Sercem systemu Laravel Eloquent są modele i powiązania między nimi. Jeśli masz z nimi trudności lub poszukujesz jasnego i wyczerpującego przewodnika, to ten artykuł jest dla Ciebie idealnym punktem wyjścia!
Jako autor tekstów o tematyce programistycznej, łatwo jest mi kreować pozory eksperta i wyolbrzymiać wrażenie, jakie tworzy dana platforma. Jednak będę szczery – nauka Laravela początkowo sprawiła mi niemałe wyzwanie, głównie dlatego, że był to mój pierwszy framework tego kalibru. Dodatkowym utrudnieniem był fakt, że nie używałem go w pracy, a jedynie z czystej ciekawości. Zaczynałem, zagłębiałem się w temat, gubiłem wątek, rezygnowałem, aż w końcu zapominałem o wszystkim. Musiałem przez to przechodzić jakieś 5-6 razy, zanim zaczęło to mieć dla mnie sens (a dokumentacja nie ułatwiała sprawy).
Elementem, który wciąż sprawiał mi kłopot, był Eloquent, a konkretnie relacje między modelami (ponieważ zakres Eloquent jest zbyt rozległy, aby pojąć go od razu w całości). Przykłady modeli autorów i wpisów na blogach, które można spotkać w tutorialach, są mało reprezentatywne, gdyż realne projekty są znacznie bardziej złożone. Niestety, oficjalne dokumenty posługują się podobnymi, uproszczonymi przykładami. Nawet jeśli trafiłem na jakiś przydatny artykuł lub materiał, tłumaczenie było niejasne lub tak niepełne, że okazywało się bezużyteczne.
(Dodam, że spotkałem się już z krytyką za moje uwagi na temat oficjalnej dokumentacji. Jeśli podzielasz te zastrzeżenia, oto moja standardowa odpowiedź: najpierw rzuć okiem na dokumentację Django, a potem możemy porozmawiać.)
Ostatecznie, krok po kroku, wszystko zaczęło się łączyć i nabierać sensu. Wreszcie mogłem prawidłowo modelować projekty i swobodnie korzystać z modeli. Pewnego dnia odkryłem kilka ciekawych trików związanych z kolekcjami, które znacznie ułatwiły mi pracę. W tym tekście omówię wszystkie te aspekty, zaczynając od podstaw, a następnie przechodząc do różnych scenariuszy, z którymi możesz spotkać się w prawdziwych projektach.
Dlaczego relacje w modelach Eloquent są tak problematyczne?
Niestety, często spotykam programistów Laravel, którzy nie do końca rozumieją ideę modeli.
Ale dlaczego tak się dzieje?
Pomimo ogromnej liczby kursów, artykułów i filmów dotyczących Laravela, ogólne zrozumienie tematu nadal pozostawia wiele do życzenia. Uważam, że to ważna kwestia i warto się nad nią zastanowić.

Z mojego punktu widzenia, relacje modelowe w Eloquent nie są wcale skomplikowane, przynajmniej jeśli chodzi o definicję słowa „skomplikowane”. Trudne są migracje schematów na żywo, pisanie nowego silnika szablonów czy wprowadzenie zmian do jądra Laravel. W porównaniu z tym, nauka i stosowanie ORM . . . cóż, to nie może być trudne! 🤭🤭
W rzeczywistości, programiści PHP, którzy zaczynają przygodę z Laravelem, mają trudności z opanowaniem Eloquent. To jest sedno problemu, a według mnie składa się na to kilka czynników (przyznam, że to ostra, być może niepopularna opinia!):
- Przed Laravelem, większość programistów PHP pracowała w środowisku CodeIgniter (który nawiasem mówiąc nadal funkcjonuje, choć upodobnił się do Laravel/CakePHP). W starszej społeczności CodeIgniter (o ile taka istniała), „dobrą praktyką” było umieszczanie zapytań SQL bezpośrednio w kodzie, tam gdzie były potrzebne. Choć dzisiaj CodeIgniter doczekał się nowej odsłony, te nawyki pozostały. W efekcie, podczas nauki Laravela, idea ORM jest dla wielu programistów PHP czymś zupełnie nowym.
- Pomijając niewielki procent programistów PHP, którzy mieli do czynienia z frameworkami takimi jak Yii, CakePHP itp., reszta jest przyzwyczajona do pracy w czystym PHP lub środowisku typu WordPress. W takim przypadku brak myślenia w kategoriach OOP, a framework, kontener usług, wzorce projektowe, ORM . . . to wszystko obce koncepcje.
- W świecie PHP istnieje słaba kultura ciągłego uczenia się. Przeciętny programista zadowala się pracą z konfiguracjami opartymi na jednym serwerze, relacyjnych bazach danych i zapytaniami zapisanymi w postaci łańcuchów znaków. Programowanie asynchroniczne, gniazda sieciowe, HTTP 2/3, Linux (nie wspominając o Dockerze), testy jednostkowe, projektowanie oparte na domenie – to dla większości programistów PHP obce pojęcia. W rezultacie, napotykając Eloquent, nie zdarza się im czytać czegoś nowego tak długo, aż poczują się w tym komfortowo.
- Słabe jest też ogólne zrozumienie baz danych i modelowania danych. Ponieważ projektowanie baz danych jest ściśle i nierozerwalnie związane z modelami Eloquent, podnosi to poprzeczkę trudności.
Nie chcę być zbyt surowy i generalizować – jest też wielu znakomitych programistów PHP, ale ogólnie ich odsetek jest bardzo niski.
Jeśli to czytasz, to znaczy, że pokonałeś te przeszkody, natknąłeś się na Laravel i masz do czynienia z Eloquent.
Gratulacje! 👏
Jesteś już prawie na miejscu. Masz wszystkie elementy potrzebne do osiągnięcia sukcesu, musimy tylko ułożyć je we właściwej kolejności i omówić szczegółowo. Zacznijmy więc od podstaw, czyli od baz danych.
Modele baz danych: powiązania i liczność
Dla uproszczenia, załóżmy, że w tym tekście będziemy pracować tylko z relacyjnymi bazami danych. Jednym z powodów jest to, że ORM powstały pierwotnie z myślą o relacyjnych bazach danych, a drugim to fakt, że RDBMS nadal cieszą się ogromną popularnością.
Model danych
Najpierw postarajmy się zrozumieć, czym są modele danych. Idea modelu (a dokładniej modelu danych) ma swoje korzenie w bazach danych. Bez bazy danych nie ma danych, a tym samym nie ma modelu danych. Czym zatem jest model danych? To po prostu sposób, w jaki decydujesz się na przechowywanie i strukturyzację swoich danych. Przykładowo, w sklepie internetowym możesz przechowywać wszystkie informacje w jednej gigantycznej tabeli (co jest STRASZNĄ praktyką, ale niestety często spotykaną w świecie PHP). To byłby Twój model danych. Możesz też podzielić dane na 20 głównych i 16 tabel pomocniczych. To również będzie model danych.
Warto podkreślić, że struktura danych w bazie danych nie musi w 100% odzwierciedlać jej reprezentacji w ORM frameworka. Niemniej jednak, zawsze staramy się zachować jak największą spójność, aby podczas tworzenia oprogramowania nie musieć pamiętać o zbyt wielu rzeczach naraz.
Kardynalność
Wyjaśnijmy szybko również termin kardynalność. W prostym ujęciu odnosi się on do „liczenia”. Czyli 1, 2, 3. . . itd. wszystko to może być kardynalnością jakiejś rzeczy. Koniec tematu. Przejdźmy dalej!
Relacje
Gdy przechowujemy dane w jakimkolwiek systemie, dane te mogą być powiązane ze sobą w określony sposób. Wiem, że brzmi to nieco abstrakcyjnie i nudno, ale jeszcze chwilę wytrzymaj. Sposoby, w jakie łączymy ze sobą różne elementy danych, nazywamy relacjami. Zacznijmy od przykładów nie związanych z bazami danych, aby mieć pewność, że w pełni rozumiemy koncepcję.
- Jeśli przechowujemy wszystkie dane w tablicy, jednym z możliwych powiązań jest fakt, że następny element danych ma indeks większy od poprzedniego o 1.
- Jeśli dane przechowujemy w drzewie binarnym, jedną z możliwych zależności jest to, że lewe poddrzewo zawsze zawiera wartości mniejsze niż węzeł nadrzędny (jeśli zdecydujemy się tak zbudować nasze drzewo).
- Jeśli przechowujemy dane jako tablicę tablic o równej długości, możemy stworzyć macierz. W takim przypadku jej właściwości staną się powiązaniami dla naszych danych.
Widzimy więc, że w kontekście danych słowo „relacja” nie ma jednego, stałego znaczenia. W rzeczywistości, dwie osoby patrząc na ten sam zbiór danych, mogą zidentyfikować dwa zupełnie różne powiązania pomiędzy nimi (witajcie statystyki!) i oba te podejścia mogą być prawidłowe.
Relacyjne bazy danych
Bazując na wszystkich pojęciach, które omówiliśmy do tej pory, możemy w końcu przejść do czegoś, co ma bezpośredni związek z modelami w frameworku internetowym (Laravel) — relacyjnych baz danych. Dla większości z nas, podstawową bazą danych, której używamy jest MySQL, MariaDB, PostgreSQL, MSSQL, SQL Server, SQLite lub coś w tym stylu. Możemy też wiedzieć, że nazywa się je RDBMS, ale większość z nas zapomniała, co to właściwie oznacza i dlaczego ma to znaczenie.
„R” w RDBMS oczywiście oznacza relacyjny. Nie jest to przypadkowo wybrany termin. W ten sposób podkreśla się fakt, że te systemy baz danych zostały zaprojektowane do efektywnej pracy z relacjami pomiędzy przechowywanymi danymi. W rzeczywistości, „relacja” ma tutaj ścisłe znaczenie matematyczne i choć żaden programista nie musi o tym pamiętać, warto wiedzieć, że za tego typu bazami danych stoi solidna matematyczna podstawa.
Sprawdź te zasoby, aby dowiedzieć się więcej o SQL i NoSQL.
W porządku, z doświadczenia wiemy, że dane w RDBMS są przechowywane w tabelach. Gdzie zatem są relacje?
Rodzaje relacji w RDBMS
To prawdopodobnie najważniejsza część całej dyskusji na temat Laravela i relacji w modelach. Jeśli tego nie zrozumiesz, Eloquent nigdy nie będzie dla Ciebie jasny, więc proszę o skupienie przez kilka najbliższych minut (wcale nie jest to takie trudne).
RDBMS umożliwia nam tworzenie relacji między danymi – na poziomie bazy danych. Oznacza to, że te powiązania nie są ulotne, abstrakcyjne czy subiektywne i mogą być tworzone i wnioskowane przez różne osoby, z takim samym skutkiem.
Jednocześnie istnieją pewne możliwości i narzędzia w RDBMS, które pozwalają nam tworzyć i egzekwować te relacje, takie jak:
- Klucz podstawowy
- Klucz obcy
- Ograniczenia
Nie chcę, aby ten artykuł zmienił się w kurs baz danych, więc zakładam, że wiesz, czym są te pojęcia. Jeśli nie jesteś pewien swojej wiedzy w tym zakresie, polecam obejrzenie tego przystępnego filmu (zachęcam do zapoznania się z całą serią):

Okazuje się, że relacje w stylu RDBMS są również najczęściej spotykanymi relacjami w prawdziwych aplikacjach (choć nie zawsze, bo na przykład sieci społecznościowe najlepiej modelować jako grafy, a nie jako zbiór tabel). Przeanalizujmy je po kolei i spróbujmy zrozumieć, gdzie mogą być przydatne.
Relacja jeden do jednego
W niemal każdej aplikacji internetowej występują konta użytkowników. Ponadto, w przypadku użytkowników i kont prawdziwe są (na ogół) następujące stwierdzenia:
- Użytkownik może posiadać tylko jedno konto.
- Konto może należeć tylko do jednego użytkownika.
Oczywiście, można argumentować, że dana osoba może zarejestrować się na inny adres e-mail i w ten sposób utworzyć dwa konta, ale z perspektywy aplikacji internetowej są to dwie różne osoby z dwoma różnymi kontami. Aplikacja np. nie pokaże danych jednego konta na drugim.
Co to wszystko oznacza? Jeśli w swojej aplikacji masz taką sytuację i korzystasz z relacyjnej bazy danych, musisz zaprojektować ją jako relację jeden do jednego. Zwróć uwagę, że nikt Cię do tego sztucznie nie zmusza. W domenie biznesowej mamy do czynienia z jasną sytuacją, a tak się składa, że korzystasz z relacyjnej bazy danych. Tylko gdy oba te warunki są spełnione, powinieneś rozważyć relację jeden do jednego.
W tym przykładzie (użytkownicy i konta), relację tę możemy zaimplementować podczas tworzenia schematu w następujący sposób:
CREATE TABLE users(
id INT NOT NULL AUTO_INCREMENT,
email VARCHAR(100) NOT NULL,
password VARCHAR(100) NOT NULL,
PRIMARY KEY(id)
);
CREATE TABLE accounts(
id INT NOT NULL AUTO_INCREMENT,
role VARCHAR(50) NOT NULL,
PRIMARY KEY(id),
FOREIGN KEY(id) REFERENCES users(id)
);
Zauważ trik, który tu zastosowaliśmy? To dość rzadkie podczas tworzenia aplikacji, ale w tabeli kont ustawiamy identyfikator jako klucz podstawowy i jednocześnie klucz obcy! Właściwość klucza obcego łączy tabelę z tabelą użytkowników (oczywiście 🙄), podczas gdy klucz podstawowy sprawia, że kolumna id jest unikalna – to jest właśnie relacja jeden do jednego!
Warto zaznaczyć, że wierność tej relacji nie jest w 100% zagwarantowana. Na przykład, nic nie stoi na przeszkodzie, aby dodać 200 nowych użytkowników bez dodawania ani jednego rekordu do tabeli kont. Jeśli tak zrobimy, w efekcie będziemy mieć relację jeden do zera! 🤭🤭 Jednak w granicach samej struktury bazy danych jest to najlepsze, co możemy zrobić. Jeśli chcemy uniemożliwić dodawanie użytkowników bez kont, musimy użyć logiki programistycznej, na przykład w postaci wyzwalaczy bazy danych lub walidacji wymuszonej przez Laravel.

Jeśli zaczynasz odczuwać stres, mam dla Ciebie kilka dobrych rad:
- Zwolnij tempo. Tak bardzo, jak tego potrzebujesz. Zamiast próbować skończyć ten artykuł i 15 innych, które masz dodane do zakładek, skup się na nim. Niech to zajmie 3, 4, 5 dni, jeśli tego potrzebujesz. Twoim celem powinno być raz na zawsze pozbycie się problemów z relacjami w Eloquent. Skakałeś już od artykułu do artykułu, marnując setki godzin, i to nie pomogło. Zrób więc tym razem coś inaczej. 😇
- Chociaż ten artykuł dotyczy Laravel Eloquent, wszystko to ma miejsce znacznie później. Podstawą jest schemat bazy danych, więc powinniśmy skupić się na tym, aby najpierw dobrze go zaprojektować. Jeśli nie potrafisz pracować wyłącznie na poziomie bazy danych (zakładając, że nie ma żadnych frameworków), modele i relacje nigdy nie będą miały dla Ciebie pełnego sensu. Na razie zapomnij więc o Laravelu. Całkowicie. Na razie tylko mówimy i zajmujemy się projektowaniem baz danych. Tak, od czasu do czasu będę nawiązywał do Laravela, ale Twoim zadaniem jest całkowite ignorowanie tych odniesień, jeśli tylko sprawiają Ci trudności.
- Po jakimś czasie poczytaj trochę więcej o bazach danych i ich możliwościach. Indeksy, wydajność, wyzwalacze, podstawowe struktury danych i ich działanie, buforowanie, relacje w MongoDB . . . wszystkie te tematy pomogą Ci rozwinąć się jako inżynierowi. Pamiętaj, że modele w frameworkach to jedynie powłoka, a prawdziwa funkcjonalność aplikacji pochodzi z baz danych.
Relacja jeden do wielu
Nie jestem pewien, czy zdajesz sobie z tego sprawę, ale jest to rodzaj relacji, którą wszyscy intuicyjnie tworzymy w naszej codziennej pracy. Na przykład, kiedy tworzymy tabelę zamówień (hipotetyczny przykład) i przechowujemy w niej klucz obcy do tabeli użytkowników, tworzymy relację jeden do wielu między użytkownikami a zamówieniami. Dlaczego? Spójrz na to jeszcze raz z perspektywy tego, kto i ile może mieć: jeden użytkownik może złożyć wiele zamówień, i tak mniej więcej działa cały e-commerce. Patrząc z przeciwnej strony, relacja informuje, że zamówienie może należeć tylko do jednego użytkownika, co również ma sens.
W modelowaniu danych, podręcznikach RDBMS i dokumentacji systemowej sytuacja ta przedstawiana jest schematycznie w następujący sposób:

Widzisz trzy linie tworzące coś w rodzaju trójzęba? To symbol „wielu”, więc diagram ten mówi, że jeden użytkownik może mieć wiele zamówień.
Nawiasem mówiąc, te liczby „wiele” i „jeden”, z którymi spotykamy się wielokrotnie, to tak zwana liczność relacji (pamiętasz ten termin z poprzedniej sekcji?). Po raz kolejny, w kontekście tego artykułu, termin ten nie ma większego zastosowania, ale warto go poznać, aby nie być zaskoczonym, gdy pojawi się podczas rozmów kwalifikacyjnych lub w trakcie dalszej lektury.
Proste, prawda? A jeśli chodzi o rzeczywisty kod SQL, tworzenie takiej relacji też jest proste. W zasadzie jest to o wiele prostsze niż w przypadku relacji jeden do jednego!
CREATE TABLE users(
id INT NOT NULL AUTO_INCREMENT,
email VARCHAR(100) NOT NULL,
password VARCHAR(100) NOT NULL,
PRIMARY KEY(id)
);
CREATE TABLE orders(
id INT NOT NULL AUTO_INCREMENT,
user_id INT NOT NULL,
description VARCHAR(50) NOT NULL,
PRIMARY KEY(id),
FOREIGN KEY(user_id) REFERENCES users(id)
);
Tabela zamówień przechowuje identyfikatory użytkowników dla każdego zamówienia. Ponieważ nie ma ograniczenia (constraint), które wymagałoby unikalności identyfikatorów użytkowników w tabeli zamówień, możemy powtarzać jeden identyfikator wiele razy. To właśnie w ten sposób tworzymy relację jeden do wielu, a nie w oparciu o jakieś tajemne zaklęcia. Identyfikatory użytkowników są przechowywane w dość nieelegancki sposób w tabeli zamówień, a SQL sam w sobie nie ma pojęcia o relacjach jeden do wielu czy jeden do jednego. Jednak gdy przechowujemy dane w ten sposób, możemy myśleć o tej relacji jako jeden do wielu.

Mam nadzieję, że teraz ma to sens. A przynajmniej więcej sensu niż wcześniej. 😅 Pamiętaj, że jak wszystko, jest to kwestia praktyki i po 4-5 razach w realnych sytuacjach, nawet nie będziesz o tym myśleć.
Relacje wiele do wielu
Kolejnym rodzajem relacji, który spotykamy w praktyce, jest tak zwana relacja wiele do wielu. Po raz kolejny, zanim zaczniemy się martwić o frameworki czy bazy danych, pomyślmy o analogicznym przykładzie z życia: książki i autorzy. Pomyśl o swoim ulubionym autorze. Napisał więcej niż jedną książkę, prawda? Jednocześnie dość często zdarza się, że kilku autorów współpracuje nad jedną książką (przynajmniej w przypadku literatury faktu). Tak więc jeden autor może napisać wiele książek, a wielu autorów może napisać jedną książkę. Pomiędzy dwiema jednostkami (książką i autorem) tworzy się relacja wiele do wielu.
Ponieważ jest mało prawdopodobne, abyśmy tworzyli realną aplikację z bibliotekami, książkami i autorami, przyjrzyjmy się kilku innym przykładom. W ustawieniach B2B, producent zamawia towar od dostawcy i w zamian dostaje fakturę. Faktura będzie zawierać kilka pozycji, z których każda będzie zawierać ilość i dostarczony towar, np. rura 5-calowa x 200 sztuk itp. W tej sytuacji pozycje i faktury mają relację wiele do wielu (przeanalizuj to i przekonaj się sam). W systemie zarządzania flotą, pojazdy i kierowcy będą miały podobną relację. W serwisie e-commerce użytkownicy i produkty mogą mieć relacje wiele do wielu, jeśli weźmiemy pod uwagę takie funkcje, jak ulubione lub listy życzeń.
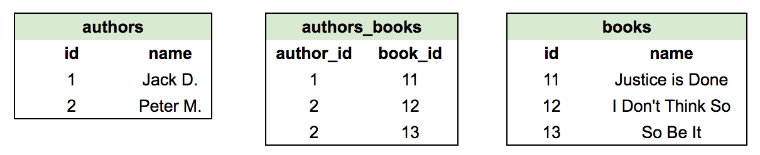
W porządku, jak stworzyć taką relację wiele do wielu w SQL? Opierając się na naszej wiedzy o działaniu relacji jeden do wielu, może nas kusić, aby umieszczać klucze obce do drugiej tabeli w obu tabelach. Jednak, jeśli spróbujemy to zrobić, napotkamy poważne problemy. Spójrz na ten przykład, gdzie autorzy książek powinni mieć relację wiele do wielu:

Na pierwszy rzut oka wszystko wydaje się w porządku – książki są przypisywane autorom, zgodnie z zasadą wiele do wielu. Przyjrzyj się jednak bliżej danym w tabeli autorów: książki o numerach 12 i 13 zostały napisane przez Petera M. (identyfikator autora 2), dlatego musimy powtarzać te wpisy. Tabela autorów ma teraz nie tylko problemy z integralnością danych (właściwa normalizacja i tym podobne), ale wartości w kolumnie id są teraz powtarzane. Oznacza to, że w takim schemacie nie może istnieć kolumna klucza podstawowego (bo klucze podstawowe nie mogą mieć zduplikowanych wartości) i cała konstrukcja się rozpada.
Oczywiście potrzebujemy innego rozwiązania i na szczęście problem ten został już rozwiązany. Ponieważ przechowywanie kluczy obcych bezpośrednio w obu tabelach jest problematyczne, właściwym sposobem tworzenia relacji wiele do wielu w RDBMS jest utworzenie tzw. „tabeli łączącej”. Chodzi o to, aby zostawić dwie oryginalne tabele w spokoju i utworzyć trzecią tabelę, która będzie zawierać powiązania wiele do wielu.
Powtórzmy przykład, który nie zadziałał, aby uwzględnić tabelę łączącą:
Zauważ, że zaszły istotne zmiany:
- Zmniejszyła się liczba kolumn w tabeli autorów.
- Zmniejszyła się liczba kolumn w tabeli książek.
- Zmniejszyła się liczba wierszy w tabeli autorów, ponieważ nie musimy ich powtarzać.
- Pojawiła się nowa tabela o nazwie Authors_books, która zawiera informacje o tym, który identyfikator autora jest powiązany z którym identyfikatorem książki. Moglibyśmy nazwać tabelę łączącą jak chcemy, ale przyjęło się, że jej nazwa to połączenie nazw dwóch tabel, które reprezentuje, z użyciem podkreślenia.
Tabela łącząca nie ma klucza podstawowego i w większości przypadków zawiera tylko dwie kolumny – identyfikatory z dwóch tabel. Jest to prawie tak, jakbyśmy usunęli kolumny klucza obcego z naszego poprzedniego przykładu i wkleili je do nowej tabeli. Ponieważ nie ma klucza podstawowego, możemy mieć tyle powtórzeń, ile potrzebujemy, aby zarejestrować wszystkie powiązania.
Teraz możemy zobaczyć na własne oczy, jak tabela łącząca wyraźnie prezentuje relacje, ale jak uzyskać do nich dostęp w naszych aplikacjach? Odpowiedź tkwi w jej nazwie – tabela łącząca. Nie jest to kurs dotyczący zapytań SQL, więc nie będę w to wchodził, ale chodzi o to, że jeśli chcesz w jednym, wydajnym zapytaniu uzyskać wszystkie książki danego autora, musisz połączyć tabele SQL w następującej kolejności: -> autorzy, autorzy_książek i książki. Tabele Authors i Authors_books łączą się odpowiednio w kolumnach id i Author_id, natomiast tabele Authors_books i books łączą się w kolumnach book_id i id.

Wyczerpujące, prawda? Ale spójrz na to z pozytywnej strony – omówiliśmy całą niezbędną teorię i podstawy, które musimy znać, zanim przejdziemy do modeli Eloquent. Przypomnę, że nie jest to nic opcjonalnego! Nieznajomość zasad projektowania bazy danych na zawsze pozostawi Cię w sferze zamieszania w kwestii Eloquent. Co więcej, cokolwiek robi lub próbuje zrobić Eloquent, idealnie odzwierciedla te detale na poziomie bazy danych, więc łatwo zrozumieć, dlaczego próba nauki Eloquent przy jednoczesnym unikaniu RDBMS jest bezcelowa.
Tworzenie relacji w modelach Laravel Eloquent
Wreszcie, po podróży, która trwała mniej więcej 70 tysięcy mil, dotarliśmy do momentu, w którym możemy porozmawiać o Eloquent, jego modelach i sposobach ich tworzenia i używania. W poprzedniej części artykułu dowiedzieliśmy się, że wszystko zaczyna się od bazy danych i modelowania danych. Uświadomiło mi to, że powinienem użyć jednego, kompletnego przykładu, w którym od zera rozpoczynam nowy projekt. Jednocześnie chcę, aby ten przykład dotyczył realnego świata, a nie blogów i autorów, czy książek i półek (które też występują w realnym świecie, ale są już mocno wyeksploatowane).
Wyobraźmy sobie sklep sprzedający pluszowe zabawki. Załóżmy również, że mamy specyfikację wymagań, na podstawie której możemy zidentyfikować w systemie cztery podmioty: użytkowników, zamówienia, faktury, towary, kategorie, podkategorie i transakcje. Tak, prawdopodobnie wiąże się to z większymi komplikacjami, ale na razie odłóżmy je na bok i skupmy się na tym, jak przejść od specyfikacji do aplikacji.
Po zidentyfikowaniu głównych podmiotów w systemie musimy zastanowić się, w jaki sposób odnoszą się one do siebie pod względem relacji w bazach danych, o których rozmawialiśmy do tej pory. Oto relacje, które przychodzą mi do głowy:
- Użytkownicy i zamówienia: Jeden do wielu.
- Zamówienia i faktury: Jeden do jednego. Zdaję sobie sprawę, że ta relacja nie jest oczywista i w zależności od domeny biznesowej może występować relacja jeden do wielu, wiele do jednego lub wiele do wielu. Jednak w przypadku przeciętnego małego sklepu internetowego, jedno zamówienie jest powiązane tylko z jedną fakturą i odwrotnie.
- Zamówienia i przedmioty: wiele do wielu.
- Przedmioty i kategorie: Wiele do jednego. Znowu, nie tak jest w przypadku dużych serwisów e-commerce, ale prowadzimy małą działalność.
- Kategorie i podkategorie: jeden do wielu. Ponownie, większość rzeczywistych przykładów będzie temu przeczyć, ale hej, Eloquent jest wystarczająco trudny, więc nie komplikujmy modelowania danych!
- Zamówienia i transakcje: jeden do wielu. Chciałbym też dodać dwa punkty na uzasadnienie mojego wyboru: 1) Mogliśmy też dodać relację między transakcjami a fakturami. To tylko kwestia decyzji dotyczącej modelowania danych. 2) Dlaczego jeden do wielu tutaj? Cóż, często zdarza się, że płatność za zamówienie nie powiedzie się z jakiegoś powodu, ale za drugim razem udaje się. W tym przypadku dla tego samego zamówienia mamy dwie transakcje. To, czy chcemy pokazać nieudane transakcje, czy nie, jest decyzją biznesową, ale dobrą praktyką jest rejestrowanie wszystkich istotnych danych.
Czy istnieją jakieś inne relacje? Cóż, możliwe jest wiele innych powiązań, ale nie są one praktyczne. Na przykład, moglibyśmy stwierdzić, że użytkownik ma wiele transakcji, więc powinna istnieć między nimi relacja. Należy jednak pamiętać, że istnieje już pośrednia relacja: użytkownicy -> zamówienia -> transakcje i ogólnie rzecz biorąc, jest ona wystarczająca, ponieważ RDBMS są potężne w łączeniu tabel. Po drugie, utworzenie tej relacji oznaczałoby dodanie kolumny user_id do tabeli transakcji. Gdybyśmy zrobili to dla każdej możliwej bezpośredniej relacji, znacznie zwiększylibyśmy obciążenie bazy danych (w postaci większej ilości miejsca, zwłaszcza w przypadku stosowania identyfikatorów UUID i konieczności utrzymywania indeksów), łącząc cały system. Jasne, jeśli firma twierdzi, że potrzebuje danych transakcyjnych w ciągu 1,5 sekundy,
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.