
Regresja i klasyfikacja to dwa najbardziej podstawowe i znaczące obszary uczenia maszynowego.
Rozróżnienie algorytmów regresji i klasyfikacji może być trudne, gdy dopiero zaczynasz przygodę z uczeniem maszynowym. Zrozumienie, jak działają te algorytmy i kiedy ich używać, może mieć kluczowe znaczenie dla trafnych prognoz i skutecznych decyzji.
Najpierw przyjrzyjmy się uczeniu maszynowemu.
Spis treści:
Co to jest uczenie maszynowe?
Uczenie maszynowe to metoda uczenia komputerów uczenia się i podejmowania decyzji bez wyraźnego programowania. Polega na szkoleniu modelu komputerowego na zbiorze danych, umożliwiając modelowi przewidywanie lub podejmowanie decyzji na podstawie wzorców i relacji w danych.
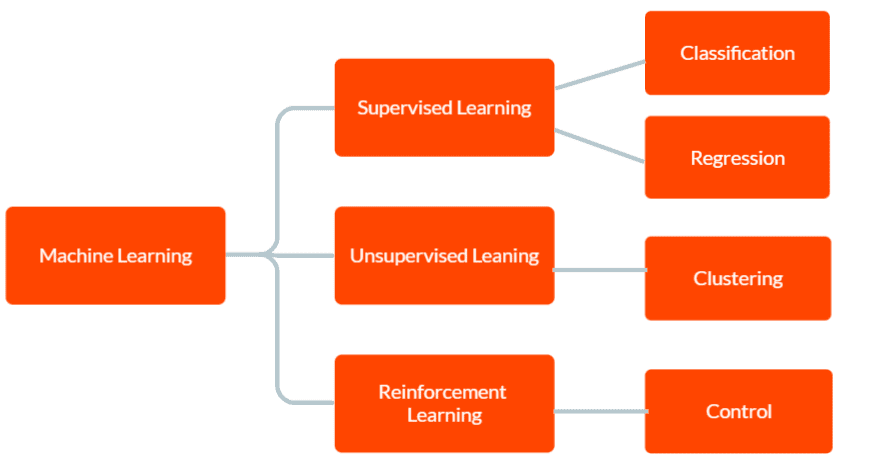
Istnieją trzy główne typy uczenia maszynowego: uczenie nadzorowane, uczenie nienadzorowane i uczenie wzmacniające.
W przypadku uczenia nadzorowanego model jest wyposażony w oznaczone dane treningowe, w tym dane wejściowe i odpowiadające im poprawne dane wyjściowe. Celem jest, aby model przewidywał dane wyjściowe dla nowych, niewidocznych danych na podstawie wzorców wyuczonych z danych szkoleniowych.
W przypadku uczenia bez nadzoru model nie otrzymuje żadnych oznaczonych danych treningowych. Zamiast tego pozostaje samodzielne odkrywanie wzorców i relacji w danych. Można to wykorzystać do identyfikacji grup lub klastrów w danych lub do znalezienia anomalii lub nietypowych wzorców.
A w uczeniu się przez wzmacnianie agent uczy się interakcji z otoczeniem, aby zmaksymalizować nagrodę. Polega na szkoleniu modelu do podejmowania decyzji w oparciu o informacje zwrotne, które otrzymuje z otoczenia.
Uczenie maszynowe jest wykorzystywane w różnych aplikacjach, w tym w rozpoznawaniu obrazów i mowy, przetwarzaniu języka naturalnego, wykrywaniu oszustw i samojezdnych samochodach. Ma potencjał do automatyzacji wielu zadań i usprawnienia podejmowania decyzji w różnych branżach.
Ten artykuł koncentruje się głównie na koncepcjach klasyfikacji i regresji, które wchodzą w zakres nadzorowanego uczenia maszynowego. Zacznijmy!
Klasyfikacja w uczeniu maszynowym

Klasyfikacja to technika uczenia maszynowego, która polega na szkoleniu modelu w celu przypisania etykiety klasy do danych danych wejściowych. Jest to zadanie uczenia nadzorowanego, co oznacza, że model jest szkolony na oznaczonym zbiorze danych, który zawiera przykłady danych wejściowych i odpowiadające im etykiety klas.
Model ma na celu poznanie relacji między danymi wejściowymi a etykietami klas, aby przewidzieć etykietę klasy dla nowych, niewidocznych danych wejściowych.
Istnieje wiele różnych algorytmów, które można wykorzystać do klasyfikacji, w tym regresja logistyczna, drzewa decyzyjne i maszyny wektorów nośnych. Wybór algorytmu będzie zależał od charakterystyki danych i pożądanej wydajności modelu.
Niektóre popularne aplikacje do klasyfikacji obejmują wykrywanie spamu, analizę nastrojów i wykrywanie oszustw. W każdym z tych przypadków dane wejściowe mogą zawierać tekst, wartości liczbowe lub ich kombinację. Etykiety klas mogą być binarne (np. spam lub nie spam) lub wieloklasowe (np. pozytywne, neutralne, negatywne nastawienie).
Rozważmy na przykład zbiór danych recenzji klientów na temat produktu. Danymi wejściowymi może być tekst recenzji, a etykietą klasy ocena (np. pozytywna, neutralna, negatywna). Model zostałby przeszkolony na zbiorze danych recenzji oznaczonych etykietą, a następnie byłby w stanie przewidzieć ocenę nowej recenzji, której wcześniej nie widział.
Typy algorytmów klasyfikacji ML
Istnieje kilka rodzajów algorytmów klasyfikacji w uczeniu maszynowym:
Regresja logistyczna
Jest to model liniowy używany do klasyfikacji binarnej. Służy do przewidywania prawdopodobieństwa wystąpienia określonego zdarzenia. Celem regresji logistycznej jest znalezienie najlepszych współczynników (wag), które minimalizują błąd między przewidywanym prawdopodobieństwem a obserwowanym wynikiem.
Odbywa się to za pomocą algorytmu optymalizacji, takiego jak opadanie gradientu, w celu dostosowania współczynników, aż model będzie jak najlepiej pasował do danych treningowych.
Drzewa decyzyjne
Są to modele przypominające drzewa, które podejmują decyzje na podstawie wartości cech. Można ich używać zarówno do klasyfikacji binarnej, jak i wieloklasowej. Drzewa decyzyjne mają kilka zalet, w tym prostotę i interoperacyjność.
Szybko uczą się i prognozują, a także radzą sobie zarówno z danymi liczbowymi, jak i kategorialnymi. Mogą być jednak podatne na przeuczenie, zwłaszcza jeśli drzewo jest głębokie i ma wiele gałęzi.
Losowa klasyfikacja lasów
Random Forest Classification to metoda zespołowa, która łączy prognozy z wielu drzew decyzyjnych, aby uzyskać dokładniejsze i stabilniejsze prognozy. Jest mniej podatne na przeuczenie niż pojedyncze drzewo decyzyjne, ponieważ prognozy poszczególnych drzew są uśredniane, co zmniejsza wariancję modelu.
AdaBoost
Jest to algorytm wzmacniający, który adaptacyjnie zmienia wagę błędnie sklasyfikowanych przykładów w zbiorze uczącym. Jest często używany do klasyfikacji binarnej.
Naiwny Bayes
Naiwny Bayes opiera się na twierdzeniu Bayesa, które jest sposobem aktualizacji prawdopodobieństwa zdarzenia na podstawie nowych dowodów. Jest to probabilistyczny klasyfikator często używany do klasyfikacji tekstu i filtrowania spamu.
K-Najbliższy sąsiad
K-Nearest Neighbors (KNN) jest używany do zadań klasyfikacji i regresji. Jest to metoda nieparametryczna, która klasyfikuje punkt danych na podstawie klasy jego najbliższych sąsiadów. KNN ma kilka zalet, w tym prostotę i łatwość wdrożenia. Może również obsługiwać zarówno dane liczbowe, jak i kategoryczne, i nie przyjmuje żadnych założeń dotyczących podstawowej dystrybucji danych.
Wzmocnienie gradientu
Są to zespoły słabych uczniów, które są szkolone sekwencyjnie, przy czym każdy model próbuje poprawić błędy poprzedniego modelu. Można ich używać zarówno do klasyfikacji, jak i regresji.
Regresja w uczeniu maszynowym
W uczeniu maszynowym regresja jest rodzajem uczenia nadzorowanego, w którym celem jest przewidywanie zmiennej zależnej od ac na podstawie jednej lub więcej cech wejściowych (zwanych także predyktorami lub zmiennymi niezależnymi).
Algorytmy regresji służą do modelowania relacji między danymi wejściowymi a danymi wyjściowymi oraz do prognozowania na podstawie tej relacji. Regresji można używać zarówno w przypadku zmiennych zależnych ciągłych, jak i kategorycznych.
Ogólnie rzecz biorąc, celem regresji jest zbudowanie modelu, który może dokładnie przewidzieć dane wyjściowe na podstawie cech wejściowych i zrozumieć podstawową relację między cechami wejściowymi a wynikami.
Analiza regresji jest wykorzystywana w różnych dziedzinach, w tym w ekonomii, finansach, marketingu i psychologii, do zrozumienia i przewidywania relacji między różnymi zmiennymi. Jest to podstawowe narzędzie w analizie danych i uczeniu maszynowym, które służy do przewidywania, identyfikowania trendów i zrozumienia mechanizmów leżących u podstaw danych.
Na przykład w prostym modelu regresji liniowej celem może być przewidywanie ceny domu na podstawie jego wielkości, lokalizacji i innych cech. Wielkość domu i jego lokalizacja byłyby zmiennymi niezależnymi, a cena domu byłaby zmienną zależną.
Model byłby szkolony na danych wejściowych, które obejmują wielkość i lokalizację kilku domów, wraz z odpowiadającymi im cenami. Po przeszkoleniu modelu można go wykorzystać do przewidywania ceny domu, biorąc pod uwagę jego wielkość i lokalizację.
Typy algorytmów regresji ML
Algorytmy regresji są dostępne w różnych formach, a zastosowanie każdego algorytmu zależy od liczby parametrów, takich jak rodzaj wartości atrybutu, wzór linii trendu i liczba zmiennych niezależnych. Często stosowane techniki regresji obejmują:
Regresja liniowa
Ten prosty model liniowy służy do przewidywania wartości ciągłej na podstawie zestawu cech. Służy do modelowania relacji między cechami a zmienną docelową poprzez dopasowanie linii do danych.
Regresja wielomianowa
Jest to model nieliniowy używany do dopasowania krzywej do danych. Służy do modelowania relacji między cechami a zmienną docelową, gdy zależność nie jest liniowa. Opiera się na idei dodawania terminów wyższego rzędu do modelu liniowego w celu uchwycenia nieliniowych relacji między zmiennymi zależnymi i niezależnymi.
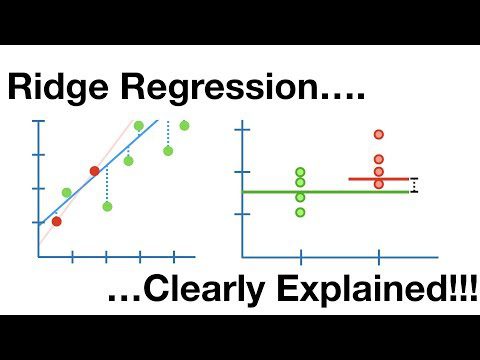
Regresja grzbietu
Jest to model liniowy, który rozwiązuje problem nadmiernego dopasowania w regresji liniowej. Jest to uregulowana wersja regresji liniowej, która dodaje do funkcji kosztu okres karny w celu zmniejszenia złożoności modelu.
Regresja wektora nośnego
Podobnie jak maszyny SVM, regresja wektorów nośnych jest modelem liniowym, który próbuje dopasować dane poprzez znalezienie hiperpłaszczyzny, która maksymalizuje margines między zmiennymi zależnymi i niezależnymi.
Jednak w przeciwieństwie do SVM, które są używane do klasyfikacji, SVR jest używany do zadań regresji, w których celem jest przewidywanie wartości ciągłej, a nie etykiety klasy.
Regresja Lasso
Jest to kolejny uregulowany model liniowy używany do zapobiegania nadmiernemu dopasowaniu w regresji liniowej. Dodaje termin kary do funkcji kosztu w oparciu o wartość bezwzględną współczynników.
Bayesowska regresja liniowa
Bayesowska regresja liniowa to probabilistyczne podejście do regresji liniowej oparte na twierdzeniu Bayesa, które jest sposobem aktualizacji prawdopodobieństwa zdarzenia na podstawie nowych dowodów.
Ten model regresji ma na celu oszacowanie późniejszego rozkładu parametrów modelu na podstawie danych. Odbywa się to poprzez zdefiniowanie wcześniejszego rozkładu parametrów, a następnie użycie twierdzenia Bayesa do aktualizacji rozkładu na podstawie zaobserwowanych danych.
Regresja a klasyfikacja
Regresja i klasyfikacja to dwa rodzaje uczenia nadzorowanego, co oznacza, że są one wykorzystywane do przewidywania wyników na podstawie zestawu cech wejściowych. Istnieje jednak kilka kluczowych różnic między nimi:
RegresjaKlasyfikacjaDefinicjaTyp uczenia nadzorowanego, który przewiduje wartość ciągłąTyp uczenia nadzorowanego, który przewiduje wartość kategorycznąTyp wynikuCiągłeDyskretneMetryki ocenyŚredni błąd kwadratowy (MSE), pierwiastek błędu średniokwadratowego (RMSE)Dokładność, precyzja, przypomnienie, wynik F1AlgorytmyRegresja liniowa, Lasso, Ridge, KNN, Drzewo decyzyjne Regresja logistyczna, SVM, Naïve Bayes, KNN, Drzewo decyzyjne Złożoność modelu Mniej złożone modele Bardziej złożone modele Założenia Liniowa zależność między cechami a celem Brak konkretnych założeń dotyczących relacji między cechami a wartością docelową Nierównowaga klas Nie dotyczy Może stanowić problem Wartości odstające Mogą wpływać na wydajność modelu Zwykle nie stanowi problemu Ważność cechy Cechy są uszeregowane według ważności Cechy nie są uszeregowane według ważnościPrzykładowe zastosowaniaPrzewidywanie cen, temperatur, ilościPrzewidywanie spamu e-mailowego, przewidywanie rezygnacji klientów
Zasoby edukacyjne
Wybór najlepszych zasobów online do zrozumienia koncepcji uczenia maszynowego może być trudny. Przeanalizowaliśmy popularne kursy oferowane przez niezawodne platformy, aby przedstawić Ci nasze rekomendacje dotyczące najlepszych kursów ML dotyczących regresji i klasyfikacji.
# 1. Bootcamp klasyfikacji uczenia maszynowego w Pythonie
Jest to kurs oferowany na platformie Udemy. Obejmuje różnorodne algorytmy i techniki klasyfikacji, w tym drzewa decyzyjne i regresję logistyczną, a także obsługuje maszyny wektorowe.

Możesz także dowiedzieć się o takich tematach, jak nadmierne dopasowanie, kompromis między odchyleniami a wariancją oraz ocena modelu. Kurs wykorzystuje biblioteki Pythona, takie jak sci-kit-learn i pandas, do implementacji i oceny modeli uczenia maszynowego. Aby rozpocząć ten kurs, wymagana jest podstawowa znajomość Pythona.
#2. Masterclass regresji uczenia maszynowego w Pythonie
W tym kursie Udemy trener omawia podstawy i podstawową teorię różnych algorytmów regresji, w tym regresji liniowej, regresji wielomianowej oraz technik regresji Lasso & Ridge.
Pod koniec tego kursu będziesz w stanie wdrożyć algorytmy regresji i ocenić wydajność wyszkolonych modeli uczenia maszynowego przy użyciu różnych kluczowych wskaźników wydajności.
Podsumowanie
Algorytmy uczenia maszynowego mogą być bardzo przydatne w wielu aplikacjach i mogą pomóc zautomatyzować i usprawnić wiele procesów. Algorytmy ML wykorzystują techniki statystyczne do uczenia się wzorców w danych i dokonywania prognoz lub podejmowania decyzji na podstawie tych wzorców.
Mogą być szkolone na dużych ilościach danych i mogą być wykorzystywane do wykonywania zadań, które byłyby trudne lub czasochłonne dla ludzi do ręcznego wykonania.
Każdy algorytm ML ma swoje mocne i słabe strony, a wybór algorytmu zależy od charakteru danych i wymagań zadania. Ważne jest, aby wybrać odpowiedni algorytm lub kombinację algorytmów dla konkretnego problemu, który próbujesz rozwiązać.
Ważne jest, aby wybrać odpowiedni typ algorytmu do problemu, ponieważ użycie niewłaściwego typu algorytmu może prowadzić do niskiej wydajności i niedokładnych prognoz. Jeśli nie masz pewności, którego algorytmu użyć, pomocne może być wypróbowanie algorytmów regresji i klasyfikacji oraz porównanie ich wydajności w zbiorze danych.
Mam nadzieję, że ten artykuł okazał się pomocny w nauce regresji a klasyfikacji w uczeniu maszynowym. Możesz być również zainteresowany poznaniem najlepszych modeli uczenia maszynowego.