Jak korzystać z polecenia uniq w systemie Linux
Polecenie uniq w systemie Linux służy do analizy plików tekstowych w celu znalezienia unikalnych lub powtarzających się linii. W tym przewodniku przyjrzymy się jego różnorodnym zastosowaniom oraz funkcjom, a także przedstawimy najlepsze sposoby na efektywne wykorzystanie tego praktycznego narzędzia.
Wyszukiwanie powtarzających się linii w systemie Linux
Polecenie uniq jest szybkim i wszechstronnym narzędziem. Jednak, podobnie jak wiele innych poleceń w Linuxie, ma swoje specyficzne cechy – co jest istotne, aby zrozumieć, jak działa. Bez tej wiedzy możesz być zaskoczony wynikami. W tym przewodniku zwrócimy uwagę na te szczegóły.
Polecenie uniq sprawdza się doskonale w sytuacjach, gdy chcesz wydobyć tylko unikalne linie. Jest również idealne do użycia w potokach, gdzie może współpracować z innymi narzędziami. Jednym z najczęściej używanych w parze z uniq jest polecenie sort, ponieważ uniq wymaga posortowanych danych wejściowych, aby działać poprawnie.
Zaczynajmy!
Używanie uniq bez dodatkowych opcji
Załóżmy, że mamy plik tekstowy zawierający tekst piosenki Roberta Johnsona zatytułowanej Wierzę, że odkurzę moją miotłę. Zobaczmy, co uniq zrobi z tym plikiem.
Aby przekazać wynik do programu less, wpisujemy:
uniq dust-my-broom.txt | less

W wyniku otrzymujemy pełny tekst piosenki, w tym linie powtarzające się:
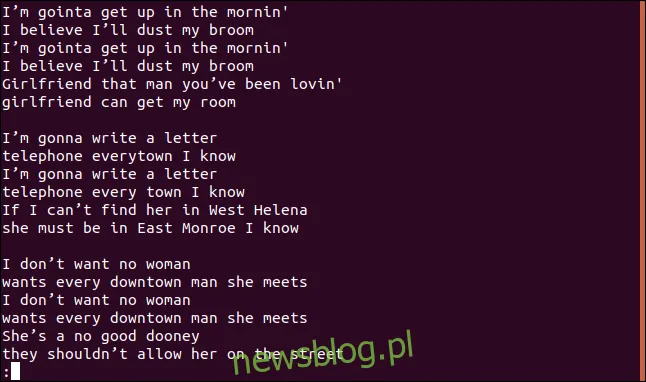
Nie widać tu ani unikalnych linii, ani zduplikowanych.
To prawda – to pierwszy z naszych istotnych spostrzeżeń. Kiedy uruchamiasz uniq bez żadnych opcji, działa tak, jakbyś użył opcji -u (wyświetl tylko unikalne linie). Aby uniq mógł uznać linię za zduplikowaną, musi ona być bezpośrednio sąsiadująca ze swoją duplikatą, dlatego sortowanie jest kluczowe.
Gdy sortujesz plik, zduplikowane linie są grupowane, co pozwala uniq traktować je jako duplikaty. Wykonamy sortowanie na pliku, a następnie przekierujemy posortowane dane do uniq, a później do less.
Aby to zrobić, używamy następującego polecenia:
sort dust-my-broom.txt | uniq | less

Po posortowaniu linie w pliku zostaną wyświetlone w less.
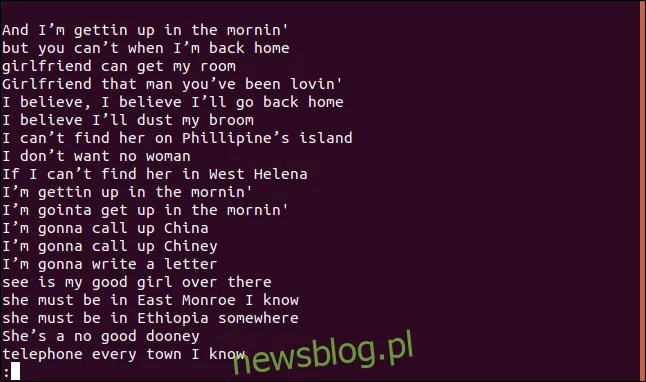
Linia „Wierzę, że odkurzę moją miotłę” pojawia się w piosence więcej niż raz, co jest oczywiste – powtórzyła się dwukrotnie w pierwszych czterech linijkach. Dlaczego więc jest na liście unikalnych linii? Ponieważ pierwsze wystąpienie tej linii jest traktowane jako unikalne, a kolejne są uznawane za duplikaty.
Możemy ponownie skorzystać z sortowania i przekierować wynik do nowego pliku, co pozwoli nam uniknąć konieczności sortowania w każdym poleceniu.
Wpisujemy:
sort dust-my-broom.txt > sorted.txt
 sort.txt ”w oknie terminala. ’ width = ”646 ″ height =” 57 ″ onload = ”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);” onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
sort.txt ”w oknie terminala. ’ width = ”646 ″ height =” 57 ″ onload = ”pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);” onerror = ”this.onerror = null; pagespeed.lazyLoadImages.loadIfVisibleAndMaybeBeacon (this);”>
Teraz mamy gotowy, posortowany plik do dalszej analizy.
Zliczanie duplikatów
Możesz użyć opcji -c (licznik), aby wydrukować, ile razy każda linia występuje w pliku.
Wpisz następujące polecenie:
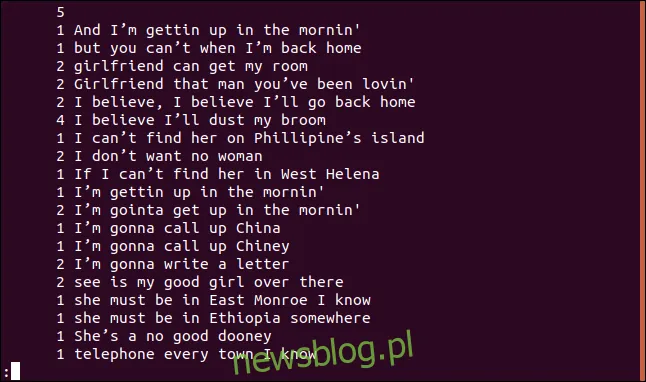
uniq -c sorted.txt | less

Każda linia jest poprzedzona liczbą wskazującą, ile razy występuje w pliku. Zauważ, że pierwsza linia jest pusta, co oznacza, że plik zawiera pięć pustych linii.
Aby uzyskać wynik posortowany według liczby wystąpień, możesz przekazać wynik z uniq do sortowania. W naszym przykładzie użyjemy opcji -r (odwróć) oraz -n (sortuj numerycznie), a następnie potokujemy wyniki do less.
Wpisujemy:
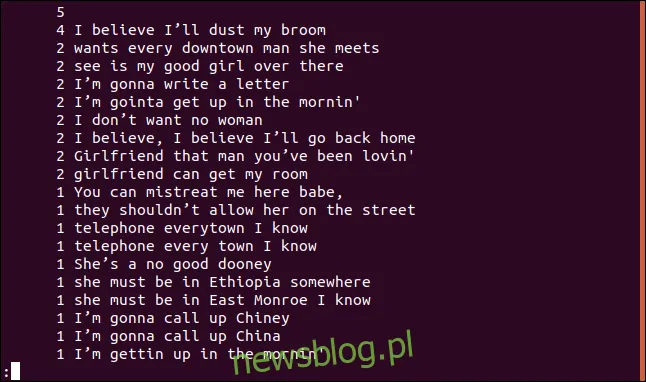
uniq -c sorted.txt | sort -rn | less

Lista zostanie posortowana malejąco na podstawie liczby wystąpień poszczególnych linii.
Wyświetlanie tylko zduplikowanych linii
Jeśli chcesz zobaczyć tylko te linie, które się powtarzają, możesz skorzystać z opcji -d (duplikaty). Niezależnie od tego, ile razy linia występuje, zostanie wyświetlona tylko raz.
Aby to zrobić, wpisujemy:
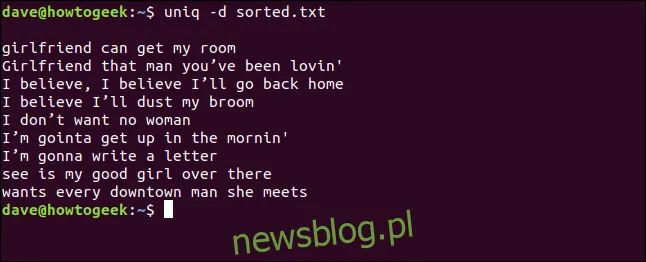
uniq -d sorted.txt

Powtarzające się linie zostaną wypisane. Zauważ, że na górze znajduje się pusta linia, co wskazuje, że plik zawiera puste linie – to nie jest efekt działania uniq.
Możemy połączyć opcje -d (duplikaty) i -c (licznik) oraz przekierować wynik przez sort. To pozwoli nam uzyskać posortowaną listę linii, które występują co najmniej dwukrotnie.
Aby to zrobić, wpisujemy:
uniq -d -c sorted.txt | sort -rn
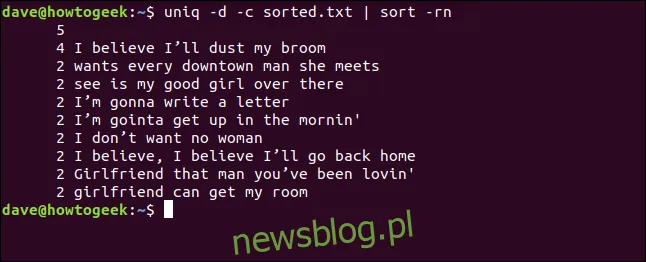
Lista wszystkich zduplikowanych linii
Jeśli chcesz zobaczyć wszystkie zduplikowane linie oraz każdą ich instancję w pliku, możesz użyć opcji -D (wszystkie duplikaty).
Aby to zrobić, wpisz:
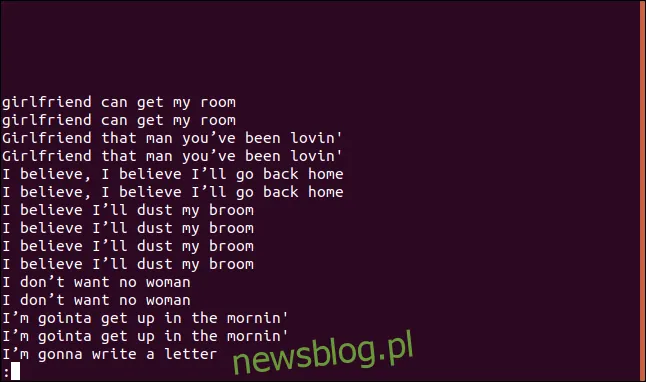
uniq -D sorted.txt | less

Lista zawiera wpis dla każdego zduplikowanego wiersza.
Jeśli użyjesz opcji --group, uniq wypisze każdy zduplikowany wiersz z pustą linią przed lub po każdej grupie, lub z obu stron.
Aby użyć opcji append, wpisz:
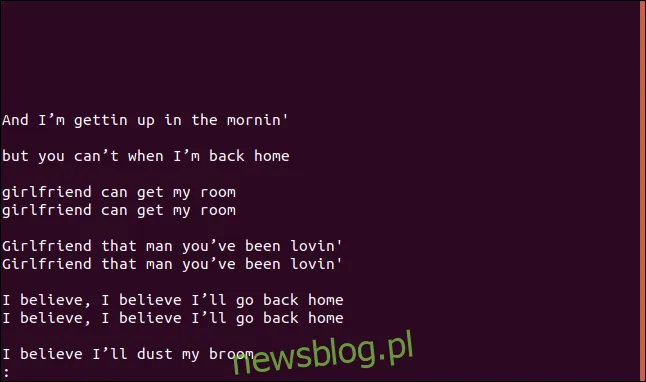
uniq --group=append sorted.txt | less

Puste linie oddzielają grupy, co ułatwia ich przeglądanie.
Sprawdzanie określonej liczby znaków
Domyślnie uniq porównuje całe linie, ale możesz ograniczyć porównania do określonej liczby znaków, używając opcji -w (sprawdzanie znaków).
W tym przykładzie powtórzymy ostatnie polecenie, ale ograniczymy porównania do pierwszych trzech znaków. Wpisujemy:
uniq -w 3 --group=append sorted.txt | less

Otrzymane wyniki i grupy będą znacznie inne.
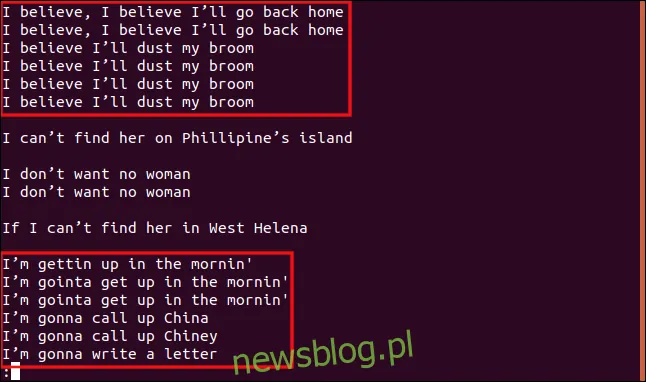
Wszystkie linie zaczynające się od „I b” są grupowane razem, ponieważ te fragmenty wierszy są identyczne, a więc traktowane jako duplikaty. Podobnie, wszystkie linie zaczynające się od „Ja” są również uznawane za duplikaty, mimo że reszta treści jest inna.
Ignorowanie określonej liczby znaków
Czasami przydatne może być pominięcie określonej liczby znaków na początku każdej linii, na przykład gdy wiersze są ponumerowane. Możesz na przykład chcieć, żeby uniq zaczynał sprawdzanie od szóstego znaku.
Poniżej znajduje się przykład pliku z ponumerowanymi wierszami.
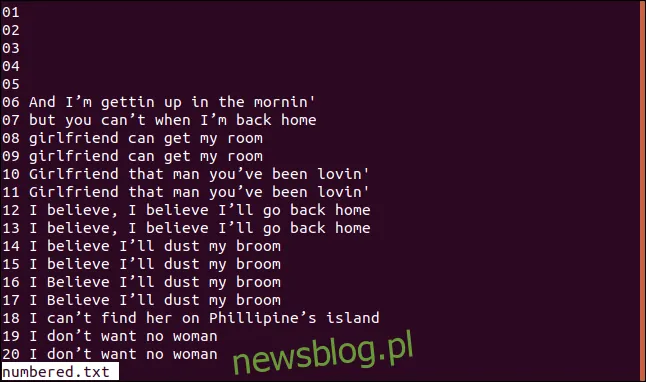
Aby rozpocząć porównywanie od trzeciego znaku, użyjemy opcji -s (pomiń znaki), wpisując:
uniq -s 3 -d -c numbered.txt
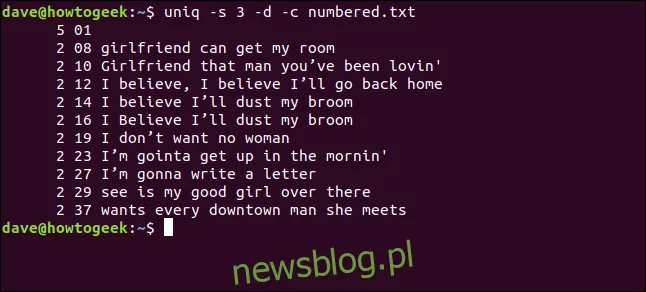
Linie są poprawnie identyfikowane jako duplikaty, a numery wyświetlane odnoszą się do pierwszego wystąpienia każdego zduplikowanego wiersza.
Możesz również pominąć pola (ciąg znaków i trochę spacji) zamiast znaków. Użyjemy opcji -f (pola), aby określić, jakie pola mają być ignorowane.
Wpiszemy następujące polecenie, aby uniq zignorował pierwsze pole:
uniq -f 1 -d -c numbered.txt
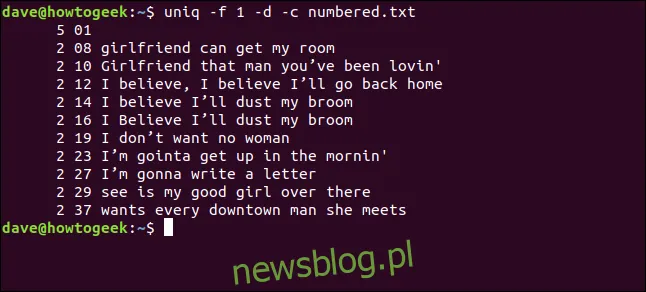
Otrzymujemy te same wyniki, które uzyskaliśmy, gdy użyliśmy opcji pomijania trzech znaków na początku każdej linii.
Ignorowanie wielkości liter
Domyślnie uniq uwzględnia wielkość liter. Gdy ta sama litera występuje w wersji wielkiej i małej, uniq traktuje je jako różne linie.
Na przykład, jeśli sprawdzisz dane wyjściowe polecenia:
uniq -d -c sorted.txt | sort -rn
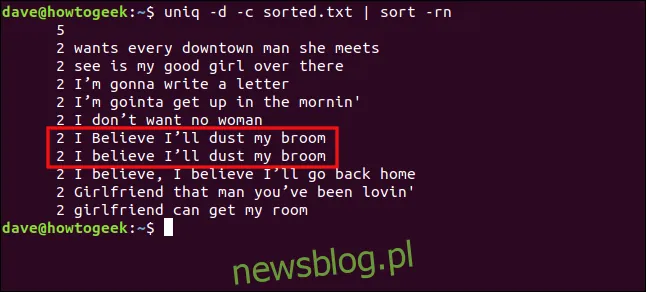
Wiersze „Wierzę, że odkurzę moją miotłę” i „Wierzę, że odkurzę miotłę” są traktowane jako różne z powodu różnicy w wielkości litery na „B” w „wierzyć”.
Ale jeśli użyjemy opcji -i (ignoruj wielkość liter), te wiersze będą traktowane jako duplikaty. Wpisujemy:
uniq -d -c -i sorted.txt | sort -rn
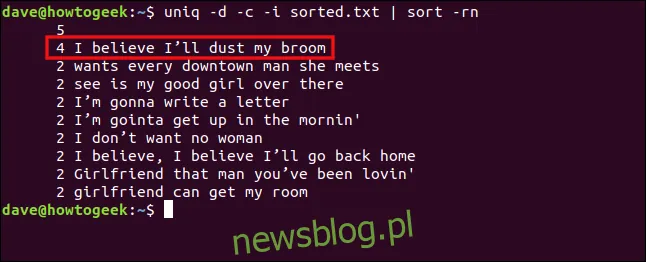
Linie są teraz traktowane jako duplikaty i grupowane razem.
Linux oferuje wiele przydatnych narzędzi. Jak wiele z nich, uniq nie jest narzędziem, które będziesz używać codziennie.
Dlatego kluczowe jest, aby pamiętać, które narzędzie może rozwiązać Twój problem i gdzie je znaleźć. Praktyka przyczyni się do Twojej biegłości w używaniu systemu Linux.
Możesz także poszukać na newsblog.pl – prawdopodobnie znajdziesz artykuł na ten temat.
