
Potok Agregacji w MongoDB: Efektywne Przetwarzanie Danych
W MongoDB, do realizacji skomplikowanych zapytań, zaleca się stosowanie potoku agregacji. Jeśli dotychczas używałeś MapReduce, warto rozważyć przejście na potok agregacji, który zapewnia bardziej efektywne przetwarzanie.
Czym Jest Agregacja w MongoDB i Jak Działa?
Potok agregacji to wieloetapowy mechanizm służący do wykonywania złożonych zapytań w MongoDB. Działa poprzez szereg etapów, zwanych potokiem. Rezultaty wygenerowane w jednym etapie mogą stanowić podstawę dla operacji w kolejnym.
Przykładowo, wynik operacji filtrowania ($match) można przekazać do etapu sortowania, i tak dalej, aż uzyskamy pożądany rezultat.
Każdy etap potoku wykorzystuje operator MongoDB i generuje jeden lub więcej zmodyfikowanych dokumentów. W zależności od zapytania, dany etap może pojawić się w potoku wielokrotnie. Na przykład, operatory takie jak $count lub $sort mogą być użyte kilka razy w ramach jednego potoku agregacji.
Etapy Potoku Agregacji
Potok agregacji przekształca dane, przechodząc przez różne etapy w ramach jednego zapytania. Dostępnych jest kilka etapów, a ich szczegółowy opis znajduje się w dokumentacji MongoDB.
Poniżej omówimy niektóre z najczęściej stosowanych etapów:
Etap $match
Etap $match pozwala na zdefiniowanie warunków filtracji na początku procesu agregacji. Umożliwia wybór danych, które będą brane pod uwagę w dalszych etapach potoku.
Etap $group
Etap $group dzieli dane na grupy w oparciu o określone kryteria, wykorzystując pary klucz-wartość. Każda grupa jest reprezentowana przez klucz w dokumencie wyjściowym.
Rozważmy przykładowe dane sprzedażowe:
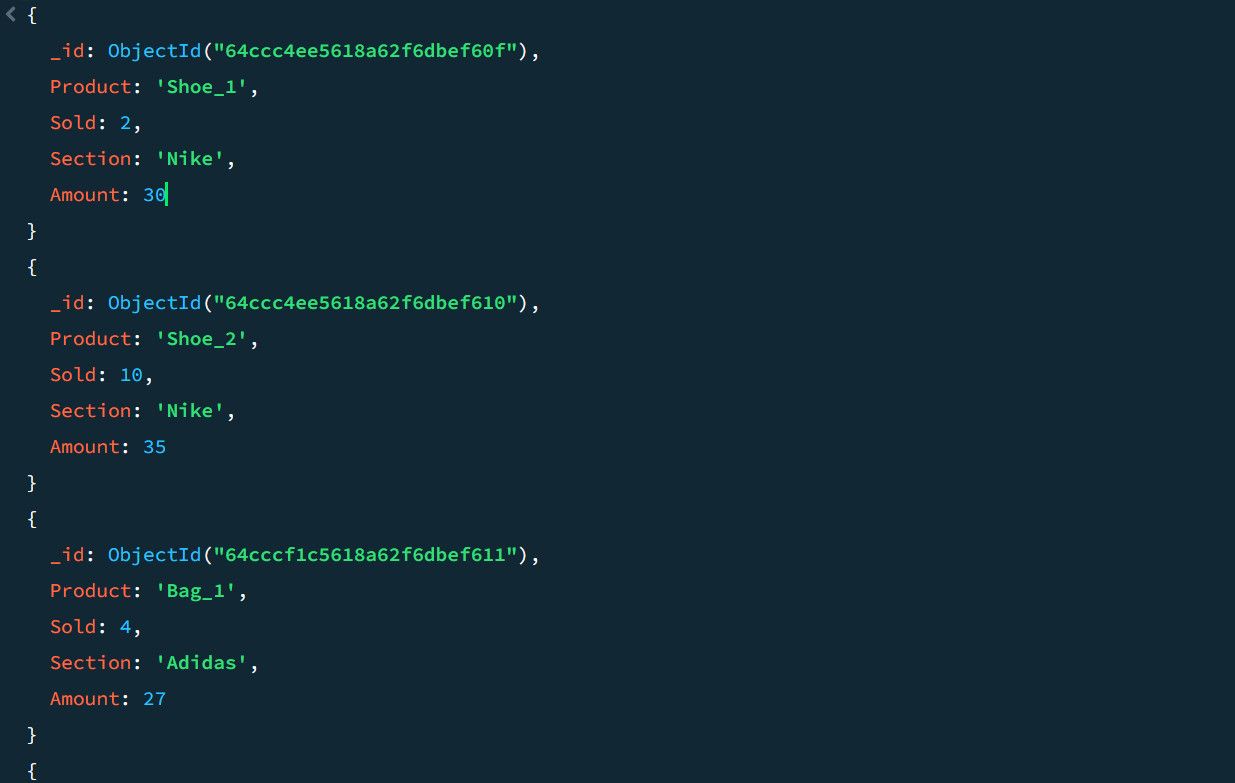
Używając potoku agregacji, możemy obliczyć całkowitą liczbę sprzedanych produktów i największą sprzedaż dla każdej kategorii:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
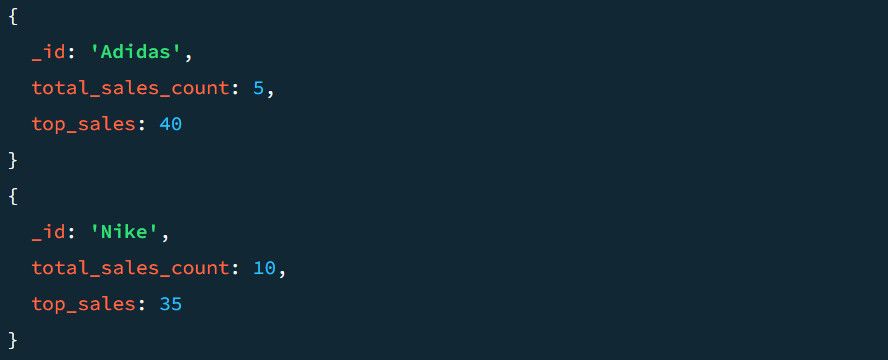
Para `_id: $Section` grupuje wyniki na podstawie sekcji. Określając pola `total_sales_count` i `top_sales`, MongoDB tworzy nowe klucze w oparciu o agregatory, takie jak suma (`$sum`), minimum (`$min`), maksimum (`$max`) lub średnia (`$avg`).
Etap $skip
Etap $skip umożliwia pominięcie określonej liczby dokumentów w wynikach. Najczęściej używany jest po etapie grupowania. Na przykład, jeśli spodziewamy się dwóch dokumentów, ale pominiemy jeden, agregacja zwróci tylko drugi dokument.
Aby dodać etap pominięcia, wstaw operację $skip do potoku:
...,
{
$skip: 1
},
Etap $sort
Etap $sort umożliwia uporządkowanie danych w porządku rosnącym lub malejącym. Na przykład, możemy posortować dane z poprzedniego przykładu w kolejności malejącej, aby zobaczyć, która sekcja ma największą sprzedaż.
Dodajmy operator $sort do wcześniejszego zapytania:
...,
{
$sort: {top_sales: -1}
},
Etap $limit
Operacja $limit ogranicza liczbę dokumentów wyjściowych w potoku agregacji. Na przykład, użyjemy operatora $limit, aby uzyskać sekcję o najwyższej sprzedaży, która została zwrócona w poprzednim kroku:
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
Powyższe zwróci tylko pierwszy dokument, czyli sekcję z najwyższą sprzedażą.
Etap $project
Etap $project pozwala na dostosowanie struktury dokumentu wyjściowego. Używając operatora $project, możemy określić, które pola mają zostać uwzględnione w wynikach, a także zmienić ich nazwy.
Przykładowy wynik bez etapu $project wygląda następująco:
Zobaczmy jak to wygląda po zastosowaniu etapu $project. Aby dodać projekt $ do potoku:
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Ponieważ wcześniej zgrupowaliśmy dane według sekcji produktów, powyższe zachowuje każdą sekcję w wynikach. Dodatkowo, zmienia nazwy zagregowanych wartości na `TotalSold` i `TopSale`, co poprawia czytelność.
Finalny wynik jest znacznie bardziej przejrzysty:

Etap $unwind
Etap $unwind rozdziela tablicę w dokumencie na pojedyncze dokumenty. Weźmy na przykład dane dotyczące zamówień:
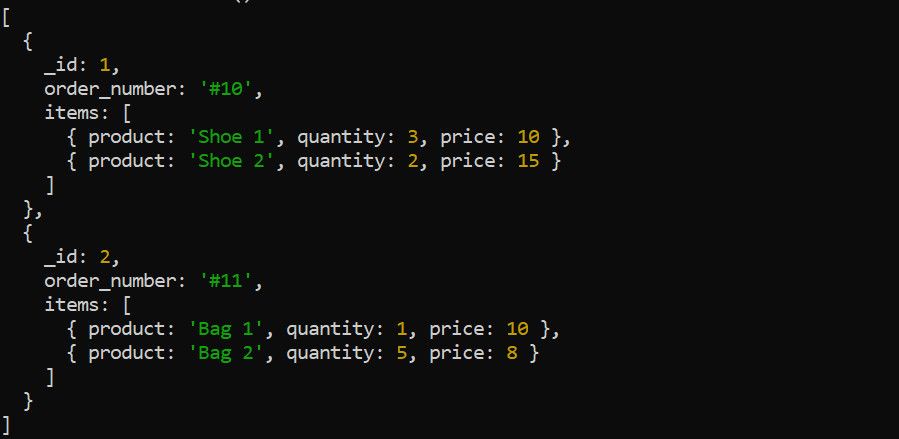
Użyjemy etapu $unwind, aby rozbić tablicę `items`, co ułatwi dalszą agregację. Rozwijanie tablicy `items` ma sens, jeśli chcemy obliczyć całkowity przychód dla każdego produktu:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Oto wynik powyższego zapytania:

Jak Utworzyć Potok Agregacji w MongoDB
Potok agregacji może zawierać wiele operacji. Przedstawione wcześniej etapy i przykłady pokazują, jak z nich korzystać, łącznie z podstawowymi zapytaniami dla każdego z nich.
Korzystając z poprzednich danych sprzedażowych, połączymy kilka etapów, aby pokazać, jak działa cały potok agregacji:
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
Ostateczny wynik jest podobny do tego, co widzieliśmy wcześniej:
Potok Agregacji vs MapReduce
Przed wprowadzeniem potoku agregacji, MapReduce było tradycyjnym sposobem agregowania danych w MongoDB. MapReduce ma zastosowanie nie tylko w MongoDB, ale jest mniej wydajne niż potok agregacji i wymaga użycia oddzielnego skryptu do mapowania i redukcji danych.
Potok agregacji jest specyficzny dla MongoDB i zapewnia wydajniejsze i łatwiejsze podejście do złożonych zapytań. Oprócz prostoty i skalowalności zapytań, poszczególne etapy potoku dają większą kontrolę nad formą danych wyjściowych.
Istnieje wiele różnic między potokiem agregacji a MapReduce. Zauważysz je, gdy przejdziesz z MapReduce na potok agregacji.
Efektywne Zapytania Big Data w MongoDB
Aby przeprowadzić zaawansowane obliczenia na złożonych danych w MongoDB, zapytanie musi być jak najbardziej efektywne. Potok agregacji jest idealny do takich zadań. Zamiast manipulować danymi w osobnych operacjach, co obniża wydajność, agregacja pozwala na zebranie ich w jednym wydajnym potoku i wykonanie ich naraz.
Chociaż potok agregacji jest wydajniejszy niż MapReduce, możemy dodatkowo zwiększyć wydajność, indeksując dane. Ograniczy to ilość danych, które MongoDB musi skanować na każdym etapie agregacji.
newsblog.pl