

Potok agregacji to zalecany sposób uruchamiania złożonych zapytań w MongoDB. Jeśli korzystasz z MapReduce z MongoDB, lepiej przełącz się na potok agregacji, aby uzyskać bardziej wydajne obliczenia.
Spis treści:
Co to jest agregacja w MongoDB i jak działa?
Potok agregacji to wieloetapowy proces uruchamiania zaawansowanych zapytań w MongoDB. Przetwarza dane poprzez różne etapy zwane potokiem. Wyniki wygenerowane z jednego poziomu można wykorzystać jako szablon operacji na innym.
Na przykład możesz przekazać wynik operacji dopasowania do innego etapu w celu posortowania w tej kolejności, aż do uzyskania żądanego wyniku.
Każdy etap potoku agregacji zawiera operator MongoDB i generuje jeden lub więcej przekształconych dokumentów. W zależności od zapytania poziom może pojawić się w potoku wiele razy. Na przykład może być konieczne użycie etapów operatora $count lub $sort więcej niż raz w potoku agregacji.
Etapy potoku agregacji
Potok agregacji przekazuje dane przez wiele etapów w jednym zapytaniu. Etapów jest kilka i ich szczegóły znajdziesz w zakładce Dokumentacja MongoDB.
Zdefiniujmy poniżej niektóre z najczęściej używanych.
Etap $match
Ten etap pomaga zdefiniować określone warunki filtrowania przed rozpoczęciem innych etapów agregacji. Możesz go użyć do wybrania pasujących danych, które chcesz uwzględnić w potoku agregacji.
Faza grupowa $
Etap grupowy dzieli dane na różne grupy w oparciu o określone kryteria przy użyciu par klucz-wartość. Każda grupa reprezentuje klucz w dokumencie wyjściowym.
Rozważmy na przykład następujące przykładowe dane sprzedaży:
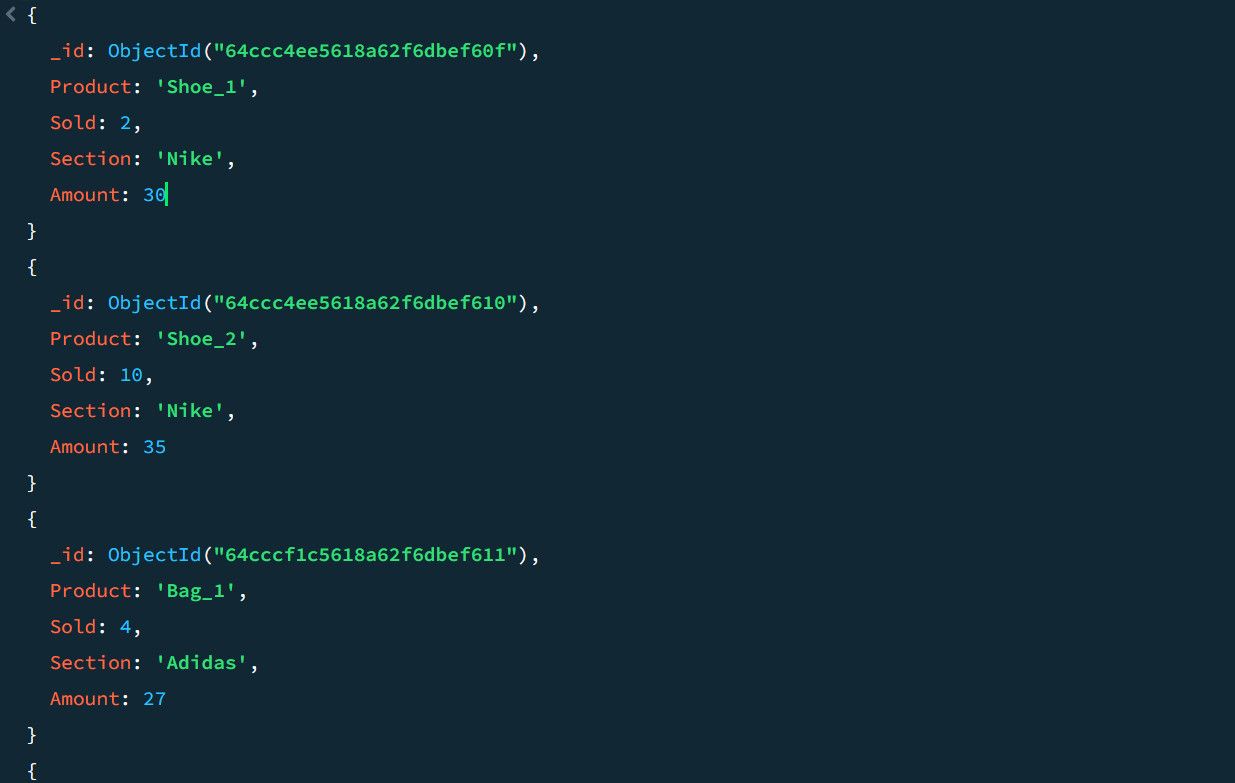
Korzystając z potoku agregacji, możesz obliczyć całkowitą liczbę sprzedaży i najwyższą sprzedaż dla każdej sekcji produktu:
{
$group: {
_id: $Section,
total_sales_count: {$sum : $Sold},
top_sales: {$max: $Amount},
}
}
Para _id: $Section grupuje dokument wyjściowy na podstawie sekcji. Określając pola top_sales_count i top_sales, MongoDB tworzy nowe klucze w oparciu o operację zdefiniowaną przez agregator; może to być suma $, min $, max $ lub średnia $.
Etap $pominięcia
Możesz użyć etapu $skip, aby pominąć określoną liczbę dokumentów w wynikach. Zwykle następuje to po fazie grupowej. Na przykład, jeśli spodziewasz się dwóch dokumentów wyjściowych, ale pominiesz jeden, agregacja wyświetli tylko drugi dokument.
Aby dodać etap pominięcia, wstaw operację $skip do potoku agregacji:
...,
{
$skip: 1
},
Etap $sort
Etap sortowania umożliwia uporządkowanie danych w kolejności malejącej lub rosnącej. Na przykład możemy dalej posortować dane z poprzedniego przykładu zapytania w kolejności malejącej, aby określić, która sekcja ma najwyższą sprzedaż.
Dodaj operator $sort do poprzedniego zapytania:
...,
{
$sort: {top_sales: -1}
},
Etap $limit
Operacja limit pomaga zmniejszyć liczbę dokumentów wyjściowych, które mają być wyświetlane w potoku agregacji. Na przykład użyj operatora $limit, aby uzyskać sekcję o najwyższej sprzedaży zwróconej w poprzednim etapie:
...,
{
$sort: {top_sales: -1}
},{"$limit": 1}
Powyższe zwraca tylko pierwszy dokument; jest to sekcja o najwyższej sprzedaży, wyświetlana na górze posortowanych wyników.
Etap $projektu
Etap $project pozwala na dowolne kształtowanie dokumentu wyjściowego. Za pomocą operatora $project możesz określić, które pole ma zostać uwzględnione w wynikach, i dostosować jego nazwę klucza.
Na przykład przykładowy wynik bez etapu $project wygląda następująco:
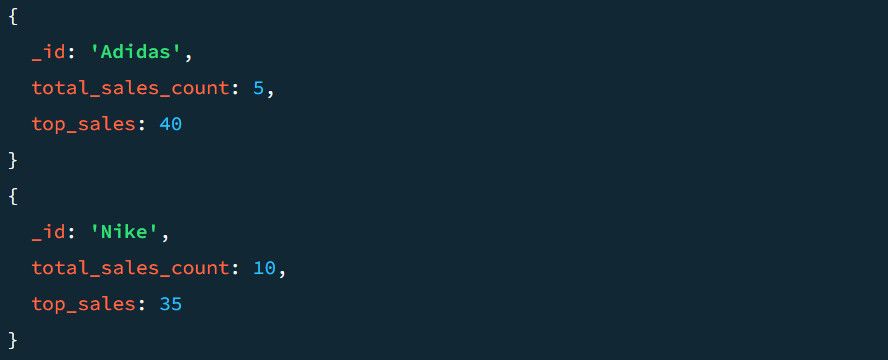
Zobaczmy jak to wygląda na etapie $projektu. Aby dodać projekt $ do potoku:
...,{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
Ponieważ wcześniej grupowaliśmy dane w oparciu o sekcje produktów, powyższe obejmuje każdą sekcję produktu w dokumencie wyjściowym. Zapewnia również, że zagregowana liczba sprzedaży i najwyższa sprzedaż będą widoczne w wynikach jako TotalSold i TopSale.
Ostateczny wynik jest znacznie czystszy w porównaniu do poprzedniego:

Etap $unwind
Etap $unwind dzieli tablicę w dokumencie na pojedyncze dokumenty. Weźmy na przykład następujące dane dotyczące zamówień:
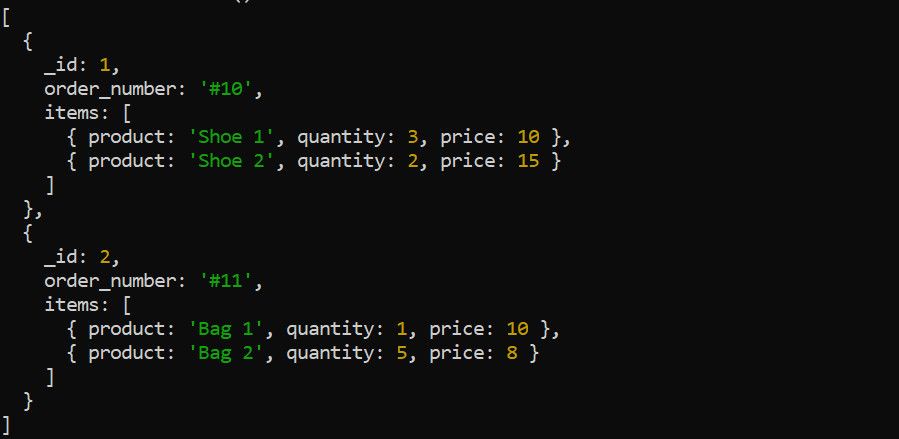
Użyj etapu $unwind, aby zdekonstruować tablicę items przed zastosowaniem innych etapów agregacji. Na przykład rozwinięcie tablicy items ma sens, jeśli chcesz obliczyć całkowity przychód dla każdego produktu:
db.Orders.aggregate(
[
{
"$unwind": "$items"
},
{
"$group": {
"_id": "$items.product",
"total_revenue": { "$sum": { "$multiply": ["$items.quantity", "$items.price"] } }
}
},
{
"$sort": { "total_revenue": -1 }
},{
"$project": {
"_id": 0,
"Product": "$_id",
"TotalRevenue": "$total_revenue",}
}
])
Oto wynik powyższego zapytania agregującego:

Jak utworzyć potok agregacji w MongoDB
Chociaż potok agregacji obejmuje kilka operacji, wcześniej przedstawione etapy dają wyobrażenie o tym, jak zastosować je w potoku, łącznie z podstawowym zapytaniem dla każdej z nich.
Korzystając z poprzedniej próbki danych sprzedażowych, zbierzmy w jednym kawałku niektóre etapy omówione powyżej, aby uzyskać szerszy obraz potoku agregacji:
db.sales.aggregate([{
"$match": {
"Sold": { "$gte": 5 }
}
},{
"$group": {
"_id": "$Section",
"total_sales_count": { "$sum": "$Sold" },
"top_sales": { "$max": "$Amount" },
}},
{
"$sort": { "top_sales": -1 }
},{"$skip": 0},
{
"$project": {
"_id": 0,
"Section": "$_id",
"TotalSold": "$total_sales_count",
"TopSale": "$top_sales",}
}
])
Ostateczny wynik wygląda jak coś, co widziałeś wcześniej:
Potok agregacji a MapReduce
Do czasu wycofania tej usługi, począwszy od MongoDB 5.0, konwencjonalnym sposobem agregowania danych w MongoDB była metoda MapReduce. Chociaż MapReduce ma szersze zastosowania poza MongoDB, jest mniej wydajny niż potok agregacji i wymaga oddzielnego skryptu innej firmy do napisania mapy i osobnej redukcji funkcji.
Z drugiej strony potok agregacji jest specyficzny tylko dla MongoDB. Zapewnia jednak czystszy i wydajniejszy sposób wykonywania złożonych zapytań. Oprócz prostoty i skalowalności zapytań, wyróżnione etapy potoku sprawiają, że dane wyjściowe są bardziej konfigurowalne.
Istnieje znacznie więcej różnic między potokiem agregacji a MapReduce. Zobaczysz je po przejściu z MapReduce do potoku agregacji.
Spraw, aby zapytania Big Data były wydajne w MongoDB
Twoje zapytanie musi być tak wydajne, jak to tylko możliwe, jeśli chcesz przeprowadzić szczegółowe obliczenia na złożonych danych w MongoDB. Potok agregacji jest idealny do zaawansowanych zapytań. Zamiast manipulować danymi w oddzielnych operacjach, co często zmniejsza wydajność, agregacja umożliwia spakowanie ich wszystkich w jednym wydajnym potoku i wykonanie ich jednorazowo.
Chociaż potok agregacji jest bardziej wydajny niż MapReduce, możesz przyspieszyć i zwiększyć wydajność agregacji, indeksując dane. Ogranicza to ilość danych, które MongoDB musi przeskanować na każdym etapie agregacji.