

Czas wybrać najlepszą opcję bezserwerowej bazy danych, która najlepiej pasuje do Twojej nowoczesnej aplikacji.
Bezserwerowa baza danych została specjalnie zaprojektowana do obsługi nieprzewidywalnych obciążeń, które mogą się szybko zmieniać. W rezultacie wiele organizacji przyjęło architekturę bezserwerową do tworzenia nowoczesnych architektur sterowanych zdarzeniami. Spowodowało to wzrost popularności w ekosystemie technologii bezserwerowych.
Spis treści:
Wprowadzenie do bezserwerowej bazy danych
Przetwarzanie bezserwerowe wymaga bezserwerowej bazy danych. Te bazy danych są specjalnie zaprojektowane do obsługi nieprzewidywalnych obciążeń, które mogą szybko się zmieniać. Co więcej?
Możesz zapłacić tylko za zasoby bazy danych, których używasz na sekundę. Ponadto bazy danych w chmurze, takie jak Amazon Aurora, które są kompatybilne z MySQL i PostgreSQL, mogą być w pełni zarządzane i skalowane do 64 TB.
Tę bazę danych można utworzyć, wybierając rozmiar instancji. Działa to dobrze, gdy istnieje przewidywalne obciążenie, częstotliwość żądań i wymagania dotyczące przetwarzania.
Zorganizowanie odpowiedniej pojemności może być trudne w przypadkach, gdy obciążenie pracą jest nieprzewidywalne i istnieje duża liczba żądań dotyczących zaledwie kilku minut tygodniowo lub jednego dnia. Jednak płacenie za to na bieżąco może nie być najlepszą opcją.
Tutaj do gry wchodzi bezserwerowa baza danych.
Funkcje bezserwerowej bazy danych

Oto główne cechy bezserwerowych baz danych:
- Dostęp w czasie rzeczywistym: Dostęp do Twoich danych jest dostępny na wysokim poziomie. Automatycznie indeksuje dane i udostępnia je natychmiast. Pozwala to na ciągłe wysyłanie zapytań, odczytywanie, aktualizowanie i dodawanie elementów do bezserwerowej bazy danych. Co więcej? Będziesz mógł uzyskać do niego natychmiastowy dostęp za pomocą funkcji.
- Nieskończona skalowalność: bezserwerowe bazy danych można skalować w górę lub w dół w dowolnym momencie. Uruchamiają się i wyłączają zgodnie z potrzebami aplikacji. Skaluje jednostki obliczeniowe (ACU w przypadku Aurora Serverless), aby obsłużyć zapytania, odczyt i zapis w tym samym klastrze danych. Ta automatyzacja pozwoli Ci uruchamiać wszystkie funkcje jednocześnie i zapewni spójność danych.
- Wysokie bezpieczeństwo: Nowoczesne aplikacje mogą być narażone na ataki złośliwych i niezaufanych odbiorców w skali globalnej. Zapewnia, że każda aplikacja współpracująca z tą samą bazą danych przechodzi przez ten sam protokół kontroli dostępu. Zmniejsza powierzchnię ataku, która jest kluczowym ryzykiem dla firm.
- Dostępność: Bezserwerowa baza danych zapewnia możliwość zmniejszenia opóźnień. Takie podejście umożliwia użytkownikowi odczytywanie danych z funkcji sterowanych zdarzeniami.
- Bez schematu: bez schematu pozwala obsługiwać wszystkie dane wyjściowe z twoich funkcji. Łatwo jest zintegrować bezserwerową bazę danych z funkcjami, korzystając z podejścia „obsługuj wszystko”. Jest to unikalna funkcja w bezserwerowych bazach danych.
Przyjrzyjmy się teraz najlepszym bezserwerowym bazom danych dla nowoczesnych aplikacji.
Fauna
Fauna to rozproszona, bezserwerowa baza danych. Fauna oferuje wyjątkową elastyczność. Możesz dostosować kilka parametrów, aby spełnić potrzeby swojego projektu. Fauna może być używana jako klucz-wartość, wykres, oparta na dokumentach lub tradycyjna relacyjna baza danych. Możesz utworzyć schemat lub uwolnić dane.
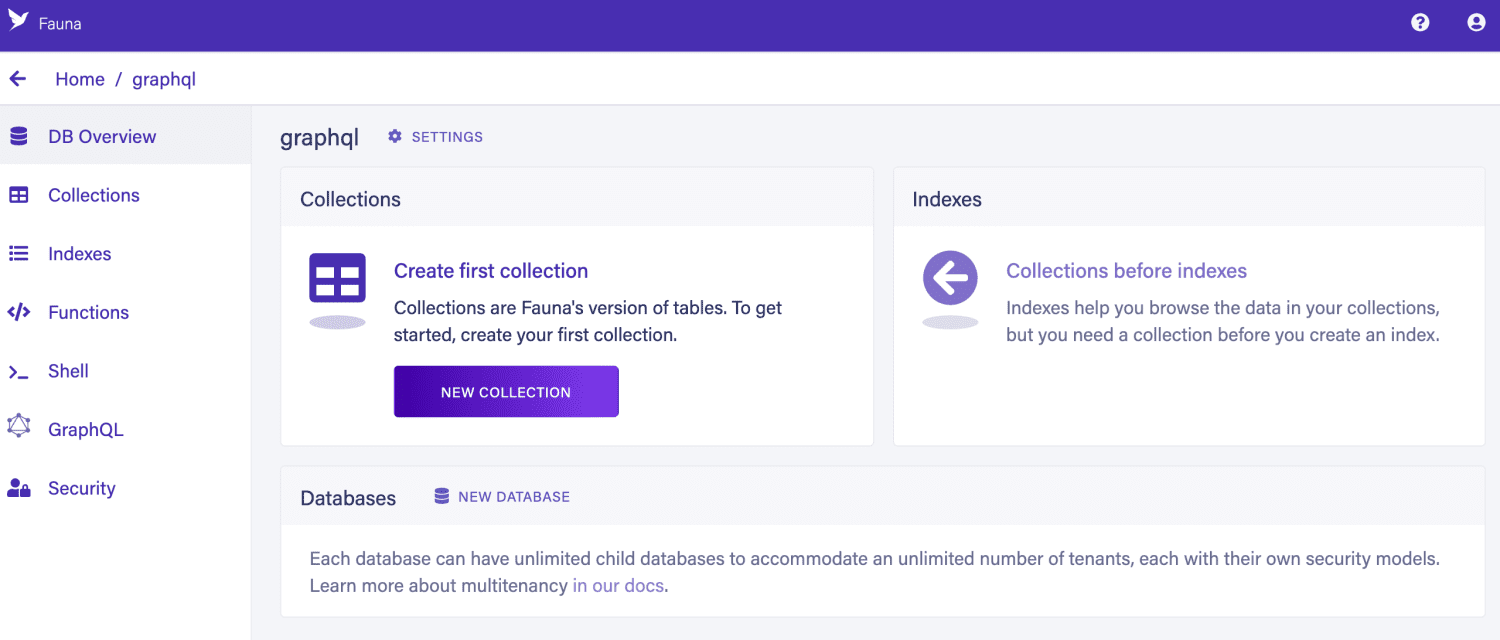
Jest niezwykle wszechstronny. Fauna może być uruchamiana w chmurze, lokalnie lub osadzona w naszej aplikacji. Oferuje również najpopularniejsze opcje wdrażania, takie jak obrazy maszyn lub obrazy dokerów. Ta aplikacja może działać z bardzo dużą szybkością i dobrze radzi sobie z transakcjami ACID.
Amazonka Aurora
Amazon Aurora to relacyjna usługa przechowywania danych, do której można uzyskać dostęp z chmury Amazon. Ta usługa jest szeroko stosowana do przechowywania danych. Pozwala na przechowywanie danych z małymi opóźnieniami i oparte na wartościach.
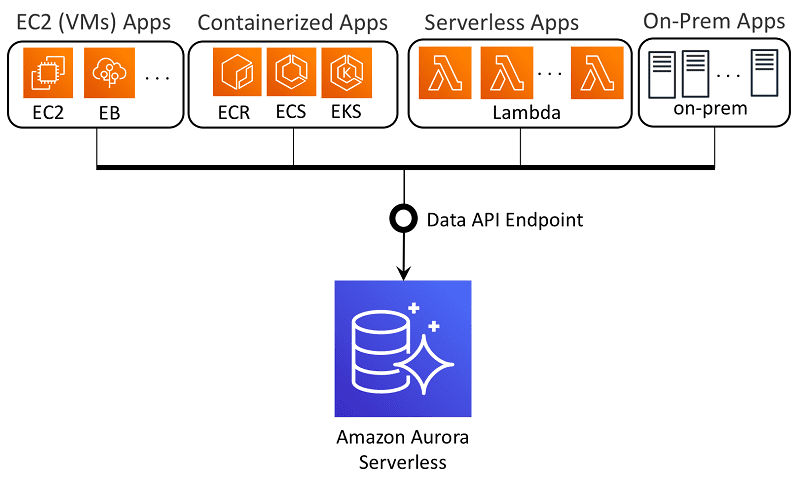 Źródło obrazu: AWS
Źródło obrazu: AWS
Amazon Aurora to relacyjna baza danych kompatybilna z PostgreSQL i MySQL, która łączy dostępność i wydajność tradycyjnych baz danych z niezawodnością i prostotą komercyjnych baz danych za 1/10 ceny. Wykorzystuje klastrowe podejście do replikacji danych w strefie dostępności AWS w celu wydajnej dostępności danych.
Amazon Aurora ma wiele wysokowydajnych podsystemów. Najszybsza rozproszona pamięć masowa jest używana przez silniki MySQL i PostgreSQL. Aurora zwiększa przepustowość i wydajność MySQL odpowiednio 5x i 3x w porównaniu z obecnym systemem.
Bazę danych można skalować do 64 terabajtów, zapewniając wsparcie dla wdrażania w przedsiębiorstwach. Amazon Aurora jest w pełni zarządzana przez usługę Amazon Relational Database Service (RDS), która automatyzuje zadania administracyjne, takie jak udostępnianie sprzętu, porządkowanie danych, naprawianie, wzmacnianie i inne.
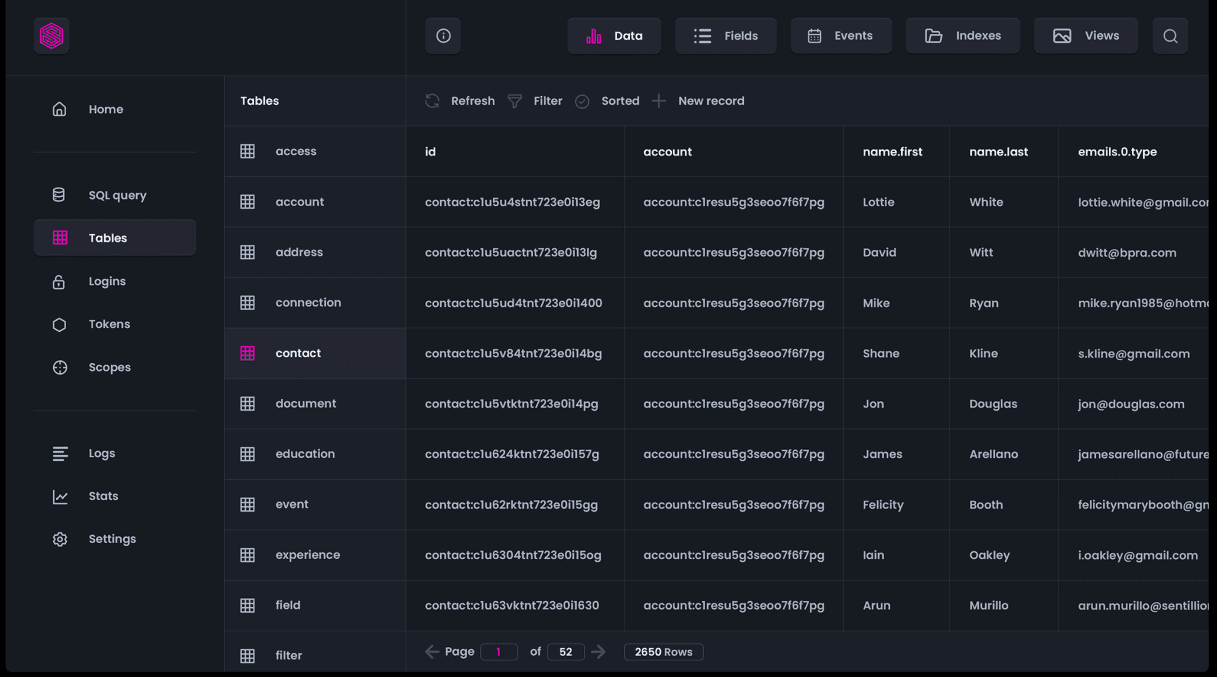
Bit.io
bit.io pozwala szybko i łatwo skonfigurować bazę danych PostgreSQL. Przeciągnij i upuść pliki, aby załadować dane do bazy danych PostgreSQL. Możesz także wprowadzić adres URL pliku, wysłać dane z R lub Pythona lub użyć dowolnego innego klienta Postgres/HTTP.
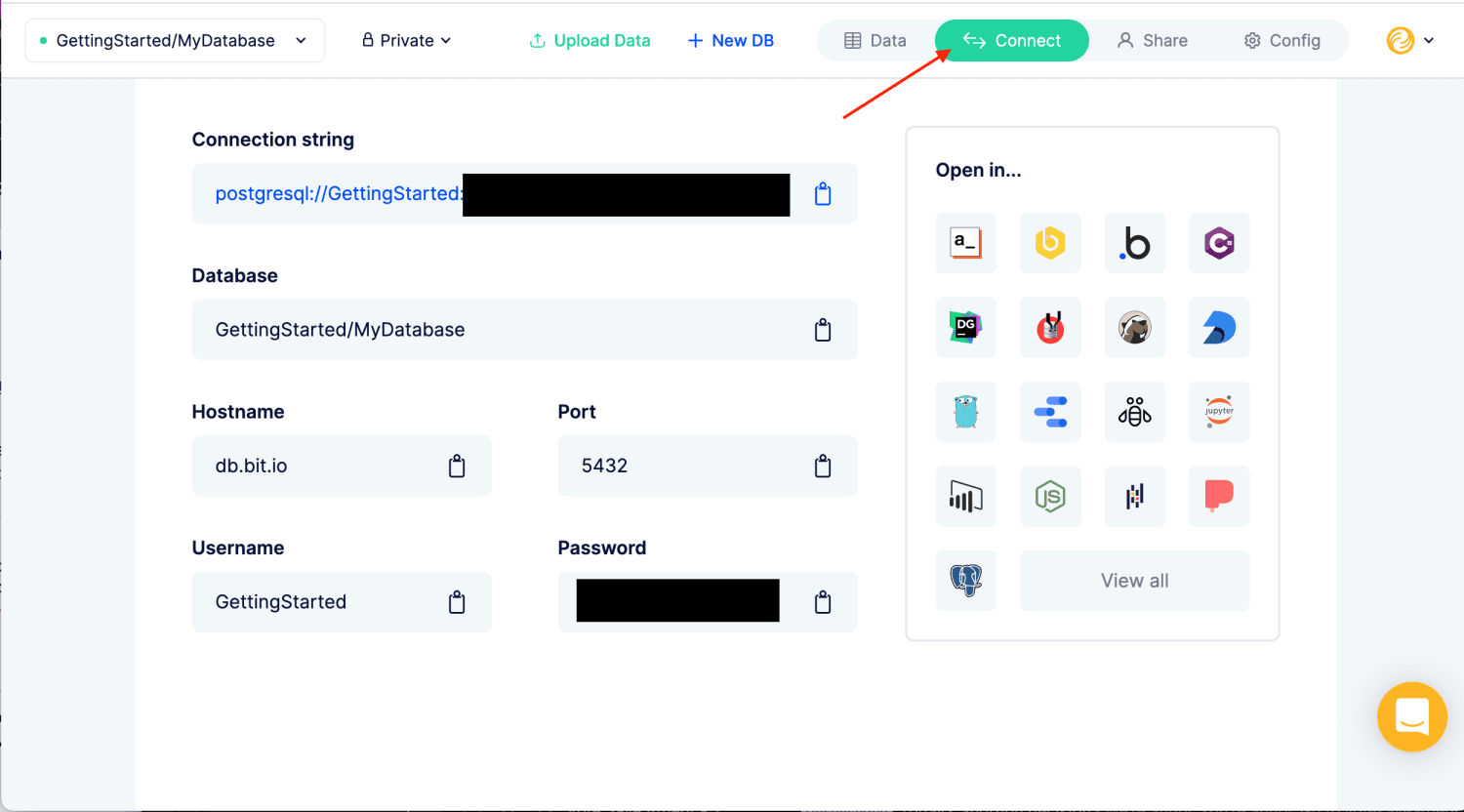
Edytor SQL w przeglądarce umożliwia pracę z danymi przy użyciu dowolnych ulubionych narzędzi do analizy danych, w tym klientów SQL, notatników R i Python, wiersza poleceń i wielu innych.
bit.io zapewnia w pełni funkcjonalną bazę danych PostgreSQL. Można go używać szybko i praktycznie bez konfiguracji. Integruje się również z rosnącą liczbą narzędzi do obsługi danych. bit.io będzie działać z każdym narzędziem obsługującym PostgreSQL.
Upstash
Upstash, bezserwerowa baza danych w chmurze pamięci stworzona przez Upstash Inc (firma z siedzibą w Kalifornii). Może być używany jako warstwa buforująca lub jako baza danych. Nie wymaga zarządzania klastrami ani serwerami baz danych. Jest całkowicie bezserwerowy.
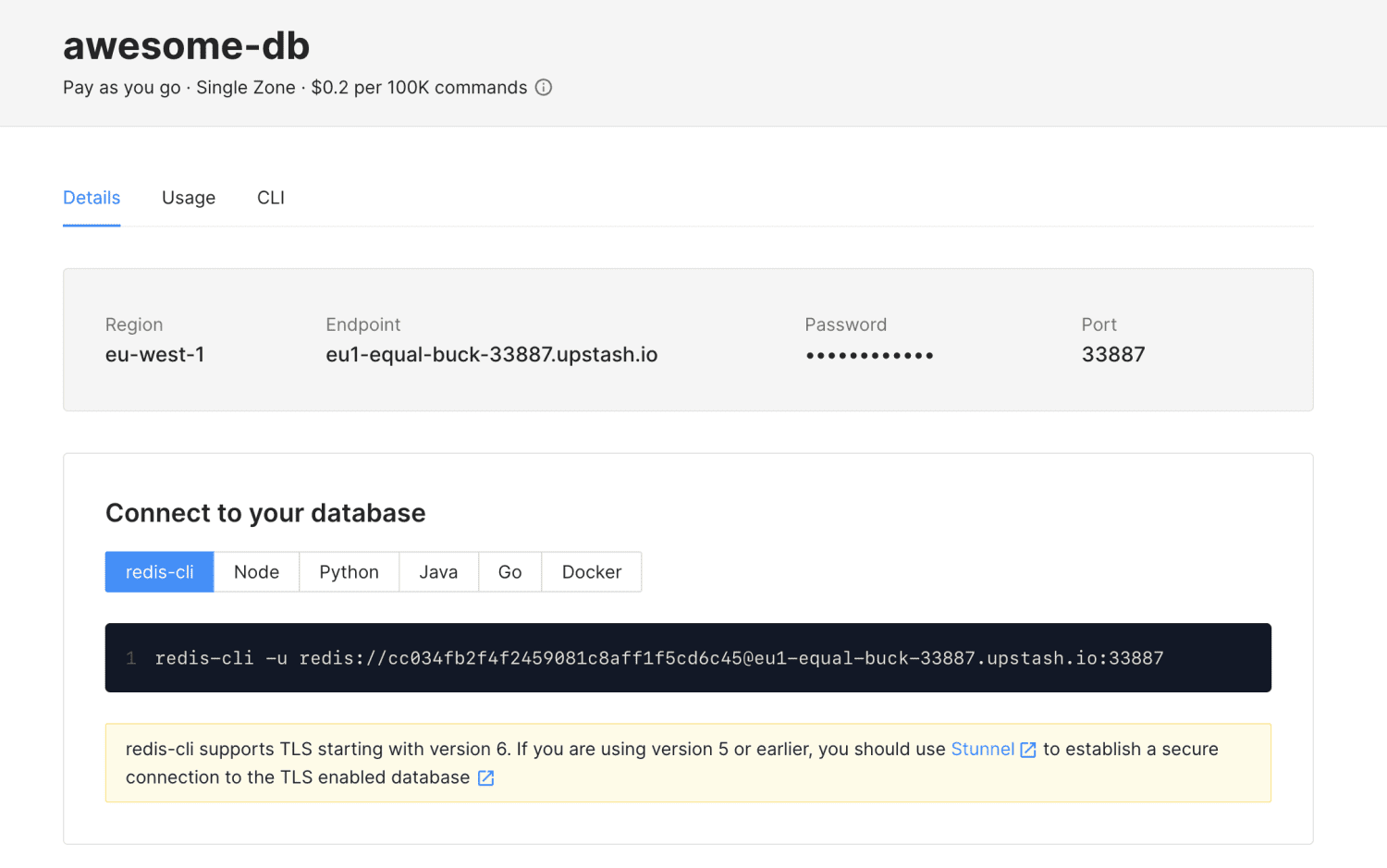
Właśnie dlatego technologie Serverless, takie jak Upstash, są tak przydatne. Upstash nie pobiera żadnych opłat, jeśli go nie używasz. Upstash może być używany w popularnych przypadkach użycia Redis, takich jak:
- Buforowanie ogólne
- Buforowanie sesji
- Rankingi
- Kolejki
- Pomiar zużycia (zliczanie)
- Filtrowanie treści
Cechy
- Zaprojektowany dla bezserwerowego
- Płać na bieżąco
- Małe opóźnienia
- Trwałe i szybkie przechowywanie
Xata
Xata, bezserwerowa baza danych, ma wbudowane zaawansowane funkcje wyszukiwania i analizy. Xata wykorzystuje model relacyjnej bazy danych ze ścisłym schematem (schematem) i obsługuje obiekty podobne do JSON. Rekordy są zorganizowane w tabele, które następnie są grupowane w bazy danych.
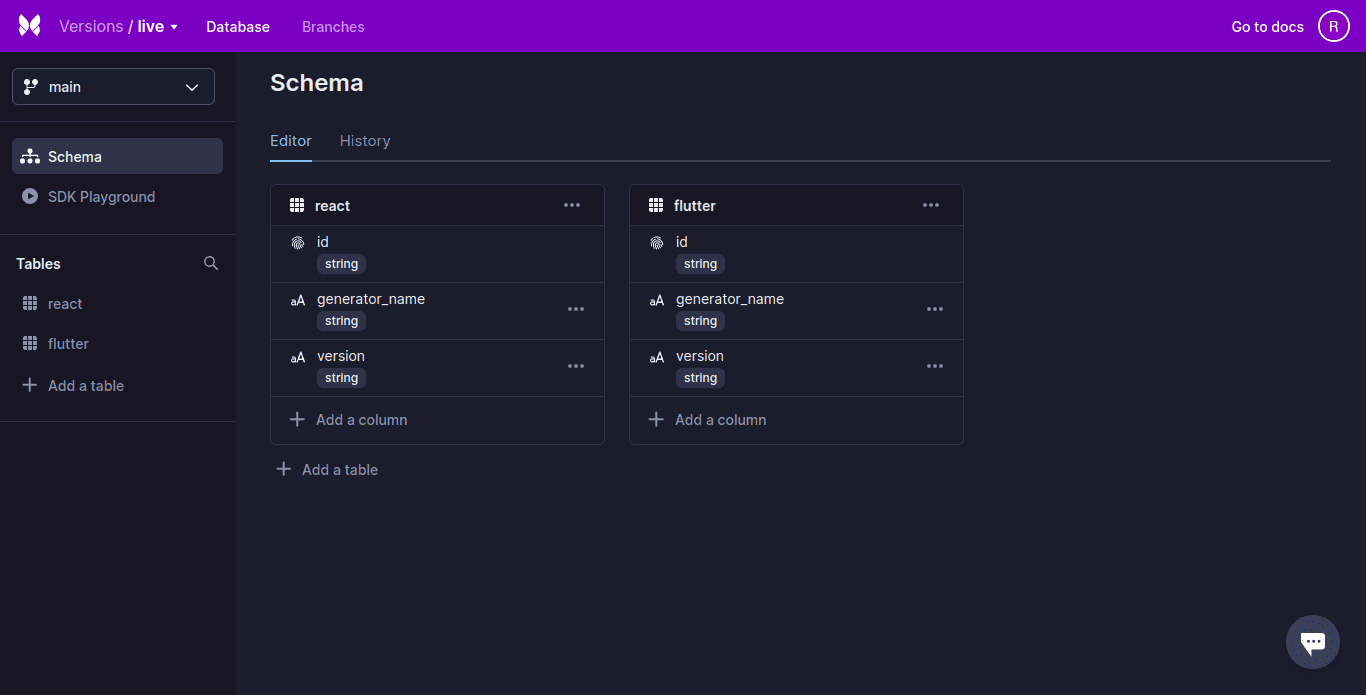
Xata obsługuje bogate kolumny, a relacje między tabelami mogą być reprezentowane za pomocą kolumn łączy. Są one podobne do klucza obcego.
Xata, nowy typ usługi w chmurze, oferuje warstwę abstrakcji nałożoną na wiele magazynów danych, aby uprościć tworzenie i obsługę aplikacji. Ten typ usługi nazywa się bezserwerową platformą danych. Ten dokument może być użyty jako pomoc w replikacji architektury, co da ci niektóre korzyści z używania Xata.
SurrealDB
SurrealDB, innowacyjna chmurowa baza danych NewSQL, może być używana w aplikacjach bezserwerowych, jamstack, jednostronicowych, tradycyjnych i bezserwerowych. Oferuje niezrównaną elastyczność i wartość finansową. Można go wdrażać w środowiskach lokalnych, wbudowanych lub brzegowych, a także w chmurze.
Twój zespół nie musi biegle posługiwać się złożonymi językami baz danych. Zaawansowana funkcjonalność jest również prosta i bezpośrednia, ale wciąż szybka i wydajna. Możesz zapomnieć o skalowaniu serwerów, baz danych, load balancerów i punktów końcowych API.
SurrealDB usuwa złożoność stosu i umożliwia skalowanie w górę dzięki rozproszonej, wysoce dostępnej platformie. SurrealDB Cloud umożliwia wdrożenie w dowolnym miejscu.
CosmosDB
Azure Cosmos DB, globalna rozproszona baza danych oparta na formacie JSON, jest dostępna jako „platforma jako usługa (PaaS)” na platformie Microsoft Azure. Umożliwia użytkownikom automatyczne tworzenie i dystrybucję aplikacji w centrach danych platformy Azure bez konieczności konfiguracji.
Jest częścią platformy Azure i jest dostępna we wszystkich regionach. Replikuje również dane w wielu centrach danych w sieci.
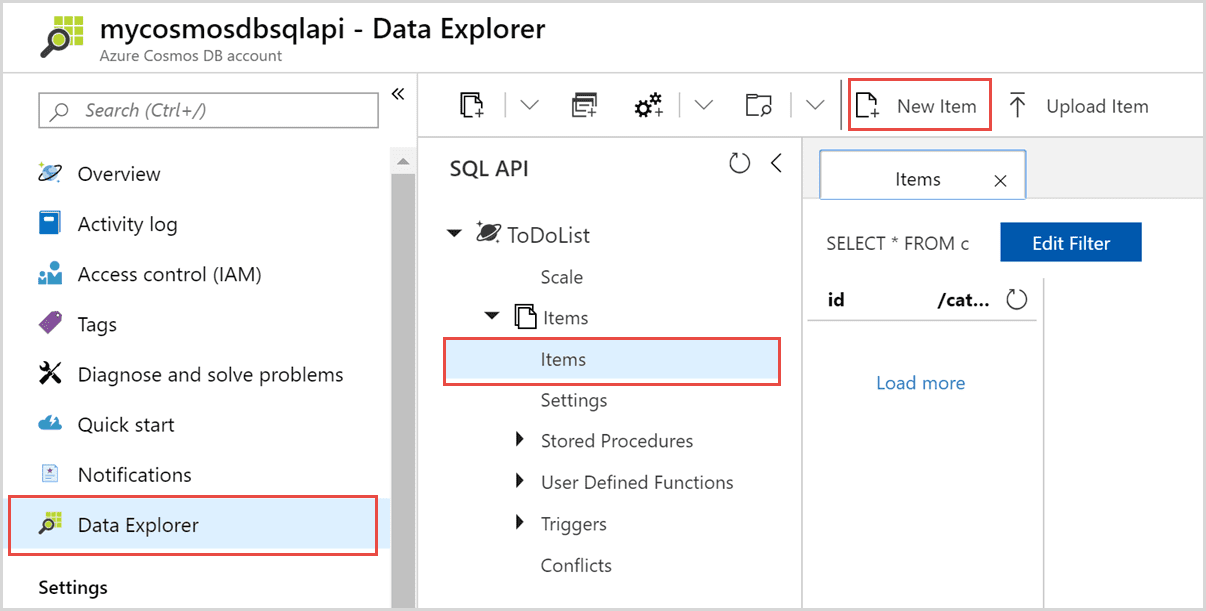
Dostępnych jest wiele interfejsów, z których najciekawszy jest oparty na języku SQL. CosmosDB to idealna usługa dla organizacji, które przetwarzają, wysyłają zapytania i zarządzają wieloma krótkotrwałymi, ważnymi informacjami.
KaraluchDB
CockroachDB, rozproszona baza danych SQL zbudowana w oparciu o spójny magazyn klucz-wartość i transakcyjny, nosi nazwę CockroachDB.
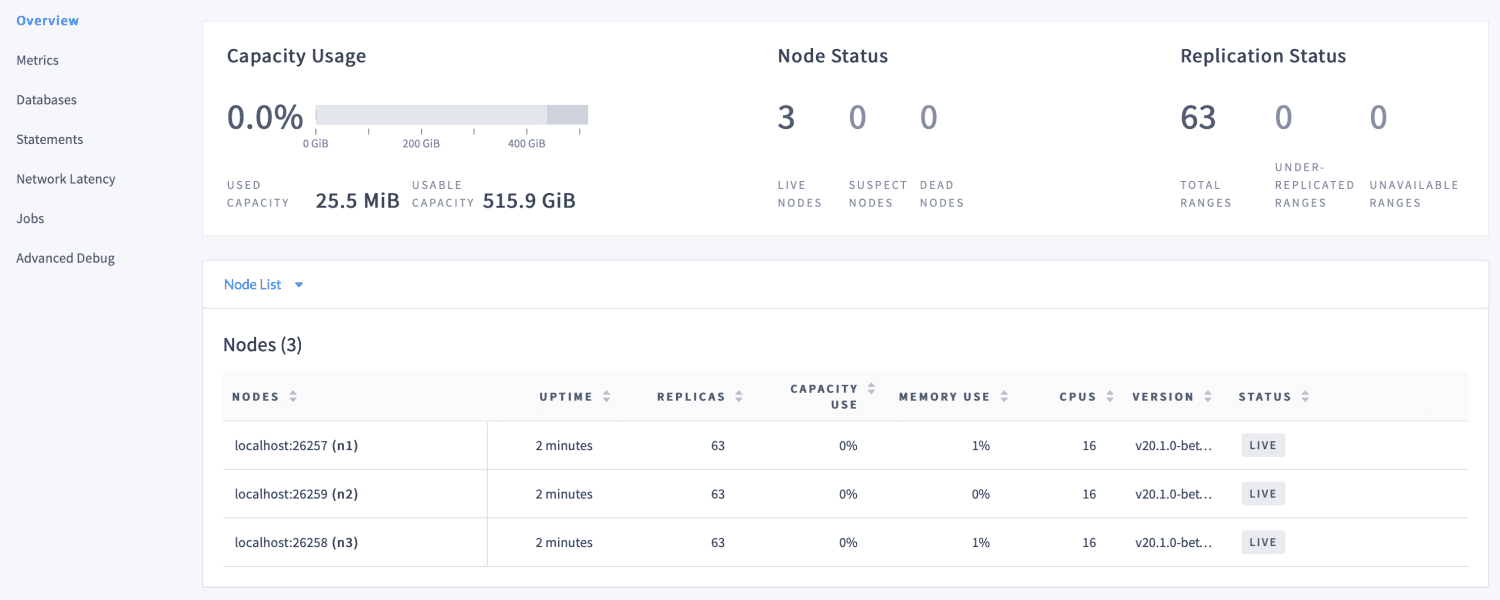
Jest napisany w Go i jest w pełni open-source. Jego główne cele obejmują obsługę transakcji ACID, skalowanie poziome i przeżywalność. Ma na celu tolerowanie wszystkiego, od awarii pojedynczego dysku po całą operację odzyskiwania po awarii, bez jakiejkolwiek ręcznej interwencji i przy minimalnym opóźnieniu.
CockroachDB to dobry wybór dla aplikacji wymagających wiarygodnych, dokładnych i dostępnych danych we wszystkich skalach. Możesz uzyskać dostęp do interfejsu administratora, który jest dostarczany w pakiecie z CockroachDB pod adresem http://localhost:8080, gdy tylko klaster zostanie uruchomiony.
Dostarcza informacji o konfiguracji klastra i bazy danych oraz pomaga nam optymalizować wydajność klastra poprzez monitorowanie metryk, takich jak kondycja, metryki czasu działania, replikacja i szczegóły węzłów.
Skala planety
PlanetScale, nowa platforma DBaaS, pozwala szybko rozbudować bazę danych bez konieczności zarządzania połączeniami. Bazy danych PlanetScale zostały zaprojektowane z myślą o programistach i ich przepływach pracy. Możesz wdrożyć w pełni zarządzaną bazę danych, która zapewnia niezawodność i elastyczność MySQL. Ich bazy danych są zbudowane na MySQL 8.0.
PlanetScale oferuje dwa rodzaje gałęzi baz danych: produkcyjną i rozwojową. Jego funkcja rozgałęziania pozwala traktować bazy danych jako kod. Możesz utworzyć gałąź ze schematu produkcyjnej bazy danych, która będzie używana w izolowanych środowiskach programistycznych.
Wniosek
A więc to było wszystko o najlepszych bezserwerowych bazach danych dla nowoczesnych aplikacji. Bezserwerowe bazy danych, a zwłaszcza Amazon Aurora Serverless, to obiecująca przyszłość. Ponieważ teraz dzięki tej nowej technologii możemy skupić się na podstawowych kwestiach związanych z dostępem do danych w czasie rzeczywistym, skalowalnością i bezpieczeństwem.
Możesz być także zainteresowany 7 sposobami, w jakie Serverless Computing to rozwijająca się technologia.