Python stał się jednym z czołowych języków programowania, szczególnie w kontekście obsługi i analizy danych. Jego unikalną cechą jest zdolność do przetwarzania informacji w różnych formatach, włączając w to JSON, CSV oraz arkusze kalkulacyjne Excel.
W niniejszym opracowaniu przyjrzymy się bliżej wybranym bibliotekom Pythona, które są nieocenione w zarządzaniu danymi, zwłaszcza tymi przechowywanymi w plikach Excel.
Dlaczego Python to dobry wybór do zarządzania danymi?
- Python charakteryzuje się czytelną i prostą składnią, co sprawia, że jest łatwy do nauki i użytkowania. To z kolei przekłada się na jego popularność w środowisku programistycznym.
- Jego wszechstronność pozwala na zastosowanie w wielu dziedzinach, od sztucznej inteligencji, poprzez tworzenie aplikacji webowych, aż po analizę danych i aplikacje desktopowe.
- Duża społeczność użytkowników Pythona aktywnie tworzy zasoby, co ułatwia rozwiązywanie problemów i przyspiesza rozwój. Dzięki temu Python jest postrzegany jako stabilne i niezawodne narzędzie.
- Python dysponuje bogatym zbiorem bibliotek, które wspomagają zarządzanie danymi. Wśród nich wyróżniają się NumPy i Pandas, które omówimy szczegółowo w dalszej części artykułu.
Przejdźmy teraz do analizy bibliotek, które Python oferuje do efektywnego zarządzania danymi.
OpenPyXL
OpenPyXL to biblioteka Pythona dedykowana do obsługi plików Microsoft Excel w wersjach od 2010 wzwyż. Obsługuje formaty takie jak .xlsx, .xlsm, .xltm i .xltx. Jest to jedna z najczęściej wybieranych bibliotek do pracy z danymi z Excela.
Pozwala ona na otwieranie plików, tworzenie nowych arkuszy, edytowanie metadanych oraz odczytywanie i zapisywanie danych. Dzięki temu zarządzanie danymi z Excela staje się proste i efektywne.
Pandas

Pandas to biblioteka o ogromnej popularności w dziedzinie zarządzania, analizy i transformacji danych w Pythonie. Jest to narzędzie typu open-source, darmowe, a zarazem oferujące wszechstronność, prostotę użytkowania i wysoką wydajność.
Potrafi odczytywać dane z różnych formatów, w tym także z Excela. Biblioteka ta jest kluczowym elementem wyposażenia każdego specjalisty od analizy danych.
Warto przeczytać: Dlaczego Pandas jest najczęściej używaną biblioteką do analizy danych w Pythonie
xlrd

xlrd to biblioteka Pythona, która służy do odczytywania i formatowania danych w skoroszytach Excela. Podobnie jak inne wspomniane narzędzia, jest bezpłatna i open-source. Jej ograniczeniem jest obsługa wyłącznie starszego formatu .xls. Mimo to, pozostaje popularnym wyborem w zarządzaniu danymi.
pyexcel
pyexcel dąży do zunifikowania interfejsu API, umożliwiając pracę z różnymi formatami plików Excel/arkuszy kalkulacyjnych, takimi jak csv, ods, xls, xlsx.
Zapewnia intuicyjny sposób importu danych, ich transformacji do tablic i słowników w pamięci, jak również odwrotnej operacji. Biblioteka ta jest dostępna na zasadach licencji open-source.
PyExcelerate
PyExcelerate to biblioteka zorientowana na szybkie i efektywne tworzenie arkuszy kalkulacyjnych. Jej optymalizacja pod kątem wydajności jest priorytetem. Służy wyłącznie do zapisu danych, ale w odróżnieniu od większości bibliotek umożliwia również dodawanie stylów. Jest to idealne rozwiązanie, gdy potrzebne jest szybkie generowanie dużej ilości arkuszy.
xlwings
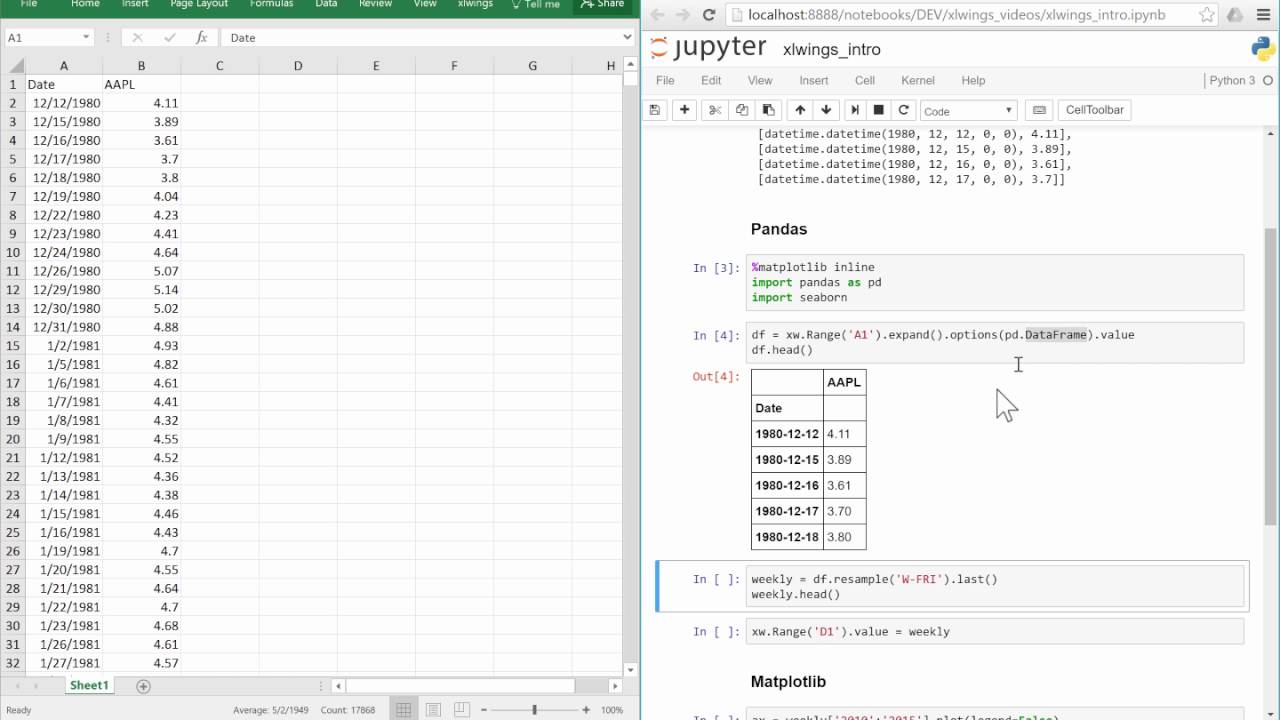
xlwings to otwarty pakiet, który integruje się z Microsoft Excel i Arkuszami Google. Jest to narzędzie do automatyzacji arkuszy kalkulacyjnych, stanowiące alternatywę dla makr VBA i Power Query.
Wersja podstawowa jest bezpłatna i open-source. Istnieje również wersja płatna, Pro, która oferuje rozszerzone funkcje i wsparcie. Z xlwings korzystają między innymi takie firmy jak Accenture, Nokia, Shell i Komisja Europejska.
xlSlim

xlSlim umożliwia pracę z arkuszami kalkulacyjnymi w sposób zbliżony do notatników Jupyter. Pozwala na pisanie kodu w interaktywnych komórkach arkusza, który może oddziaływać z danymi i wykonywać obliczenia.
xlSlim zawiera również edytor kodu Pythona. Daje możliwość wywoływania funkcji VBA z Pythona i korzystania z funkcji zdefiniowanych w arkuszu kalkulacyjnym, tak jak z wbudowanych funkcji Excela.
NumPy

NumPy to biblioteka do obliczeń numerycznych w Pythonie, ceniona za swoją szybkość i możliwości przetwarzania danych.
Umożliwia import danych z plików CSV do tablic NumPy. Po imporcie można zarządzać danymi na wiele sposobów, wykorzystując możliwości Pythona. Istnieje również możliwość eksportu danych z powrotem do plików CSV.
Pycel
Pycel przekształca skoroszyty Excela w wykres obliczeń Pythona, który może być uruchamiany poza Excelem. Jest to przydatne w sytuacjach, gdy złożone obliczenia mają być wykonywane w środowisku innym niż Excel, np. w Pythonie na serwerze z systemem Linux.
Wygenerowany graf obliczeń odzwierciedla wszystkie komórki arkusza i ich wzajemne powiązania. Te zależności można wykorzystać do dynamicznej aktualizacji wartości komórek w przypadku zmiany wartości jednej z nich.
Formuły
Formuły to kolejny interpreter skoroszytów Excela. Ten open-source’owy pakiet odczytuje skoroszyty, analizuje formuły i transformuje je do kodu Python. Ten kod może być wykonywany znacznie szybciej na różnych platformach bez konieczności instalowania serwera Excel COM.
PyXLL

PyXLL umożliwia wykorzystanie Pythona w Excelu poprzez interfejs użytkownika. Dzięki temu pakietowi można pisać kod Pythona, który interaguje z danymi w arkuszach kalkulacyjnych i definiować funkcje, które mogą być używane w komórkach.
Działa jako substytut dla VBA, umożliwiając wykorzystanie bogatego ekosystemu Pythona i jego bibliotek w Microsoft Excel.
Podsumowanie
W niniejszym artykule przedstawiliśmy różne biblioteki Pythona przydatne w zarządzaniu danymi z arkuszy kalkulacyjnych Excel. Te narzędzia umożliwiają pozyskiwanie danych i ich przetwarzanie w jednym z najpopularniejszych formatów, jakim są arkusze Excel.
Dzięki tym bibliotekom można realizować bardziej skomplikowane zadania i w pełni wykorzystać potencjał ekosystemu Pythona.
Zachęcamy również do zapoznania się z informacjami o tworzeniu Pandas DataFrame.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.