Apache Kafka to platforma służąca do przesyłania strumieniowego danych, umożliwiająca różnym aplikacjom w środowisku rozproszonym skuteczną komunikację i wymianę informacji za pomocą przesyłanych wiadomości.
Działa na zasadzie publikowania-subskrypcji, gdzie aplikacje pełniące rolę producentów wysyłają komunikaty, a systemy konsumenckie je odbierają i przetwarzają.
Apache Kafka pozwala na stworzenie luźno powiązanej architektury pomiędzy komponentami systemu, które generują i wykorzystują dane. Ułatwia to zarówno projektowanie, jak i późniejsze zarządzanie całością. Kafka opiera się na Zookeeperze, który odpowiada za zarządzanie metadanymi oraz synchronizację elementów składowych klastra.
Kluczowe cechy Apache Kafki
Popularność Apache Kafki wynika między innymi z tego, że jest:
- Skalowalna dzięki architekturze klastrowej i partycjom
- Szybka, osiągając wydajność nawet 2 milionów zapisów na sekundę
- Gwarantuje zachowanie kolejności wysyłanych wiadomości
- Niezawodna dzięki mechanizmom replikacji
- Możliwość aktualizacji bez wyłączania systemu
Poniżej omówimy najczęstsze scenariusze zastosowania Kafki.
Typowe zastosowania Apache Kafki
Kafka znajduje szerokie zastosowanie w przetwarzaniu ogromnych zbiorów danych, rejestrowaniu i agregowaniu zdarzeń (np. kliknięć użytkowników), analizie danych, czy też konsolidacji dzienników z różnych części systemu w jednej, centralnej lokalizacji.
Umożliwia również komunikację między różnorodnymi aplikacjami w ramach jednego systemu oraz obróbkę w czasie rzeczywistym danych pochodzących z urządzeń IoT.
Teraz przejdźmy do szczegółowej instrukcji instalacji Kafki w systemach Windows i Linux.
Instalacja Kafki w systemie Windows
Przed rozpoczęciem instalacji Apache Kafka w systemie Windows, należy upewnić się, że na komputerze zainstalowana jest Java. W tym celu otwórz wiersz poleceń z uprawnieniami administratora i wprowadź polecenie:
java --version
Jeśli Java jest zainstalowana, w odpowiedzi powinna pojawić się informacja o numerze zainstalowanej wersji JDK.
W przypadku, gdy wyświetlony zostanie komunikat o błędzie o nierozpoznaniu polecenia, oznacza to, że Java nie została jeszcze zainstalowana i należy ją zainstalować. Aby to zrobić, wejdź na stronę Adoptium.net i kliknij przycisk pobierania.
Po pobraniu pliku instalatora Java, uruchom go. Pojawi się okno z instrukcjami instalacji.
Klikaj „Dalej”, aby zaakceptować domyślne ustawienia. Po zakończeniu procesu instalacji, sprawdź poprawność, zamykając aktualne okno wiersza poleceń, otwierając nowe (również z uprawnieniami administratora) i wprowadzając to samo polecenie:
java --version
Tym razem powinna pojawić się informacja o numerze nowo zainstalowanej wersji JDK. Gdy Java jest poprawnie zainstalowana, możemy przejść do instalacji Kafki.
W celu instalacji Kafki, wejdź na oficjalną stronę projektu.

Kliknij link, który przeniesie cię do strony z plikami do pobrania. Ściągnij najnowszą dostępną wersję plików binarnych.
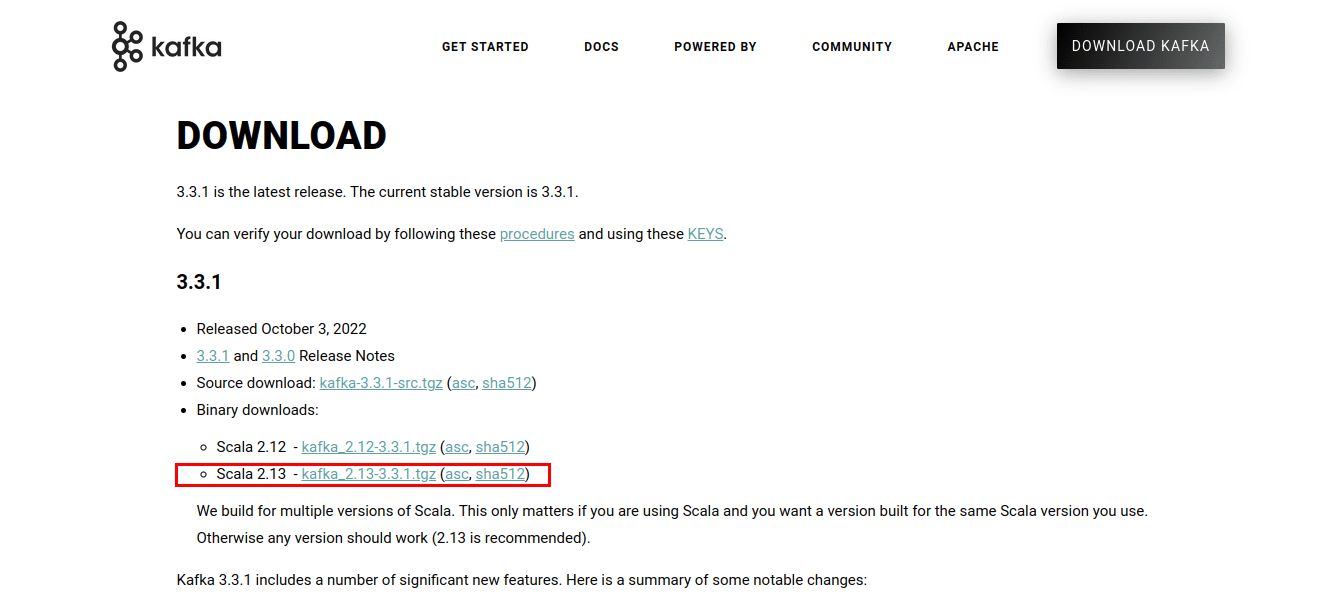
Pobrany plik .tgz zawiera skrypty i pliki binarne Kafki. Należy je rozpakować. W tym celu można użyć programu WinZip, dostępnego do pobrania ze strony WinZip.
Po rozpakowaniu, przenieś folder z plikami do katalogu C:, tak aby ścieżka do plików Kafki była C:\kafka
Następnie, uruchom wiersz poleceń w trybie administratora. Przejdź do katalogu Kafki i uruchom Zookeeper, używając pliku zookeeper-server-start.bat wraz z plikiem konfiguracyjnym zookeeper.properties:
cd C:kafka binwindowszookeeper-server-start.bat configzookeeper.properties
W trakcie działania Zookeepera, należy dodać do systemowej zmiennej PATH ścieżkę do pliku wykonywalnego wmic, który jest używany przez Kafkę:
set PATH=C:WindowsSystem32wbem;%PATH%;
Następnie, aby uruchomić serwer Apache Kafka, otwórz kolejną sesję wiersza poleceń (również z uprawnieniami administratora) i przejdź do folderu C:\kafka
cd C:kafka
Uruchom Kafkę, używając polecenia:
binwindowskafka-server-start.bat configserver.properties
W tym momencie Kafka powinna być już uruchomiona. Ustawienia serwera, takie jak lokalizacja przechowywania logów, można skonfigurować w pliku server.properties.
Instalacja Kafki w systemie Linux
Zacznij od upewnienia się, że system jest zaktualizowany poprzez odświeżenie pakietów:
sudo apt update && sudo apt upgrade
Kolejnym krokiem jest sprawdzenie, czy Java jest zainstalowana w systemie. Uruchom w tym celu:
java --version
Jeśli Java jest zainstalowana, pojawi się informacja o numerze wersji. Jeśli nie, możesz ją zainstalować za pomocą apt:
sudo apt install default-jdk
Następnie, można przejść do instalacji Apache Kafka, pobierając pliki binarne ze strony projektu.
Otwórz terminal i przejdź do katalogu, gdzie zapisałeś pobrane pliki (np. w moim przypadku folder Pobrane):
cd Downloads
W folderze pobranych plików, rozpakuj pliki z archiwum za pomocą polecenia tar:
tar -xvzf kafka_2.13-3.3.1.tgz
Przejdź do rozpakowanego folderu:
cd kafka_2.13-3.3.1.tgz
Wyświetl zawartość folderu, aby się upewnić, że wszystko przebiegło poprawnie.
Następnie, wewnątrz folderu, uruchom serwer Zookeeper, wykonując skrypt zookeeper-server-start.sh znajdujący się w podfolderze bin.
Skrypt ten wymaga pliku konfiguracyjnego Zookeepera. Domyślnie jest to plik o nazwie zookeeper.properties znajdujący się w katalogu config.
Aby uruchomić serwer, użyj polecenia:
bin/zookeeper-server-start.sh config/zookeeper.properties
Po uruchomieniu Zookeepera, możemy uruchomić serwer Apache Kafka. Skrypt kafka-server-start.sh również znajduje się w folderze bin i także wymaga pliku konfiguracyjnego (domyślnie jest to server.properties umieszczony w podfolderze config).
bin/kafka-server-start.sh config/server.properties
W ten sposób Kafka powinna zostać uruchomiona. W katalogu bin znajduje się wiele skryptów do tworzenia tematów, zarządzania producentami i konsumentami. Ustawienia serwera można dostosować w pliku server.properties.
Podsumowanie
W tym przewodniku przedstawiliśmy kroki niezbędne do instalacji Javy i Apache Kafki. Chociaż klastrami Kafka można zarządzać ręcznie, warto rozważyć opcje zarządzane, takie jak Amazon Web Services i Confluent.
W kolejnym kroku warto zapoznać się z przetwarzaniem danych przy użyciu Kafki i Sparka.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.