
Fragmentacja bazy danych to technika osiągania skalowalności poziomej w systemach o dużej skali.
Prawie wszystkie rzeczywiste systemy składają się z serwera bazy danych, który otrzymuje wiele żądań odczytu i znaczną liczbę żądań zapisu. Może to spowodować przeciążenie serwera i obniżenie wydajności systemu.
Aby złagodzić takie skutki i poprawić wydajność systemu, istnieją podejścia, takie jak replikacja bazy danych i sharding bazy danych. W tym przewodniku najpierw omówimy techniki poprawiające wydajność systemu, w tym:
- Skalowanie serwera bazy danych
- Replikacja bazy danych
- Podział poziomy
Po omówieniu tych technik przejdziemy do poznania sposobu działania dzielenia bazy danych na fragmenty, a także przyjrzymy się zaletom i ograniczeniom tego podejścia.
Zaczynajmy!
Spis treści:
Techniki poprawy wydajności systemu
Zacznijmy od omówienia technik poprawiania wydajności systemu w przypadku wąskich gardeł związanych z serwerem bazy danych:
# 1. Skalowanie serwera bazy danych
Skalowanie w górę instancji serwera bazy danych może wydawać się prostym podejściem do poprawy wydajności systemu. Obejmuje to zwiększenie mocy obliczeniowej, dodanie większej ilości pamięci RAM i tym podobne.
Jednak ta technika wiąże się z następującym ograniczeniem. Nie możemy mieć serwera z nieskończoną mocą przechowywania i przetwarzania. Powyżej pewnego limitu otrzymujemy malejące zwroty.
#2. Replikacja bazy danych
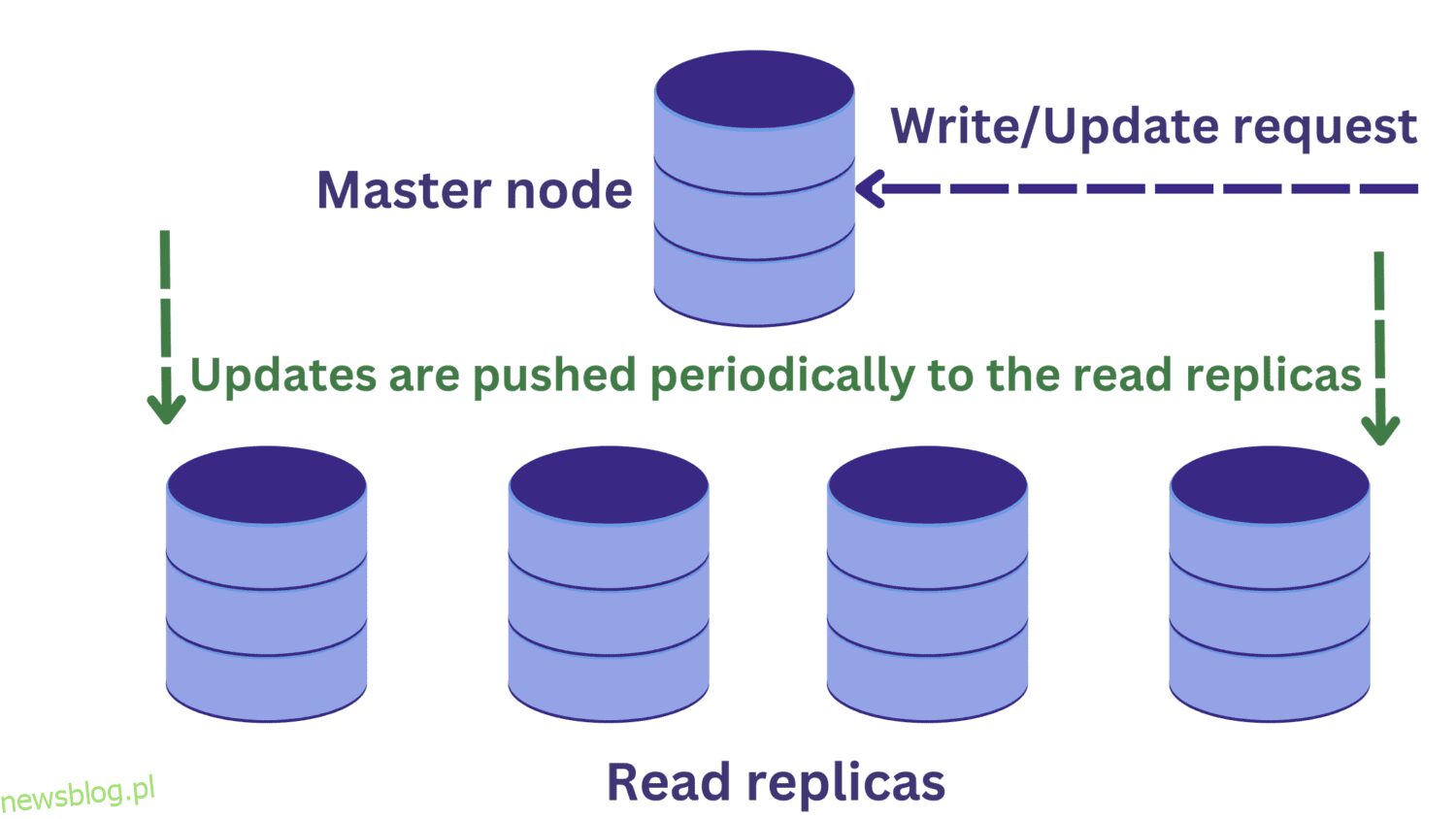
Gdy wystąpi przeciążenie instancji serwera bazy danych z powodu przychodzących żądań, możemy rozważyć replikację bazy danych.
W ramach replikacji bazy danych mamy jeden węzeł główny, który zazwyczaj odbiera żądania zapisu. Istnieje wiele replik do odczytu.
Poprawia to dostępność i zmniejsza przeciążenie systemu. Możemy teraz przetwarzać wiele zapytań równolegle, ponieważ żądania odczytu mogą być kierowane do jednej z replik odczytu.
Ale to wprowadza kolejny problem. Żądania zapisu do węzła głównego mogą zmienić dane, a te aktualizacje są okresowo propagowane do replik odczytu.
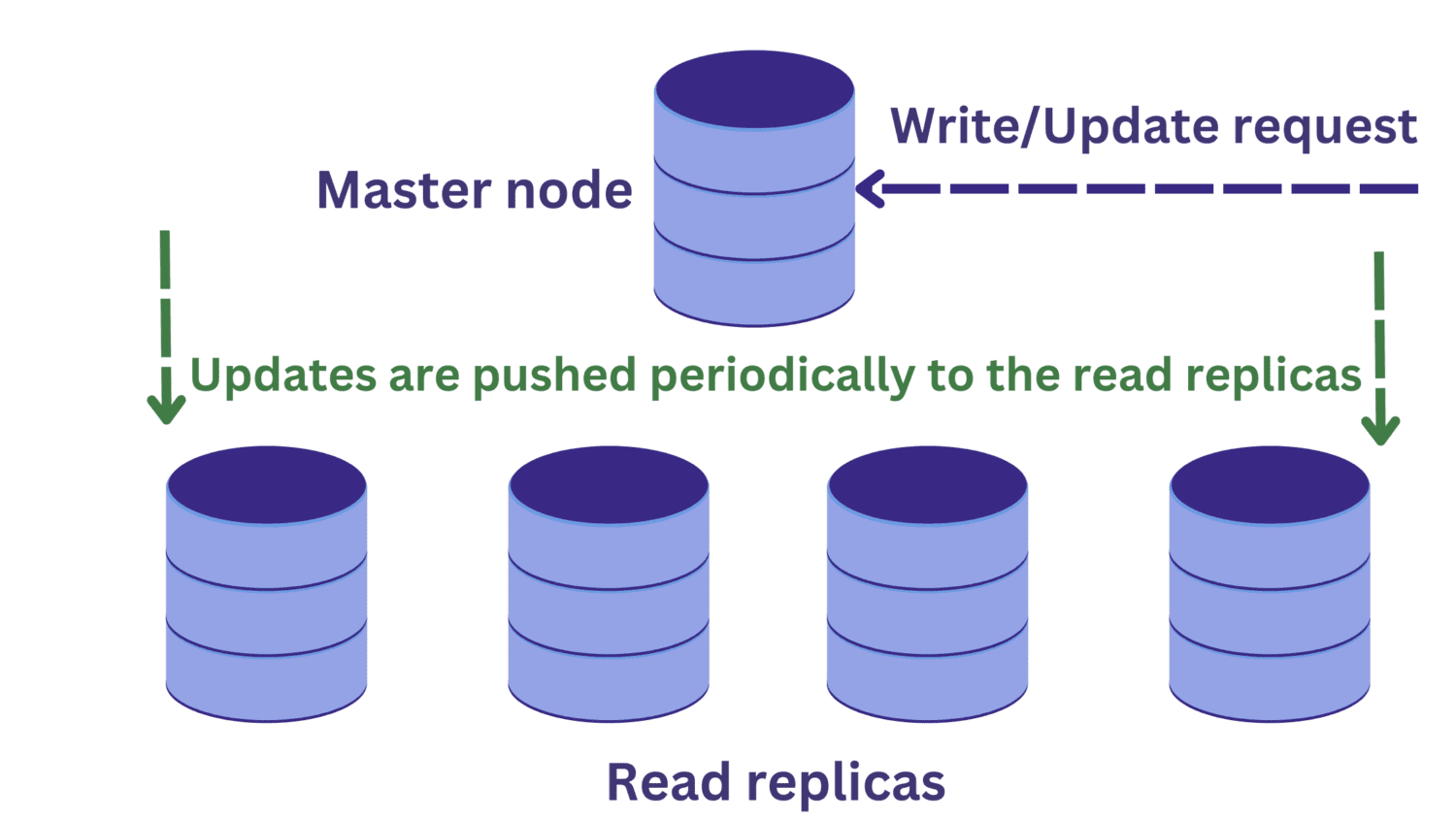
Załóżmy, że istnieje żądanie odczytu do jednej z replik odczytu w tym samym czasie, gdy w węźle głównym trwa operacja zapisu.
Zmiany w węźle głównym nie zostaną jeszcze rozpropagowane do replik do odczytu. W takim przypadku możemy odczytywać nieaktualne dane, co nie jest pożądane.
#3. Partycjonowanie poziome
Partycjonowanie poziome to kolejna technika optymalizacji wydajności systemu. Możemy mieć pojedynczą dużą tabelę z miliardami wierszy (taką jak tabela klientów i dane transakcji).
Operacje odczytu z takiej tabeli bazy danych są wolniejsze. Ale przy użyciu partycjonowania poziomego pojedyncza duża tabela jest teraz podzielona na wiele partycji (lub mniejszych tabel), z których możemy czytać. Relacyjne bazy danych, takie jak PostgreSQL, natywnie obsługują partycjonowanie.
Jednak wszystkie partycje nadal znajdują się w jednej instancji serwera bazy danych. Jedyna różnica polega na tym, że możemy teraz czytać z partycji zamiast z pojedynczej dużej tabeli.
Dlatego w przypadku wzrostu liczby przychodzących żądań serwer może nie być w stanie obsłużyć zwiększonego zapotrzebowania.
Jak działa dzielenie bazy danych?
Teraz, gdy omówiliśmy podejścia do poprawy wydajności systemu i ich ograniczenia, zrozummy, jak działa fragmentacja bazy danych.
Podczas dzielenia na fragmenty dzielimy pojedynczą dużą bazę danych na wiele mniejszych baz danych, z których każda działa na instancji serwera bazy danych. Każda taka mniejsza baza danych nazywana jest fragmentem. A każdy fragment zawiera unikalny podzbiór danych.
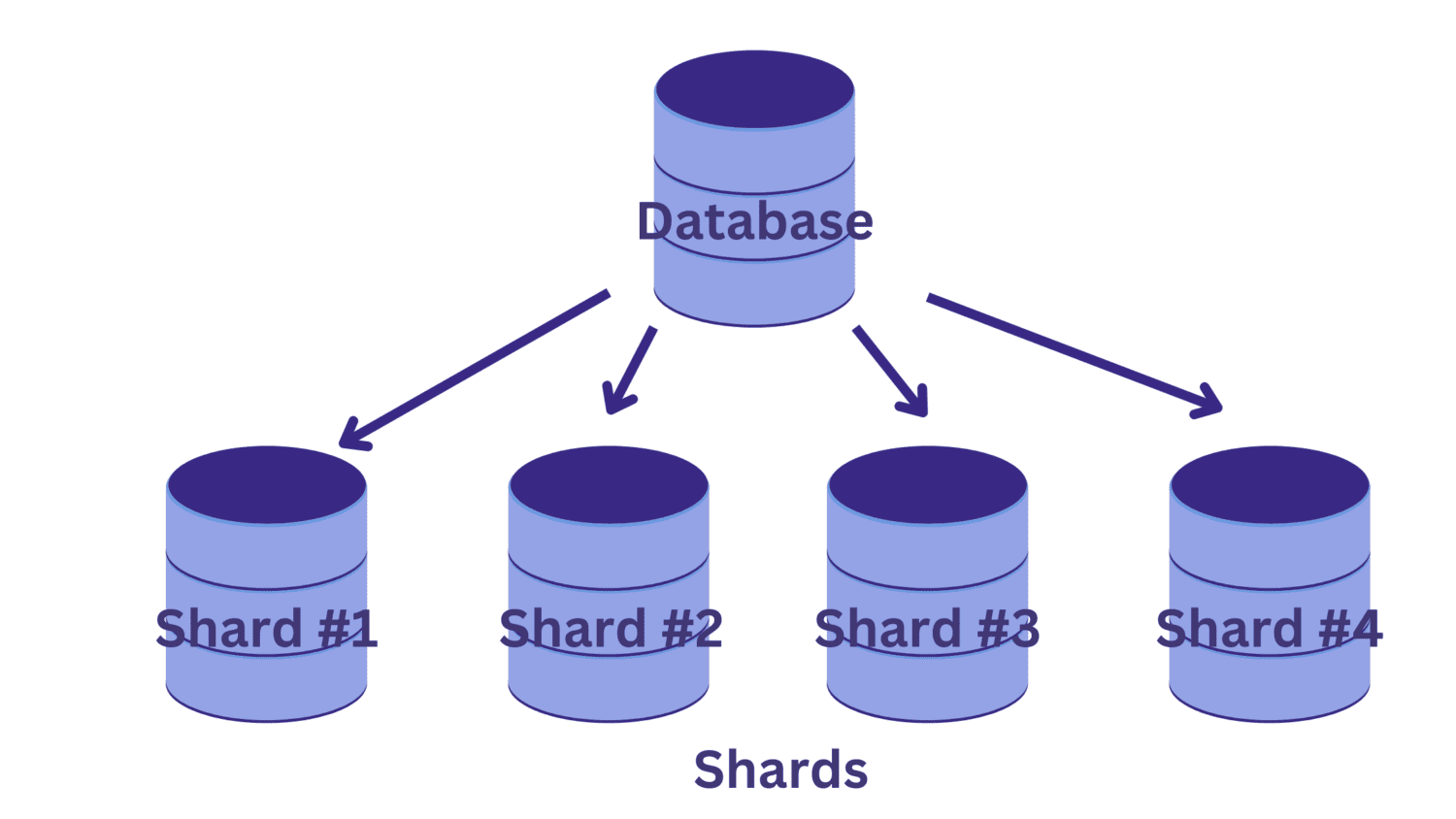
Ale jak podzielić bazę danych na fragmenty? A jak określić, który z rzędów trafia do którego fragmentu?
🔑 Wprowadź klucz podziału.
Zrozumienie klucza Sharding
Przyjrzyjmy się roli klucza shardingu.
Klucz podziału na fragmenty, który zwykle jest kolumną (lub kombinacją kolumn) w tabeli bazy danych, powinien być wybrany w taki sposób, aby dystrybucja danych była równomierna na wielu fragmentach. Ponieważ nie chcemy, aby konkretny odłamek był znacznie większy niż inne odłamki.
W bazie danych przechowującej dane o klientach i transakcjach identyfikator_klienta jest dobrym kandydatem na klucz dzielenia na części.
Kiedy już zdecydujemy się na klucz podziału na fragmenty, możemy wymyślić funkcję haszującą, która określa, który z wierszy trafia do którego z fragmentów.
W tym przykładzie powiedzmy, że musimy podzielić bazę danych na pięć fragmentów (od fragmentu nr 0 do fragmentu nr 4) przy użyciu identyfikatora_klienta jako klucza podziału na fragmenty. W tym przypadku prostą funkcją haszującą jest customer_ID % 5.
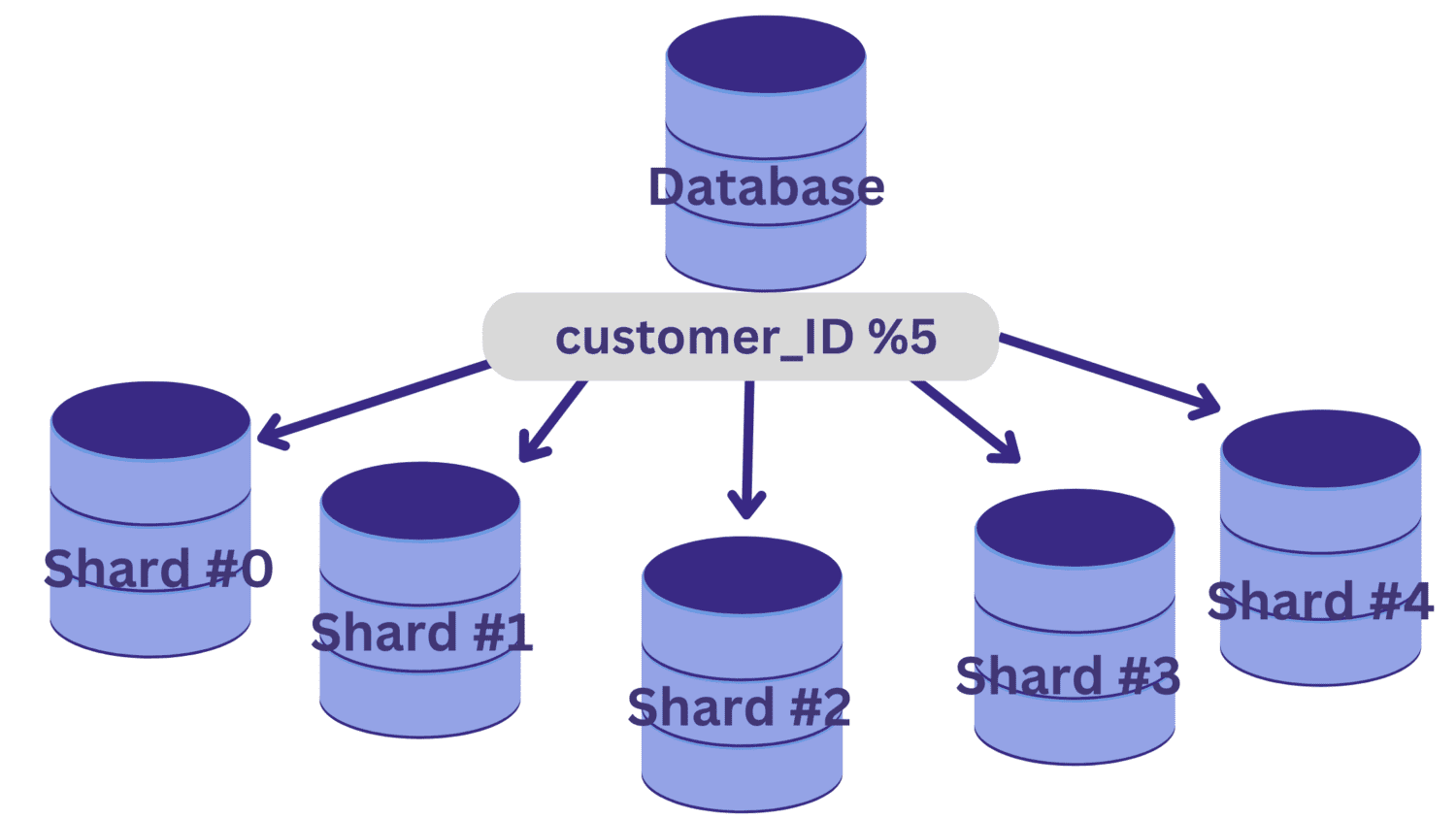
Wszystkie wartości customer_ID, które przy dzieleniu przez 5 pozostawiają resztę zerową, zostaną zmapowane na fragment nr 0. A wartości customer_ID, które pozostawiają resztę od 1 do 4, będą mapowane odpowiednio na fragmenty od 1 do 4.
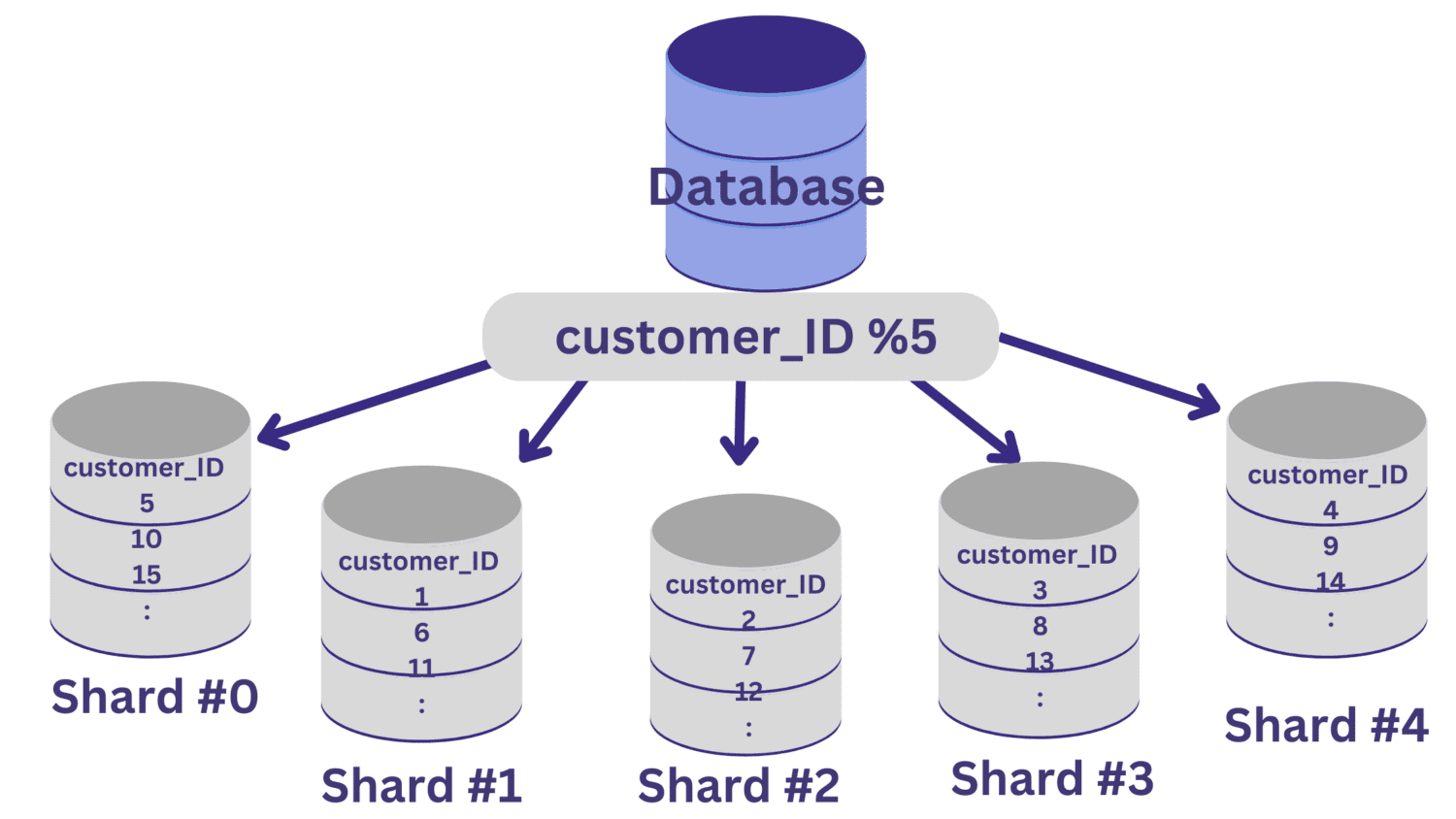
Po zaimplementowaniu dzielenia bazy danych na fragmenty w ten sposób ważne jest, aby mieć warstwę routingu, która kieruje żądania przychodzące do odpowiedniego fragmentu bazy danych.
Zalety dzielenia bazy danych
Oto niektóre zalety shardingu bazy danych:
# 1. Wysoka skalowalność
Zawsze istnieje możliwość podzielenia większej bazy danych na wiele mniejszych fragmentów. Tak więc sharding bazy danych pozwala nam na skalowanie w poziomie.
#2. Duża dostępność
Gdy istnieje pojedyncza instancja serwera bazy danych, która obsługuje wszystkie przychodzące żądania, mamy do czynienia z pojedynczym punktem awarii. Jeśli serwer bazy danych nie działa, cała aplikacja jest wyłączona.
W przypadku dzielenia bazy danych na fragmenty prawdopodobieństwo, że wszystkie fragmenty bazy danych przestaną działać w danej chwili, jest stosunkowo niskie. W związku z tym, jeśli określony fragment nie działa, nie będziemy mogli przetwarzać żądań odczytu do tego fragmentu. Ale inne fragmenty nadal mogą przetwarzać przychodzące żądania. Skutkuje to wysoką dostępnością i zwiększoną odpornością na awarie.
Ograniczenia dzielenia bazy danych
Przyjrzyjmy się teraz niektórym ograniczeniom dzielenia bazy danych na fragmenty:
# 1. Złożoność
Chociaż sharding ma zalety pod względem skalowalności i odporności na uszkodzenia, wprowadza złożoność do systemu.
Od mapowania rekordów do partycji po implementację warstwy routingu w celu kierowania zapytań do odpowiednich fragmentów — z bazami danych dzielonymi na fragmenty wiąże się znaczna złożoność.
#2. Ponowne udostępnianie
Kolejnym ograniczeniem shardingu jest konieczność ponownego shardingu.
Chociaż używamy funkcji haszującej, aby uzyskać równomierny rozkład rekordów danych, możliwe jest, że jeden z fragmentów jest znacznie większy niż inne i może się wcześniej wyczerpać. W tym przypadku musimy wziąć pod uwagę ponowne shardowanie (lub przetasowanie), a to wiąże się ze znacznymi kosztami.
#3. Uruchamianie złożonych zapytań
Gdy musisz uruchomić zapytania do analizy, które obejmują sprzężenia, musisz użyć rekordów z wielu fragmentów, a nie z jednej bazy danych. Może to być więc wyzwaniem, gdy trzeba uruchomić zbyt wiele zapytań analitycznych. Można to obejść, denormalizując bazy danych, ale nadal wymaga to pewnego wysiłku!
Wniosek
Zakończmy dyskusję podsumowaniem tego, czego się nauczyliśmy.
Skalowanie sprzętu nie zawsze jest optymalne. Dlatego wzmacnianie instancji serwera nie jest zalecane. Dokonaliśmy również przeglądu technik, takich jak replikacja bazy danych i partycjonowanie poziome, oraz ich ograniczeń.
Następnie dowiedzieliśmy się, jak działa fragmentacja bazy danych, dzieląc dużą bazę danych na mniejsze i łatwe w zarządzaniu fragmenty. Omówiliśmy, w jaki sposób należy starannie wybrać klucz shardingu, aby uzyskać równe partycje i potrzebę warstwy routingu do kierowania przychodzących żądań do właściwego fragmentu bazy danych.
Fragmentacja bazy danych ma zalety, takie jak wysoka dostępność i skalowalność. Niektóre wady obejmują złożoność konfigurowania shardingu i ponownego shardingu, gdy jeden lub więcej odłamków zostanie wyczerpanych.
Możesz więc rozważyć sharding, gdy uważasz, że korzyści przewyższają złożoność wprowadzoną przez sharding. Następnie sprawdź porównanie różnych relacyjnych baz danych AWS.