
Laravel to wiele rzeczy. Ale szybko nie jest jednym z nich. Nauczmy się kilku sztuczek handlowych, aby przyspieszyć!
Żaden programista PHP nie jest nietknięty Laravel w te dni. Są albo młodszymi lub średnimi programistami, którzy uwielbiają szybki rozwój oferowany przez Laravel, albo starszymi programistami, którzy są zmuszeni uczyć się Laravela z powodu presji rynkowej.
Tak czy inaczej, nie można zaprzeczyć, że Laravel ożywił ekosystem PHP (z pewnością opuściłbym świat PHP dawno temu, gdyby nie było Laravela).
Fragment (nieco uzasadnionej) samochwały Laravela
Ponieważ jednak Laravel robi wszystko, aby ułatwić ci życie, oznacza to, że pod spodem wykonuje mnóstwo pracy, aby zapewnić ci wygodne życie jako programista. Wszystkie „magiczne” funkcje Laravela, które wydają się działać, mają warstwy kodu, które należy aktualizować za każdym razem, gdy funkcja jest uruchamiana. Nawet prosty wyjątek śledzi, jak głęboka jest królicza nora (zwróć uwagę, gdzie zaczyna się błąd, aż do głównego jądra):
W przypadku czegoś, co wydaje się być błędem kompilacji w jednym z widoków, istnieje 18 wywołań funkcji do prześledzenia. Osobiście natknąłem się na 40, a może być ich więcej, jeśli używasz innych bibliotek i wtyczek.
Chodzi o to, że domyślnie te warstwy kodu spowalniają Laravel.
Jak wolny jest Laravel?
Szczerze mówiąc, odpowiedź na to pytanie jest po prostu niemożliwa z kilku powodów.
Po pierwsze, nie ma akceptowalnego, obiektywnego, rozsądnego standardu pomiaru szybkości aplikacji internetowych. Szybciej czy wolniej w porównaniu do czego? Pod jakimi warunkami?
Po drugie, aplikacja internetowa zależy od tak wielu rzeczy (bazy danych, systemu plików, sieci, pamięci podręcznej itp.), że mówienie o szybkości jest po prostu głupie. Bardzo szybka aplikacja internetowa z bardzo wolną bazą danych to bardzo wolna aplikacja internetowa. 🙂
Ale ta niepewność jest właśnie powodem popularności testów porównawczych. Nawet jeśli nic nie znaczą (por ten oraz ten), stanowią pewien punkt odniesienia i pomagają nam nie zwariować. Dlatego mając kilka szczypt soli gotowych, zdobądźmy błędne, przybliżone pojęcie o szybkości wśród frameworków PHP.
Idąc przez ten dość szanowany GitHub źródłooto porównanie frameworków PHP:
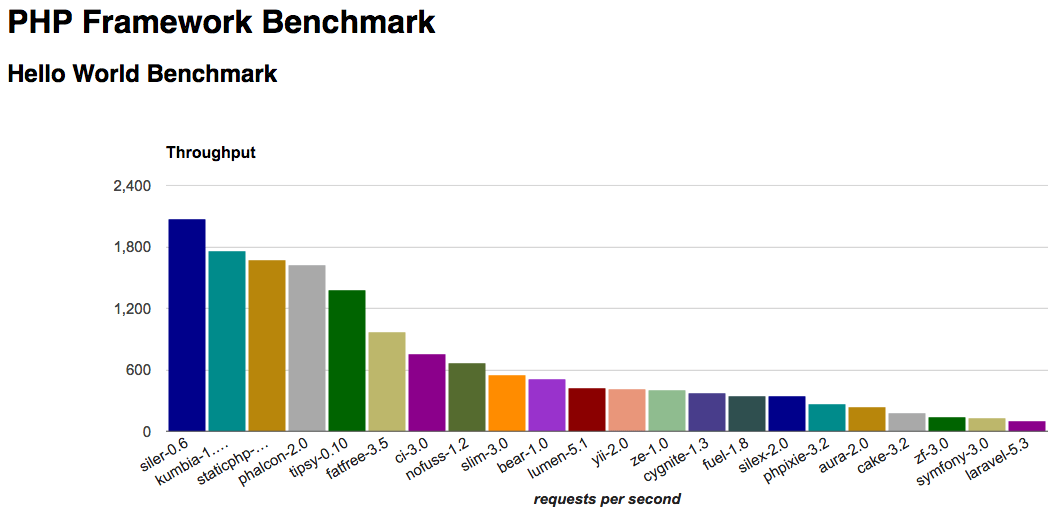
Możesz nawet nie zauważyć tutaj Laravela (nawet jeśli bardzo mocno zmrużysz oczy), chyba że rzucisz swoją skrzynkę na sam koniec ogona. Tak, drodzy przyjaciele, Laravel jest ostatni! To prawda, większość tych „frameworków” nie jest zbyt praktyczna ani nawet użyteczna, ale mówi nam, jak powolny jest Laravel w porównaniu z innymi, bardziej popularnymi.
Zwykle ta „powolność” nie występuje w aplikacjach, ponieważ nasze codzienne aplikacje internetowe rzadko osiągają wysokie wyniki. Ale kiedy już to zrobią (powiedzmy, powyżej 200-500 współbieżności), serwery zaczynają się dusić i umierać. To czas, kiedy nawet rzucanie większej ilości sprzętu nie rozwiązuje problemu, a rachunki za infrastrukturę rosną tak szybko, że Twoje wysokie ideały przetwarzania w chmurze padają w gruzy.

Ale hej, rozchmurz się! Ten artykuł nie jest o tym, czego nie można zrobić, ale o tym, co można zrobić. 🙂
Dobra wiadomość jest taka, że możesz zrobić wiele, aby Twoja aplikacja Laravel działała szybciej. Kilka razy szybko. Tak, nie żartuję. Możesz sprawić, że ta sama baza kodu zacznie działać balistycznie i zaoszczędzić kilkaset dolarów na rachunkach za infrastrukturę/hosting co miesiąc. Jak? Weźmy się za to.
Cztery rodzaje optymalizacji
Moim zdaniem optymalizację można przeprowadzić na czterech różnych poziomach (jeśli chodzi o aplikacje PHP, to znaczy):
- Poziom języka: Oznacza to, że używasz szybszej wersji języka i unikasz określonych funkcji/stylów kodowania w języku, który spowalnia Twój kod.
- Poziom ramowy: to są rzeczy, które omówimy w tym artykule.
- Poziom infrastruktury: Dostrajanie menedżera procesów PHP, serwera WWW, bazy danych itp.
- Poziom sprzętu: przejście do lepszego, szybszego i wydajniejszego dostawcy hostingu sprzętu.
Wszystkie te typy optymalizacji mają swoje miejsce (na przykład optymalizacja PHP-fpm jest dość krytyczna i potężna). Ale głównym tematem tego artykułu będą optymalizacje wyłącznie typu 2: te związane z frameworkiem.
Nawiasem mówiąc, numeracja nie ma żadnego uzasadnienia i nie jest to akceptowany standard. Właśnie je wymyśliłem. Proszę, nigdy nie cytujcie mnie i nie mówcie: „Potrzebujemy optymalizacji typu 3 na naszym serwerze”, bo inaczej wasz lider zespołu zabije was, znajdzie mnie, a potem zabije również mnie. 😀
A teraz wreszcie docieramy do ziemi obiecanej.
Spis treści:
Bądź świadomy n+1 zapytań do bazy danych
Problem z zapytaniem n+1 jest częstym problemem, gdy używane są ORM. Laravel ma swój potężny ORM o nazwie Eloquent, który jest tak piękny, tak wygodny, że często zapominamy patrzeć, co się dzieje.
Rozważmy bardzo częsty scenariusz: wyświetlenie listy wszystkich zamówień złożonych przez daną listę klientów. Jest to dość powszechne w systemach e-commerce i ogólnie we wszelkich interfejsach raportowania, w których musimy wyświetlić wszystkie encje powiązane z niektórymi encjami.
W Laravel możemy sobie wyobrazić funkcję kontrolera, która wykonuje to zadanie w następujący sposób:
class OrdersController extends Controller
{
// ...
public function getAllByCustomers(Request $request, array $ids) {
$customers = Customer::findMany($ids);
$orders = collect(); // new collection
foreach ($customers as $customer) {
$orders = $orders->merge($customer->orders);
}
return view('admin.reports.orders', ['orders' => $orders]);
}
}
Słodki! A co ważniejsze, eleganckie, piękne. 🤩🤩
Niestety, jest to katastrofalny sposób pisania kodu w Laravelu.
Dlatego.
Kiedy prosimy ORM o wyszukanie danych klientów, generowane jest takie zapytanie SQL:
SELECT * FROM customers WHERE id IN (22, 45, 34, . . .);
Czyli dokładnie tak, jak oczekiwano. W rezultacie wszystkie zwrócone wiersze są przechowywane w kolekcji $customers wewnątrz funkcji kontrolera.
Teraz przeglądamy każdego klienta jeden po drugim i otrzymujemy jego zamówienia. Spowoduje to wykonanie następującego zapytania. . .
SELECT * FROM orders WHERE customer_id = 22;
. . . tyle razy, ilu jest klientów.
Innymi słowy, jeśli potrzebujemy uzyskać dane zamówienia dla 1000 klientów, całkowita liczba wykonanych zapytań do bazy danych wyniesie 1 (do pobrania danych wszystkich klientów) + 1000 (do pobrania danych zamówienia dla każdego klienta) = 1001. To stąd nazwa n+1.
Czy możemy zrobić lepiej? Z pewnością! Używając tak zwanego szybkiego ładowania, możemy zmusić ORM do wykonania JOIN i zwrócenia wszystkich potrzebnych danych w jednym zapytaniu! Lubię to:
$orders = Customer::findMany($ids)->with('orders')->get();
Otrzymana struktura danych jest oczywiście strukturą zagnieżdżoną, ale dane zamówienia można łatwo wyodrębnić. Wynikowe pojedyncze zapytanie w tym przypadku wygląda mniej więcej tak:
SELECT * FROM customers INNER JOIN orders ON customers.id = orders.customer_id WHERE customers.id IN (22, 45, . . .);
Pojedyncze zapytanie jest oczywiście lepsze niż tysiąc dodatkowych zapytań. Wyobraź sobie, co by się stało, gdyby do przetworzenia było 10 000 klientów! Albo nie daj Boże, gdybyśmy chcieli też eksponować pozycje zawarte w każdym zamówieniu! Pamiętaj, nazwa tej techniki to „chętne ładowanie” i prawie zawsze jest to dobry pomysł.
Zachowaj konfigurację!
Jednym z powodów elastyczności Laravel jest mnóstwo plików konfiguracyjnych, które są częścią frameworka. Chcesz zmienić sposób/miejsce przechowywania obrazów?
Cóż, po prostu zmień plik config/filesystems.php (przynajmniej w chwili pisania). Chcesz pracować z wieloma sterownikami kolejek? Możesz je opisać w pliku config/queue.php. Właśnie policzyłem i odkryłem, że istnieje 13 plików konfiguracyjnych dla różnych aspektów frameworka, dzięki czemu nie będziesz rozczarowany bez względu na to, co chcesz zmienić.

Biorąc pod uwagę naturę PHP, za każdym razem, gdy pojawia się nowe żądanie WWW, Laravel budzi się, uruchamia wszystko i analizuje wszystkie te pliki konfiguracyjne, aby dowiedzieć się, jak tym razem zrobić coś inaczej. Tyle, że to głupie, jeśli nic się nie zmieniło przez ostatnie dni! Przebudowa konfiguracji na każde żądanie to marnotrawstwo, którego można (właściwie trzeba) uniknąć, a wyjściem jest proste polecenie, które oferuje Laravel:
php artisan config:cache
To, co robi, to połączenie wszystkich dostępnych plików konfiguracyjnych w jeden, a pamięć podręczna jest gdzieś do szybkiego pobierania. Następnym razem, gdy pojawi się żądanie sieciowe, Laravel po prostu przeczyta ten pojedynczy plik i zacznie działać.
To powiedziawszy, buforowanie konfiguracji jest niezwykle delikatną operacją, która może wybuchnąć ci w twarz. Największym problemem jest to, że po wydaniu tego polecenia funkcja env() wywołania ze wszystkich miejsc poza plikami konfiguracyjnymi zwrócą wartość null!
Ma to sens, kiedy się nad tym zastanowić. Jeśli korzystasz z buforowania konfiguracji, mówisz frameworkowi: „Wiesz co, myślę, że wszystko dobrze skonfigurowałem i jestem w 100% pewien, że nie chcę, żeby się zmieniały”. Innymi słowy, oczekujesz, że środowisko pozostanie statyczne, do czego służą pliki .env.
Powiedziawszy to, oto kilka żelaznych, świętych, niezniszczalnych zasad buforowania konfiguracji:
Ogranicz usługi ładowane automatycznie
Aby być pomocnym, Laravel ładuje mnóstwo usług po przebudzeniu. Są one dostępne w pliku config/app.php jako część klucza tablicy „providers”. Rzućmy okiem na to, co mam w moim przypadku:
/*
|--------------------------------------------------------------------------
| Autoloaded Service Providers
|--------------------------------------------------------------------------
|
| The service providers listed here will be automatically loaded on the
| request to your application. Feel free to add your own services to
| this array to grant expanded functionality to your applications.
|
*/
'providers' => [
/*
* Laravel Framework Service Providers...
*/
IlluminateAuthAuthServiceProvider::class,
IlluminateBroadcastingBroadcastServiceProvider::class,
IlluminateBusBusServiceProvider::class,
IlluminateCacheCacheServiceProvider::class,
IlluminateFoundationProvidersConsoleSupportServiceProvider::class,
IlluminateCookieCookieServiceProvider::class,
IlluminateDatabaseDatabaseServiceProvider::class,
IlluminateEncryptionEncryptionServiceProvider::class,
IlluminateFilesystemFilesystemServiceProvider::class,
IlluminateFoundationProvidersFoundationServiceProvider::class,
IlluminateHashingHashServiceProvider::class,
IlluminateMailMailServiceProvider::class,
IlluminateNotificationsNotificationServiceProvider::class,
IlluminatePaginationPaginationServiceProvider::class,
IlluminatePipelinePipelineServiceProvider::class,
IlluminateQueueQueueServiceProvider::class,
IlluminateRedisRedisServiceProvider::class,
IlluminateAuthPasswordsPasswordResetServiceProvider::class,
IlluminateSessionSessionServiceProvider::class,
IlluminateTranslationTranslationServiceProvider::class,
IlluminateValidationValidationServiceProvider::class,
IlluminateViewViewServiceProvider::class,
/*
* Package Service Providers...
*/
/*
* Application Service Providers...
*/
AppProvidersAppServiceProvider::class,
AppProvidersAuthServiceProvider::class,
// AppProvidersBroadcastServiceProvider::class,
AppProvidersEventServiceProvider::class,
AppProvidersRouteServiceProvider::class,
],
Jeszcze raz policzyłem i na liście jest 27 usług! Teraz możesz potrzebować ich wszystkich, ale jest to mało prawdopodobne.
Na przykład w tej chwili buduję REST API, co oznacza, że nie potrzebuję dostawcy usług sesji, dostawcy usług przeglądania itp. A ponieważ robię kilka rzeczy po swojemu i nie przestrzegam domyślnych ustawień frameworka , mogę również wyłączyć dostawcę usług uwierzytelniania, dostawcę usług paginacji, dostawcę usług tłumaczeniowych i tak dalej. W sumie prawie połowa z nich jest niepotrzebna w moim przypadku użycia.
Przyjrzyj się uważnie swojej aplikacji. Czy potrzebuje wszystkich tych usługodawców? Ale na litość boską, proszę, nie komentujcie ślepo tych usług i nie naciskajcie na produkcję! Przeprowadź wszystkie testy, sprawdź rzeczy ręcznie na maszynach programistycznych i testowych i bądź bardzo paranoikiem, zanim pociągniesz za spust. 🙂
Bądź rozsądny ze stosami oprogramowania pośredniego
Gdy potrzebujesz niestandardowego przetwarzania przychodzącego żądania sieciowego, odpowiedzią jest utworzenie nowego oprogramowania pośredniczącego. Teraz kuszące jest otwarcie app/Http/Kernel.php i umieszczenie oprogramowania pośredniego w stosie web lub api; w ten sposób staje się dostępny w całej aplikacji i jeśli nie robi czegoś uciążliwego (na przykład rejestrowania lub powiadamiania).
Jednak w miarę rozwoju aplikacji ta kolekcja globalnego oprogramowania pośredniego może stać się cichym obciążeniem dla aplikacji, jeśli wszystkie (lub większość) z nich są obecne w każdym żądaniu, nawet jeśli nie ma ku temu powodu biznesowego.
Innymi słowy, uważaj, gdzie dodajesz/stosujesz nowe oprogramowanie pośrednie. Dodanie czegoś globalnie może być wygodniejsze, ale na dłuższą metę spadek wydajności jest bardzo wysoki. Znam ból, który musiałbyś przejść, gdybyś miał selektywnie stosować oprogramowanie pośrednie za każdym razem, gdy pojawia się nowa zmiana, ale jest to ból, który chętnie zniosę i polecę!
Unikaj ORM (czasami)
Podczas gdy Eloquent sprawia, że wiele aspektów interakcji DB jest przyjemnych, dzieje się to kosztem szybkości. Będąc mapperem, ORM musi nie tylko pobierać rekordy z bazy danych, ale także tworzyć instancje obiektów modelu i uzupełniać je danymi z kolumn.
Tak więc, jeśli wykonasz prostą $users = User::all() i jest, powiedzmy, 10 000 użytkowników, framework pobierze 10 000 wierszy z bazy danych i wewnętrznie wykona 10 000 new User() i wypełni ich właściwości odpowiednimi danymi . To ogromna ilość pracy wykonywanej za kulisami, a jeśli baza danych jest miejscem, w którym aplikacja staje się wąskim gardłem, czasami dobrym pomysłem jest ominięcie ORM.
Jest to szczególnie prawdziwe w przypadku złożonych zapytań SQL, w których musiałbyś przeskakiwać wiele obręczy i pisać zamknięcia po zamknięciach, a mimo to uzyskać wydajne zapytanie. W takich przypadkach preferowane jest wykonanie DB::raw() i ręczne wpisanie zapytania.
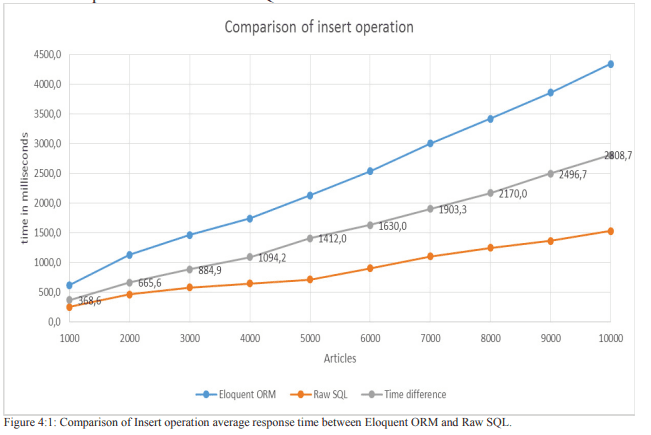
Przechodząc ten studium wykonania, nawet dla prostych wstawek Eloquent jest znacznie wolniejszy wraz ze wzrostem liczby rekordów:
Używaj buforowania w jak największym stopniu
Jedną z najlepiej strzeżonych tajemnic optymalizacji aplikacji internetowych jest buforowanie.
Dla niewtajemniczonych buforowanie oznacza wstępne obliczanie i przechowywanie kosztownych wyników (drogich pod względem wykorzystania procesora i pamięci) oraz po prostu zwracanie ich, gdy to samo zapytanie zostanie powtórzone.
Na przykład w sklepie e-commerce może się natknąć na 2 miliony produktów, przez większość czasu ludzie są zainteresowani tymi, które są świeżo zaopatrzone, w określonym przedziale cenowym i dla określonej grupy wiekowej. Wysyłanie zapytań do bazy danych w celu uzyskania tych informacji jest marnotrawstwem — ponieważ zapytanie nie zmienia się często, lepiej przechowywać te wyniki w miejscu, do którego mamy szybki dostęp.
Laravel ma wbudowaną obsługę kilku typów buforowanie. Oprócz używania sterownika buforowania i budowania systemu buforowania od podstaw, możesz chcieć użyć niektórych pakietów Laravel, które ułatwiają buforowanie modelu, buforowanie zapytańitp.
Należy jednak pamiętać, że poza pewnym uproszczonym przypadkiem użycia, gotowe pakiety pamięci podręcznej mogą powodować więcej problemów niż rozwiązywać.
Preferuj buforowanie w pamięci
Kiedy buforujesz coś w Laravel, masz kilka opcji, gdzie przechowywać wynikowe obliczenia, które muszą być buforowane. Opcje te są również znane jako sterowniki pamięci podręcznej. Tak więc, chociaż jest możliwe i całkowicie rozsądne używanie systemu plików do przechowywania wyników z pamięci podręcznej, tak naprawdę nie jest to buforowanie.
Najlepiej byłoby użyć pamięci podręcznej w pamięci (całkowicie znajdującej się w pamięci RAM), takiej jak Redis, Memcached, MongoDB itp., Aby przy większym obciążeniu buforowanie służyło istotnemu zastosowaniu, a nie samo w sobie było wąskim gardłem.
Teraz możesz pomyśleć, że posiadanie dysku SSD jest prawie takie samo jak używanie pamięci RAM, ale nie jest nawet blisko. Nawet nieformalne wzorce pokazują, że RAM przewyższa SSD 10-20 razy, jeśli chodzi o szybkość.
Moim ulubionym systemem jeśli chodzi o buforowanie jest Redis. Jego śmiesznie szybko (zwykłe jest 100 000 operacji odczytu na sekundę), a w przypadku bardzo dużych systemów pamięci podręcznej można przekształcić w grupa z łatwością.
Zachowaj trasy
Podobnie jak konfiguracja aplikacji, trasy nie zmieniają się zbytnio w czasie i są idealnym kandydatem do buforowania. Jest to szczególnie prawdziwe, jeśli nie możesz znieść dużych plików, tak jak ja, i kończysz na dzieleniu web.php i api.php na kilka plików. Pojedyncze polecenie Laravel zawiera wszystkie dostępne trasy i przechowuje je pod ręką, aby uzyskać do nich dostęp w przyszłości:
php artisan route:cache
A kiedy skończysz dodawać lub zmieniać trasy, po prostu wykonaj:
php artisan route:clear
Optymalizacja obrazu i CDN
Obrazy są sercem i duszą większości aplikacji internetowych. Przypadkowo są również największymi konsumentami przepustowości i jedną z głównych przyczyn powolnych aplikacji/stron internetowych. Jeśli po prostu naiwnie przechowujesz przesłane obrazy na serwerze i wysyłasz je z powrotem w odpowiedziach HTTP, pozwalasz, by przemknęła Ci ogromna szansa na optymalizację.
Moja pierwsza rekomendacja to nie przechowywanie obrazów lokalnie — istnieje problem utraty danych, z którym trzeba się uporać, a w zależności od regionu geograficznego, w którym znajduje się klient, transfer danych może być boleśnie powolny.
Zamiast tego wybierz rozwiązanie takie jak pochmurno który automatycznie zmienia rozmiar i optymalizuje obrazy w locie.
Jeśli nie jest to możliwe, użyj czegoś takiego jak Cloudflare do buforowania i udostępniania obrazów, gdy są one przechowywane na serwerze.
A jeśli nawet to nie jest możliwe, niewielka modyfikacja oprogramowania serwera WWW w celu skompresowania zasobów i skierowania przeglądarki odwiedzającego do buforowania rzeczy robi dużą różnicę. Oto jak wyglądałby fragment konfiguracji Nginx:
server {
# file truncated
# gzip compression settings
gzip on;
gzip_comp_level 5;
gzip_min_length 256;
gzip_proxied any;
gzip_vary on;
# browser cache control
location ~* .(ico|css|js|gif|jpeg|jpg|png|woff|ttf|otf|svg|woff2|eot)$ {
expires 1d;
access_log off;
add_header Pragma public;
add_header Cache-Control "public, max-age=86400";
}
}
Zdaję sobie sprawę, że optymalizacja obrazu nie ma nic wspólnego z Laravelem, ale jest to tak prosta i potężna sztuczka (i tak często jest zaniedbywana), że nie mogłem się powstrzymać.
Optymalizacja autoloadera
Automatyczne ładowanie to zgrabna, niezbyt stara funkcja w PHP, która prawdopodobnie uratowała język przed zagładą. To powiedziawszy, proces znajdowania i ładowania odpowiedniej klasy poprzez odszyfrowanie danego ciągu przestrzeni nazw jest czasochłonny i można go uniknąć we wdrożeniach produkcyjnych, w których pożądana jest wysoka wydajność. Po raz kolejny Laravel ma rozwiązanie tego problemu za pomocą jednego polecenia:
composer install --optimize-autoloader --no-dev
Zaprzyjaźnij się z kolejkami
Kolejki są sposobem przetwarzania rzeczy, gdy jest ich wiele, a ukończenie każdej z nich zajmuje kilka milisekund. Dobrym przykładem jest wysyłanie e-maili — powszechnym przypadkiem użycia w aplikacjach internetowych jest wysyłanie kilku e-maili z powiadomieniami, gdy użytkownik wykona jakieś działania.
Na przykład w przypadku nowo wprowadzonego produktu możesz chcieć, aby kierownictwo firmy (około 6-7 adresów e-mail) było powiadamiane za każdym razem, gdy ktoś złoży zamówienie powyżej określonej wartości. Zakładając, że Twoja brama e-mail może odpowiedzieć na żądanie SMTP w 500 ms, mówimy o dobrym 3-4 sekundowym oczekiwaniu na potwierdzenie zamówienia przez użytkownika. Naprawdę zły kawałek UX, jestem pewien, że będziesz Zgodzić się.
Rozwiązaniem jest przechowywanie zadań w miarę ich pojawiania się, informowanie użytkownika, że wszystko poszło dobrze, i przetwarzanie ich (kilka sekund) później. Jeśli wystąpi błąd, zadania w kolejce można ponawiać kilka razy, zanim zostaną uznane za zakończone niepowodzeniem.
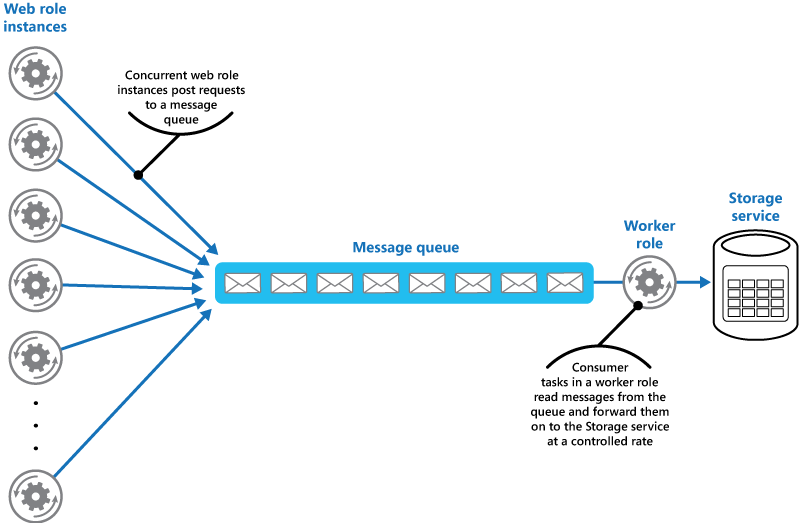 Kredyty: Microsoft.com
Kredyty: Microsoft.com
Chociaż system kolejkowania nieco komplikuje konfigurację (i dodaje trochę narzutu na monitorowanie), jest niezbędny w nowoczesnej aplikacji internetowej.
Optymalizacja zasobów (Laravel Mix)
W przypadku wszystkich zasobów front-end w Twojej aplikacji Laravel upewnij się, że istnieje potok, który kompiluje i minimalizuje wszystkie pliki zasobów. Ci, którzy czują się komfortowo z systemem pakującym, takim jak Webpack, Gulp, Parcel itp., Nie muszą się tym przejmować, ale jeśli jeszcze tego nie robisz, Mieszanka Laravela jest solidną rekomendacją.
Mix to lekkie (i zachwycające, szczerze mówiąc!) opakowanie Webpack, które zajmuje się wszystkimi twoimi plikami CSS, SASS, JS itp. do produkcji. Typowy plik .mix.js może być tak mały, jak ten i nadal czynić cuda:
const mix = require('laravel-mix');
mix.js('resources/js/app.js', 'public/js')
.sass('resources/sass/app.scss', 'public/css');
To automatycznie zajmuje się importem, minimalizacją, optymalizacją i całym shebangiem, gdy jesteś gotowy do produkcji i uruchamiasz npm run production. Mix dba nie tylko o tradycyjne pliki JS i CSS, ale także o komponenty Vue i React, które możesz mieć w swojej aplikacji.
Więcej informacji tutaj!
Wniosek
Optymalizacja wydajności to bardziej sztuka niż nauka — wiedza o tym, jak i ile należy zrobić, jest ważniejsza niż to, co należy zrobić. To powiedziawszy, nie ma końca, ile i co możesz zoptymalizować w aplikacji Laravel.
Ale cokolwiek robisz, chciałbym zostawić Ci pewną radę na pożegnanie — optymalizację należy przeprowadzać, gdy istnieje solidny powód, a nie dlatego, że brzmi to dobrze lub dlatego, że masz paranoję co do wydajności aplikacji dla ponad 100 000 użytkowników, podczas gdy w rzeczywistości jest tylko 10.
Jeśli nie jesteś pewien, czy potrzebujesz zoptymalizować swoją aplikację, nie musisz kopać przysłowiowego gniazda szerszeni. Działająca aplikacja, która wydaje się nudna, ale robi dokładnie to, co musi, jest dziesięć razy bardziej pożądana niż aplikacja, która została zoptymalizowana pod kątem zmutowanej supermaszyny hybrydowej, ale od czasu do czasu się psuje.
A jeśli nowicjusz zostanie mistrzem Laravela, sprawdź to kurs online.
Niech Twoje aplikacje działają dużo, dużo szybciej! 🙂