Jak korzystać z $lookup w MongoDB
MongoDB, popularna baza danych NoSQL, organizuje informacje w kolekcjach. Te kolekcje składają się z dokumentów, które są nośnikami rzeczywistych danych zapisanych w formacie JSON. Dokumenty w MongoDB można porównać do wierszy w tradycyjnych bazach danych SQL, a kolekcje do tabel.
Istotną funkcją każdej bazy danych jest możliwość zadawania zapytań o zgromadzone dane. Dzięki zapytaniom możemy selekcjonować potrzebne informacje, przeprowadzać analizy, generować raporty oraz integrować dane.
Aby skutecznie przeszukiwać bazę danych, kluczowe jest łączenie informacji z wielu tabel w bazach SQL lub z wielu kolekcji w bazach NoSQL, w celu uzyskania spójnego zestawu wyników.
W MongoDB operator `$lookup` umożliwia łączenie danych z dwóch kolekcji podczas wykonywania zapytań, realizując działanie analogiczne do lewego sprzężenia zewnętrznego w bazach SQL.
Zastosowanie i cel operatora $lookup
Jednym z głównych celów baz danych jest przetwarzanie danych w taki sposób, by z surowych danych wydobyć wartościowe informacje.
Na przykład, właściciel restauracji może analizować dane sprzedaży, by sprawdzić dzienny utarg, popularność dań w weekendy, czy godzinową sprzedaż kawy.
Do takich analiz, proste zapytania do bazy danych okazują się niewystarczające. Potrzebne są zaawansowane metody przeszukiwania danych. MongoDB oferuje w tym celu tak zwany potok agregacji.
Potok agregacji to mechanizm składający się z szeregu operacji, zwanych etapami, które służą do przetwarzania danych w celu uzyskania zagregowanego rezultatu. Przykłady etapów to: `$sort`, `$match`, `$group`, `$merge`, `$count` i `$lookup`.
Etapy te można układać w potoku agregacji w dowolnej kolejności. Każdy etap wykonuje odmienne operacje na danych, które przepływają przez potok.
`$lookup` jest etapem w potoku agregacji MongoDB, którego zadaniem jest wykonanie lewego sprzężenia zewnętrznego między dwiema kolekcjami. Lewe sprzężenie zewnętrzne łączy wszystkie dokumenty z lewej kolekcji z pasującymi dokumentami z prawej kolekcji.
Dla zobrazowania, przyjmijmy dwie kolekcje, przedstawione w formie tabelarycznej dla lepszego zrozumienia:
zamówienia_odbiór:
order_idcustomer_idorder_datetotal_amount11002022-05-0150.0021012022-05-0275.0031022022-05-03100.00
klienci_kolekcja:
numer_klienta nazwa_klientacustomer_emailcustomer_phone100Jan [email protected] [email protected]
Wykonując lewe sprzężenie zewnętrzne na tych kolekcjach, używając pola `customer_id`, które jest w kolekcji `order_collection`, gdzie `order_collection` jest lewą kolekcją, a `customer_collection` prawą, wynikiem będzie zbiór wszystkich dokumentów z kolekcji `Orders`, połączonych z dokumentami z kolekcji `Customers`, których pole `numer_klienta` odpowiada polu `customer_id` z kolekcji `Orders`.
Efekt końcowy lewego sprzężenia zewnętrznego, prezentowany w formie tabeli, wygląda następująco:
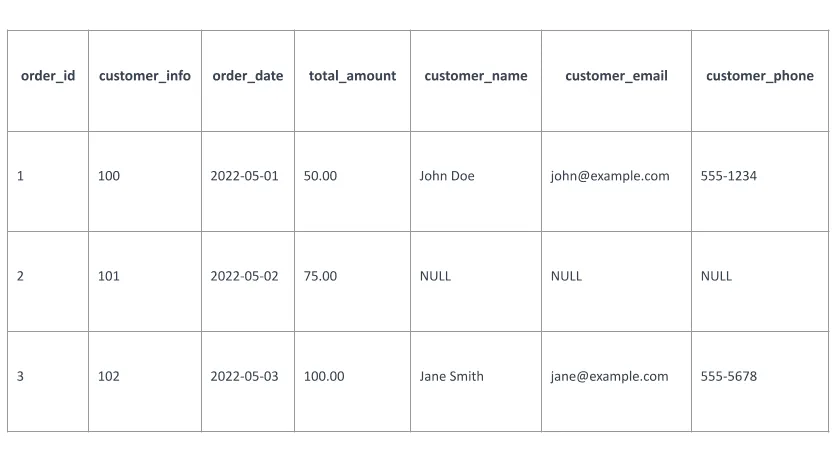
Warto zauważyć, że dla klienta o identyfikatorze `customer_id` równym 101 w zbiorze zamówień, który nie miał odpowiednika w polu `numer_klienta` w zbiorze klientów, brakujące dane z tabeli klientów zostały uzupełnione wartościami `null`.
`$lookup` przeprowadza dokładne porównanie równości między polami i pobiera cały pasujący dokument, a nie tylko wybrane pola.
Składnia `$lookup`
Składnia `$lookup` jest następująca:
{
$lookup:
{
from: <kolekcja do złączenia>,
localField: <pole z dokumentów wejściowych>,
foreignField: <pole z dokumentów kolekcji "from">,
as: <pole wyjściowej tablicy>
}
}
`$lookup` przyjmuje cztery parametry:
- `from` – wskazuje kolekcję, z której chcemy pobrać dokumenty. W naszym wcześniejszym przykładzie z `orders_collection` i `customer_collection`, tutaj umieścilibyśmy `customer_collection`.
- `localField` – to pole w kolekcji roboczej, które jest używane do porównania z polami w kolekcji `from` (w naszym przypadku `customers_collection`). W powyższym przykładzie polem `localField` byłby `identyfikator klienta` z kolekcji `zamówienia`.
- `foreignField` – pole w kolekcji określonej w `from`, do którego porównujemy wartość z `localField`. W naszym przykładzie byłby to `numer_klienta` z kolekcji `klienci`.
- `as` – to nowa nazwa pola, które będzie zawierać tablicę dokumentów wynikających z dopasowań między `localField` a `foreignField`. Wszystkie pasujące dokumenty są umieszczane w tej tablicy. Jeśli nie ma dopasowań, pole to będzie zawierało pustą tablicę.
W kontekście naszych dwóch przykładowych kolekcji, do wykonania operacji `$lookup` użylibyśmy następującego kodu, traktując `zbiór zamówień` jako naszą kolekcję roboczą lub bazową:
{
$lookup: {
from: "customers_collection",
localField: "customer_id",
foreignField: "customer_num",
as: "customer_info"
}
}
Warto zaznaczyć, że nazwa pola `as` może być dowolnym ciągiem znaków. Jeśli jednak nazwa ta pokrywa się z nazwą istniejącego już pola w dokumencie roboczym, to pole zostanie nadpisane.
Łączenie danych z wielu kolekcji
`$lookup` w MongoDB to użyteczny etap potoku agregacji. Choć nie jest wymagane, aby potok agregacji zawierał etap `$lookup`, jest on kluczowy podczas wykonywania złożonych zapytań, które wymagają łączenia danych z różnych kolekcji.
Etap `$lookup` wykonuje lewe sprzężenie zewnętrzne na dwóch kolekcjach, czego rezultatem jest utworzenie nowego pola lub nadpisanie istniejącego pola tablicą, zawierającą dokumenty z innej kolekcji.
Dokumenty te są wybierane na podstawie tego, czy ich wartości pasują do wartości pola, z którym są porównywane. Efektem końcowym jest pole zawierające tablicę dokumentów, jeśli znaleziono dopasowania, lub pustą tablicę, jeśli nie ma dopasowań.
Rozważmy kolekcje pracowników i projektów pokazane poniżej.
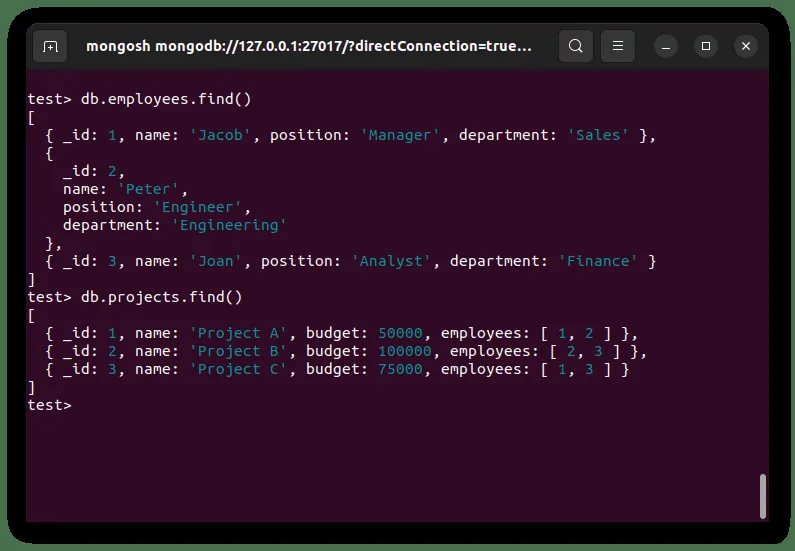
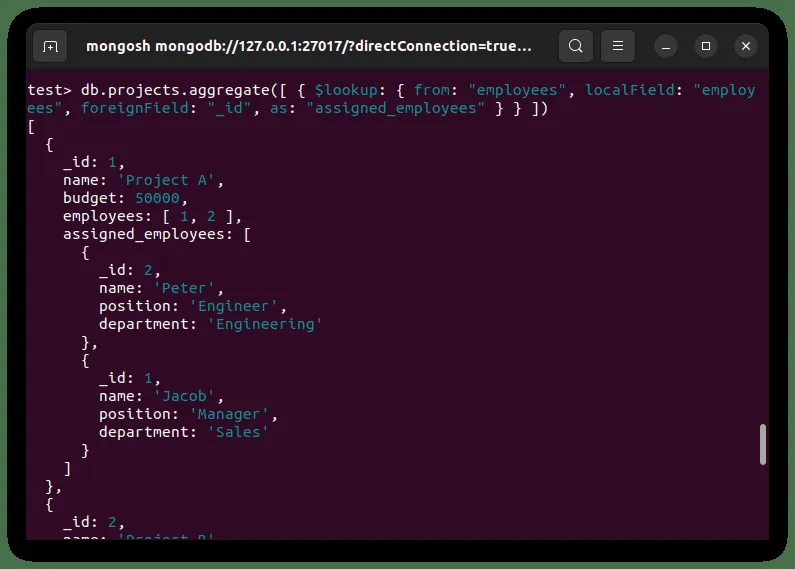
Do połączenia tych dwóch kolekcji, możemy użyć następującego kodu:
db.projects.aggregate([
{
$lookup: {
from: "employees",
localField: "employees",
foreignField: "_id",
as: "assigned_employees"
}
}
])
Wynikiem tej operacji jest połączenie danych z dwóch kolekcji. Otrzymujemy listę projektów wraz z informacjami o wszystkich pracownikach przypisanych do każdego z nich. Pracownicy są przedstawieni w formie tablicy.
Etapy potoku, które można stosować w połączeniu z `$lookup`
Jak wspomniano wcześniej, `$lookup` jest etapem w potoku agregacji MongoDB i można go używać w połączeniu z innymi etapami. Aby zademonstrować, jak te etapy mogą być stosowane razem z `$lookup`, użyjemy dwóch poniższych kolekcji.
W MongoDB dane te są przechowywane w formacie JSON. Tak te kolekcje wyglądają w MongoDB:
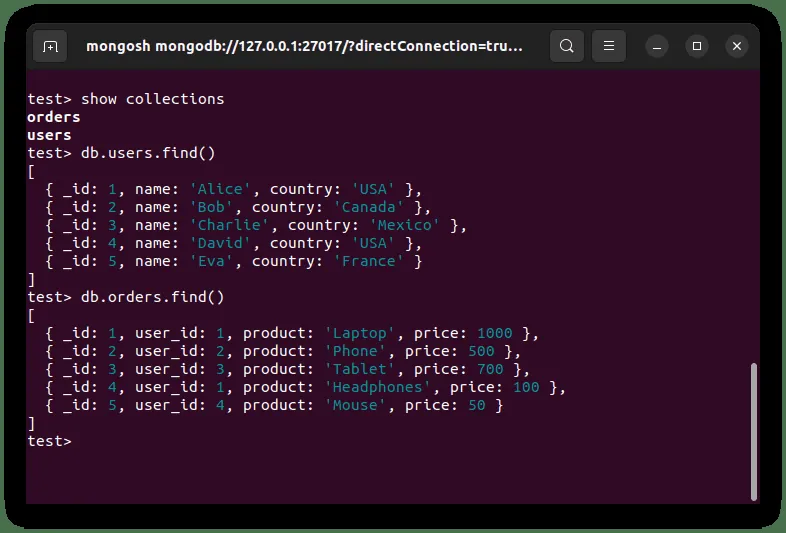
Oto kilka przykładów etapów potoku agregacji, które można stosować razem z `$lookup`:
`$match`
`$match` to etap potoku agregacji, który służy do filtrowania strumienia dokumentów, przepuszczając do następnego etapu jedynie te, które spełniają określony warunek. Najlepiej zastosować ten etap na początku potoku, aby odfiltrować niepotrzebne dokumenty i w ten sposób zoptymalizować cały potok.
W kontekście dwóch wcześniejszych kolekcji, połączenie `$match` i `$lookup` może wyglądać następująco:
db.users.aggregate([
{
$match: {
country: "USA"
}
},
{
$lookup: {
from: "orders",
localField: "_id",
foreignField: "user_id",
as: "orders"
}
}
])
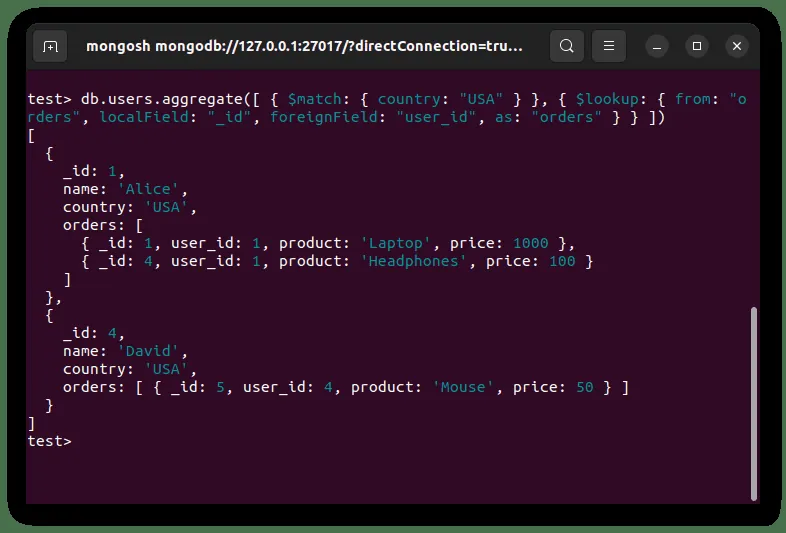
`$match` służy do odfiltrowania użytkowników z USA. Wynik tego etapu jest następnie łączony z wynikiem `$lookup`, by uzyskać szczegóły zamówień użytkowników z USA. Efekt powyższej operacji jest przedstawiony poniżej:
`$project`
`$project` to etap służący do transformacji dokumentów poprzez określenie, które pola mają być uwzględnione, wykluczone lub dodane. Na przykład, jeśli przetwarzamy dokumenty zawierające dziesięć pól, ale tylko cztery z nich są istotne, możemy użyć `$project` do wyfiltrowania niepotrzebnych pól.
Dzięki temu unikamy przesyłania zbędnych danych do kolejnych etapów potoku agregacji.
Połączenie `$lookup` i `$project` może wyglądać następująco:
db.users.aggregate([
{
$lookup: {
from: "orders",
localField: "_id",
foreignField: "user_id",
as: "orders"
}
},
{
$project: {
name: 1,
_id: 0,
total_spent: { $sum: "$orders.price" }
}
}
])
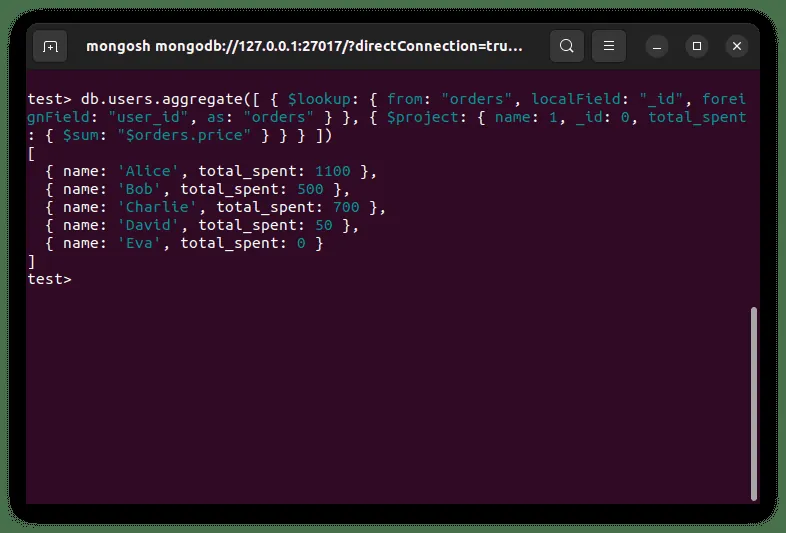
Powyższy kod łączy kolekcje użytkowników i zamówień za pomocą `$lookup`, a następnie `$project` służy do wyświetlenia tylko imienia każdego użytkownika i kwoty, jaką wydał. `$project` usuwa także pole `_id` z wyników. Rezultat powyższej operacji jest widoczny poniżej:
`$unwind`
`$unwind` to etap agregacji służący do dekonstrukcji lub rozwinięcia pola tablicy, tworząc nowe dokumenty dla każdego elementu tej tablicy. Jest przydatny, gdy chcemy przeprowadzić agregację na wartościach pól tablicy.
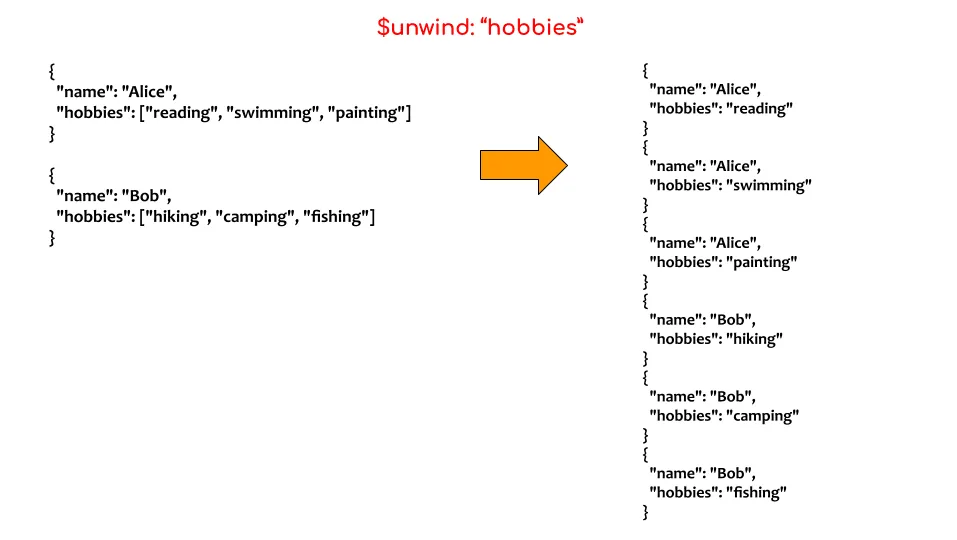
Na przykład, w poniższym przykładzie, jeśli chcemy przeprowadzić agregację dla pola `hobby`, nie możemy tego zrobić, ponieważ jest to tablica. Możemy jednak użyć `$unwind`, a następnie wykonać agregacje na wynikowych dokumentach.
W oparciu o kolekcje użytkowników i zamówień, możemy użyć `$lookup` i `$unwind` w następujący sposób:
db.users.aggregate([
{
$lookup: {
from: "orders",
localField: "_id",
foreignField: "user_id",
as: "orders"
}
},
{
$unwind: "$orders"
}
])
W powyższym kodzie `$lookup` zwraca pole tablicowe o nazwie `orders`. Następnie `$unwind` jest używany do rozwinięcia tej tablicy. Wynik tej operacji został pokazany poniżej: Widać, że Alicja pojawia się dwa razy, ponieważ złożyła dwa zamówienia.
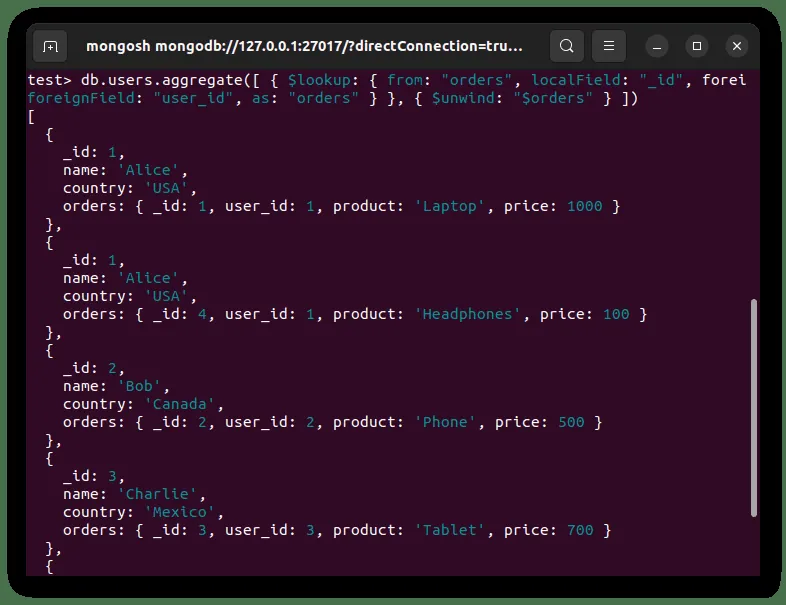
Przykłady zastosowań `$lookup`
`$lookup` jest użytecznym narzędziem podczas przetwarzania danych. Możemy na przykład mieć dwie kolekcje, które chcemy połączyć w oparciu o pola zawierające podobne dane. W tym celu możemy użyć prostego etapu `$lookup`, aby dodać nowe pole do kolekcji bazowych, które będzie zawierało dokumenty pobrane z innej kolekcji.
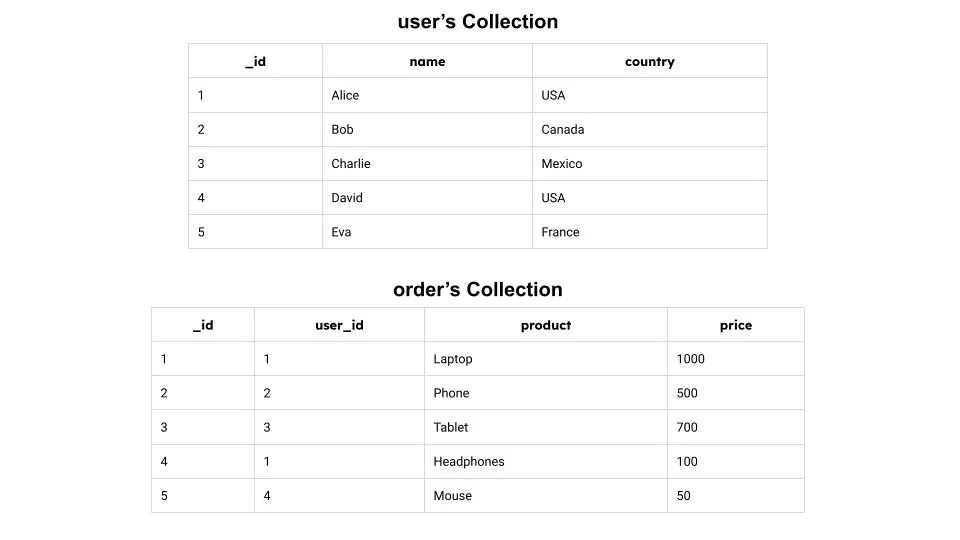
Rozważmy kolekcje użytkowników i zamówień zaprezentowane poniżej:
Te dwie kolekcje można połączyć za pomocą `$lookup`, aby otrzymać wynik przedstawiony poniżej:
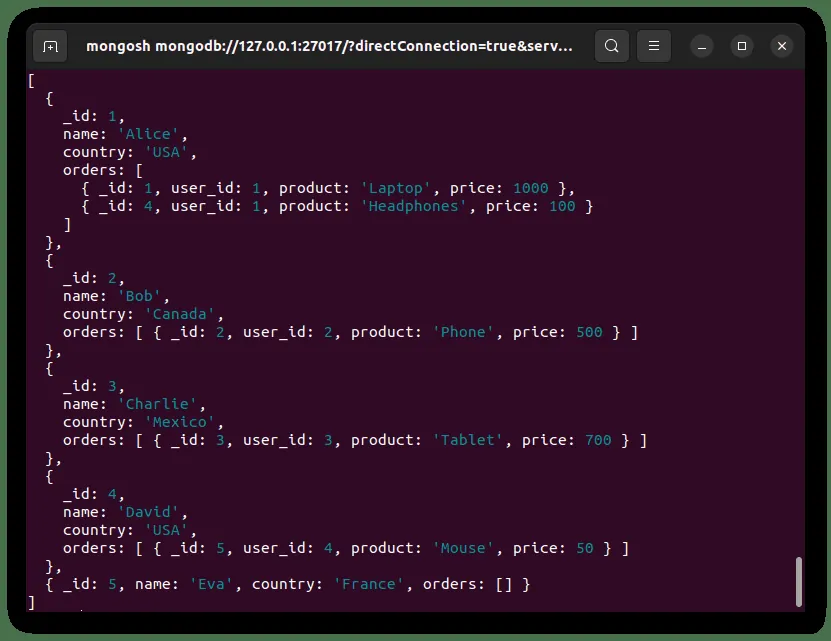
`$lookup` może być również używany do wykonywania bardziej złożonych połączeń. Funkcja `$lookup` nie ogranicza się tylko do łączenia dwóch kolekcji. Możemy zaimplementować wiele etapów `$lookup`, aby wykonać sprzężenia na więcej niż dwóch kolekcjach. Rozważmy trzy kolekcje przedstawione poniżej:
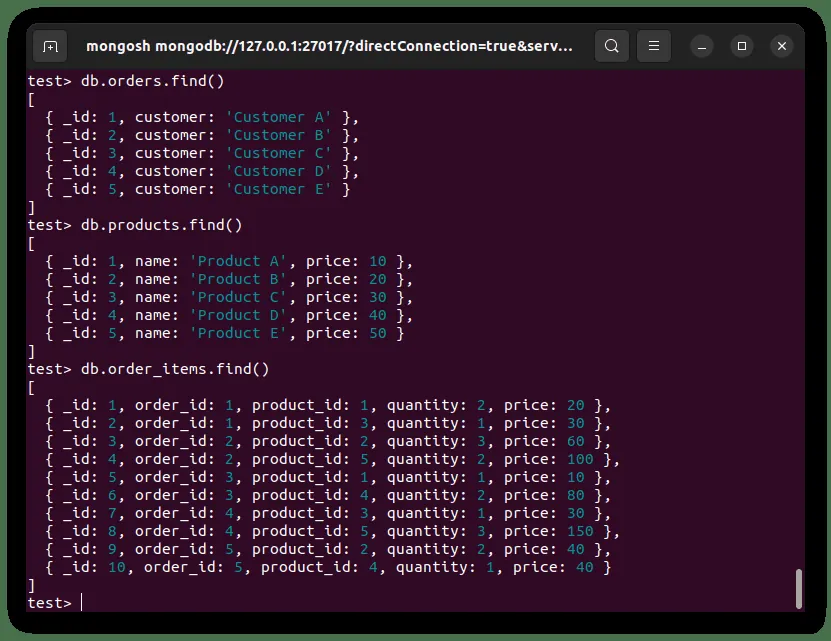
Możemy użyć poniższego kodu, aby przeprowadzić bardziej złożone połączenie trzech kolekcji i uzyskać wszystkie szczegóły zamówień, wraz ze szczegółami zamówionych produktów.
Poniższy kod pozwala to osiągnąć:
db.orders.aggregate([
{
$lookup: {
from: "order_items",
localField: "_id",
foreignField: "order_id",
as: "order_items"
}
},
{
$unwind: "$order_items"
},
{
$lookup: {
from: "products",
localField: "order_items.product_id",
foreignField: "_id",
as: "product_details"
}
},
{
$group: {
_id: "$_id",
customer: { $first: "$customer" },
total: { $sum: "$order_items.price" },
products: { $push: "$product_details" }
}
}
])
Wynik powyższej operacji jest przedstawiony poniżej:
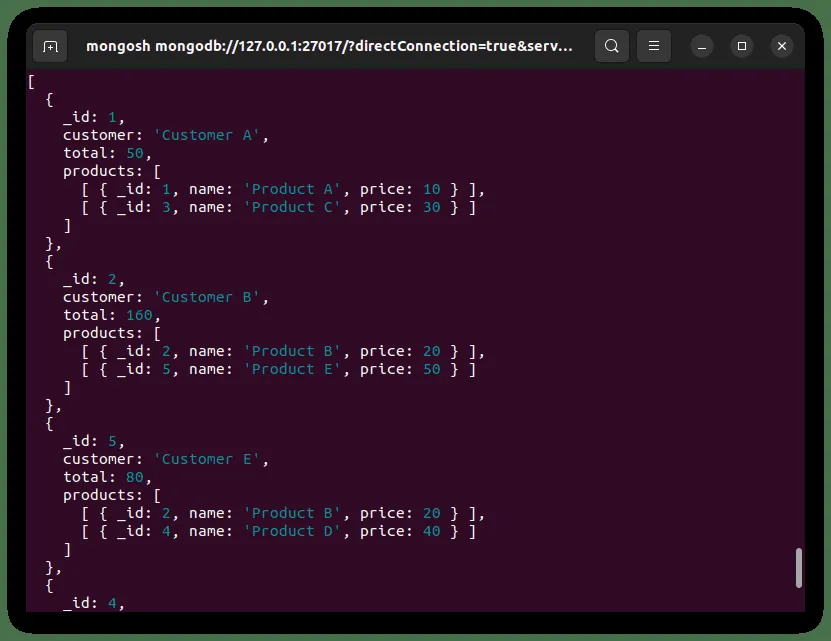
Podsumowanie
Podczas przetwarzania danych pochodzących z wielu kolekcji, funkcja `$lookup` jest bardzo przydatna. Umożliwia ona łączenie danych i wyciąganie wniosków w oparciu o informacje przechowywane w różnych kolekcjach. Przetwarzanie danych rzadko kiedy ogranicza się do jednej kolekcji.
Aby wyciągnąć sensowne wnioski z danych, kluczowym krokiem jest połączenie informacji z różnych kolekcji. Warto rozważyć wykorzystanie etapu `$lookup` w potoku agregacji MongoDB, aby poprawić jakość przetwarzania danych i umożliwić wyciąganie bardziej wartościowych wniosków z nieprzetworzonych danych przechowywanych w różnych kolekcjach.
Warto również zapoznać się z niektórymi poleceniami i zapytaniami MongoDB.
