcy, działa ona w naturalny sposób „zgodnie z tym jak myślisz”. Jest prosta w użyciu dla osób nietechnicznych, co dodatkowo ułatwiają liczne tutoriale i filmy dostępne online.
Do najbardziej wyjątkowych funkcji Tableau należą: nieograniczona liczba połączeń z danymi, obsługa danych na żywo i w pamięci oraz projekty zoptymalizowane pod kątem urządzeń mobilnych.
QlikView
QlikView oferuje przejrzysty i prosty interfejs użytkownika, który pomaga analitykom w odkrywaniu nowych wniosków na podstawie istniejących danych, wykorzystując elementy wizualne łatwe do zrozumienia dla wszystkich.
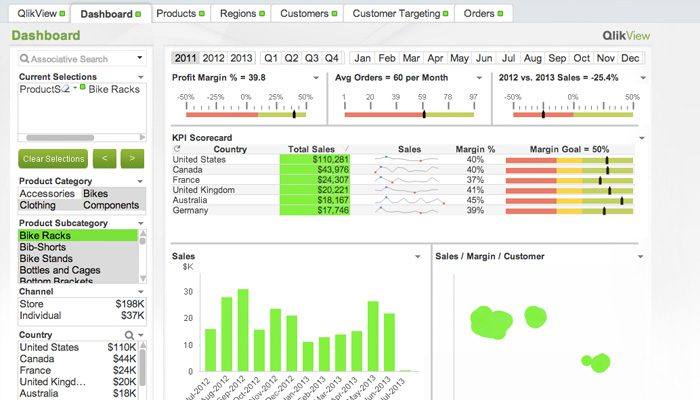
Narzędzie to jest znane z tego, że jest jedną z najbardziej elastycznych platform Business Intelligence. Udostępnia funkcję o nazwie Wyszukiwanie Asocjacyjne, która pomaga skupić się na najważniejszych danych, oszczędzając czas potrzebny na samodzielne ich znalezienie.
Dzięki QlikView można współpracować z partnerami w czasie rzeczywistym, przeprowadzając analizy porównawcze. Wszystkie istotne dane można połączyć w jedną aplikację z funkcjami bezpieczeństwa, które ograniczają dostęp do danych.
Narzędzia do pobierania danych
W początkach istnienia Internetu roboty sieciowe zaczęły przemierzać sieci, zbierając po drodze informacje. Wraz z rozwojem technologii, termin indeksowanie stron internetowych został zastąpiony przez web scraping (pobieranie danych ze stron), ale nadal oznacza to samo: automatyczne wyodrębnianie informacji ze stron internetowych. Aby wykonać web scraping, wykorzystuje się zautomatyzowane procesy lub boty, które przeskakują z jednej strony internetowej na drugą, pobierając z nich dane i eksportując je do różnych formatów lub umieszczając je w bazach danych w celu dalszej analizy.
Poniżej przedstawiamy charakterystykę trzech najpopularniejszych aktualnie skrobaków internetowych.
Octoparse
Web scraper Octoparse oferuje kilka interesujących cech, w tym wbudowane narzędzia do pobierania informacji ze stron internetowych, które nie ułatwiają robotom skrobania wykonywania ich pracy. Jest to aplikacja desktopowa, która nie wymaga programowania. Posiada przyjazny dla użytkownika interfejs, który umożliwia wizualizację procesu ekstrakcji za pomocą graficznego projektanta przepływu pracy.
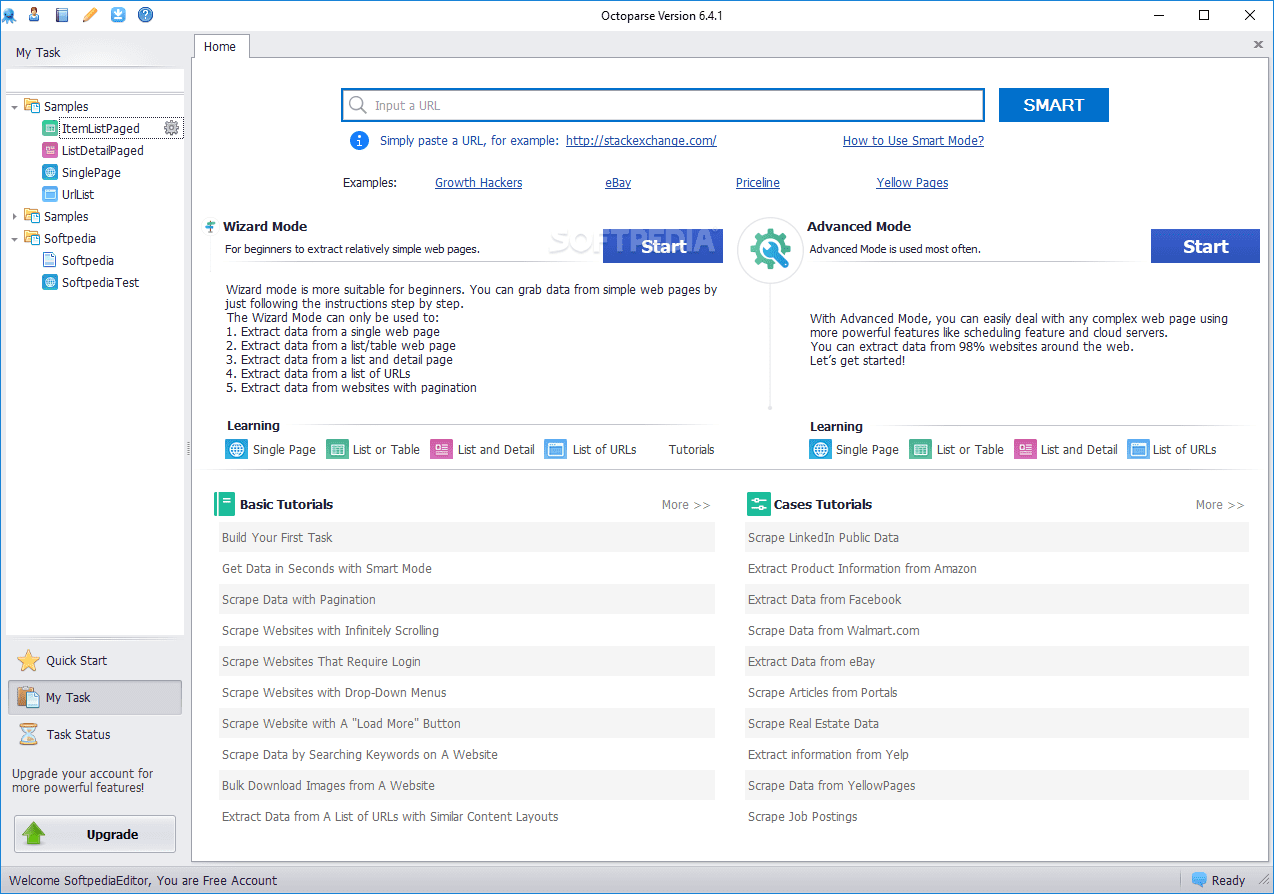
Oprócz aplikacji desktopowej, Octoparse oferuje usługę opartą na chmurze, która przyspiesza proces ekstrakcji danych. Użytkownicy mogą osiągnąć 4-10-krotny wzrost szybkości podczas korzystania z usługi w chmurze zamiast aplikacji desktopowej. Jeśli zdecydujemy się pozostać przy wersji desktopowej, możemy korzystać z Octoparse za darmo. Jednak w przypadku korzystania z usługi w chmurze konieczne będzie wybranie jednego z płatnych planów.
Content Grabber
Jeśli poszukujesz narzędzia do pobierania danych o bogatej funkcjonalności, warto zwrócić uwagę na Content Grabber. W przeciwieństwie do Octoparse, korzystanie z Content Grabbera wymaga posiadania zaawansowanych umiejętności programistycznych. W zamian otrzymujemy edycję skryptów, interfejsy debugowania i inne zaawansowane funkcje. W Content Grabber można używać języków .Net do tworzenia wyrażeń regularnych. W ten sposób nie trzeba generować wyrażeń za pomocą wbudowanego narzędzia.
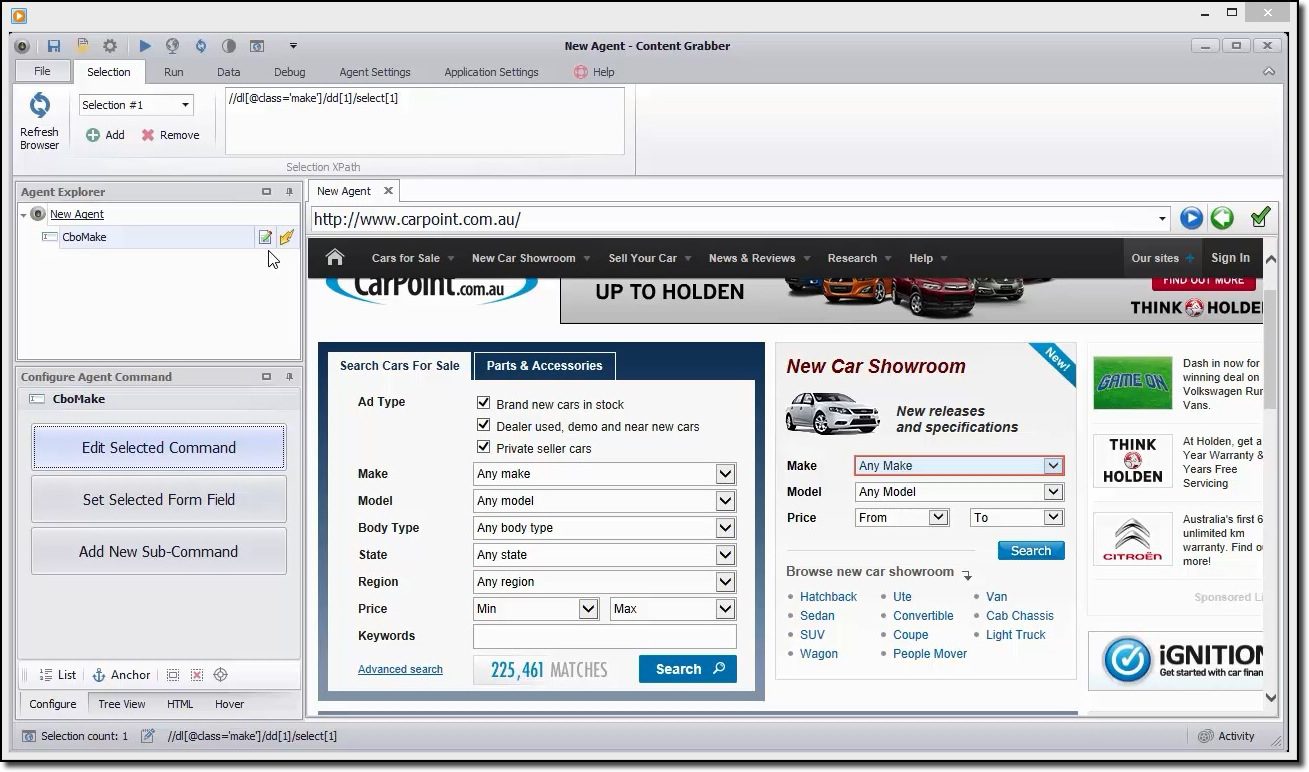
Narzędzie oferuje API (interfejs programowania aplikacji), którego można użyć do dodania funkcji pobierania danych do aplikacji desktopowych i internetowych. Aby korzystać z tego API, programiści muszą uzyskać dostęp do usługi Content Grabber Windows.
ParseHub
Ten skrobak jest w stanie obsłużyć obszerną listę różnych typów treści, w tym fora, zagnieżdżone komentarze, kalendarze i mapy. Radzi sobie również ze stronami, które wymagają uwierzytelnienia, obsługują JavaScript, Ajax i inne zaawansowane technologie. ParseHub można używać jako aplikację webową lub desktopową, działającą w systemach Windows, macOS X i Linux.
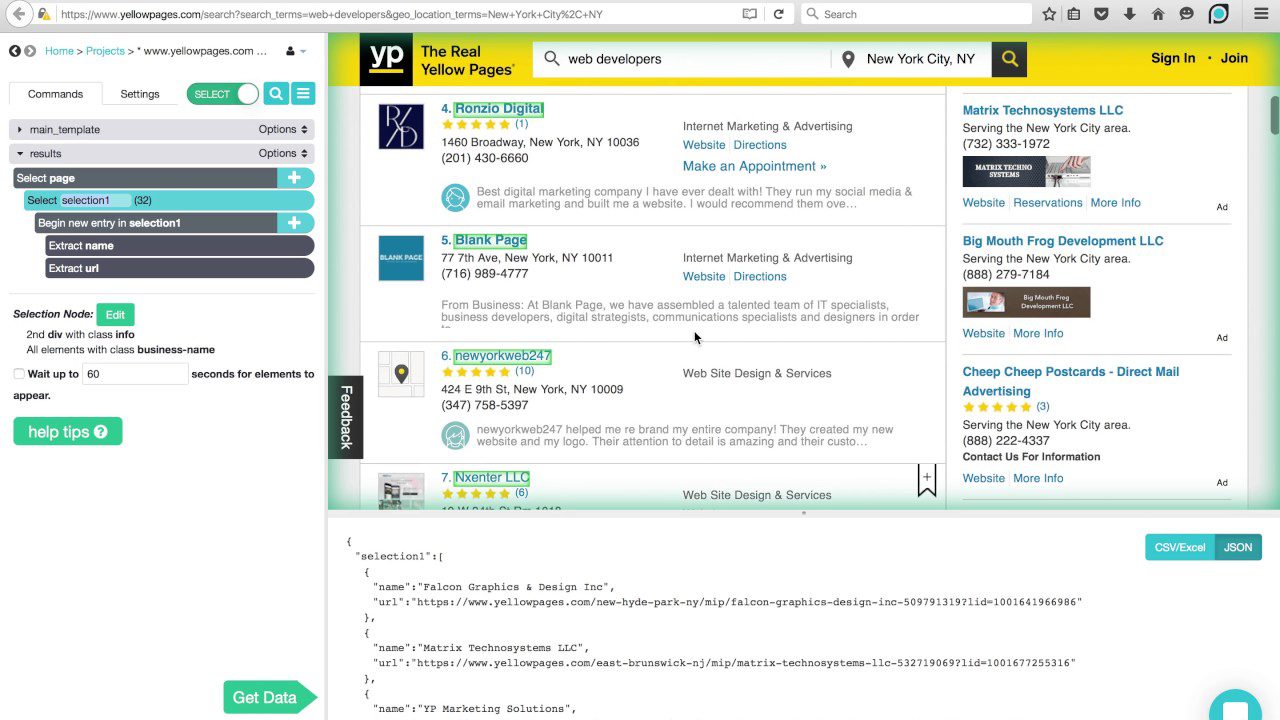
Podobnie jak Content Grabber, zaleca się posiadanie pewnej wiedzy programistycznej, aby w pełni wykorzystać potencjał ParseHub. Dostępna jest darmowa wersja, ograniczona do 5 projektów i 200 stron na jedno uruchomienie.
Języki programowania
Podobnie jak wspomniany wcześniej język SQL został zaprojektowany specjalnie do pracy z relacyjnymi bazami danych, istnieją inne języki stworzone z myślą o analizie danych. Języki te umożliwiają programistom pisanie programów, które zajmują się analizą danych na dużą skalę, takimi jak statystyka i uczenie maszynowe.
SQL jest również uważany za ważną umiejętność, którą programiści powinni posiadać w obszarze analizy danych, ale dzieje się tak dlatego, że większość organizacji nadal przechowuje duże ilości danych w relacyjnych bazach danych. Natomiast „prawdziwymi” językami do analizy danych są R i Python.
Python

Python to wysokopoziomowy, interpretowany język programowania ogólnego przeznaczenia, dobrze dostosowany do szybkiego tworzenia aplikacji. Posiada prostą i łatwą do nauczenia składnię, co skraca czas potrzebny na naukę i obniża koszty utrzymania programu. Istnieje wiele powodów, dla których jest to preferowany język w analizie danych. Wymieniając tylko kilka: potencjał skryptowy, czytelność kodu, przenośność i wydajność.
Język ten jest dobrym punktem startu dla analityków danych, którzy planują przeprowadzić wiele eksperymentów, zanim przejdą do prawdziwej i ciężkiej pracy z przetwarzaniem danych oraz chcą tworzyć kompletne aplikacje.
R
Język R służy głównie do przetwarzania danych statystycznych i tworzenia wykresów. Chociaż nie jest przeznaczony do tworzenia pełnoprawnych aplikacji, jak ma to miejsce w przypadku Pythona, język R zyskał na popularności w ostatnich latach, ze względu na swój potencjał w eksploracji i analizie danych.

Dzięki stale rosnącej bibliotece darmowych pakietów, które rozszerzają jego funkcjonalność, język R jest w stanie wykonywać wszelkiego rodzaju zadania związane z przetwarzaniem danych, w tym modelowanie liniowe/nieliniowe, klasyfikację, testy statystyczne itp.
Nie jest to łatwy język do nauczenia, jednak po zapoznaniu się z jego filozofią, obliczenia statystyczne staną się proste.
IDE
Jeśli poważnie myślisz o karierze w dziedzinie analizy danych, musisz starannie wybrać zintegrowane środowisko programistyczne (IDE), które odpowiada Twoim potrzebom, ponieważ Ty i Twoje IDE spędzicie dużo czasu na wspólnej pracy.
Idealne środowisko IDE powinno zawierać wszystkie narzędzia potrzebne w codziennej pracy programisty: edytor tekstu z podświetlaniem składni i autouzupełnianiem, potężny debugger, przeglądarkę obiektów i łatwy dostęp do narzędzi zewnętrznych. Poza tym, musi być kompatybilne z wybranym językiem, dlatego dobrym pomysłem jest wybór IDE po poznaniu języka, którego zamierzasz używać.
Spyder
To uniwersalne środowisko IDE jest przeznaczone głównie dla naukowców i analityków, którzy również muszą programować. Aby zapewnić im wygodę, nie ogranicza się do funkcjonalności samego IDE, ale udostępnia również narzędzia do eksploracji i wizualizacji danych oraz interaktywnego wykonywania, które można znaleźć w pakiecie naukowym. Edytor w Spyderze obsługuje wiele języków i oferuje przeglądarkę klas, dzielenie okien, możliwość przeskakiwania do definicji, automatyczne uzupełnianie kodu i narzędzie do analizy kodu.
Debugger pomaga w interaktywnym śledzeniu każdego wiersza kodu, a profiler pomaga w znajdowaniu i eliminowaniu nieefektywności.
PyCharm
Jeśli programujesz w Pythonie, to najprawdopodobniej Twoim wyborem będzie IDE PyCharm. Posiada inteligentny edytor kodu z wyszukiwaniem, uzupełnianiem kodu oraz wykrywaniem i naprawianiem błędów. Za pomocą jednego kliknięcia można przeskoczyć z edytora kodu do dowolnego okna kontekstowego, w tym testu, supermetody, implementacji, deklaracji i innych. PyCharm obsługuje Anacondę i wiele pakietów naukowych, takich jak NumPy i Matplotlib.
Oferuje integrację z najważniejszymi systemami kontroli wersji, a także z testerem, profilerem i debuggerem. Ponadto integruje się z Dockerem i Vagrantem, co zapewnia wieloplatformowe środowisko programistyczne i konteneryzację.
RStudio
Dla tych analityków danych, którzy preferują język R, wyborem IDE powinno być RStudio, ze względu na liczne funkcje. Można je zainstalować na komputerze z systemem Windows, macOS lub Linux, lub uruchomić z przeglądarki internetowej, jeśli nie chcemy go instalować lokalnie. Obie wersje oferują funkcje takie jak podświetlanie składni, inteligentne wcięcia i uzupełnianie kodu. Dostępna jest zintegrowana przeglądarka danych, która jest przydatna, gdy chcemy przejrzeć dane tabelaryczne.
Tryb debugowania pozwala zobaczyć, jak dane są aktualizowane dynamicznie podczas wykonywania programu lub skryptu krok po kroku. W celu kontroli wersji RStudio integruje obsługę SVN i Git. Dodatkowym atutem jest możliwość tworzenia interaktywnych grafik za pomocą bibliotek Shiny i Gives.
Twój osobisty zestaw narzędzi
W tym momencie powinieneś mieć pełny obraz narzędzi, które powinieneś znać, aby doskonalić się w analizie danych. Mamy również nadzieję, że przekazaliśmy Ci wystarczająco dużo informacji, abyś mógł zdecydować, które opcje w poszczególnych kategoriach narzędzi są dla Ciebie najbardziej odpowiednie. Teraz wszystko zależy od Ciebie. Analiza danych to dynamicznie rozwijająca się dziedzina, która oferuje możliwości rozwoju kariery. Jeśli chcesz się w niej rozwijać, musisz być na bieżąco ze zmieniającymi się trendami i technologiami, ponieważ zmiany zachodzą niemal codziennie.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.