Co to jest dzielenie bazy danych?
Fragmentacja baz danych stanowi metodę osiągania skalowalności poziomej w rozbudowanych systemach informatycznych.
W większości systemów rzeczywistych występuje serwer bazy danych, który odbiera liczne zapytania o dane i znaczną liczbę żądań modyfikacji. Taka sytuacja może prowadzić do przeciążenia serwera, a w konsekwencji do spadku wydajności całego systemu.
W celu minimalizacji negatywnych skutków i podniesienia efektywności systemu stosuje się różne strategie, takie jak replikacja bazy danych oraz jej fragmentacja (sharding). W niniejszym opracowaniu omówione zostaną najpierw techniki usprawniające działanie systemu, w tym:
- Zwiększenie mocy serwera bazy danych
- Replikacja danych
- Partycjonowanie horyzontalne
Po przedstawieniu tych metod, przeanalizujemy działanie fragmentacji bazy danych, a także zalety i wady tego rozwiązania.
Przejdźmy do szczegółów!
Sposoby na optymalizację wydajności systemu
Rozpocznijmy od omówienia metod poprawy wydajności systemu w kontekście wąskich gardeł związanych z serwerem baz danych:
# 1. Zwiększenie mocy serwera bazy danych
Rozbudowa serwera bazy danych poprzez zwiększenie jego mocy obliczeniowej, dodanie większej ilości pamięci RAM i inne modyfikacje, może wydawać się prostym rozwiązaniem w celu poprawy wydajności systemu.
Niemniej jednak, to podejście posiada pewne ograniczenia. Nie jest możliwe posiadanie serwera o nieograniczonej mocy obliczeniowej i przestrzeni dyskowej. Po przekroczeniu pewnego progu, korzyści z dalszej rozbudowy stają się coraz mniejsze.
#2. Replikacja bazy danych
W przypadku, gdy serwer baz danych jest obciążony nadmierną ilością zapytań, można rozważyć zastosowanie replikacji.
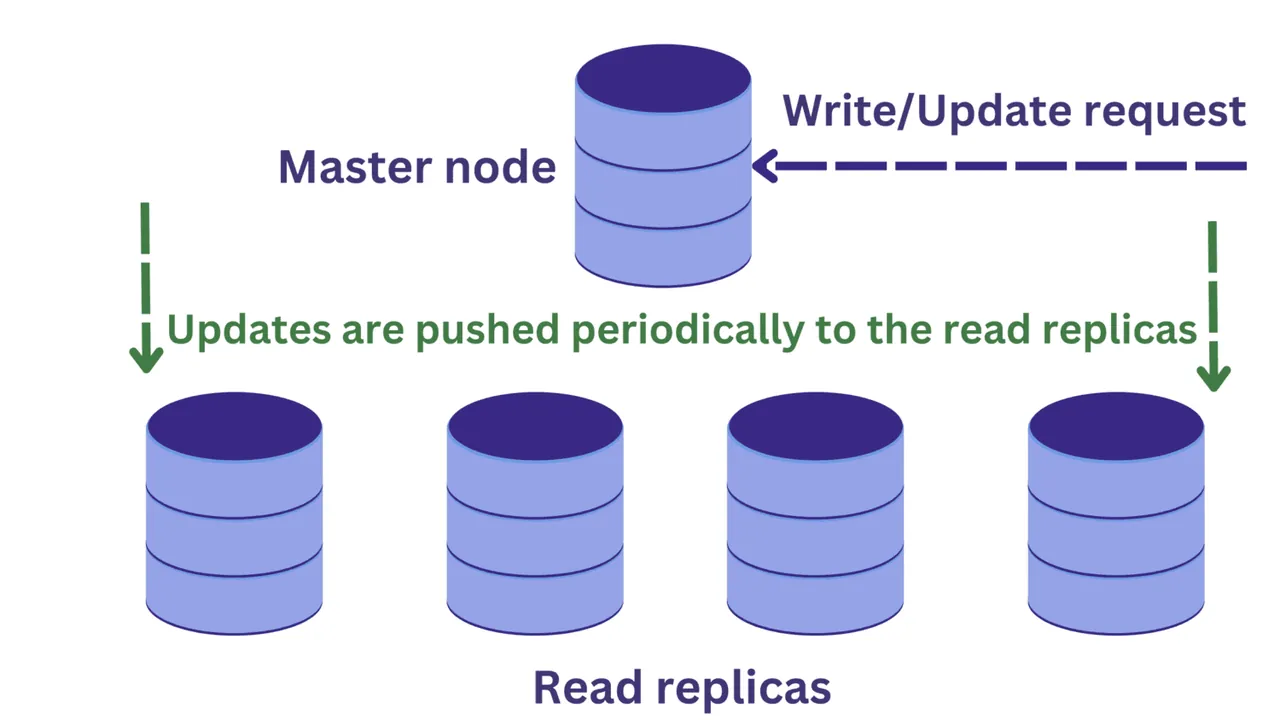
W ramach replikacji baz danych, istnieje węzeł główny, który najczęściej przyjmuje żądania modyfikacji, oraz wiele replik służących do odczytu.
Taki model poprawia dostępność danych i obniża obciążenie systemu. Dzięki temu, że zapytania odczytu są przekierowywane do replik, możemy równolegle przetwarzać większą liczbę zapytań.
Jednak wprowadza to również pewien problem. Żądania zapisu kierowane do węzła głównego mogą zmieniać dane, a te aktualizacje są co jakiś czas synchronizowane z replikami.
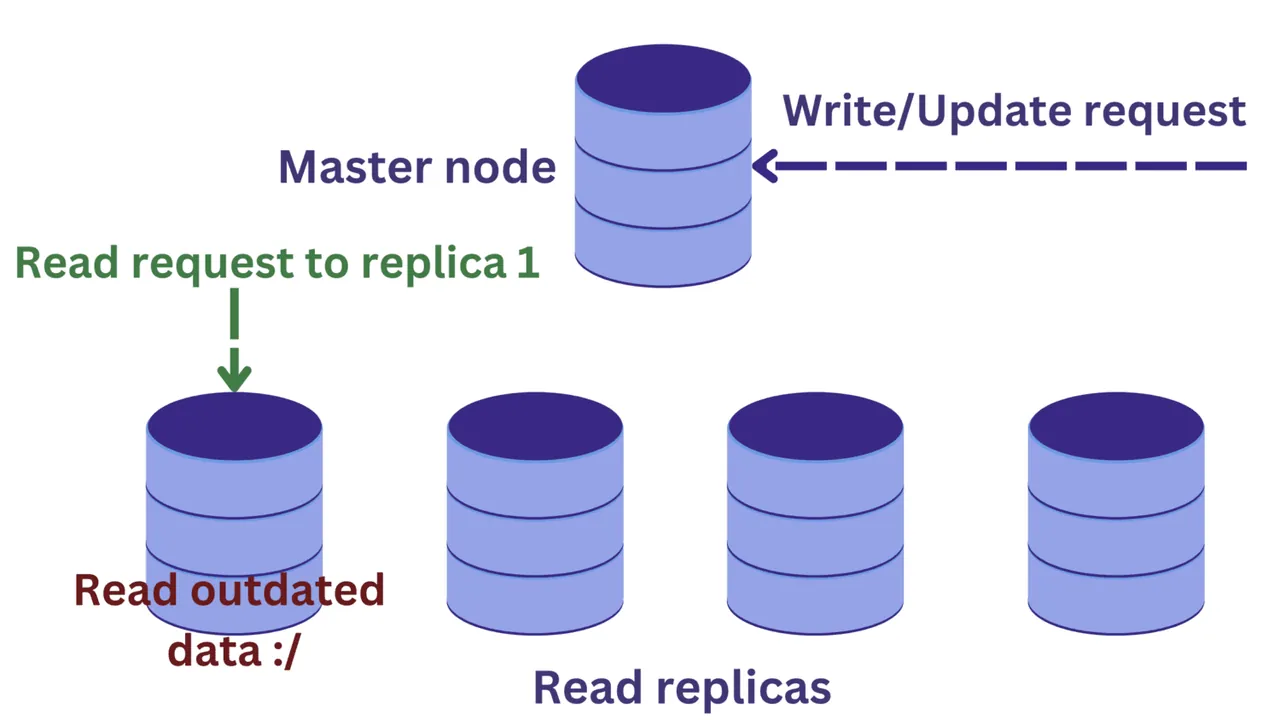
Załóżmy, że w tym samym czasie, gdy trwa operacja zapisu w węźle głównym, do jednej z replik trafia żądanie odczytu.
Zmiany dokonane w węźle głównym nie zostaną jeszcze zsynchronizowane z replikami. W takim scenariuszu, możemy uzyskać nieaktualne dane, co jest niepożądane.
#3. Partycjonowanie horyzontalne
Partycjonowanie horyzontalne stanowi kolejną metodę optymalizacji wydajności systemu. Możemy mieć do czynienia z pojedynczą, ogromną tabelą zawierającą miliardy rekordów, np. tabelę klientów i danych transakcyjnych.
Odczyt danych z tak dużej tabeli jest czasochłonny. Jednak dzięki partycjonowaniu horyzontalnemu, taka tabela jest dzielona na mniejsze partycje (lub mniejsze tabele), z których możemy odczytywać dane. Relacyjne bazy danych, takie jak PostgreSQL, mają wbudowaną obsługę partycjonowania.
Wszystkie partycje są jednak umieszczone w ramach jednej instancji serwera bazy danych. Zasadnicza różnica polega na tym, że odczytujemy dane z mniejszych partycji, zamiast z jednej gigantycznej tabeli.
W sytuacji zwiększenia ilości napływających żądań, serwer może mieć trudności z obsłużeniem tak dużego obciążenia.
Jak działa fragmentacja bazy danych?
Po omówieniu różnych podejść do poprawy wydajności systemu i ich ograniczeń, przejdźmy do zrozumienia, w jaki sposób działa fragmentacja bazy danych.
W procesie fragmentacji dzielimy jedną dużą bazę danych na szereg mniejszych baz, z których każda jest umieszczona na oddzielnej instancji serwera. Każda z tych mniejszych baz nazywana jest fragmentem. Każdy fragment zawiera unikalny podzbiór danych.
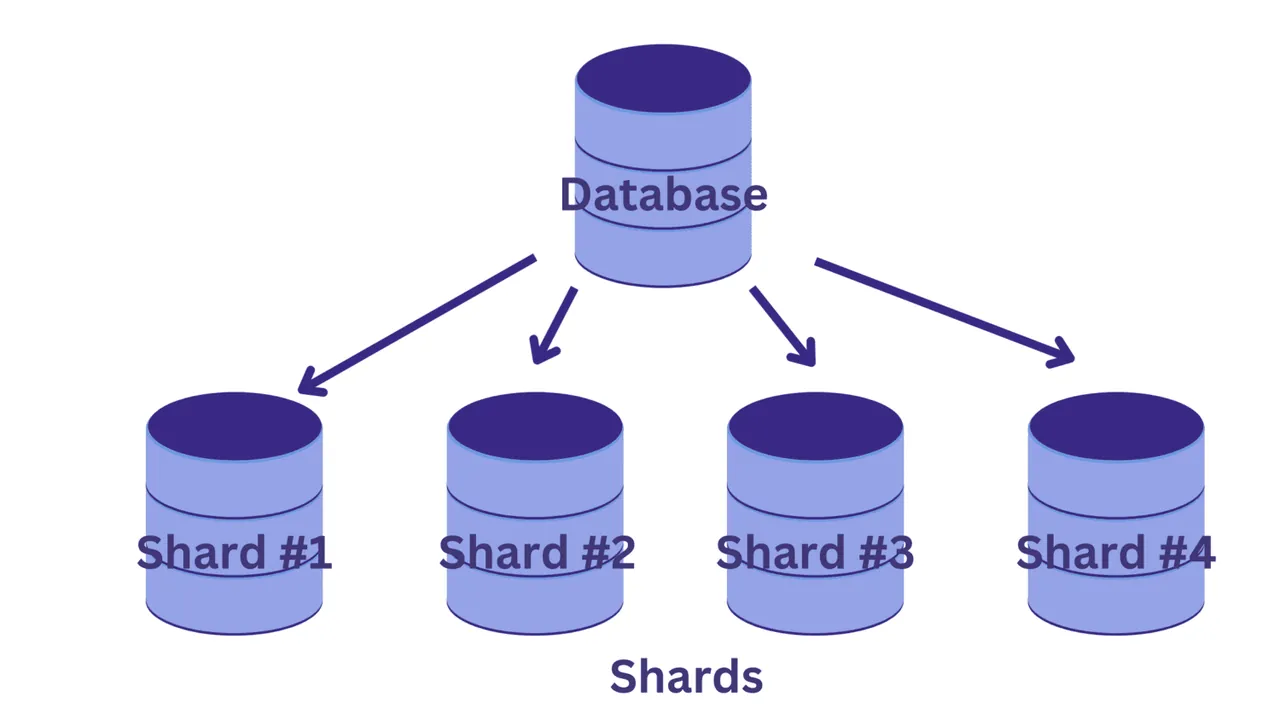
Jak jednak podzielić bazę danych na fragmenty? I w jaki sposób określić, które wiersze trafią do którego fragmentu?
🔑 Tutaj z pomocą przychodzi klucz fragmentacji (sharding key).
Zrozumienie klucza fragmentacji
Przyjrzyjmy się dokładniej roli klucza fragmentacji.
Klucz fragmentacji, który zwykle jest kolumną (lub kombinacją kolumn) w tabeli bazy danych, powinien być tak dobrany, aby zapewnić równomierny rozkład danych pomiędzy fragmentami. Chodzi o to, by żaden z fragmentów nie był znacznie większy od pozostałych.
W bazie danych przechowującej dane o klientach i transakcjach, identyfikator klienta jest dobrym kandydatem na klucz fragmentacji.
Po ustaleniu klucza fragmentacji, możemy opracować funkcję haszującą, która ustali, które wiersze trafią do którego fragmentu.
Załóżmy, że chcemy podzielić bazę danych na pięć fragmentów (od fragmentu nr 0 do fragmentu nr 4), używając identyfikatora klienta jako klucza fragmentacji. W tym przypadku, prostą funkcją haszującą jest: identyfikator_klienta % 5.
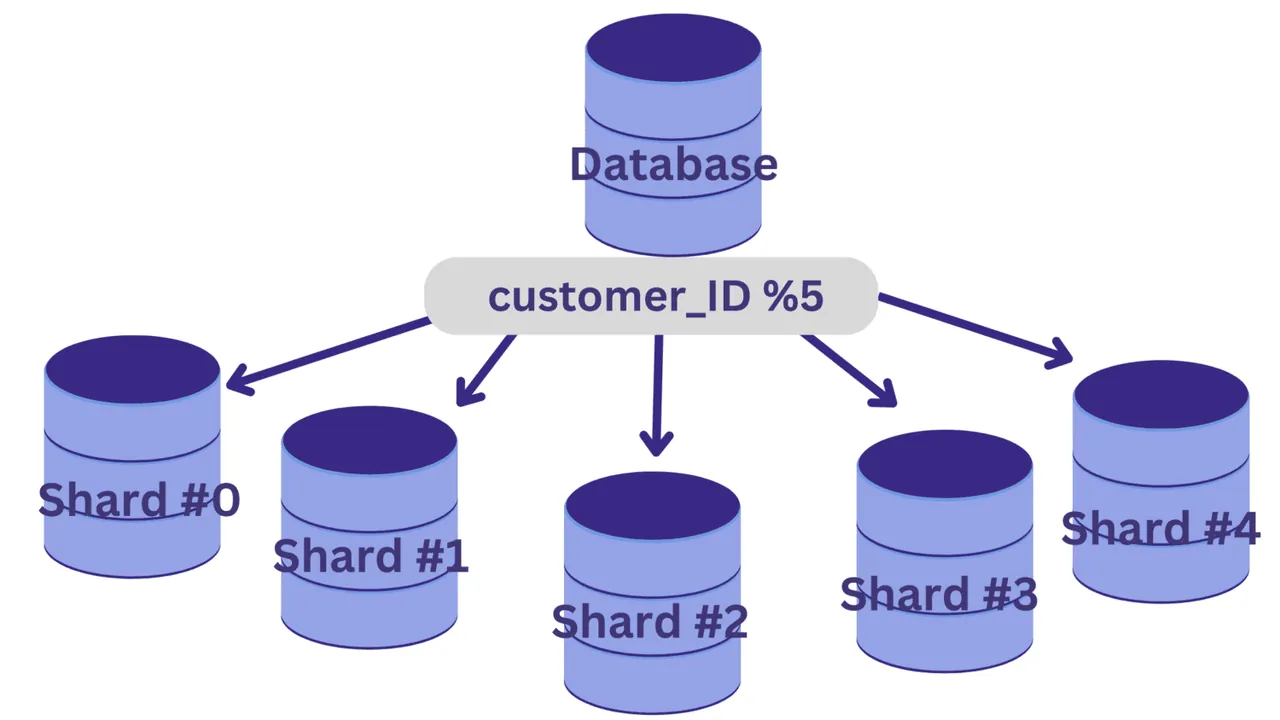
Wszystkie identyfikatory klientów, których reszta z dzielenia przez 5 wynosi zero, zostaną przypisane do fragmentu nr 0. Natomiast wartości, których reszta z dzielenia wynosi od 1 do 4, zostaną przypisane do fragmentów od 1 do 4.
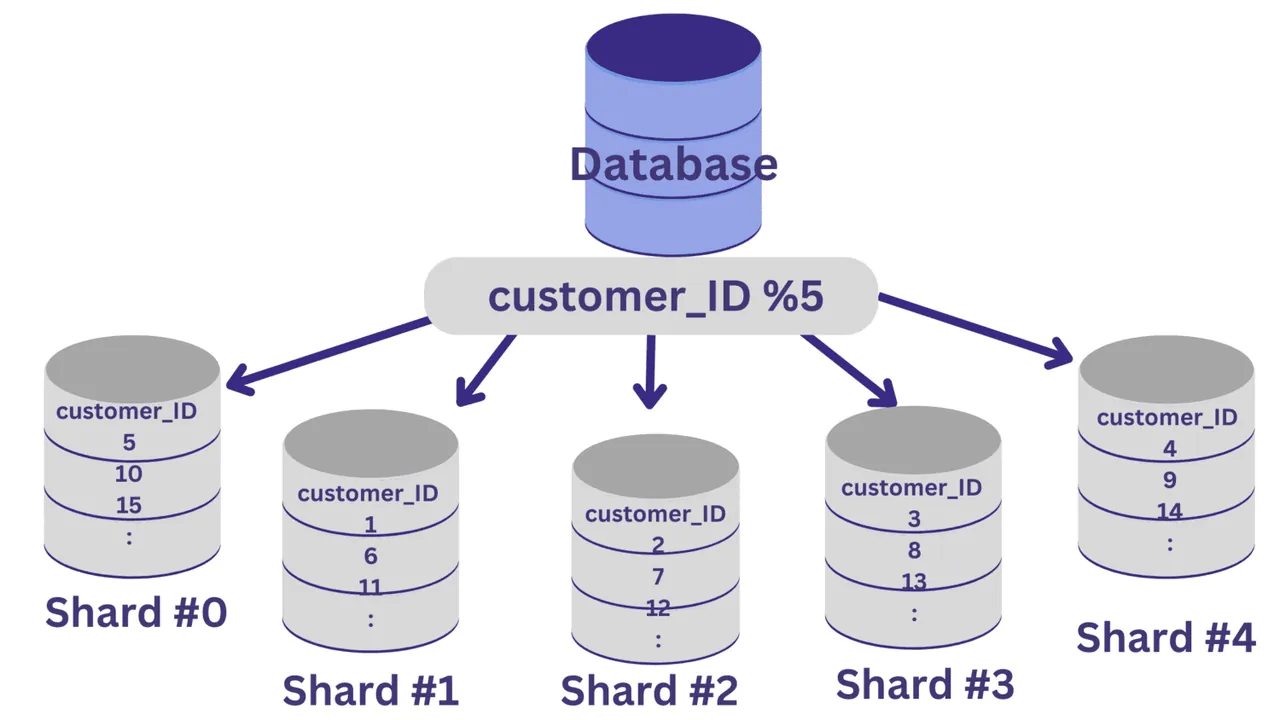
Po zaimplementowaniu fragmentacji bazy danych, kluczowe jest posiadanie warstwy routingu, która kieruje napływające żądania do właściwego fragmentu bazy danych.
Zalety fragmentacji bazy danych
Oto niektóre zalety fragmentacji baz danych:
# 1. Wysoka skalowalność
Zawsze istnieje możliwość podziału większej bazy danych na większą liczbę mniejszych fragmentów. Fragmentacja baz danych pozwala na skalowanie w poziomie.
#2. Wysoka dostępność
W sytuacji, gdy wszystkie zapytania obsługuje pojedyncza instancja serwera, mamy do czynienia z pojedynczym punktem awarii. Jeśli serwer przestanie działać, cała aplikacja zostanie wyłączona.
W przypadku fragmentacji baz danych, prawdopodobieństwo, że wszystkie fragmenty przestaną działać jednocześnie jest stosunkowo niskie. W związku z tym, nawet jeśli jeden z fragmentów ulegnie awarii, nie będziemy mogli przetwarzać jedynie zapytań kierowanych do tego fragmentu. Pozostałe fragmenty będą nadal przetwarzać napływające żądania. Przekłada się to na wysoką dostępność i zwiększoną odporność na awarie.
Ograniczenia fragmentacji bazy danych
Przyjrzyjmy się teraz niektórym ograniczeniom fragmentacji baz danych:
# 1. Złożoność
Pomimo zalet pod względem skalowalności i odporności na uszkodzenia, fragmentacja wprowadza pewną złożoność do systemu.
Od mapowania rekordów do partycji, po implementację warstwy routingu, która przekierowuje zapytania do odpowiednich fragmentów – bazy danych z fragmentacją wiążą się z istotną złożonością.
#2. Konieczność ponownej fragmentacji
Kolejnym ograniczeniem shardingu jest konieczność jego ponownego przeprowadzenia.
Pomimo użycia funkcji haszującej w celu uzyskania równomiernego rozkładu rekordów, może zdarzyć się, że jeden z fragmentów stanie się znacznie większy od innych i szybciej wyczerpie swoje zasoby. W takiej sytuacji niezbędne jest przeprowadzenie ponownej fragmentacji, co wiąże się ze znacznymi kosztami.
#3. Realizacja złożonych zapytań
W przypadku konieczności uruchomienia złożonych zapytań analitycznych, obejmujących łączenie danych z wielu fragmentów, a nie jednej bazy danych, może to stanowić wyzwanie. Można je obejść poprzez denormalizację bazy danych, jednak wymaga to dodatkowego nakładu pracy.
Podsumowanie
Podsumujmy najważniejsze informacje, które omówiliśmy.
Zwiększanie mocy serwera nie zawsze jest optymalnym rozwiązaniem. W związku z tym, rozbudowa instancji serwera nie jest zalecana. Przeanalizowaliśmy również techniki takie jak replikacja bazy danych i partycjonowanie horyzontalne, zwracając uwagę na ich ograniczenia.
Następnie wyjaśniliśmy, jak działa fragmentacja bazy danych, która polega na podziale dużej bazy na mniejsze i łatwiejsze w zarządzaniu fragmenty. Omówiliśmy, jak istotne jest staranne dobranie klucza fragmentacji, aby uzyskać równomierne partycje, oraz potrzebę wprowadzenia warstwy routingu, która będzie kierować napływające żądania do odpowiedniego fragmentu.
Fragmentacja bazy danych oferuje zalety, takie jak wysoka dostępność i skalowalność. Do wad należą złożoność konfiguracji oraz konieczność ponownej fragmentacji, gdy jeden lub więcej fragmentów wyczerpie swoje zasoby.
Rozważ zastosowanie fragmentacji, gdy uważasz, że korzyści płynące z tego rozwiązania przeważają nad złożonością, którą wprowadza. Warto również zapoznać się z porównaniem różnych relacyjnych baz danych AWS.
