Dogłębne omówienie technologii deepfake i uproszczonego procesu ich tworzenia za pomocą narzędzia Faceswap.
Sztuczna inteligencja coraz mniej przypomina swoją „sztuczną” naturę. Współczesność przyniosła jej niebezpieczne zbliżenie do ludzkich możliwości.
Potrafi już generować sugestie, pisać teksty, tworzyć dzieła sztuki, a teraz także imitować wygląd i sposób mówienia człowieka.
Jest to jedno z najnowszych osiągnięć technologicznych, które niesie ze sobą potencjał korzyści, ale równocześnie stanowi poważne zagrożenie.
Czym dokładnie są deepfake?
Termin „deepfake” powstał z połączenia dwóch angielskich słów: „deep learning” (głębokie uczenie) i „fake” (fałszywy). W uproszczeniu, deepfake to zaawansowana manipulacja materiałami medialnymi, tworząca wrażenie autentyczności.
Zgodnie z definicją Wikipedii, deepfake to rodzaj syntetycznych mediów, w których istniejący obraz, nagranie dźwiękowe lub wideo są zmieniane w taki sposób, aby przedstawiały inną osobę lub sytuację.
Deepfake’i najczęściej wykorzystuje się do tego, aby znane osoby wypowiadały słowa, których w rzeczywistości nigdy nie powiedziały.
W zależności od umiejętności twórcy, deepfake może być niezwykle trudny do odróżnienia od prawdziwego nagrania.
Jak działa technologia deepfake?
W najprostszym ujęciu, fragment oryginalnego filmu (na przykład twarz) jest zastępowany bardzo realistycznym odpowiednikiem. Jest to proces znany również jako zamiana twarzy, co doskonale ilustruje słynne wideo z „Obamą”.
Jednak technologia deepfake nie ogranicza się tylko do wideo. Obejmuje ona również obrazy, dźwięk, a w niedalekiej przyszłości – prawdopodobnie także awatary w wirtualnej rzeczywistości.
źródło: disney
Metoda tworzenia deepfake zależy w dużej mierze od konkretnej aplikacji i algorytmu, na którym bazuje.
Według artykułu badawczego Disneya, istnieje wiele technik, w tym autoenkodery, generatywne sieci przeciwstawne (GAN) oraz metody oparte na geometrii.
Poniższe sekcje skupią się na działaniu Faceswap, darmowego oprogramowania open-source do tworzenia deepfake’ów, które wykorzystuje różne algorytmy do osiągnięcia pożądanego rezultatu.
Proces generowania deepfake’ów składa się z trzech podstawowych etapów: ekstrakcji, trenowania i konwersji.
#1. Ekstrakcja
Na tym etapie identyfikuje się i wyodrębnia obszar zainteresowania z materiałów źródłowych – zarówno oryginalnych, jak i tych, które mają zostać podmienione.
W zależności od możliwości sprzętowych, stosuje się różne algorytmy detekcji.
Przykładowo, Faceswap oferuje rozmaite opcje ekstrakcji, wyrównywania i maskowania, dostosowane do wydajności procesora lub karty graficznej.
Ekstrakcja polega na rozpoznaniu twarzy w całym filmie. Wyrównanie odpowiada za detekcję kluczowych cech twarzy (oczy, nos, podbródek, itp.). Maskowanie natomiast eliminuje inne elementy obrazu spoza obszaru zainteresowania.
Czas potrzebny na uzyskanie danych wyjściowych jest istotny przy wyborze opcji. Wybranie zbyt wymagających algorytmów na przeciętnym sprzęcie może skutkować awarią lub znacznym wydłużeniem procesu.
Oprócz sprzętu, wybór algorytmu zależy również od specyfiki materiału wejściowego, na przykład tego, czy na twarzy występują przeszkody, takie jak dłonie czy okulary.
Istotnym krokiem jest również oczyszczenie danych wyjściowych, ponieważ ekstrakcja często generuje fałszywe alarmy.
Proces ekstrakcji powtarza się dla oryginalnego i docelowego wideo (którego twarz chcemy podmienić).
#2. Trenowanie
To kluczowy etap tworzenia deepfake’ów.
Trenowanie polega na uczeniu sieci neuronowej składającej się z kodera i dekodera. Algorytmy przetwarzają wyekstrahowane dane, aby stworzyć model, który posłuży do późniejszej konwersji.
Koder przekształca dane wejściowe w reprezentację wektorową, a dekoder na tej podstawie uczy się, jak odtwarzać twarz.
Sieć neuronowa analizuje swoje iteracje, porównuje je z oryginałem i na podstawie tego przypisuje wynik strat. Wartość ta zmniejsza się z czasem, gdy algorytm przechodzi kolejne iteracje. Proces uczenia kończy się, gdy osiągnięte zostaną zadowalające wyniki.
Uczenie jest procesem czasochłonnym, a jego efektywność zależy od liczby wykonanych iteracji oraz jakości danych wejściowych.
Przykładowo, Faceswap zaleca użycie co najmniej 500 zdjęć, zarówno oryginalnych, jak i tych do zamiany. Obrazy te powinny być różnorodne, przedstawiając różne kąty i oświetlenie, aby zapewnić jak najwierniejsze odwzorowanie.
Z uwagi na długi czas trwania procesu uczenia, niektóre aplikacje, takie jak Faceswap, umożliwiają przerwanie uczenia w trakcie i kontynuowanie go później.
Należy pamiętać, że fotorealizm generowanego deepfake’a zależy od wydajności algorytmu, jakości danych wejściowych i możliwości sprzętowych.
#3. Konwersja
To ostatni etap tworzenia deepfake’a. Algorytmy konwersji wymagają wideo źródłowego, wytrenowanego modelu i pliku z wyrównaniem.
Możliwe jest dostosowanie dodatkowych opcji, takich jak korekcja kolorów, typ maski czy format wyjściowy.
Po skonfigurowaniu wszystkich parametrów, pozostaje tylko czekać na wygenerowanie ostatecznego nagrania.
Jak wcześniej wspomniano, Faceswap oferuje wiele algorytmów, które można dowolnie łączyć, aby uzyskać zamierzony efekt.
Czy to wszystko?
NIE!
To, co opisano powyżej, to jedynie zamiana twarzy, czyli podzbiór technologii deepfake. Jak sama nazwa wskazuje, zamiana twarzy polega jedynie na zastąpieniu części twarzy, co daje jedynie mgliste wyobrażenie o pełnym potencjale deepfake.
Aby uzyskać wiarygodną manipulację, często konieczne jest również naśladowanie dźwięku (klonowanie głosu) i całej sylwetki, włącznie ze wszystkimi elementami kadru, jak na poniższym przykładzie:

Na czym polega problem?
W przedstawionym przykładzie autor deepfake’a mógł samodzielnie nagrać wideo (jak sugeruje ostatnie kilka sekund), zsynchronizować dialog z syntetycznym głosem Morgana Freemana i na koniec wymienić twarz.

Reasumując, deepfake to nie tylko zamiana twarzy, ale manipulacja całym kadrem, łącznie z dźwiękiem.
W serwisie YouTube można znaleźć wiele deepfake’ów, co zmusza do zastanowienia się nad tym, komu możemy ufać. Do rozpoczęcia tworzenia deepfake wystarczy komputer o wysokiej wydajności z mocną kartą graficzną.
Jednak osiągnięcie perfekcji w tej dziedzinie jest niezwykle trudne.
Stworzenie przekonującego deepfake’a, który może wprowadzić w błąd lub zachwycić widzów, wymaga dużych umiejętności i od kilku dni do kilku tygodni przetwarzania jednej lub dwóch minut filmu.
Obecne możliwości algorytmów są imponujące, ale przyszłość – w tym efektywność tych aplikacji na słabszym sprzęcie – budzi obawy wielu rządów.
Nie będziemy jednak zagłębiać się w potencjalne konsekwencje. Skupmy się na tym, jak samodzielnie stworzyć deepfake dla własnej rozrywki.
Tworzenie (podstawowych) deepfake’ów
Istnieje wiele aplikacji do tworzenia deepfake’ów, które można wykorzystać do stworzenia np. memów.
Jedną z nich jest Faceswap, którą wykorzystamy w tym poradniku.
Zanim przejdziemy dalej, upewnijmy się, że mamy dobrej jakości nagranie docelowej osoby, ukazujące różnorodne emocje. Potrzebne będzie również źródłowe wideo, na które zostanie nałożona twarz docelowa.
Przed rozpoczęciem pracy z Faceswap należy zamknąć wszystkie aplikacje obciążające kartę graficzną, takie jak przeglądarki internetowe czy gry. Jest to szczególnie ważne, jeśli karta graficzna ma mniej niż 2 GB pamięci VRAM (pamięci wideo).
Krok 1: Ekstrakcja twarzy
Pierwszym krokiem jest wyekstrahowanie twarzy z filmu. W tym celu wybieramy docelowe wideo w katalogu wejściowym i określamy katalog wyjściowy dla wyekstrahowanych danych.
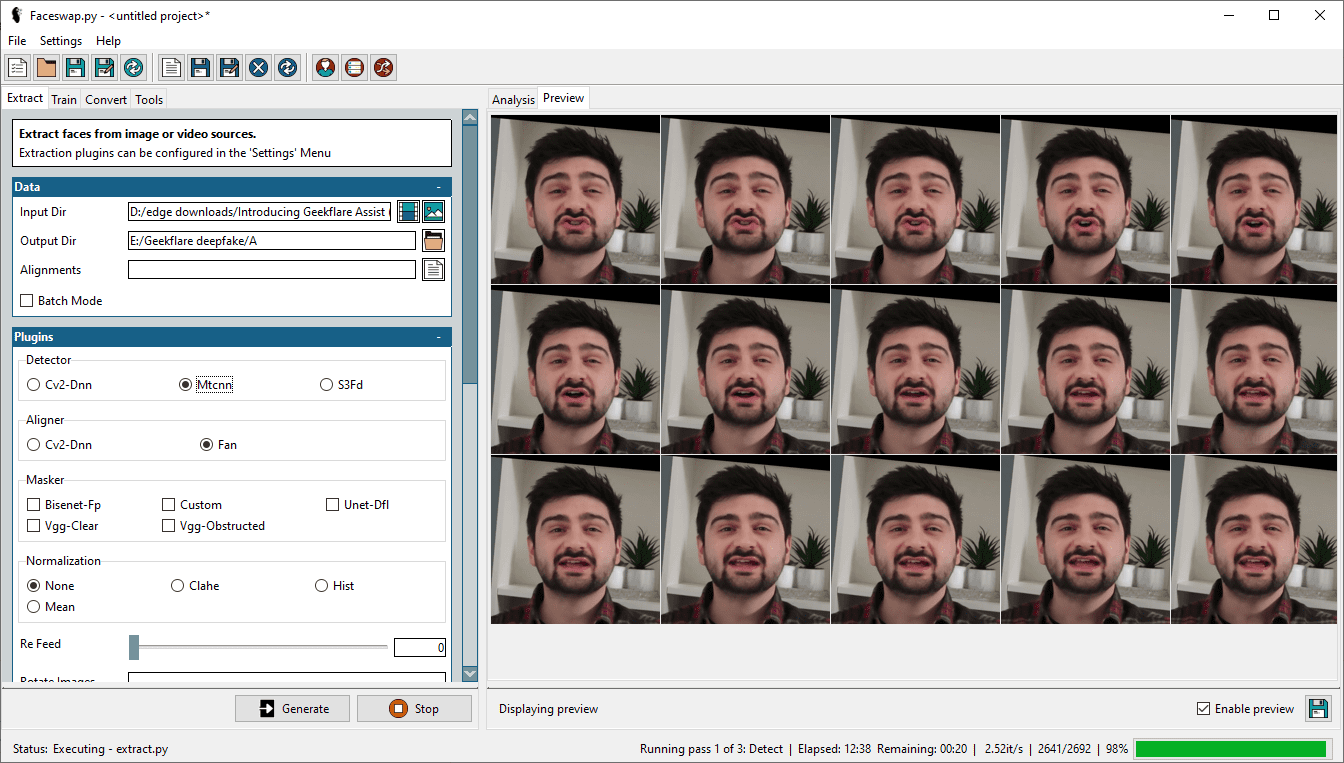
Dostępne są różne opcje, w tym detektor, aligner i masker. Szczegółowe wyjaśnienia każdego z nich znajdują się w sekcji FAQ Faceswap. Powtarzanie tych informacji byłoby niepotrzebne.
 Źródło: Faceswap FAQ
Źródło: Faceswap FAQ
Ogólnie rzecz biorąc, warto zapoznać się z dokumentacją, aby lepiej zrozumieć proces i osiągnąć zadowalający rezultat. W Faceswap dostępne są również pomocne wskazówki, które wyświetlają się po najechaniu kursorem na daną opcję.
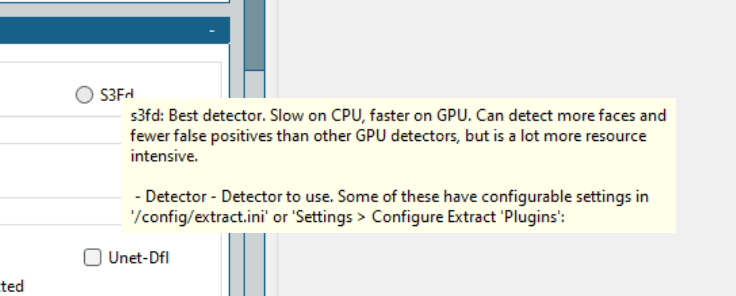
Nie ma uniwersalnej konfiguracji, która sprawdzi się w każdym przypadku. Należy zacząć od wypróbowania najlepszych algorytmów i stopniowo testować inne, aby uzyskać satysfakcjonujący deepfake.
Na potrzeby tego poradnika, użyłem Mtcnn (detektor), Fan (aligner) i Bisenet-Fp (masker), pozostawiając pozostałe opcje bez zmian.
Wcześniej próbowałem z S3Fd (najlepszy detektor) i kilkoma innymi maskami, ale moja karta graficzna Nvidia GeForce GTX 750Ti z 2 GB pamięci nie poradziła sobie z obciążeniem, co wielokrotnie prowadziło do awarii programu.
Ostatecznie obniżyłem oczekiwania i dostosowałem ustawienia.
Oprócz wyboru odpowiedniego detektora, maski itp., w Ustawieniach > Konfiguruj ustawienia, dostępne są dodatkowe opcje, które umożliwiają dostosowanie poszczególnych parametrów, aby zoptymalizować działanie programu na posiadanym sprzęcie.
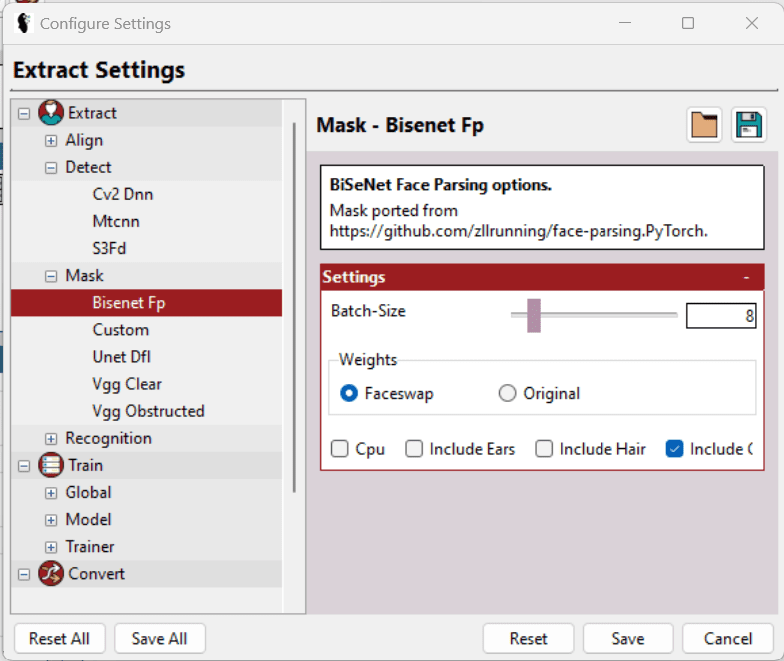
Najlepiej wybrać najmniejszy możliwy rozmiar wsadu, rozmiar wejściowy i wyjściowy, a także włączyć opcję LowMem. Te opcje nie są dostępne uniwersalnie i zależą od konkretnej sekcji. Teksty pomocy ułatwiają wybór najlepszych opcji.
Mimo, że narzędzie doskonale radzi sobie z wyodrębnianiem twarzy, generowane ramki mogą zawierać więcej danych niż jest potrzebne do wytrenowania modelu. Przykładowo, mogą zawierać wszystkie twarze (jeśli na wideo występuje więcej niż jedna osoba) i niektóre błędne detekcje, w których docelowa twarz w ogóle nie występuje.
Dlatego konieczne jest wyczyszczenie zbioru danych. Można przejrzeć folder wyjściowy i ręcznie usunąć zbędne ramki, lub skorzystać z opcji sortowania Faceswap.
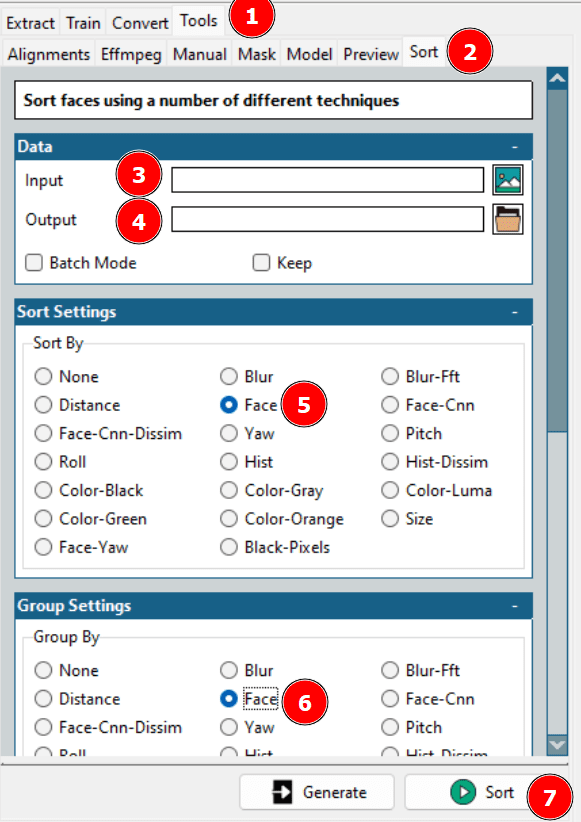
Wykorzystanie powyższej opcji pozwala na posortowanie i uporządkowanie zdjęć twarzy, co umożliwia umieszczenie potrzebnych danych w jednym folderze i usunięcie reszty.
Pamiętaj, że proces ekstrakcji należy powtórzyć dla wideo źródłowego.
Krok 2: Trenowanie modelu
Jest to najbardziej czasochłonna część procesu tworzenia deepfake’a. W tym kroku Wejście A odnosi się do twarzy docelowej, a Wejście B do twarzy źródłowej. Folder Model Dir to miejsce, gdzie zapisane zostaną pliki szkoleniowe.
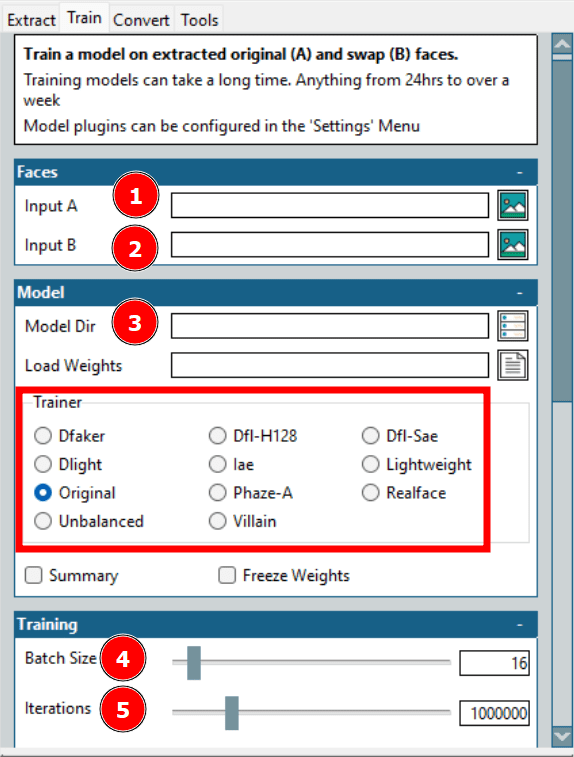
Najważniejszą opcją jest Trener. Dostępnych jest wiele ustawień z możliwością indywidualnego skalowania. W moim przypadku na moim sprzęcie dobrze sprawdziły się opcje Dfl-H128 i Lightweight z najniższymi ustawieniami konfiguracji.
Kolejnym parametrem jest wielkość partii (batch size). Większa wielkość partii skraca całkowity czas uczenia, ale zużywa więcej pamięci VRAM. Liczba iteracji nie ma ustalonego wpływu na rezultat. Należy ustawić wystarczająco wysoką wartość i przerwać uczenie, gdy podglądy będą akceptowalne.
Dostępnych jest jeszcze kilka opcji, w tym tworzenie filmu poklatkowego (timelapse) z ustawionymi interwałami. Ja jednak trenowałem model z absolutnym minimum parametrów.
Krok 3: Zamiana na oryginalne nagranie
To ostatni etap tworzenia deepfake’a.
Zazwyczaj nie trwa on długo. Można eksperymentować z różnymi opcjami, aby szybko uzyskać pożądany efekt.
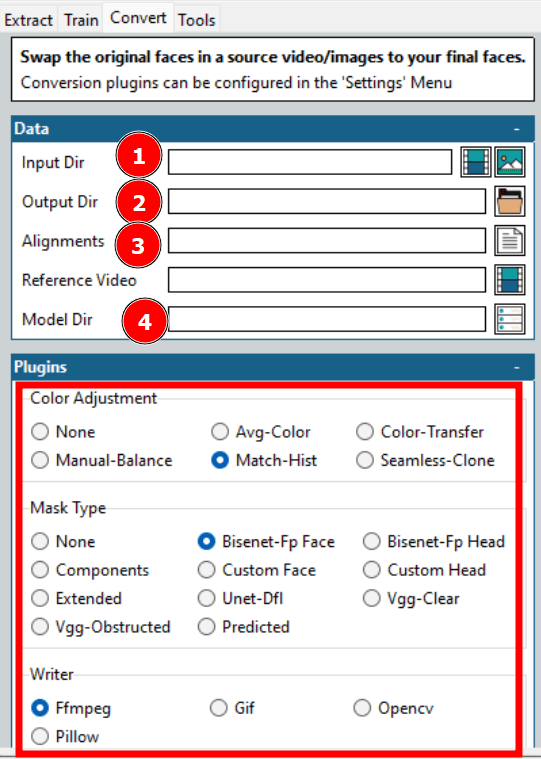
Jak widać na powyższym zrzucie ekranu, konieczne jest wybranie kilku opcji, aby rozpocząć proces konwersji.
Większość opcji została już omówiona, np. katalog wejściowy i wyjściowy, katalog modelu itp. Kluczowe jest wyrównanie, które odnosi się do pliku wyrównania (.fsa) docelowego wideo. Plik ten jest tworzony w katalogu wejściowym podczas ekstrakcji.
Pole Wyrównania można pozostawić puste, jeśli plik nie został przeniesiony. W przeciwnym razie można wskazać plik i przejść do dalszych ustawień. Należy pamiętać o wyczyszczeniu pliku wyrównywania, jeśli wcześniej wyczyszczono wyekstrahowane dane.
W tym celu w Narzędzia > Wyrównania, znajduje się mini narzędzie.
Należy wybrać opcję Usuń powierzchnie w sekcji Zadanie, wskazać oryginalny plik wyrównania oraz folder z oczyszczonymi powierzchniami docelowymi, a następnie kliknąć Wyrównania w prawym dolnym rogu.
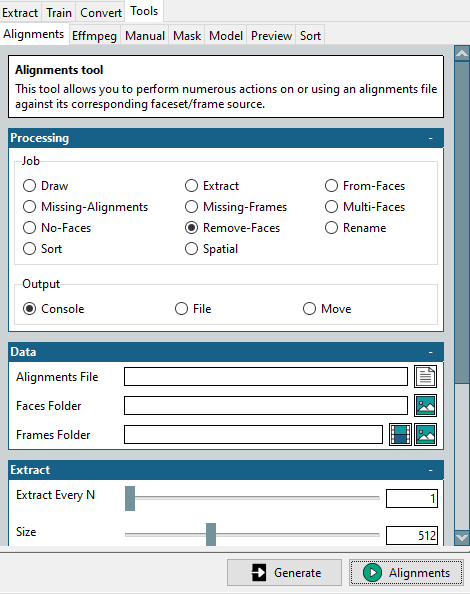
W rezultacie zostanie utworzony zmodyfikowany plik wyrównania, pasujący do folderu ze zoptymalizowanymi powierzchniami. Jest on niezbędny dla docelowego wideo, na które zamierzamy podmienić twarz.
Kilka dodatkowych ustawień obejmuje dostosowanie kolorów i typ maski. Dopasowanie kolorów odpowiada za mieszanie maski. Można wypróbować kilka opcji, sprawdzić podgląd i wybrać najodpowiedniejszą.
Ważniejszy jest typ maski. Jego wybór zależy od oczekiwań i dostępnego sprzętu. Należy również wziąć pod uwagę charakterystykę wejściowego wideo. Przykładowo, Vgg-Clear dobrze sprawdza się w przypadku twarzy skierowanych prosto, bez przeszkód, podczas gdy Vgg-Obstructed może być użyty w sytuacjach, gdy występują przeszkody, takie jak gesty rąk, okulary itp.
Następnie w sekcji Writer znajduje się kilka opcji, w zależności od pożądanego formatu wyjściowego. Na przykład należy wybrać Ffmpeg, aby wygenerować wideo.
Podsumowując, kluczem do udanego deepfake’a jest przejrzenie kilku wyników i zoptymalizowanie ustawień pod kątem dostępnego czasu i mocy sprzętu.
Zastosowania Deepfake’ów
Istnieją dobre, złe i niebezpieczne zastosowania deepfake’ów.
Do dobrych zastosowań należy odtwarzanie wydarzeń historycznych, w których uczestnicy wydarzeń opowiadają o nich z większym zaangażowaniem.
Ponadto deepfake są wykorzystywane przez internetowe platformy edukacyjne do generowania filmów z tekstem.
Jednym z największych beneficjentów będzie przemysł filmowy. Dzięki deepfake można wyobrazić sobie głównego bohatera wykonującego niebezpieczne akrobacje, nawet jeśli w rzeczywistości robi to kaskader. Tworzenie wielojęzycznych filmów staje się również łatwiejsze niż kiedykolwiek.
Jeśli chodzi o złe zastosowania, niestety jest ich wiele. Jak dotąd największe zastosowanie deepfake’ów, 96% (zgodnie z raportem Deeptrace), jest w branży pornograficznej, gdzie twarze celebrytów są podmieniane na twarze aktorów porno.
Co gorsza, deepfake’i są również wykorzystywane jako broń przeciwko „zwykłym” kobietom nie będącym celebrytkami. Zazwyczaj takie ofiary umieszczają w swoich profilach w mediach społecznościowych zdjęcia lub filmy wysokiej jakości, które są wykorzystywane do tworzenia deepfake’ów.
Kolejnym niepokojącym zastosowaniem jest vishing, czyli phishing głosowy. W jednym z takich przypadków dyrektor generalny brytyjskiej firmy przelał 243 000 dolarów na polecenie „dyrektora generalnego” swojej niemieckiej spółki macierzystej, tylko po to, by później dowiedzieć się, że była to fałszywa rozmowa telefoniczna.
Jeszcze bardziej niebezpieczne są deepfake, które mogą wywołać wojnę lub namawiać do poddania się. W jednym z ostatnich przypadków prezydent Ukrainy Wołodymyr Zełenski miał wydać rozkaz swoim wojskom i narodowi poddania się w toczącej się wojnie. Na szczęście słaba jakość wideo ujawniła, że był to fałszerstwo.
Podsumowując, istnieje wiele zastosowań deepfake’ów, a to dopiero początek.
Co prowadzi nas do zasadniczego pytania…
Czy deepfake jest legalny?
W dużej mierze zależy to od lokalnych przepisów. Obecnie tworzone są zdefiniowane przepisy, które określą, co jest dozwolone, a co nie.
Wiadomo jednak, że legalność zależy od przeznaczenia deepfake’a – intencji. Nie ma prawie żadnej szkody, jeśli deepfake ma bawić lub edukować bez naruszania godności osób przedstawionych na nagraniu.
Z drugiej strony, złośliwe aplikacje powinny podlegać karze prawnej, niezależnie od jurysdykcji. Kolejną szarą strefą jest kwestia naruszenia praw autorskich, którą należy odpowiednio rozważyć.
Zawsze należy skonsultować się z lokalnymi organami rządowymi w sprawie legalnych zastosowań deepfake’ów.
Miej się na baczności!
Deepfake wykorzystuje sztuczną inteligencję, aby manipulować wizerunkiem i słowami osób.
Nie ufaj wszystkiemu, co widzisz w Internecie. To pierwsza zasada, którą powinniśmy wdrożyć. Dezinformacja jest powszechna, a jej skuteczność rośnie.
Ponieważ tworzenie deepfake’ów staje się coraz łatwiejsze, nadszedł czas, aby nauczyć się je rozpoznawać.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.