
- Platformy mediów społecznościowych sprzedają dane użytkowników firmom zajmującym się sztuczną inteligencją w celu szkolenia modeli generatywnych sztucznej inteligencji, pomimo obaw związanych z prywatnością.
- Platformy takie jak Meta, Reddit, Tumblr i WordPress.com aktywnie angażują się w te umowy licencyjne na dane na potrzeby szkoleń AI.
- Użytkownicy mogą podjąć niewielkie kroki, aby chronić swoje dane, np. dostosować ustawienia prywatności, zrezygnować z udostępniania i zachować ostrożność w stosunku do tego, co publikują w Internecie.
Jednym z najnowszych sposobów zarabiania na danych użytkowników przez firmy z branży mediów społecznościowych są umowy z firmami zajmującymi się sztuczną inteligencją. Ale czy jest coś, co zwykli użytkownicy mogą zrobić, aby chronić swoje dane i treści?
Wykorzystywanie danych z mediów społecznościowych do uczenia generatywnych modeli sztucznej inteligencji jest posunięciem kontrowersyjnym, ale nie wydaje się, aby powstrzymywało to firmy z mediów społecznościowych od udostępniania danych użytkowników.
Meta wykorzystuje już dane z mediów społecznościowych do szkolenia funkcji generatywnej sztucznej inteligencji ogłoszonych na Meta Connect w 2023 r. Obejmuje to Meta AI i funkcje takie jak tworzenie naklejek generowanych przez sztuczną inteligencję w WhatsApp.
Jak stwierdził Mike Clark, dyrektor ds. zarządzania produktami w Meta, w: Post w Meta Newsroomie:
„Publicznie udostępniane posty z Instagrama i Facebooka – w tym zdjęcia i tekst – były częścią danych wykorzystywanych do uczenia generatywnych modeli sztucznej inteligencji leżących u podstaw funkcji, które ogłosiliśmy na Connect”.
Nie wydaje się, aby w 2024 roku trend ten miał wyhamować. Według ReuteraReddit zawarł umowę z Google, aby udostępnić treści platformy mediów społecznościowych na potrzeby uczenia modeli sztucznej inteligencji.
Zgłoszenie S-1 Reddita na pierwszą ofertę publiczną złożoną 22 lutego 2024 r. potwierdza, że spółka rozważa umowy licencyjne. W zgłoszeniu stwierdza się:
„Dane Reddit to fundamentalny element konstrukcji obecnej technologii sztucznej inteligencji i wielu LLM. Wierzymy, że ogromny zbiór danych i wiedzy konwersacyjnej Reddit będzie nadal odgrywał rolę w szkoleniu i ulepszaniu LLM”.
Określa, że Reddit „jest na wczesnym etapie umożliwiania stronom trzecim licencjonowania dostępu do wyszukiwania, analizowania i wyświetlania danych historycznych i danych w czasie rzeczywistym z naszej platformy” w celu szkolenia LLM.
I choć Meta i Reddit to jedne z największych nazwisk w mediach społecznościowych, nie są jedynymi platformami wykorzystującymi dane z mediów społecznościowych do szkolenia sztucznej inteligencji. Według raport 404 MediaTumblr i WordPress.com przygotowują się do sprzedaży danych użytkowników Midjourney i OpenAI.
Jest szansa, że jeśli korzystasz z Facebooka, Instagrama, Reddita, Tumblra czy WordPress.com, Twoje publicznie dostępne treści zostały już wykorzystane w szkoleniu LLM.
Na przykład, jeśli używasz Narzędzie wyszukiwania Washington Post aby zobaczyć, jakie witryny znalazły się w zbiorze danych Google C4, który został wykorzystany w ramach szkolenia Barda, zobaczysz, że Reddit.com liczy 7,9 miliona tokenów.

Na Tumblr.com przypada 1,6 miliona tokenów. Moja mała witryna internetowa, która korzysta z WordPress.com, zgromadziła 14 000 tokenów, więc zbiór danych mógł uwzględniać małe blogi osobiste.
Biorąc pod uwagę trwające umowy między firmami zajmującymi się sztuczną inteligencją a firmami z branży mediów społecznościowych, umowy licencyjne będą oznaczać, że dane te będą aktywnie sprzedawane, a nie tylko usuwane z Internetu.
Ale jeśli chodzi o przyszłe przetwarzanie, co możesz z tym zrobić? Meta wprowadziła formularz dotyczący praw podmiotu danych związanych z generatywną sztuczną inteligencją który pozwala Ci sprzeciwić się lub ograniczyć przetwarzanie Twoich danych osobowych przez strony trzecie w celu szkolenia generatywnych modeli AI firmy Meta.
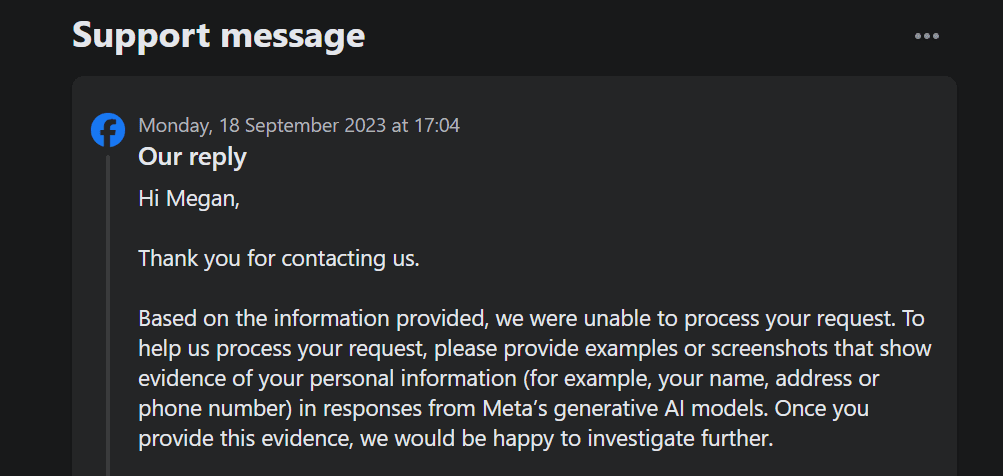
W szczególności ta opcja nie pozwala sprzeciwić się przetwarzaniu danych przez Meta na własną rękę w celu szkolenia generatywnej sztucznej inteligencji. Co więcej, kiedy za pomocą formularza wysłałem zgłoszenie sprzeciwu wobec wykorzystania moich danych osobowych, zgłoszenie do pomocy technicznej wymagało ode mnie udowodnienia, że moje dane osobowe już pojawiały się w generatywnych wynikach sztucznej inteligencji Meta.
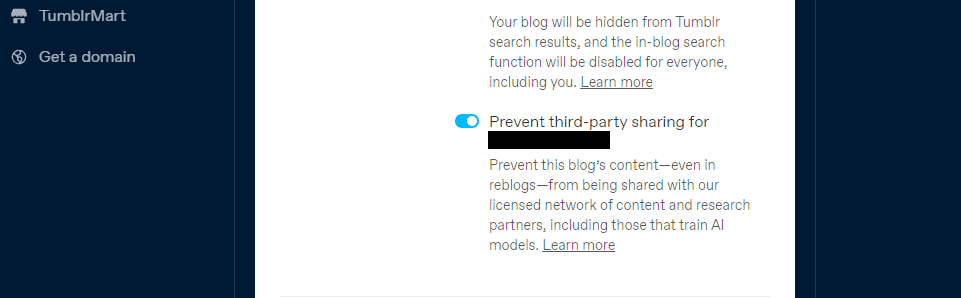
Tumblr wprowadził także opcję rezygnacji z udostępniania zawartości Twoich publicznych blogów stronom trzecim, korzystając z ustawień Twojego bloga. Znajdziesz go w swoich ustawieniach, klikając swojego bloga i przewijając w dół do ustawień widoczności. Następnie wybierz opcję Zapobiegaj udostępnianiu bloga osobom trzecim.
Jeśli chodzi o platformę taką jak Instagram, możesz spróbować przełączyć swoje konto na Instagramie na prywatne, aby uniemożliwić wykorzystanie Twoich danych. Nie gwarantuje to, że Twoje dane nie zostaną wykorzystane, ale ponieważ pobieranie danych dla LLM wydaje się skupiać na danych publicznych, może to stanowić potencjalne zabezpieczenie.
Możesz także ustawić swoje konto X (Twitter) jako prywatne, ale po raz kolejny jest to tylko potencjalne zabezpieczenie i nie gwarantuje, że Twoje dane pozostaną prywatne.
A wspólne oświadczenie przez różnych krajowych komisarzy i ekspertów ds. informacji na całym świecie zasugerował również pewne działania dla osób, które chcą zminimalizować ryzyko prywatności wynikające ze skrobania danych przez firmy zajmujące się sztuczną inteligencją. Porady obejmują:
- Przeczytaj warunki i politykę prywatności danej witryny internetowej, aby zobaczyć, w jaki sposób udostępnia ona Twoje dane osobowe.
- Ogranicz informacje, które publikujesz w Internecie, szczególnie te wrażliwe.
- Zarządzaj ustawieniami prywatności.
- Pomyśl długoterminowo o informacjach, które udostępniasz online.
- Jeśli uważasz, że Twoje dane zostały niewłaściwie pobrane, skontaktuj się z firmą zajmującą się mediami społecznościowymi lub witryną. Jeśli nie jesteś zadowolony z ich odpowiedzi, złóż skargę do odpowiedniego organu ochrony danych.
Możesz także usunąć pewne informacje online, jeśli nie czujesz się komfortowo, gdy osoby trzecie mają do nich dostęp, chociaż publicznie dostępne informacje w Twoich profilach mogły już zostać usunięte.
Niestety my, zwykli użytkownicy, możemy zrobić tylko tyle, aby chronić nasze dane przed firmami zajmującymi się sztuczną inteligencją. Prawdziwa kontrola nad tymi informacjami prawdopodobnie będzie możliwa jedynie przy pomocy organów regulacyjnych.