Jak korzystać z polecenia grep w systemie Linux
Polecenie grep w systemach Linux to potężne narzędzie, które służy do wyszukiwania ciągów oraz wzorców w plikach, a także w danych przekazywanych z innych poleceń. W tym artykule przedstawimy, jak skutecznie z niego korzystać.
Geneza grep
Polecenie grep jest dobrze znane w środowisku Linux i Unix z trzech powodów: jest bardzo użyteczne, oferuje bogaty zestaw opcji, co może być przytłaczające, a także powstało w odpowiedzi na konkretną potrzebę. Dwa pierwsze powody są oczywiste, natomiast trzeci może wydawać się mniej istotny.
Ken Thompson wydobył funkcjonalność wyszukiwania wyrażeń regularnych z edytora ed (wymawiane ee-dee) i stworzył mały program, który miał na celu przeszukiwanie plików tekstowych. Jego przełożony w Bell Labs, Doug McIlroy, zwrócił się do Thompsona z prośbą o rozwiązanie problemu, który dotyczył jego współpracownika, Lee McMahon.
McMahon próbował ustalić autorstwo Pism Federalnych poprzez analizę tekstu i potrzebował narzędzia do wyszukiwania fraz w plikach tekstowych. Thompson poświęcił wieczór na rozwinięcie swojego narzędzia, aby mogło być używane przez innych, i nadał mu nazwę grep, co pochodzi od polecenia ed g/re/p, oznaczającego „globalne wyszukiwanie wyrażeń regularnych”.
Możesz obejrzeć rozmowę Thompsona z Brianem Kernighanem na temat powstania grepa.
Podstawowe wyszukiwanie z grep
Aby wyszukać określony ciąg w pliku, wystarczy wpisać szukany termin oraz nazwę pliku w terminalu:

Wynikiem będą linie, które pasują do wyszukiwanego terminu. W tym przypadku jest to jedna linia, a dopasowany tekst jest podświetlony, co wynika z aliasu domyślnego w większości dystrybucji, który ustawia:
alias grep='grep --colour=auto'
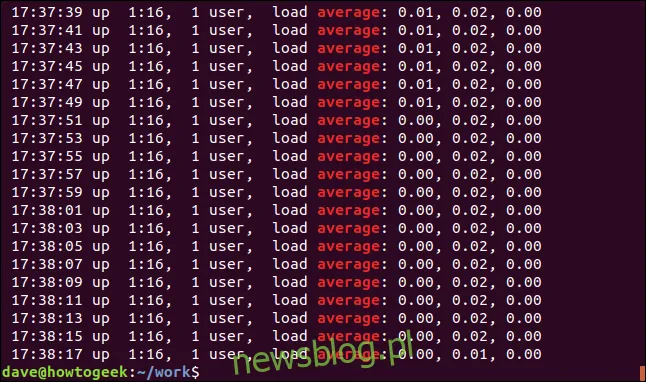
Przyjrzyjmy się sytuacji, gdy w pliku jest wiele dopasowanych linii. Poszukamy słowa „Średnia” w pliku dziennika aplikacji. Ponieważ nie pamiętamy, czy słowo w pliku dziennika jest zapisane wielką literą, użyjemy opcji -i (ignoruj wielkość liter):
grep -i Average geek-1.log

Wynik pokaże każdą pasującą linię z podświetlonym tekstem.
Aby zobaczyć linie, które nie pasują do wyszukiwanego terminu, możemy użyć opcji -v (odwróć dopasowanie).
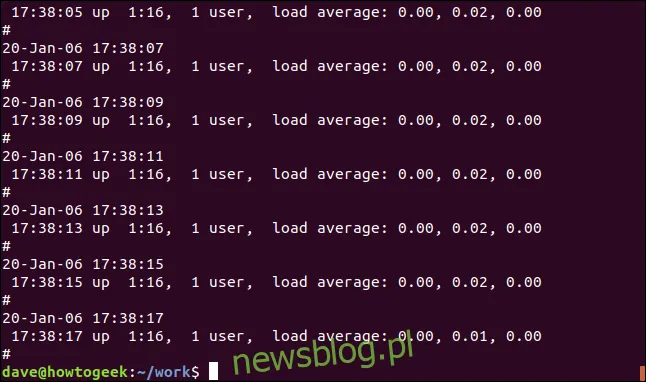
grep -v Mem geek-1.log

W tym przypadku nie ma podświetlenia, ponieważ zwracane są tylko niepasujące linie.
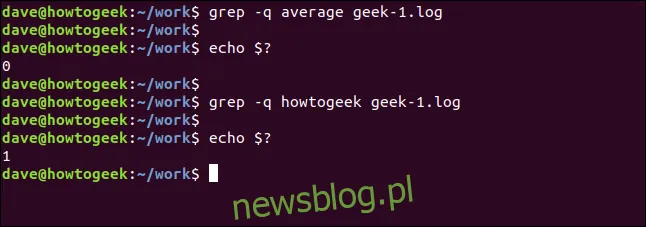
Możemy również sprawić, aby grep pracował w trybie cichym. W takim przypadku wynik jest zwracany do powłoki jako kod wyjścia grepa. Kod zero oznacza, że ciąg został znaleziony, a jeden, że nie został. Możemy sprawdzić kod zwrotny używając specjalnych parametrów:
grep -q average geek-1.log
echo $?
grep -q newsblog.pl geek-1.log
echo $?
Rekurencyjne wyszukiwanie z grep
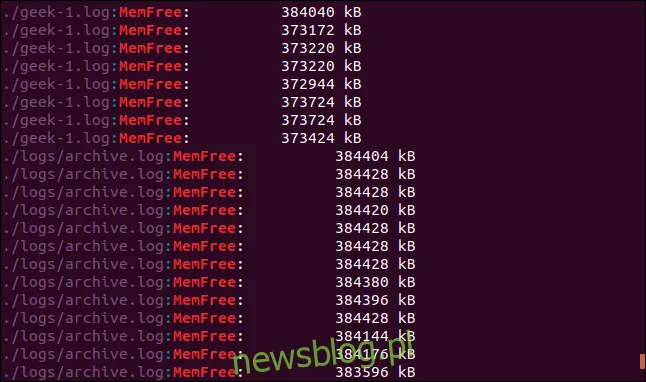
Aby przeszukać katalogi i podkatalogi, należy użyć opcji -r (rekurencyjnie). W tym przypadku nie podajemy nazwy pliku, a jedynie ścieżkę. Szukamy w bieżącym katalogu „.” oraz we wszystkich podkatalogach:
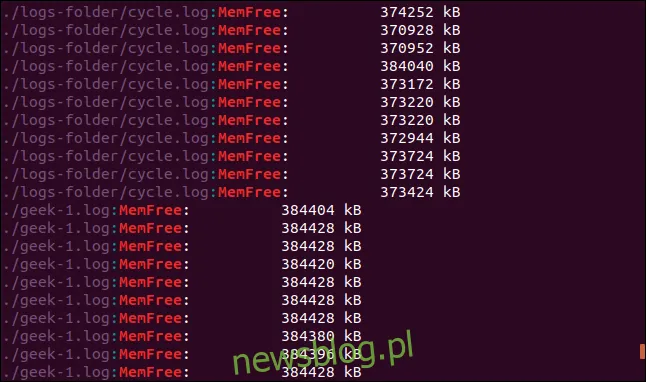
grep -r -i memfree .

Wyniki będą zawierały ścieżkę i nazwę pliku dla każdej pasującej linii.
Możemy również sprawić, że grep będzie podążał za dowiązaniami symbolicznymi, korzystając z opcji -R (rekursywne wyłuskiwanie). W naszym katalogu mamy dowiązanie symboliczne do folderu logs, które wskazuje na /home/dave/logs.
ls -l logs-folder

Powtórzmy nasze ostatnie wyszukiwanie z opcją -R (rekursywne wyłuskiwanie):
grep -R -i memfree .

Dzięki temu grep przeszuka również katalog, na który wskazuje dowiązanie symboliczne.
Wyszukiwanie pełnych słów
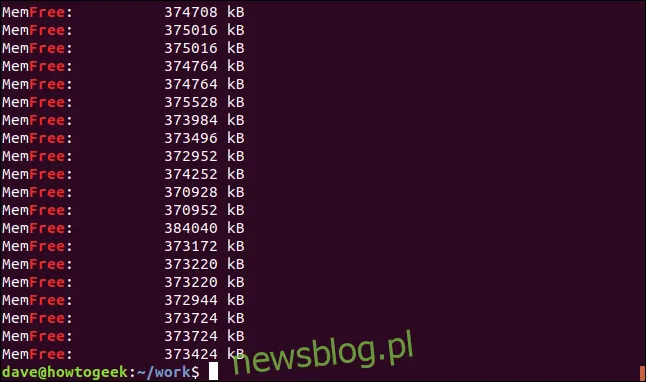
Domyślnie grep dopasowuje linię, jeśli szukany termin występuje w dowolnym miejscu w tej linii. Spójrzmy na przykład, w którym szukamy frazy „za darmo”.
grep -i free geek-1.log

Wynik pokaże linie zawierające ciąg „wolny”, ale nie będą to oddzielne słowa, ponieważ są częścią wyrażenia „MemFree”.
Aby wymusić dopasowywanie tylko oddzielnych „słów”, użyj opcji -w (wyrażenie regularne):
grep -w -i free geek-1.log
echo $?
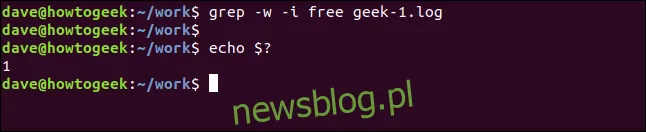
W tym przypadku nie ma wyników, ponieważ szukany termin „wolny” nie występuje w pliku jako osobne słowo.
Wykorzystanie wielu wyszukiwanych haseł
Opcja -E (rozszerzone wyrażenia regularne) pozwala na wyszukiwanie wielu terminów. (Opcja -E zastępuje przestarzałe egrep).
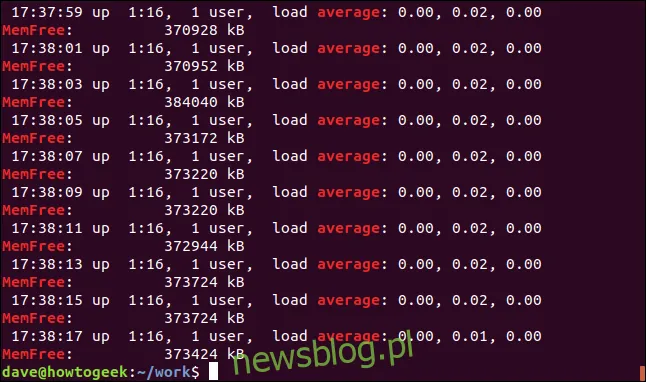
To polecenie wyszukuje dwa hasła: „średni” i „bez memów”.
grep -E -w -i "average|memfree" geek-1.log

Wszystkie pasujące linie zostaną wyświetlone dla każdego z wyszukiwanych terminów.
Możemy także wyszukiwać wiele terminów, które nie są koniecznie pełnymi słowami, ale mogą być nimi.
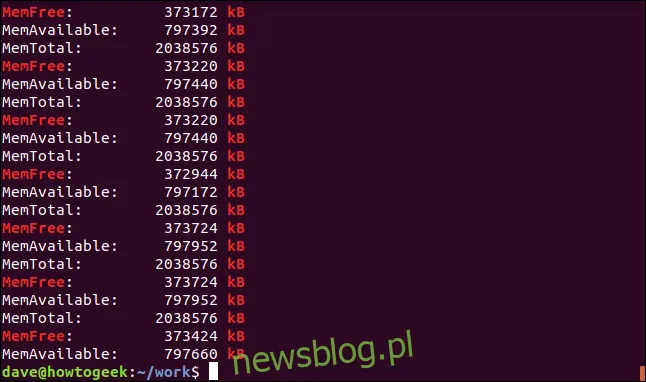
Opcja -e (wzory) pozwala na użycie wielu terminów wyszukiwania w jednym poleceniu. Korzystając z nawiasów w wyrażeniach regularnych, możemy stworzyć wzorzec wyszukiwania, który każe grepowi dopasować dowolny z znaków zawartych w nawiasach „[].” Oznacza to, że grep podczas wyszukiwania dopasuje zarówno „kB”, jak i „KB”.

Oba ciągi zostaną dopasowane, a niektóre linie będą zawierać oba.
Ścisłe dopasowanie linii
Opcja -x (wyrażenie regularne linii) dopasowuje jedynie te linie, które całkowicie odpowiadają wyszukiwanemu terminowi. Sprawdźmy datę i godzinę, która jest znana z jednokrotnego wystąpienia w pliku dziennika:
grep -x "20-Jan--06 15:24:35" geek-1.log

Jedna linia, która pasuje, zostanie wyświetlona.
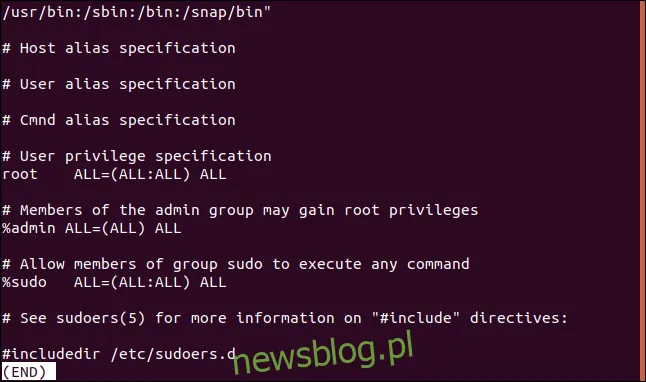
Możemy także wyświetlić jedynie linie, które nie pasują. Może to być przydatne, gdy przeglądamy pliki konfiguracyjne. Komentarze mogą być pomocne, ale czasami trudno jest odnaleźć rzeczywiste ustawienia. Oto przykład pliku /etc/sudoers:
Możemy skutecznie przefiltrować linie komentarzy w ten sposób:
sudo grep -v "https://www.newsblog.pl.com/496056/how-to-use-the-grep-command-on-linux/#" /etc/sudoers
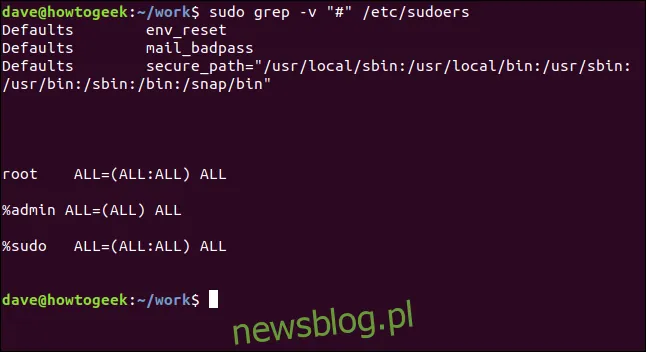
To znacznie ułatwia analizę.
Pokazywanie tylko dopasowanego tekstu
Czasami może być konieczne zobaczenie wyłącznie pasującego tekstu, a nie całych linii. Opcja -o (tylko dopasowanie) wykonuje właśnie to.
grep -o MemFree geek-1.log

Wynik ogranicza się do wyświetlania tylko tekstu, który pasuje do wyszukiwanego terminu, bez pełnych linii.

Liczenie z użyciem grepa
grep to nie tylko narzędzie do wyszukiwania tekstu, ale także może dostarczać informacji liczbowych. Możemy użyć go do zliczania wystąpień danego hasła w pliku, korzystając z opcji -c (liczba).
grep -c average geek-1.log

grep poinformuje nas, że szukane hasło pojawia się 240 razy w tym pliku.
Możemy również zmusić grep do wyświetlania numerów linii dla każdej pasującej linii, używając opcji -n (numer linii).
grep -n Jan geek-1.log

Numer linii dla każdego dopasowanego wiersza jest wyświetlany na początku danej linii.
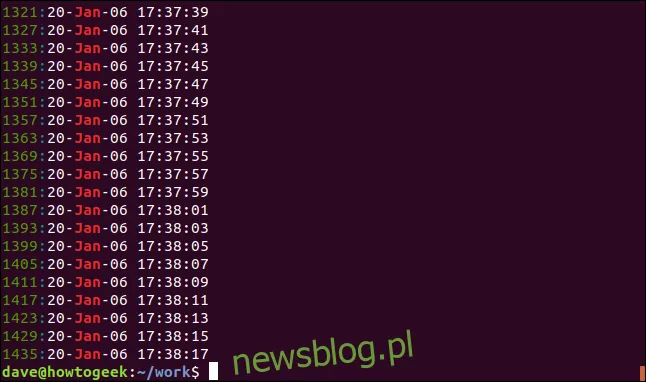
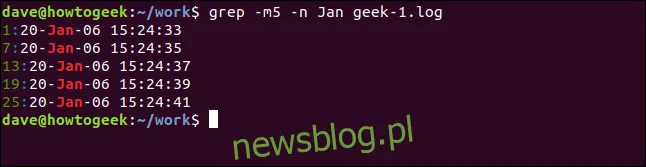
Możemy również ograniczyć liczbę wyświetlanych wyników, używając opcji -m (maksymalna liczba). Załóżmy, że chcemy ograniczyć wyniki do pięciu pasujących linii:
grep -m5 -n Jan geek-1.log
Dodawanie kontekstu do wyników
Możliwość zobaczenia dodatkowych linii – zazwyczaj niepasujących – dla każdej pasującej linii może być bardzo przydatna. Pomaga to w identyfikacji, które z dopasowanych linii są istotne.
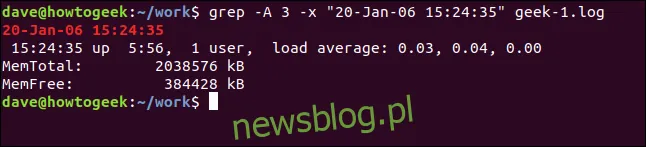
Aby wyświetlić kilka wierszy po pasującej linii, użyj opcji -A (po kontekście). W tym przykładzie żądamy trzech wierszy:
grep -A 3 -x "20-Jan-06 15:24:35" geek-1.log
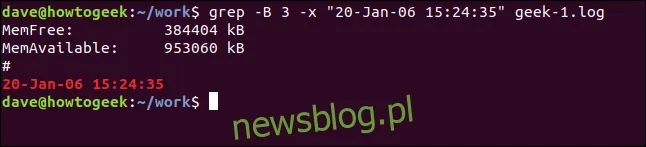
Aby zobaczyć kilka linii przed pasującą linią, użyj opcji -B (kontekst przed).
grep -B 3 -x "20-Jan-06 15:24:35" geek-1.log
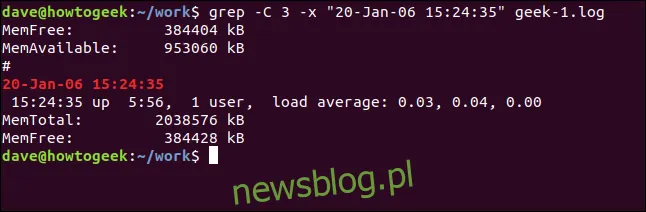
Aby zobaczyć linie przed i po pasującej linii, użyj opcji -C (kontekst).
grep -C 3 -x "20-Jan-06 15:24:35" geek-1.log
Pokazywanie pasujących plików
Aby zobaczyć nazwy plików, które zawierają wyszukiwany termin, użyj opcji -l (pliki z dopasowaniem). Aby sprawdzić, które pliki z kodem źródłowym C odnoszą się do pliku nagłówkowego sl.h, użyj tego polecenia:
grep -l "sl.h" *.c

Wynik wyświetli nazwy plików, a nie pasujące wiersze.

Oczywiście możemy szukać plików, które nie zawierają wyszukiwanego hasła. Do tego służy opcja -L (pliki bez dopasowania).
grep -L "sl.h" *.c

Dopasowania na początku i końcu linii
Możemy skonfigurować grep, aby wyświetlał jedynie dopasowania, które znajdują się na początku lub na końcu linii. Operator wyrażenia regularnego „^” dopasowuje początek wiersza. Wiele linii w pliku dziennika będzie zawierać spacje, ale poszukamy linii, których pierwszym znakiem jest spacja:
grep "^ " geek-1.log

Wynik wyświetli wiersze, w których pierwszym znakiem jest spacja.
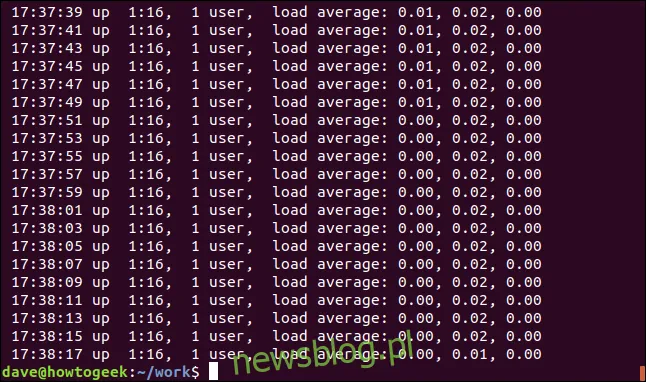
Aby dopasować koniec wiersza, użyj operatora wyrażenia regularnego „$”. Poszukamy linii kończących się na „00”.
grep "00$" geek-1.log

Wynikiem będą wiersze, których ostatnim znakiem jest „00”.
Używanie potoków z grep
Możemy przesyłać dane wejściowe do grepa przez potoki, a także przekazywać wyjście z grepa do innych programów, umieszczając go w środku łańcucha potoków.
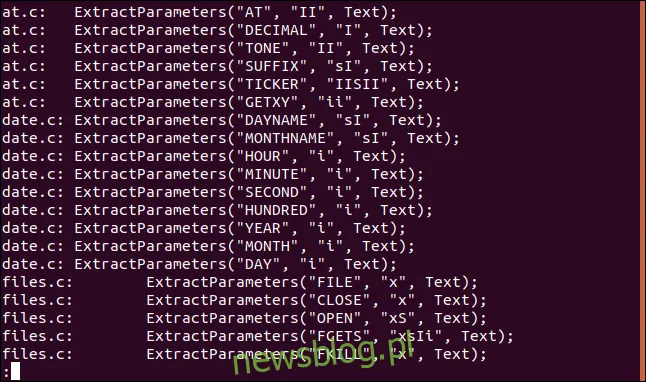
Załóżmy, że chcemy zobaczyć wszystkie wystąpienia ciągu „ExtractParameters” w naszych plikach źródłowych C. Ponieważ spodziewamy się wielu wyników, przekazujemy wyjście do narzędzia less:
grep "ExtractParameters" *.c | less

Wynik zostanie przedstawiony w formacie umożliwiającym wygodne przeglądanie.
Umożliwia to przeglądanie listy plików i korzystanie z funkcji wyszukiwania w narzędziu less.
Jeśli wyprowadzimy wynik z grepa do wc i użyjemy opcji -l (linia), możemy w policzyć liczbę linii w plikach źródłowych, które zawierają „ExtractParameters”. (Możemy to osiągnąć także używając opcji -c w grepie, ale to pokazuje, jak działa potokowanie z grep.)
grep "ExtractParameters" *.c | wc -l

W kolejnym przykładzie przesyłamy wynik z ls do grepa, a następnie do sortowania. Wymieniamy pliki w bieżącym katalogu, filtrując te, które zawierają ciąg „Aug”, i sortując je według rozmiaru pliku:
ls -l | grep "Aug" | sort +4n
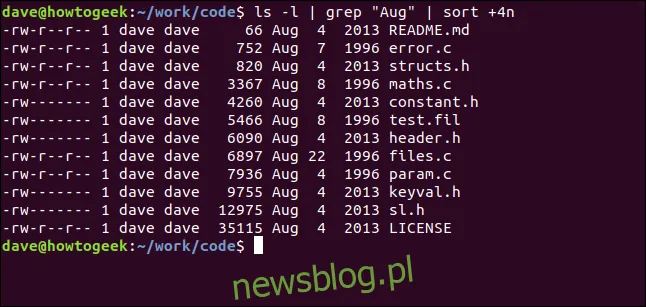
Rozłóżmy to na części:
ls -l: Wyświetla listę plików w długim formacie przy użyciu ls.
grep „Aug”: Wybiera linie z listy ls, które zawierają „Aug”. Należy zauważyć, że spowoduje to również znalezienie plików, które mają „Aug” w nazwie.
sort + 4n: Sortuje wynik z grepa według czwartej kolumny (rozmiar pliku).
Otrzymujemy posortowaną listę wszystkich plików zmodyfikowanych w sierpniu (niezależnie od roku), w kolejności rosnącej według rozmiaru.
grep: mniej dowodzenia, więcej sojusznika
grep to niezwykłe narzędzie, które może znacząco ułatwić pracę. Jego rozwój sięga 1974 roku i wciąż ewoluuje, ponieważ spełnia nasze potrzeby w zakresie przeszukiwania danych, a nikt nie robi tego lepiej.
Połączenie grepa z umiejętnością korzystania z wyrażeń regularnych może znacznie zwiększyć jego możliwości.
