Automatyczne pobieranie danych ze stron internetowych, czyli tak zwany web scraping, to skuteczne narzędzie do szybkiego pozyskiwania ogromnych ilości informacji. Metoda ta jest szczególnie przydatna, kiedy strony internetowe nie udostępniają danych w uporządkowanej formie poprzez interfejsy API (Application Programming Interfaces).
Wyobraź sobie, że tworzysz aplikację, która porównuje ceny różnych produktów w sklepach internetowych. Jak do tego podejdziesz? Jednym ze sposobów jest ręczne sprawdzanie cen w każdym ze sklepów i zapisywanie wyników. Nie jest to jednak optymalne rozwiązanie, ponieważ platformy e-commerce oferują tysiące produktów, a ręczne wyszukiwanie i zapisywanie danych zajęłoby bardzo dużo czasu.
Znacznie lepszym rozwiązaniem jest wykorzystanie web scrapingu. Polega on na automatycznym wydobywaniu danych ze stron internetowych za pomocą specjalnego oprogramowania.
Do pobierania danych ze stron internetowych używane są skrypty, określane mianem web scraperów. Pobierają one nieuporządkowane dane, które następnie mogą być analizowane i przechowywane w uporządkowany sposób, przyjazny dla użytkownika.
Web scraping jest niezwykle cenny w kontekście ekstrakcji danych, ponieważ umożliwia dostęp do dużych ilości informacji i automatyzację procesu. Skrypty mogą być zaplanowane do działania w określonych interwałach czasowych lub reagować na określone zdarzenia. Dodatkowo, web scraping umożliwia pozyskiwanie danych w czasie rzeczywistym i wspiera badania rynkowe.

Wiele firm i przedsiębiorstw wykorzystuje web scraping do pozyskiwania danych, które następnie są poddawane analizie. Firmy z branż takich jak HR, e-commerce, finanse, nieruchomości, turystyka, media społecznościowe oraz nauka wykorzystują tę metodę do ekstrakcji istotnych informacji ze stron internetowych.
Nawet Google korzysta z web scrapingu do indeksowania stron internetowych, co pozwala mu dostarczać użytkownikom trafne wyniki wyszukiwania.
Podczas korzystania z web scrapingu należy jednak zachować ostrożność. Choć pozyskiwanie publicznie dostępnych danych samo w sobie nie jest nielegalne, to niektóre strony internetowe wyraźnie tego zabraniają. Może to wynikać z faktu, że zawierają one wrażliwe dane użytkowników, a ich regulaminy zabraniają web scrapingu, lub też strony chronią w ten sposób swoją własność intelektualną.
Dodatkowo, niektóre strony mogą nie zezwalać na web scraping, gdyż może on przeciążyć serwer strony i zwiększyć koszty przepustowości, szczególnie gdy proces ten przeprowadzany jest na dużą skalę.
Aby sprawdzić, czy dana strona pozwala na web scraping, należy do adresu URL strony dodać plik robots.txt. Zawiera on wytyczne dla botów, które elementy strony mogą zostać pobrane. Przykładowo, by sprawdzić, czy można scrapować Google, należy wejść na adres google.com/robots.txt.
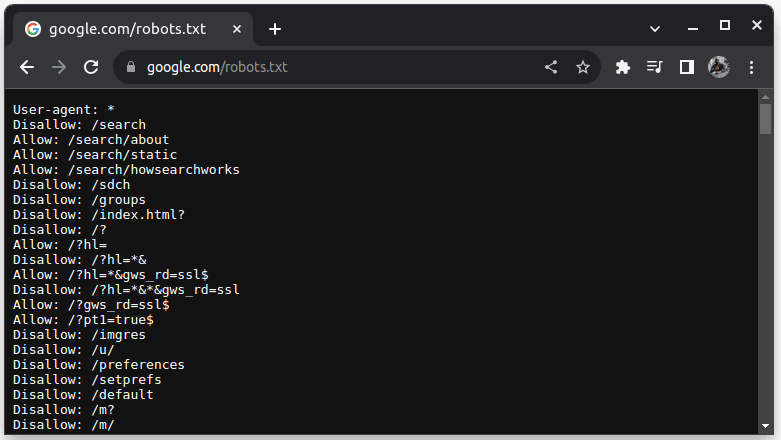
Wpis „User-agent: *” odnosi się do wszystkich botów, skryptów i robotów indeksujących. Polecenie „Disallow” informuje boty, że nie mogą uzyskiwać dostępu do żadnego adresu URL w danym katalogu (np. /search). Natomiast „Allow” wskazuje katalogi, do których dostęp jest dozwolony.
Przykładem witryny, która nie zezwala na scraping, jest LinkedIn. By sprawdzić, czy możemy scrapować LinkedIn, należy wejść na adres linkedin.com/robots.txt.
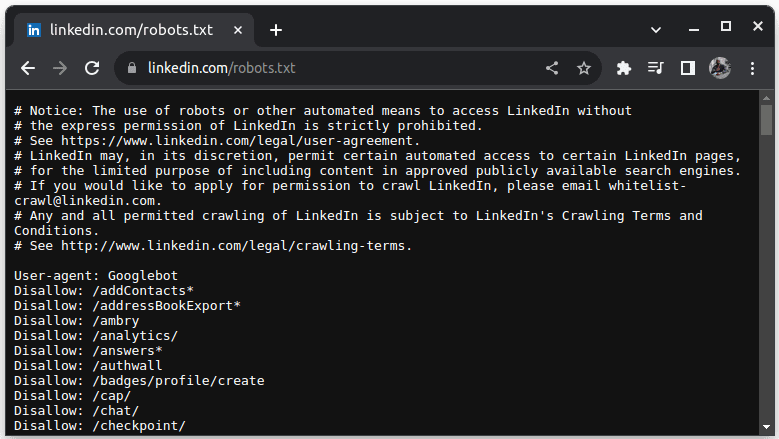
Jak widać, nie można scrapować LinkedIn bez ich zgody. Dlatego zawsze należy sprawdzać, czy dana witryna pozwala na scraping, aby uniknąć potencjalnych problemów prawnych.
Dlaczego Java jest odpowiednim językiem do web scrapingu?
Choć skrypty do web scrapingu można tworzyć w różnych językach programowania, Java jest szczególnie polecana do tego zadania z kilku powodów. Po pierwsze, Java charakteryzuje się rozbudowanym ekosystemem, dużą społecznością i oferuje wiele bibliotek dedykowanych web scrapingowi, takich jak JSoup, WebMagic i HTMLUnit. Ułatwiają one pisanie scraperów.

Ponadto, Java udostępnia biblioteki do parsowania HTML, które upraszczają proces wyodrębniania danych z dokumentów HTML, oraz biblioteki sieciowe, takie jak HttpURLConnection, do wysyłania zapytań do różnych adresów URL stron internetowych.
Silne wsparcie dla współbieżności i wielowątkowości w Javie jest również atutem w przypadku web scrapingu. Umożliwia to równoległe przetwarzanie i obsługę wielu zadań, co pozwala na pobieranie wielu stron jednocześnie. Skalowalność to kolejna istotna zaleta Javy – scraper napisany w tym języku pozwoli na swobodne przeglądanie stron internetowych na dużą skalę.
Wieloplatformowość Javy to kolejna zaleta. Skrypty napisane w Javie można uruchomić w każdym systemie wyposażonym w kompatybilną wirtualną maszynę Javy. Oznacza to, że skrypty mogą być tworzone i uruchamiane w różnych systemach operacyjnych bez konieczności ich modyfikacji.
Java może być również wykorzystywana w tzw. przeglądarkach bezgłowych, takich jak Headless Chrome, HTML Unit, Headless Firefox i PhantomJs. Przeglądarka bezgłowa to przeglądarka bez graficznego interfejsu użytkownika. Może ona symulować interakcje użytkownika, co jest niezwykle przydatne podczas scrapowania stron wymagających interakcji użytkownika.
Podsumowując, Java jest popularnym i szeroko stosowanym językiem, który jest wspierany i może być łatwo zintegrowany z różnymi narzędziami, takimi jak bazy danych i platformy przetwarzania danych. Gwarantuje to, że podczas web scrapingu wszystkie potrzebne narzędzia będą kompatybilne z Javą.
Zobaczmy, jak możemy wykorzystać Javę do web scrapingu.
Java do web scrapingu: wymagania wstępne
Aby móc korzystać z Javy do web scrapingu, należy spełnić następujące warunki:
1. Java – powinieneś mieć zainstalowaną Javę, najlepiej najnowszą wersję z długoterminowym wsparciem. Jeśli nie masz zainstalowanej Javy, sprawdź instrukcję instalacji.
2. Zintegrowane środowisko programistyczne (IDE) – powinieneś mieć zainstalowane IDE. W tym przykładzie użyjemy IntelliJ IDEA, ale możesz użyć dowolnego innego.
3. Maven – będzie używany do zarządzania zależnościami i instalowania bibliotek do web scrapingu.
Jeśli nie masz zainstalowanego Mavena, możesz go zainstalować za pomocą terminala, wpisując:
sudo apt install maven
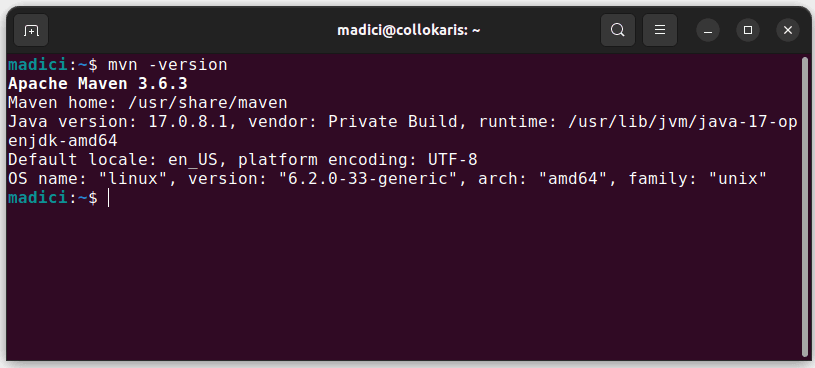
Spowoduje to instalację Mavena z oficjalnego repozytorium. Możesz potwierdzić, że Maven został poprawnie zainstalowany, wpisując:
mvn -version
Jeśli instalacja przebiegła pomyślnie, powinieneś zobaczyć podobny wynik:
Konfiguracja środowiska
Aby skonfigurować środowisko:
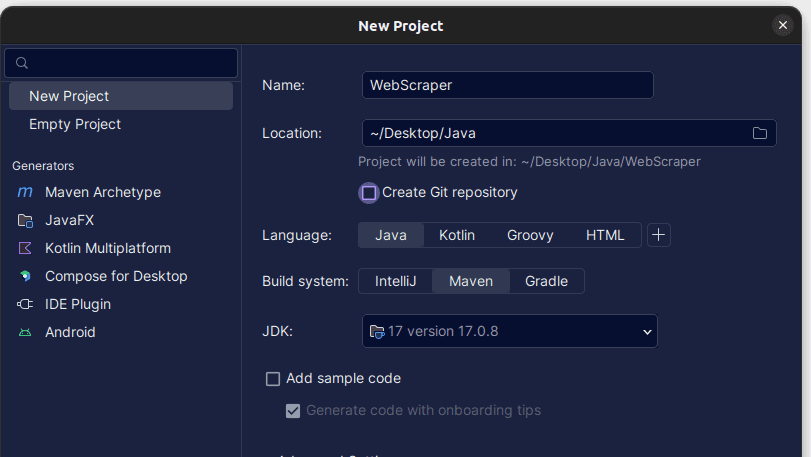
1. Uruchom IntelliJ IDEA. W menu po lewej stronie kliknij „Projects”, a następnie wybierz „New Project”.
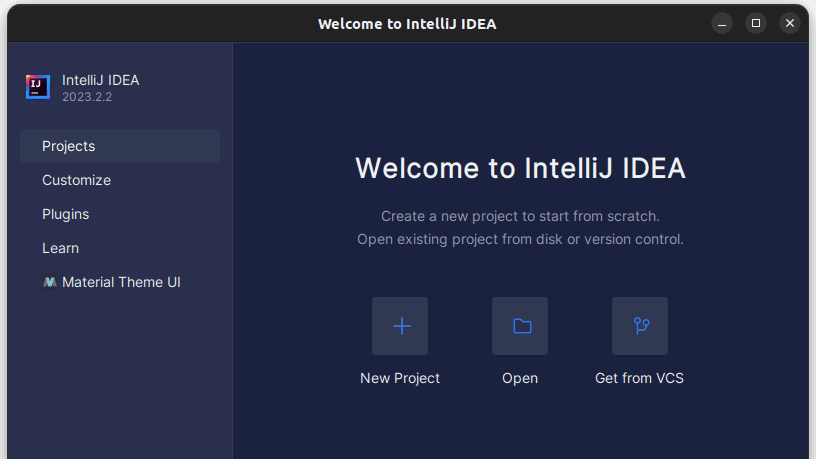
2. W oknie „New Project” wypełnij formularz w sposób przedstawiony na poniższym zrzucie. Upewnij się, że „Language” ustawione jest na „Java”, a „Build system” na „Maven”. Możesz nadać projektowi dowolną nazwę i wybrać folder, w którym projekt ma być utworzony. Następnie kliknij „Create”.
3. Po utworzeniu projektu powinieneś zobaczyć w nim plik pom.xml.
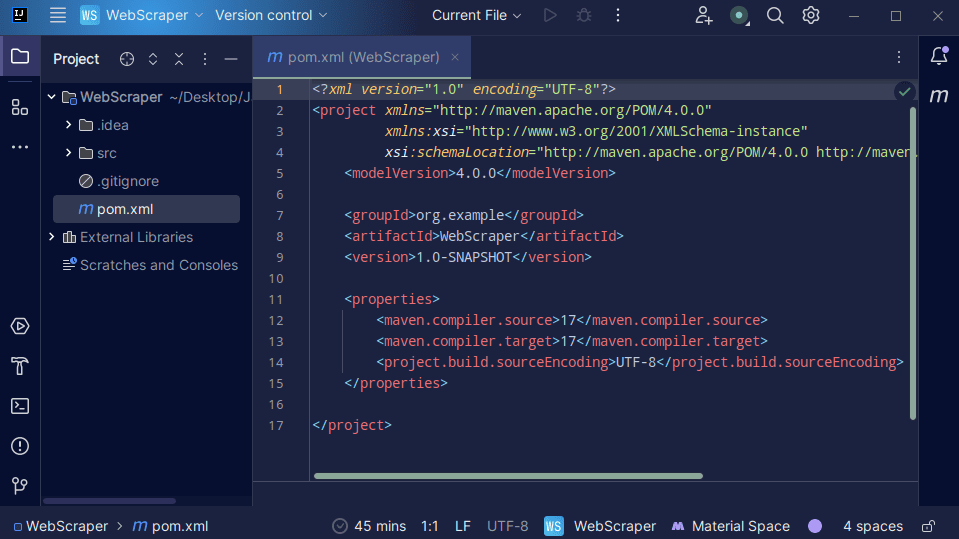
Plik pom.xml jest tworzony przez Mavena i zawiera informacje o projekcie oraz szczegóły konfiguracji, które Maven wykorzystuje do budowania projektu. Użyjemy tego pliku do zdefiniowania, z których bibliotek zewnętrznych będziemy korzystać.
Do stworzenia web scrapera użyjemy biblioteki jsoup. Musimy więc dodać ją jako zależność w pliku pom.xml.
4. Dodaj zależność jsoup do pliku pom.xml, kopiując poniższy kod i wklejając go do pliku pom.xml.
<dependencies>
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
Wynik powinien wyglądać tak:
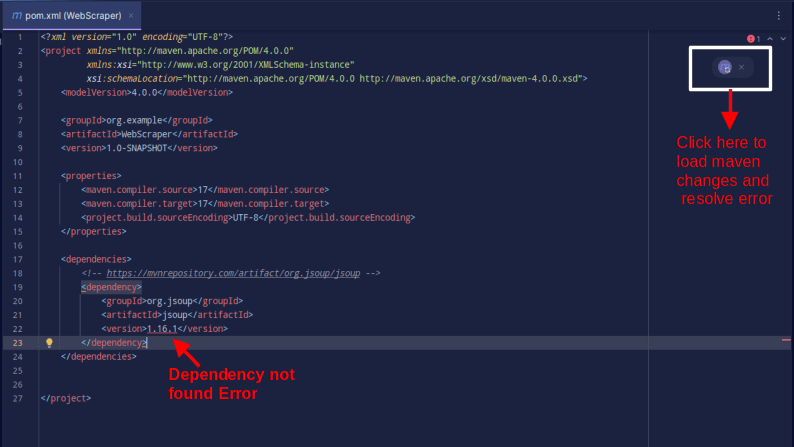
Jeśli pojawi się błąd informujący o niemożności znalezienia zależności, kliknij ikonę, która pojawi się obok, aby Maven załadował wprowadzone zmiany, pobrał zależność i naprawił błąd.
W tym momencie środowisko jest w pełni skonfigurowane.
Web scraping z użyciem Javy
W celu przetestowania web scrapingu, pobierzemy dane ze strony ScrapeThisSite, która udostępnia „piaskownicę”, gdzie programiści mogą ćwiczyć web scraping bez obaw o problemy prawne.
Aby scrapować stronę internetową za pomocą Javy:
1. W menu po lewej stronie IntelliJ otwórz katalog src, następnie katalog main, znajdujący się w katalogu src. Katalog main zawiera katalog Java. Kliknij go prawym przyciskiem myszy, wybierz „New”, a następnie „Java Class”.
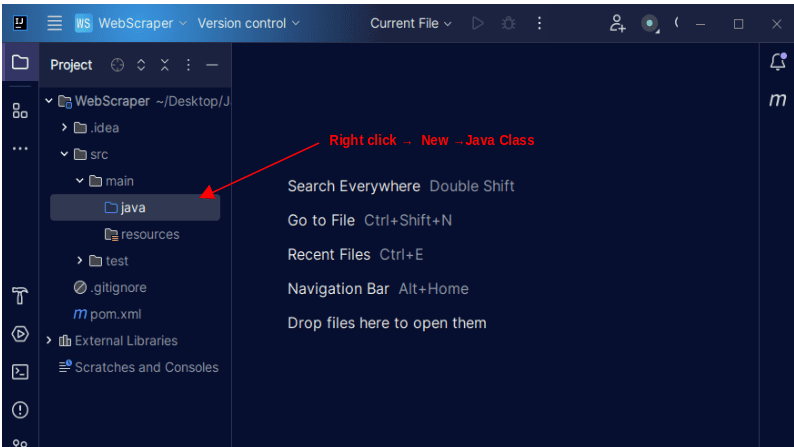
Nadaj klasie dowolną nazwę, na przykład WebScraper, i naciśnij klawisz Enter, aby utworzyć nową klasę Java.
Otwórz utworzony właśnie plik z klasą Java.
2. Web scraping polega na pobieraniu danych ze stron internetowych. Musimy więc najpierw określić adres URL strony, z której chcemy pobrać dane. Po ustaleniu adresu URL musimy połączyć się z nim i wysłać żądanie GET, by pobrać zawartość HTML strony.
Poniżej znajduje się kod, który to realizuje:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
System.out.println(doc);
} catch (IOException e) {
System.out.println("Wystąpił błąd IOException. Spróbuj ponownie.");
}
}
}
Wyjście:
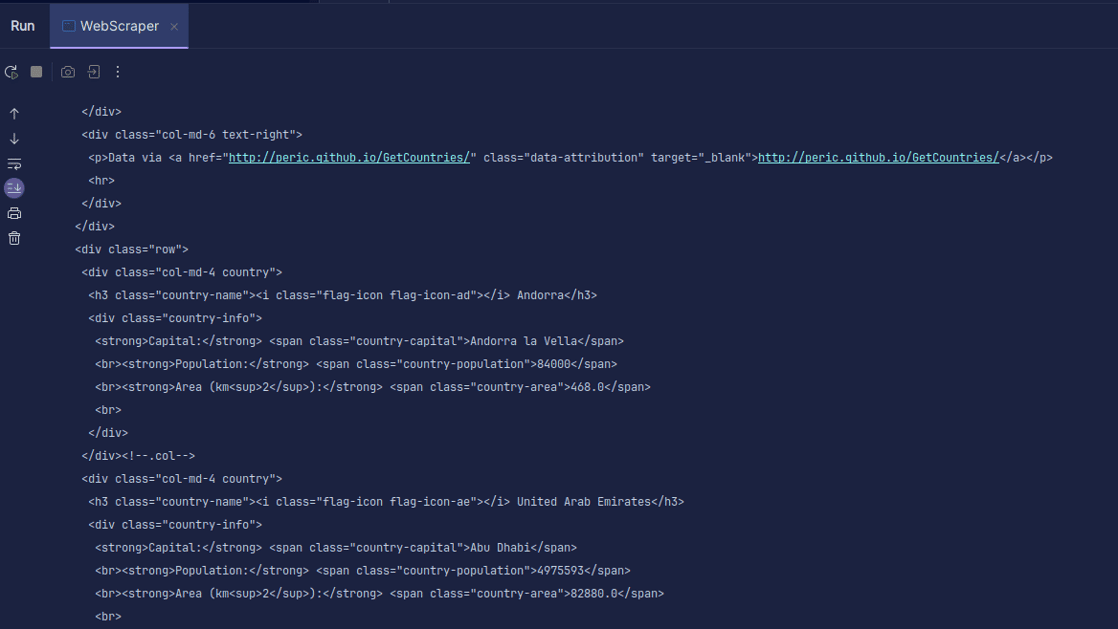
Jak widać, otrzymujemy kod HTML strony, który następnie drukujemy. Podczas scrapowania adres URL może zawierać błąd, a zasób, który próbujemy scrapować, może nie istnieć. Dlatego nasz kod umieszczamy w bloku try-catch.
Linia:
Document doc = Jsoup.connect(url).get();
służy do połączenia się z adresem URL. Metoda get() wysyła żądanie GET i pobiera kod HTML strony. Wynik zostaje zapisany w obiekcie doc typu Document JSOUP. Dzięki temu możemy manipulować pobranym kodem HTML za pomocą interfejsu API JSOUP.
3. Przejdź do ScrapeThisSite i przyjrzyj się strukturze strony. W kodzie HTML powinna być widoczna struktura przedstawiona poniżej:
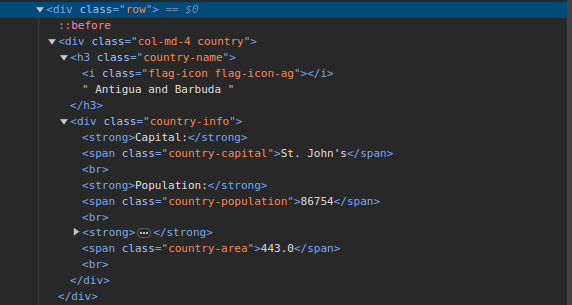
Zwróć uwagę, że wszystkie kraje na stronie mają podobną strukturę. Każdy kraj znajduje się w elemencie div z klasą „country”, a jego nazwa w elemencie h3 z klasą „country-name”.
Wewnątrz elementu div z klasą „country” znajduje się inny element div z klasą „country-info”, zawierający informacje, takie jak stolica, liczba ludności i powierzchnia kraju. Możemy użyć tych nazw klas do wyboru elementów HTML i wydobycia z nich danych.
4. Wydobycie konkretnych informacji z kodu HTML strony umożliwia poniższy kod:
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Populacja - " + population);
}
Metoda select() służy do wybierania elementów HTML pasujących do selektora CSS, który do niej przekazujemy. W naszym przypadku przekazujemy nazwy klas. Analizując strukturę strony, widzimy, że informacje o krajach są zapisane w elemencie div z klasą „country”.
Każdy kraj ma swój div z klasą „country”, zawierający takie informacje jak nazwa, stolica i populacja.
Najpierw wybieramy wszystkie kraje na stronie za pomocą selektora „.country”. Następnie zapisujemy to w zmiennej countries typu Elements (działa ona jak lista). Potem za pomocą pętli for przechodzimy przez wszystkie kraje, wydobywamy nazwę, stolicę i populację, po czym drukujemy te informacje.
Poniżej znajduje się cały kod:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.select.Elements;
import org.jsoup.nodes.Element;
import java.io.IOException;
public class WebScraper {
public static void main(String[] args) {
String url = "https://www.scrapethissite.com/pages/simple/";
try {
Document doc = Jsoup.connect(url).get();
Elements countries = doc.select(".country");
for (Element country : countries) {
String countryName = country.select(".country-name").text();
String capitalCity = country.select(".country-capital").text();
String population = country.select(".country-population").text();
System.out.println(countryName + " - " + capitalCity + " - Populacja - " + population);
}
} catch (IOException e) {
System.out.println("Wystąpił błąd IOException. Spróbuj ponownie.");
}
}
}
Wyjście:
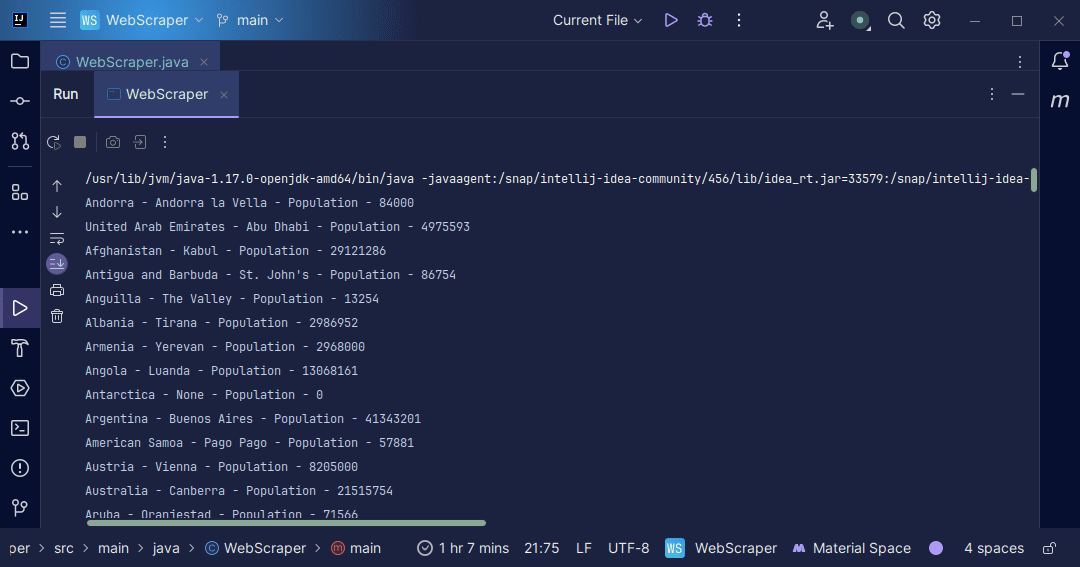
Z informacjami pozyskanymi ze strony możemy zrobić wiele rzeczy, np. wydrukować je na ekranie lub zapisać do pliku, aby dalej przetwarzać dane.
Podsumowanie
Web scraping to doskonała metoda wydobywania nieuporządkowanych danych ze stron internetowych, zapisywania ich w uporządkowany sposób i przetwarzania w celu uzyskania cennych informacji. Należy jednak pamiętać, że nie wszystkie strony internetowe pozwalają na web scraping, dlatego zawsze trzeba zachować ostrożność.
By być bezpiecznym, korzystaj ze stron, które udostępniają piaskownice do ćwiczenia web scrapingu. W przeciwnym razie zawsze sprawdzaj plik robots.txt witryny, którą chcesz scrapować, by upewnić się, że strona na to pozwala.
Java to doskonały język do tworzenia web scraperów, ponieważ oferuje biblioteki, które czynią ten proces łatwiejszym i bardziej wydajnym. Jeśli jesteś programistą Javy, stworzenie własnego web scrapera pomoże Ci rozwinąć umiejętności. Spróbuj napisać własnego scrapera lub zmodyfikować ten przedstawiony w artykule, by wydobywać inne rodzaje danych. Miłego kodowania!
Możesz również zapoznać się z popularnymi rozwiązaniami do web scrapingu w chmurze.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.