Wykorzystanie wiedzy zbiorowej może znacząco usprawnić proces podejmowania decyzji i rozwiązywania skomplikowanych problemów, poprzez połączenie wniosków z wielu, niezależnych modeli.
Uczenie maszynowe dynamicznie rozwija się w różnorodnych sektorach, od finansów i medycyny, po tworzenie oprogramowania i systemy zabezpieczeń.
Dobre wyszkolenie modeli uczenia maszynowego jest kluczowe dla osiągnięcia sukcesu w biznesie czy pracy zawodowej. Istnieje szereg metod, które to umożliwiają.
W dalszej części tekstu omówimy uczenie zespołowe, jego istotę, praktyczne zastosowania oraz różnorodne techniki.
Zapraszam do lektury!
Na czym polega uczenie zespołowe?
W kontekście uczenia maszynowego i statystyki, termin „zespół” odnosi się do metod, które generują zróżnicowane hipotezy w oparciu o wspólną bazę wiedzy.
Uczenie zespołowe to zaawansowana technika, gdzie wiele modeli (działających niczym eksperci) jest celowo projektowanych i łączonych w celu rozwiązywania złożonych zadań obliczeniowych lub tworzenia bardziej precyzyjnych prognoz.
Głównym celem tego podejścia jest zwiększenie efektywności procesu przewidywania, aproksymacji funkcji, klasyfikacji i innych zadań. Metoda ta pomaga także uniknąć sytuacji, w której wybierzemy mniej efektywny model z dostępnej puli. Wykorzystanie wielu algorytmów uczenia ma na celu osiągnięcie lepszych wyników predykcyjnych.
Znaczenie uczenia zespołowego w uczeniu maszynowym
W modelach uczenia maszynowego pojawiają się różne źródła błędów, takie jak obciążenie, wariancja czy zakłócenia. Uczenie zespołowe pomaga zredukować te problemy, zapewniając stabilność i dokładność algorytmów.
Oto kilka powodów, dla których uczenie zespołowe znajduje zastosowanie w różnych sytuacjach:
Wybór optymalnego klasyfikatora
Uczenie zespołowe ułatwia wybór najlepszego modelu lub klasyfikatora, minimalizując ryzyko wynikające z podjęcia niewłaściwej decyzji.

W zależności od problemu, stosuje się różne typy klasyfikatorów, takie jak maszyny wektorów nośnych (SVM), perceptrony wielowarstwowe (MLP), naiwne klasyfikatory Bayesa czy drzewa decyzyjne. Dodatkowo, istnieje wiele wariantów algorytmów klasyfikacji. Efektywność tych algorytmów może różnić się w zależności od danych treningowych.
Zamiast wyboru pojedynczego modelu, zastosowanie zespołu modeli i połączenie ich wyników pozwala uniknąć problemów związanych z wyborem gorszego rozwiązania.
Zarządzanie danymi
Wiele tradycyjnych metod uczenia maszynowego może tracić skuteczność w przypadku braku odpowiedniej ilości danych lub w przypadku ich nadmiaru.
Uczenie zespołowe sprawdza się w obu tych sytuacjach, niezależnie od tego, czy ilość danych jest zbyt mała, czy zbyt duża.
- W przypadku niedoboru danych można wykorzystać technikę bootstrap do trenowania różnych klasyfikatorów na różnych próbkach.
- Gdy danych jest zbyt dużo, można je podzielić na mniejsze zbiory, ułatwiając proces uczenia.
Radzenie sobie ze złożonością

Pojedynczy klasyfikator może nie być w stanie rozwiązać bardzo złożonych problemów, gdzie granice decyzyjne są skomplikowane. W takiej sytuacji zastosowanie liniowego klasyfikatora może okazać się niewystarczające.
Jednak, dzięki odpowiedniemu połączeniu zespołu liniowych klasyfikatorów, możliwe staje się nauczenie się nieliniowych zależności. Klasyfikator dzieli dane na mniejsze, łatwiejsze do analizy części. Każdy klasyfikator zajmuje się jedną, prostszą partycją, a następnie wyniki są łączone w celu uzyskania ogólnej granicy decyzyjnej.
Szacowanie pewności
W uczeniu zespołowym do podjętych decyzji przypisywany jest poziom ufności. Jeśli większość klasyfikatorów jest zgodna co do danej decyzji, jest ona uznawana za wysoce pewną.
Z kolei, gdy klasyfikatory są podzielone, poziom pewności decyzji jest niski.
Warto pamiętać, że wysoki poziom pewności nie zawsze oznacza słuszną decyzję. Niemniej jednak, prawidłowo przeszkolony zespół z wysoką pewnością zwykle podejmuje właściwe decyzje.
Zwiększenie precyzji poprzez fuzję danych
Łączenie danych z różnych źródeł, w strategiczny sposób, może poprawić precyzję klasyfikacji. Metoda ta jest zazwyczaj skuteczniejsza niż praca z danymi pochodzącymi z jednego tylko źródła.
Jak działa uczenie zespołowe?
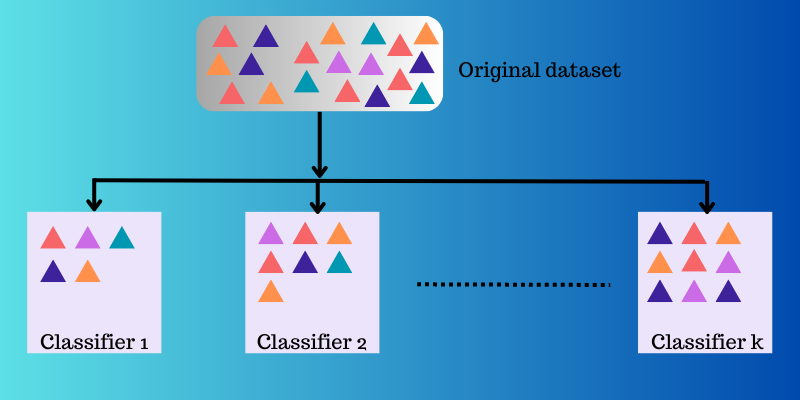
Uczenie zespołowe wykorzystuje zbiór funkcji mapujących, wygenerowanych przez różne klasyfikatory, a następnie łączy je w jedną funkcję.
Poniżej znajduje się przykład ilustrujący działanie uczenia zespołowego.
Przykład: Tworzysz aplikację związaną z żywieniem. Chcesz zbierać opinie użytkowników na temat problemów, z jakimi się spotykają, niedociągnięć, błędów i innych.
Możesz zebrać opinie od rodziny, przyjaciół, współpracowników, pytając ich o preferencje żywieniowe i doświadczenia z zamawianiem jedzenia online. Możesz również udostępnić wersję beta swojej aplikacji, aby uzyskać opinie w czasie rzeczywistym, wolne od uprzedzeń.
Działanie to polega na analizie wielu różnych pomysłów i opinii, aby ulepszyć doświadczenia użytkownika.
Podobnie działają modele uczenia zespołowego. Wykorzystują zestaw modeli i łączą je w celu uzyskania ostatecznego rezultatu, poprawiając precyzję i efektywność przewidywania.
Podstawowe techniki uczenia zespołowego
#1. Tryb
„Tryb” to wartość, która najczęściej pojawia się w zbiorze danych. W uczeniu zespołowym specjaliści wykorzystują wiele modeli do prognozowania dla każdego punktu danych. Prognozy te są traktowane jako indywidualne głosy, a prognoza wybrana przez większość modeli jest uważana za ostateczną. Metoda ta jest często stosowana w problemach klasyfikacji.
Przykład: Jeżeli cztery osoby oceniły aplikację na 4, a jedna na 3, to tryb wynosiłby 4, ponieważ większość wybrała 4.
#2. Średnia/Mediana
W tej technice uwzględnia się wszystkie prognozy modeli i oblicza ich średnią, aby uzyskać ostateczny wynik. Metoda ta jest szczególnie przydatna w problemach regresji, obliczaniu prawdopodobieństw w klasyfikacji i innych.
Przykład: W poprzednim przykładzie, gdzie cztery osoby dały 4, a jedna dała 3, średnia wyniosłaby (4+4+4+4+3)/5=3.8
#3. Średnia ważona
W tej metodzie różnym modelom przypisuje się różne wagi podczas procesu prognozowania. Waga odzwierciedla znaczenie danego modelu w procesie podejmowania decyzji.
Przykład: Jeśli 5 osób ocenia aplikację, z czego 3 to programiści, a 2 nie mają doświadczenia w tworzeniu aplikacji, opinie programistów będą miały większą wagę.
Zaawansowane techniki uczenia zespołowego
#1. Bagging
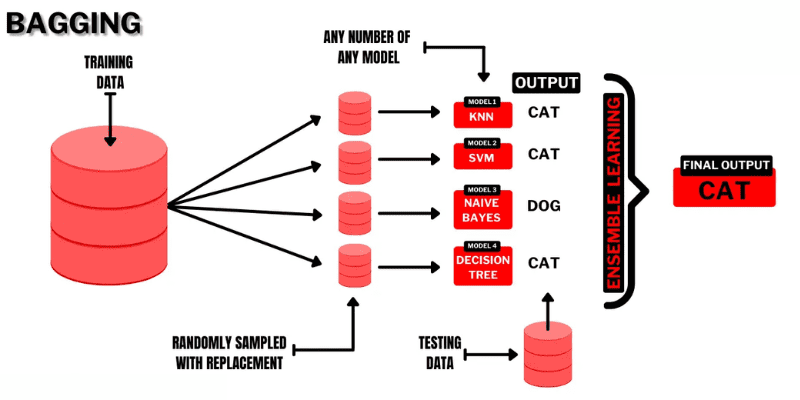
Bagging (Bootstrap AGGregatING) to intuicyjna technika uczenia zespołowego, która przynosi dobre rezultaty. Jak sugeruje nazwa, metoda łączy dwa terminy: „Bootstrap” i „agregacja”.
Bootstrapping to technika próbkowania, w której z oryginalnego zestawu danych tworzy się podzbiory, wybierając obserwacje z powtórzeniami. Rozmiar podzbioru jest taki sam jak rozmiar oryginalnego zestawu danych.
 Źródło: programista Buggy
Źródło: programista Buggy
W bagginu podzbiory te służą do zrozumienia dystrybucji pełnego zbioru. Podzbiory mogą być mniejsze niż oryginalny zestaw danych. Metoda ta wykorzystuje pojedynczy algorytm uczenia maszynowego. Celem łączenia wyników różnych modeli jest uzyskanie uogólnionego wyniku.
Jak działa bagging:
- Z oryginalnego zbioru danych generuje się kilka podzbiorów, wybierając obserwacje z powtórzeniami. Podzbiory są wykorzystywane do trenowania modeli, na przykład drzew decyzyjnych.
- Dla każdego podzbioru tworzony jest słaby lub bazowy model. Modele działają niezależnie od siebie i równolegle.
- Ostateczna prognoza jest tworzona poprzez połączenie prognoz z każdego modelu za pomocą statystyk, takich jak uśrednianie czy głosowanie.
Popularne algorytmy wykorzystywane w tej technice to:
- Las losowy
- Spakowane drzewa decyzyjne
Zaletą tej metody jest minimalizowanie błędów wariancji w drzewach decyzyjnych.
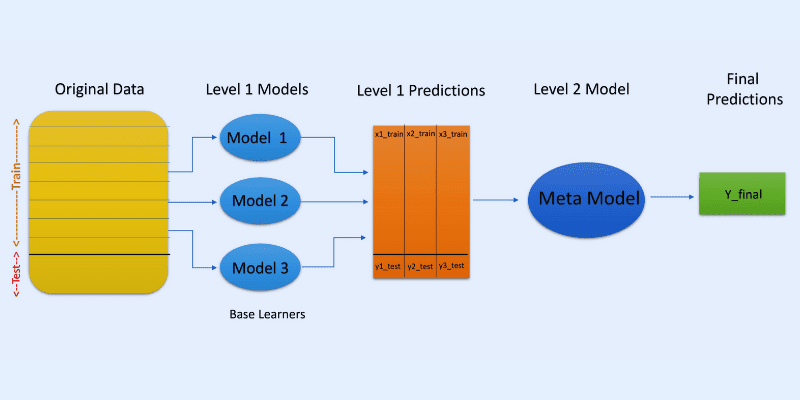
#2. Układanie (Stacking)
 Źródło obrazu: OpenGenus IQ
Źródło obrazu: OpenGenus IQ
W układaniu prognozy z różnych modeli, takich jak drzewa decyzyjne, są wykorzystywane do tworzenia nowego modelu, który ma za zadanie przewidzieć wynik dla zbioru testowego.
Układanie obejmuje tworzenie podzbiorów danych dla modeli treningowych, podobnie jak w bagginie. Tutaj jednak dane wyjściowe modeli są danymi wejściowymi dla innego klasyfikatora, zwanego meta-klasyfikatorem, który dokonuje ostatecznej prognozy.
Zastosowanie dwóch warstw klasyfikatorów pozwala ocenić, czy zbiory treningowe są odpowiednio wykorzystywane w procesie uczenia. Chociaż popularne jest podejście dwuwarstwowe, można zastosować więcej warstw.
Przykładowo, możesz użyć 3-5 modeli w pierwszej warstwie i jednego modelu w drugiej. Model z drugiej warstwy łączy prognozy z pierwszej warstwy, aby utworzyć ostateczny wynik.
Można użyć dowolnego modelu uczenia maszynowego do agregowania prognoz. Modele liniowe, takie jak regresja liniowa czy logistyczna, są często stosowane.
Popularne algorytmy używane w układaniu to:
- Mieszanie (Blending)
- Super zespół
- Ułożone modele
Uwaga: Mieszanie wykorzystuje zestaw walidacyjny lub wstrzymany z zestawu danych treningowych do tworzenia predykcji. W przeciwieństwie do układania w stosy, w mieszaniu przewidywania są wykonywane tylko na podstawie danych wstrzymanych.
#3. Wzmacnianie (Boosting)
Boosting to iteracyjna metoda uczenia zespołowego, która dostosowuje wagę obserwacji w zależności od jej poprzedniej klasyfikacji. Oznacza to, że każdy kolejny model stara się poprawić błędy popełnione przez model poprzedni.
Jeśli obserwacja nie zostanie poprawnie sklasyfikowana, wzmacnianie zwiększa jej wagę.
W procesie wzmacniania, pierwszy algorytm jest trenowany na pełnym zbiorze danych. Następnie budowane są kolejne algorytmy, wykorzystując reszty z poprzedniego algorytmu. Większą wagę przypisuje się obserwacjom, które poprzedni model sklasyfikował nieprawidłowo.
Proces krok po kroku:
- Z oryginalnego zestawu danych generuje się podzbiór. Początkowo każdy punkt ma taką samą wagę.
- Model bazowy jest tworzony na podstawie podzbioru.
- Prognoza jest dokonywana na pełnym zbiorze danych.
- Na podstawie rzeczywistych i przewidywanych wartości obliczane są błędy.
- Obserwacjom sklasyfikowanym nieprawidłowo przypisywane są większe wagi.
- Tworzony jest nowy model, a proces powtarza się, próbując poprawić poprzednie błędy. Tworzone są kolejne modele, a każdy z nich poprawia niedoskonałości poprzedniego.
- Ostateczna prognoza jest dokonywana na podstawie ostatecznego modelu, który jest średnią ważoną wszystkich modeli.
Popularne algorytmy wzmacniające to:
- CatBoost
- LightGBM
- AdaBoost
Zaletą wzmacniania jest generowanie lepszych prognoz i redukcja błędów obciążenia.
Inne techniki zespołowe

Mieszanka Ekspertów: Wykorzystuje trenowanie wielu klasyfikatorów, a ich wyniki są łączone z wykorzystaniem ogólnej zasady liniowej. Wagi dla kombinacji są określane przez model, który można wytrenować.
Głosowanie Większościowe: Wybiera nieparzystą liczbę klasyfikatorów i oblicza prognozy dla każdej próbki. Klasa, która uzyska najwięcej głosów, jest przewidywaną klasą zespołu. Stosowane jest w problemach klasyfikacji binarnej.
Reguła Maxa: Wykorzystuje rozkłady prawdopodobieństwa każdego klasyfikatora i zaufanie do prognozowania. Stosowane w problemach klasyfikacji wieloklasowej.
Praktyczne zastosowania uczenia zespołowego
#1. Wykrywanie twarzy i emocji
Uczenie zespołowe, wykorzystujące techniki takie jak analiza niezależnych składowych (ICA), umożliwia wykrywanie twarzy.
Ponadto, uczenie zespołowe znajduje zastosowanie w rozpoznawaniu emocji na podstawie mowy, a także pomaga w wykrywaniu emocji na twarzy.
#2. Bezpieczeństwo
Wykrywanie oszustw: Uczenie zespołowe pomaga lepiej modelować normalne zachowania, co czyni je skutecznym w wykrywaniu oszustw, na przykład w systemach kart kredytowych, oszustwach telekomunikacyjnych czy praniu brudnych pieniędzy.

DDoS: Atak typu rozproszonej odmowy usługi (DDoS) stanowi poważne zagrożenie dla dostawców internetu. Klasyfikatory zespołowe mogą pomóc w wykrywaniu błędów i odróżnianiu ataków od normalnego ruchu.
Wykrywanie włamań: Uczenie zespołowe jest stosowane w systemach monitorowania, takich jak narzędzia do wykrywania włamań, umożliwiając identyfikowanie kodów intruzów, monitorowanie sieci, wykrywanie anomalii i inne.
Wykrywanie złośliwego oprogramowania: Uczenie zespołowe skutecznie wykrywa i klasyfikuje złośliwe oprogramowanie, takie jak wirusy, robaki, oprogramowanie ransomware, konie trojańskie, oprogramowanie szpiegujące, wykorzystując do tego techniki uczenia maszynowego.
#3. Nauka przyrostowa
W uczeniu przyrostowym algorytm uczy się na podstawie nowego zestawu danych, zachowując dotychczasową wiedzę, ale bez dostępu do poprzednich danych. Systemy zespołowe znajdują zastosowanie w tym procesie, umożliwiając uczenie się dodawanego klasyfikatora dla każdego zestawu danych, gdy tylko staje się dostępny.
#4. Medycyna
Klasyfikatory zespołowe są przydatne w diagnostyce medycznej, np. w wykrywaniu zaburzeń neurokognitywnych, takich jak choroba Alzheimera. Systemy te analizują zestawy danych MRI i klasyfikują cytologię szyjki macicy. Poza tym, znajdują zastosowanie w proteomice, neuronauce i innych dziedzinach.
#5. Zdalne wykrywanie
Wykrywanie zmian: Klasyfikatory zespołowe są wykorzystywane do wykrywania zmian za pomocą metod takich jak średnia bayesowska i głosowanie większościowe.
Mapowanie pokrycia terenu: Metody uczenia zespołowego, takie jak wzmacnianie, drzewa decyzyjne, analiza głównych składowych jądra (KPCA) są wykorzystywane do efektywnego wykrywania i mapowania pokrycia terenu.
#6. Finanse
Precyzja jest krytycznym aspektem w finansach, zarówno w obliczeniach, jak i prognozach. Ma duży wpływ na efektywność podejmowanych decyzji. Modele uczenia zespołowego mogą analizować zmiany na giełdzie, wykrywać manipulacje cenami akcji i wiele innych.
Dodatkowe materiały szkoleniowe

#1. Zespołowe metody uczenia maszynowego
Ta książka pomoże ci nauczyć się i wdrożyć od podstaw ważne metody uczenia zespołowego.
#2. Metody zespołowe: podstawy i algorytmy
Ta książka zawiera podstawy uczenia zespołowego i jego algorytmów. Przedstawia również sposób jego wykorzystania w praktyce.
#3. Nauka zespołowa
Oferuje wprowadzenie do ujednoliconej metody zespołowej, wyzwań, aplikacji itp.
#4. Ensemble Machine Learning: metody i zastosowania
Zapewnia szeroki zakres zaawansowanych technik uczenia zespołowego.
Podsumowanie
Mam nadzieję, że ten artykuł pomógł wam zrozumieć, czym jest uczenie zespołowe, jakie są jego metody, przypadki użycia i dlaczego warto z niego korzystać. Uczenie zespołowe ma potencjał, by rozwiązywać wiele realnych problemów, od bezpieczeństwa, tworzenia aplikacji, po finanse, medycynę i inne dziedziny. Zastosowania tej metody stale rosną, dlatego prawdopodobnie w najbliższej przyszłości zaobserwujemy kolejne ulepszenia tej koncepcji.
Zachęcam również do zapoznania się z narzędziami do generowania danych syntetycznych, które mogą być przydatne w procesie trenowania modeli uczenia maszynowego.