
Jeśli jesteś nowy w analizie dużych zbiorów danych, na twoim radarze może znajdować się wiele narzędzi Apache; jednak sama liczba różnych narzędzi może być myląca, a czasami przytłaczająca.
Ten post rozwieje to zamieszanie i wyjaśni, czym są Apache Hive i Impala i czym się od siebie różnią!
Spis treści:
Ul Apache
Apache Hive to interfejs dostępu do danych SQL dla platformy Apache Hadoop. Hive umożliwia wykonywanie zapytań, agregowanie i analizowanie danych przy użyciu składni SQL.
Schemat dostępu do odczytu jest używany do danych w systemie plików HDFS, co pozwala traktować dane jak zwykłą tabelę lub relacyjny DBMS. Zapytania HiveQL są tłumaczone na kod Java dla zadań MapReduce.
Zapytania Hive są pisane w języku zapytań HiveQL, który jest oparty na języku SQL, ale nie ma pełnego wsparcia dla standardu SQL-92.
Jednak ten język pozwala programistom używać ich zapytań, gdy korzystanie z funkcji HiveQL jest niewygodne lub nieefektywne. HiveQL można rozszerzyć o zdefiniowane przez użytkownika funkcje skalarne (UDF), agregacje (kody UDAF) i funkcje tabelowe (UDTF).
Jak działa Apache Hive
Apache Hive tłumaczy programy napisane w języku HiveQL (zbliżonym do SQL) na jedno lub więcej zadań MapReduce, Apache Tez lub Apache Spark. Są to trzy silniki wykonawcze, które można uruchomić na platformie Hadoop. Następnie Apache Hive organizuje dane w tablicę dla pliku Hadoop Distributed File System (HDFS), aby uruchomić zadania w klastrze i wygenerować odpowiedź.
Tabele Apache Hive są podobne do relacyjnych baz danych, a jednostki danych są zorganizowane od najbardziej znaczącej jednostki do najbardziej szczegółowej. Bazy danych to tablice złożone z partycji, które ponownie można podzielić na „wiaderka”.
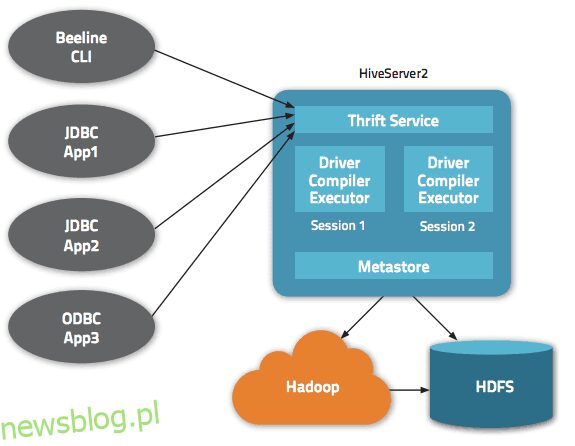
Dane są dostępne za pośrednictwem HiveQL. W każdej bazie danych dane są numerowane, a każda tabela odpowiada katalogowi HDFS.
W architekturze Apache Hive dostępnych jest wiele interfejsów, takich jak interfejs WWW, CLI lub klienci zewnętrzni.
Rzeczywiście, serwer „Apache Hive Thrift” umożliwia zdalnym klientom przesyłanie poleceń i żądań do Apache Hive przy użyciu różnych języków programowania. Centralny katalog Apache Hive to „metastore” zawierający wszystkie informacje.
Silnik, który sprawia, że Hive działa, nazywa się „sterownikiem”. Zawiera kompilator i optymalizator w celu określenia optymalnego planu wykonania.
Wreszcie bezpieczeństwo zapewnia Hadoop. Dlatego opiera się na protokole Kerberos do wzajemnego uwierzytelniania między klientem a serwerem. Uprawnienia do nowo tworzonych plików w Apache Hive są narzucane przez HDFS, co pozwala na autoryzację użytkownika, grupy lub w inny sposób.
Cechy Hive’a
- Obsługuje silnik obliczeniowy Hadoop i Spark
- Wykorzystuje HDFS i działa jako hurtownia danych.
- Używa MapReduce i obsługuje ETL
- Dzięki HDFS ma odporność na uszkodzenia podobną do Hadoop
Apache Hive: Korzyści
Apache Hive to idealne rozwiązanie do obsługi zapytań i analizy danych. Umożliwia uzyskanie jakościowych spostrzeżeń, zapewniających przewagę konkurencyjną i ułatwiających reagowanie na zapotrzebowanie rynku.
Wśród głównych zalet Apache Hive można wymienić łatwość obsługi powiązaną z jego „przyjaznym SQL” językiem. Ponadto przyspiesza wstępne wprowadzanie danych, ponieważ dane nie muszą być odczytywane ani numerowane z dysku w formacie wewnętrznej bazy danych.
Wiedząc, że dane są przechowywane w systemie plików HDFS, możliwe jest przechowywanie dużych zestawów danych, nawet setek petabajtów danych, w Apache Hive. Rozwiązanie to jest znacznie bardziej skalowalne niż tradycyjna baza danych. Wiedząc, że jest to usługa w chmurze, Apache Hive umożliwia użytkownikom szybkie uruchamianie serwerów wirtualnych w oparciu o fluktuacje obciążeń (tj. zadań).
Bezpieczeństwo jest również aspektem, w którym Hive działa lepiej, dzięki swojej zdolności do replikacji obciążeń krytycznych dla odzyskiwania w przypadku problemu. Wreszcie, wydajność pracy jest niezrównana, ponieważ może wykonać do 100 000 żądań na godzinę.
Apache Impala
Apache Impala to masowo równoległy silnik zapytań SQL do interaktywnego wykonywania zapytań SQL na danych przechowywanych w Apache Hadoop, napisany w C++ i dystrybuowany na licencji Apache 2.0.
Impala jest również nazywany silnikiem MPP (Massively Parallel Processing), rozproszonym systemem DBMS, a nawet stosową bazą danych SQL-on-Hadoop.

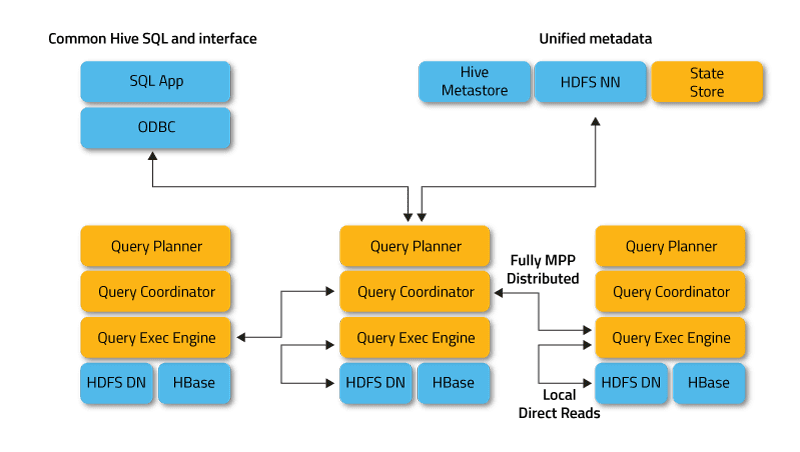
Impala działa w trybie rozproszonym, w którym instancje procesów działają w różnych węzłach klastra, odbierając, planując i koordynując żądania klientów. W takim przypadku możliwe jest równoległe wykonywanie fragmentów zapytania SQL.
Klienci to użytkownicy i aplikacje, które wysyłają zapytania SQL do danych przechowywanych w Apache Hadoop (HBase i HDFS) lub Amazon S3. Interakcja z Impala odbywa się za pośrednictwem interfejsu internetowego HUE (Hadoop User Experience), ODBC, JDBC i powłoki wiersza poleceń Impala Shell.
Infrastrukturalnie Impala polega na innym popularnym narzędziu SQL-on-Hadoop, Apache Hive, korzystającym z magazynu metadanych. W szczególności Hive Metastore informuje firmę Impala o dostępności i strukturze baz danych.
Podczas tworzenia, modyfikowania i usuwania obiektów schematu lub ładowania danych do tabel za pomocą instrukcji SQL odpowiednie zmiany metadanych są automatycznie propagowane do wszystkich węzłów Impala za pomocą wyspecjalizowanej usługi katalogowej.
Kluczowymi składnikami Impala są następujące pliki wykonywalne:
- Demon Impalad lub Impala to usługa systemowa, która planuje i wykonuje zapytania dotyczące danych HDFS, HBase i Amazon S3. W każdym węźle klastra działa jeden proces impalad.
- Statestore to usługa nazewnictwa, która śledzi lokalizację i stan wszystkich instancji impalad w klastrze. Jedno wystąpienie tej usługi systemowej działa na każdym węźle i serwerze głównym (Nazwa węzła).
- Katalog to usługa koordynacji metadanych, która propaguje zmiany z instrukcji Impala DDL i DML do wszystkich węzłów Impala, których to dotyczy, dzięki czemu nowe tabele lub nowo załadowane dane są natychmiast widoczne dla każdego węzła w klastrze. Zaleca się, aby jedna instancja Katalogu działała na tym samym hoście klastra, co demon Statestored.
Jak działa Apache Impala
Impala, podobnie jak Apache Hive, używa podobnego deklaratywnego języka zapytań, Hive Query Language (HiveQL), który jest podzbiorem SQL92 zamiast SQL.
Faktyczna realizacja żądania w Impala wygląda następująco:
Aplikacja kliencka wysyła zapytanie SQL, łącząc się z dowolnym impaladem za pośrednictwem standardowych interfejsów sterowników ODBC lub JDBC. Podłączony impalad staje się koordynatorem bieżącego żądania.
Zapytanie SQL jest analizowane w celu określenia zadań dla instancji impalad w klastrze; następnie budowany jest optymalny plan wykonania zapytania.
Impalad uzyskuje bezpośredni dostęp do HDFS i HBase przy użyciu lokalnych instancji usług systemowych w celu dostarczania danych. W przeciwieństwie do Apache Hive, taka bezpośrednia interakcja znacznie skraca czas wykonania zapytania, ponieważ wyniki pośrednie nie są zapisywane.
W odpowiedzi każdy demon zwraca dane do koordynującego impalada, wysyłając wyniki z powrotem do klienta.
Cechy Impali
- Obsługa przetwarzania w pamięci w czasie rzeczywistym
- Przyjazny SQL
- Obsługuje systemy pamięci masowej, takie jak HDFS, Apache HBase i Amazon S3
- Obsługuje integrację z narzędziami BI, takimi jak Pentaho i Tableau
- Używa składni HiveQL
Apache Impala: Korzyści
Impala pozwala uniknąć ewentualnych narzutów związanych z uruchamianiem, ponieważ wszystkie procesy demonów systemowych są uruchamiane bezpośrednio w czasie uruchamiania. Znacznie oszczędza czas wykonywania zapytań. Dodatkowy wzrost szybkości Impala wynika z tego, że to narzędzie SQL dla Hadoop, w przeciwieństwie do Hive, nie przechowuje pośrednich wyników i uzyskuje bezpośredni dostęp do HDFS lub HBase.
Ponadto Impala generuje kod programu w czasie wykonywania, a nie podczas kompilacji, jak robi to Hive. Jednak efektem ubocznym wysokich prędkości Impala jest zmniejszona niezawodność.
W szczególności, jeśli węzeł danych ulegnie awarii podczas wykonywania zapytania SQL, instancja Impala uruchomi się ponownie, a Hive będzie nadal utrzymywać połączenie ze źródłem danych, zapewniając odporność na błędy.
Inne zalety Impala to wbudowana obsługa bezpiecznego protokołu uwierzytelniania sieci Kerberos, ustalanie priorytetów oraz możliwość zarządzania kolejką żądań i obsługa popularnych formatów Big Data, takich jak LZO, Avro, RCFile, Parquet i Sequence.
Hive kontra Impala: podobieństwa
Hive i Impala są swobodnie dystrybuowane na licencji Apache Software Foundation i odnoszą się do narzędzi SQL do pracy z danymi przechowywanymi w klastrze Hadoop. Ponadto używają również rozproszonego systemu plików HDFS.
Impala i Hive realizują różne zadania, skupiając się na przetwarzaniu SQL dużych zbiorów danych przechowywanych w klastrze Apache Hadoop. Impala zapewnia interfejs podobny do SQL, umożliwiający odczyt i zapis tabel Hive, umożliwiając w ten sposób łatwą wymianę danych.
Jednocześnie Impala sprawia, że operacje SQL na Hadoop są dość szybkie i wydajne, umożliwiając wykorzystanie tego DBMS w projektach badawczych związanych z analizą Big Data. Gdy tylko jest to możliwe, Impala współpracuje z istniejącą infrastrukturą Apache Hive, która jest już używana do wykonywania długotrwałych zapytań wsadowych SQL.
Ponadto Impala przechowuje swoje definicje tabel w metastore, tradycyjnej bazie danych MySQL lub PostgreSQL, czyli w tym samym miejscu, w którym Hive przechowuje podobne dane. Pozwala Impala na dostęp do tabel Hive, o ile wszystkie kolumny używają obsługiwanych przez Impala typów danych, formatów plików i kodeków kompresji.
Hive kontra Impala: różnice

Język programowania
Hive jest napisany w Javie, a Impala w C++. Jednak Impala używa również niektórych UDF Hive opartych na Javie.
Przypadków użycia
Inżynierowie danych używają Hive w procesach ETL (wyodrębnianie, przekształcanie, ładowanie), na przykład do długotrwałych zadań wsadowych na dużych zestawach danych, na przykład w agregatorach podróży i systemach informacji lotniskowej. Z kolei Impala jest przeznaczona głównie dla analityków i data science i jest wykorzystywana głównie w zadaniach takich jak business intelligence.
Wydajność
Impala wykonuje zapytania SQL w czasie rzeczywistym, podczas gdy Hive charakteryzuje się niską szybkością przetwarzania danych. Dzięki prostym zapytaniom SQL Impala może działać 6-69 razy szybciej niż Hive. Jednak Hive lepiej obsługuje złożone zapytania.
Opóźnienie/przepustowość
Przepustowość Hive jest znacznie wyższa niż Impala. Funkcja LLAP (Live Long and Process), która umożliwia buforowanie zapytań w pamięci, zapewnia Hive dobrą wydajność na niskim poziomie.
LLAP obejmuje długoterminowe usługi systemowe (demony), które pozwalają na bezpośrednią interakcję z węzłami danych HDFS i zastępują ściśle zintegrowaną strukturę zapytań DAG (Directed acycle graph) – model grafów aktywnie wykorzystywany w obliczeniach Big Data.
Tolerancja błędów
Hive to system odporny na błędy, który zachowuje wszystkie wyniki pośrednie. Wpływa to również pozytywnie na skalowalność, ale prowadzi do zmniejszenia szybkości przetwarzania danych. Z kolei Impala nie można nazwać platformą odporną na błędy, ponieważ jest bardziej ograniczona pamięcią.
Konwersja kodu
Hive generuje wyrażenia zapytań w czasie kompilacji, podczas gdy Impala generuje je w czasie wykonywania. Hive charakteryzuje się problemem „zimnego startu” przy pierwszym uruchomieniu aplikacji; zapytania konwertowane są powoli ze względu na konieczność nawiązania połączenia ze źródłem danych.
Impala nie ma tego rodzaju kosztów początkowych. Niezbędne usługi systemowe (demony) do przetwarzania zapytań SQL są uruchamiane podczas startu systemu, co przyspiesza pracę.
Obsługa pamięci masowej
Impala obsługuje formaty LZO, Avro i Parquet, podczas gdy Hive współpracuje z Plain Text i ORC. Jednak oba obsługują formaty RCFIle i Sequence.
Apache HiveApache ImpalaJęzyk JavaC++ Przypadki użyciaInżynieria danychAnaliza i analitykaWydajnośćWysoka dla prostych zapytań Stosunkowo niskie opóźnienieWiększe opóźnienie dzięki buforowaniuMniejsza tolerancja na błędy ukryteWiększa tolerancja dzięki MapReduceMniejsza tolerancja dzięki MPPConversionWolne dzięki zimnemu startowiSzybsza konwersjaObsługa pamięci masowejZwykły tekst i ORCLZO, Avro, Parquet
Ostatnie słowa
Hive i Impala nie konkurują ze sobą, ale raczej skutecznie się uzupełniają. Mimo że istnieją znaczne różnice między tymi dwoma rozwiązaniami, mają one również wiele wspólnego, a wybór jednego z nich zależy od danych i konkretnych wymagań projektu.
Możesz także zapoznać się z bezpośrednimi porównaniami między Hadoop i Spark.
.