Jak używać Scikit-LLM do analizy tekstu z dużymi modelami językowymi
Scikit-LLM to biblioteka języka Python, która ułatwia integrację zaawansowanych modeli językowych (LLM) z architekturą scikit-learn. Jest pomocna w realizacji zadań związanych z przetwarzaniem tekstu. Osobom zaznajomionym z scikit-learn, praca z Scikit-LLM będzie znacznie prostsza.
Warto podkreślić, że Scikit-LLM nie stanowi zamiennika dla scikit-learn. Scikit-learn jest uniwersalnym zbiorem narzędzi do uczenia maszynowego, natomiast Scikit-LLM koncentruje się na zadaniach związanych z analizą tekstową.
Pierwsze kroki z Scikit-LLM
Aby rozpocząć przygodę z Scikit-LLM, konieczne jest zainstalowanie biblioteki i skonfigurowanie klucza API. W tym celu należy otworzyć środowisko programistyczne (IDE) i stworzyć nowe wirtualne środowisko. Pozwoli to uniknąć potencjalnych konfliktów pomiędzy wersjami różnych bibliotek. Następnie w terminalu należy uruchomić następujące polecenie:
pip install scikit-llm
To polecenie zainstaluje Scikit-LLM wraz z wszystkimi wymaganymi zależnościami.
Aby skonfigurować klucz API, trzeba go pozyskać od dostawcy usług LLM. Aby uzyskać klucz OpenAI API, postępuj zgodnie z poniższymi instrukcjami:
Przejdź do strony API OpenAI. Następnie w prawym górnym rogu okna kliknij swój profil. Z menu wybierz opcję "Wyświetl klucze API", która przeniesie Cię na dedykowaną stronę.
Na stronie "Klucze API" wybierz przycisk "Utwórz nowy tajny klucz".
Nadaj nazwę swojemu kluczowi API i kliknij "Utwórz tajny klucz". Wygenerowany klucz należy skopiować i zapisać w bezpiecznym miejscu, ponieważ OpenAI nie udostępnia go ponownie. W przypadku utraty klucza, konieczne będzie wygenerowanie nowego.
Po uzyskaniu klucza API, otwórz IDE i zaimportuj klasę `SKLLMConfig` z biblioteki Scikit-LLM. Ta klasa umożliwia konfigurację opcji związanych z wykorzystaniem dużych modeli językowych.
from skllm.config import SKLLMConfig
W tym kroku należy ustawić klucz API OpenAI oraz dane organizacji.
SKLLMConfig.set_openai_key("Twój klucz API")
SKLLMConfig.set_openai_org("Identyfikator Twojej organizacji")
Identyfikator organizacji i nazwa nie są identyczne. Identyfikator organizacji to unikalny ciąg znaków przypisany do Twojej organizacji. Aby go zdobyć, przejdź do strony ustawień organizacji OpenAI i skopiuj identyfikator. W ten sposób ustanowione zostanie połączenie między Scikit-LLM a dużym modelem językowym.
Scikit-LLM wymaga aktywnego planu płatności, rozliczanego zgodnie z faktycznym zużyciem zasobów. Jest to spowodowane faktem, że bezpłatne konta testowe OpenAI mają ograniczenie do trzech żądań na minutę, co jest niewystarczające dla Scikit-LLM.
Podczas próby analizy tekstu przy użyciu bezpłatnego konta testowego, może wystąpić błąd zbliżony do poniższego:

Więcej informacji na temat limitów zapytań można znaleźć na stronie poświęconej limitom OpenAI.
Usługi LLM nie są ograniczone tylko do OpenAI. Można korzystać z rozwiązań innych dostawców.
Importowanie niezbędnych bibliotek i ładowanie zbioru danych
Zaimportuj bibliotekę Pandas, która będzie wykorzystana do załadowania zbioru danych. Ponadto z Scikit-LLM i scikit-learn zaimportuj wymagane klasy.
import pandas as pd
from skllm import ZeroShotGPTClassifier, MultiLabelZeroShotGPTClassifier
from skllm.preprocessing import GPTSummarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.preprocessing import MultiLabelBinarizer
Następnie załaduj zbiór danych, na którym chcesz przeprowadzić analizę. W tym przykładzie wykorzystano zbiór danych filmów IMDB. Można go jednak dostosować do dowolnego własnego zestawu danych.
data = pd.read_csv("imdb_movies_dataset.csv")
data = data.head(100)
Użycie pierwszych 100 wierszy zbioru nie jest obowiązkowe. Można wykorzystać całość swojego zbioru danych.
Kolejnym krokiem jest wyodrębnienie danych i kolumn z etykietami, a następnie podzielenie zbioru na część treningową i testową.
X = data['Description']y = data['Genre']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Kolumna "Gatunek" zawiera kategorie, które będą prognozowane.
Klasyfikacja tekstu Zero-Shot z Scikit-LLM
Klasyfikacja tekstu Zero-Shot to funkcja oferowana przez duże modele językowe. Pozwala na klasyfikację tekstu do predefiniowanych kategorii bez konieczności wcześniejszego trenowania na oznaczonych danych. Jest szczególnie przydatna, gdy zachodzi potrzeba klasyfikowania tekstu do kategorii, które nie były przewidziane na etapie uczenia modelu.
Do przeprowadzenia klasyfikacji tekstu Zero-Shot przy użyciu Scikit-LLM, wykorzystywana jest klasa `ZeroShotGPTClassifier`.
zero_shot_clf = ZeroShotGPTClassifier(openai_model="gpt-3.5-turbo")
zero_shot_clf.fit(X_train, y_train)
zero_shot_predictions = zero_shot_clf.predict(X_test)
print("Raport z klasyfikacji tekstu Zero-Shot:")
print(classification_report(y_test, zero_shot_predictions))
Poniżej przedstawiono przykładowy wynik:
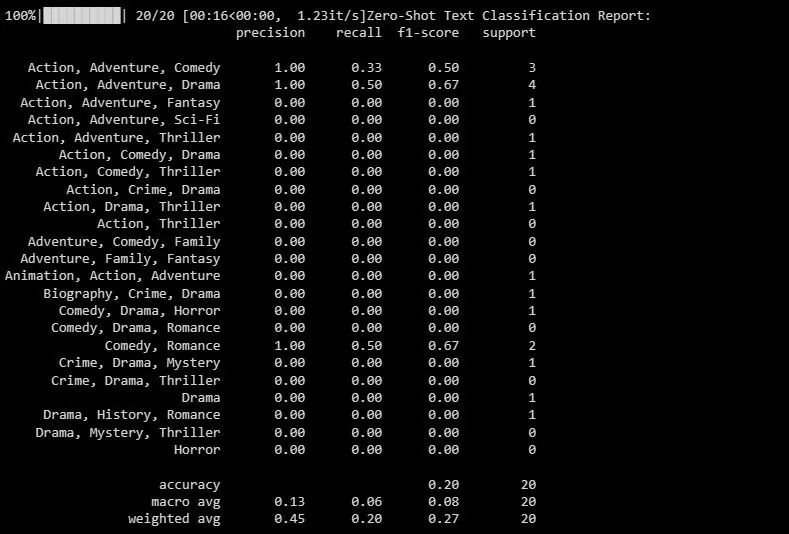
Raport klasyfikacji zawiera metryki skuteczności dla każdej etykiety, którą model stara się przewidzieć.
Klasyfikacja tekstu Multi-Label Zero-Shot z Scikit-LLM
W pewnych sytuacjach dany fragment tekstu może należeć jednocześnie do wielu kategorii. Tradycyjne modele klasyfikacji mogą mieć z tym problem. Scikit-LLM natomiast umożliwia klasyfikację wieloetykietową. Jest ona kluczowa, gdy chcemy przypisać wiele opisowych etykiet do pojedynczej próbki tekstu.
Do przewidywania, które etykiety pasują do danej próbki tekstu, należy użyć klasy `MultiLabelZeroShotGPTClassifier`.
candidate_labels = ["Akcja", "Komedia", "Dramat", "Horror", "Sci-Fi"]
multi_label_zero_shot_clf = MultiLabelZeroShotGPTClassifier(max_labels=2)
multi_label_zero_shot_clf.fit(X_train, candidate_labels)
multi_label_zero_shot_predictions = multi_label_zero_shot_clf.predict(X_test)
mlb = MultiLabelBinarizer()
y_test_binary = mlb.fit_transform(y_test)
multi_label_zero_shot_predictions_binary = mlb.transform(multi_label_zero_shot_predictions)
print("Raport z klasyfikacji tekstu Multi-Label Zero-Shot:")
print(classification_report(y_test_binary, multi_label_zero_shot_predictions_binary))
W powyższym przykładzie definiowane są potencjalne etykiety, do których może należeć tekst.
Poniżej znajduje się przykładowy wynik:
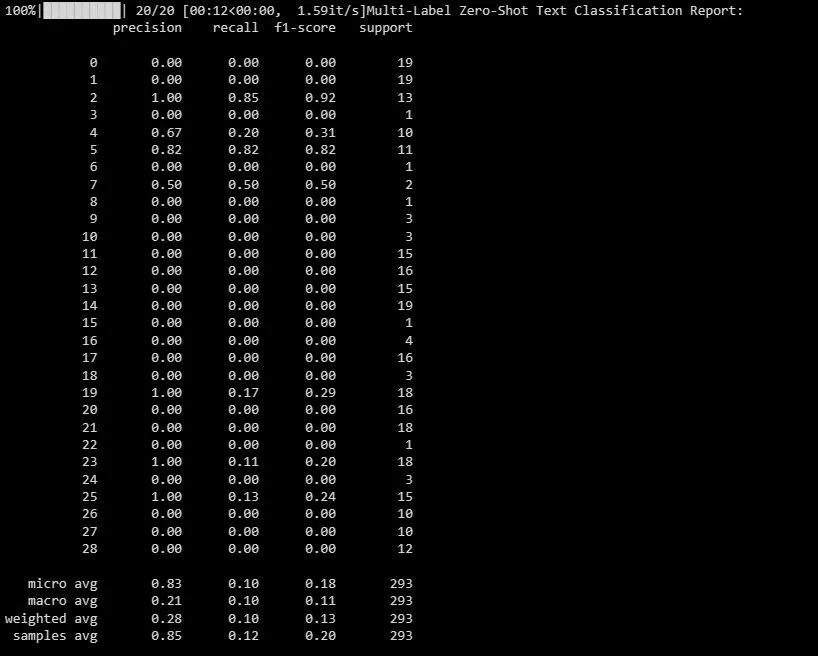
Ten raport pomaga ocenić skuteczność modelu w przypadku każdej etykiety w klasyfikacji wieloetykietowej.
Wektoryzacja tekstu z Scikit-LLM
W procesie wektoryzacji tekstu, dane tekstowe konwertowane są na format liczbowy, zrozumiały dla modeli uczenia maszynowego. Scikit-LLM udostępnia w tym celu klasę `GPTVectorizer`. Umożliwia ona przekształcanie tekstu na wektory o stałych wymiarach przy użyciu modeli GPT.
Można to osiągnąć przy użyciu metody Częstotliwość Terminu - Odwrotna Częstotliwość Dokumentu (TF-IDF).
tfidf_vectorizer = TfidfVectorizer(max_features=1000)
X_train_tfidf = tfidf_vectorizer.fit_transform(X_train)
X_test_tfidf = tfidf_vectorizer.transform(X_test)
print("Wektoryzacja TF-IDF (pierwsze 5 próbek):")
print(X_train_tfidf[:5])
Poniżej przedstawiono przykładowy wynik:
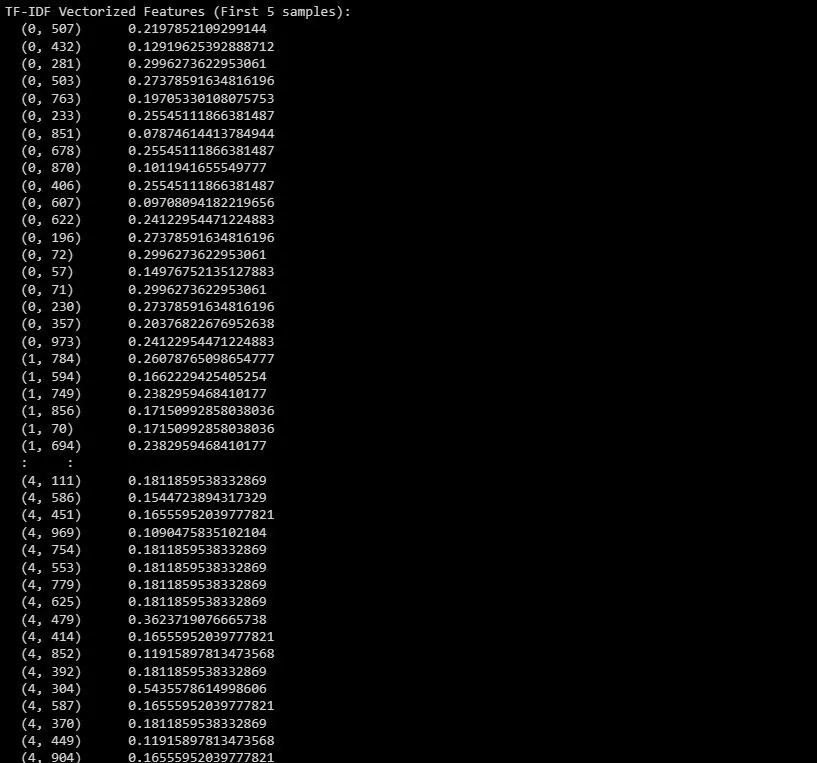
Wynik przedstawia wektoryzowane cechy TF-IDF dla pierwszych 5 próbek w zbiorze danych.
Streszczanie tekstu z Scikit-LLM
Streszczanie tekstu polega na kondensacji dłuższego fragmentu tekstu, zachowując najważniejsze informacje. Scikit-LLM oferuje klasę `GPTSummarizer`, która wykorzystuje modele GPT do generowania zwięzłych streszczeń.
summarizer = GPTSummarizer(openai_model="gpt-3.5-turbo", max_words=15)
summaries = summarizer.fit_transform(X_test)
print(summaries)
Poniżej znajduje się przykładowy wynik:
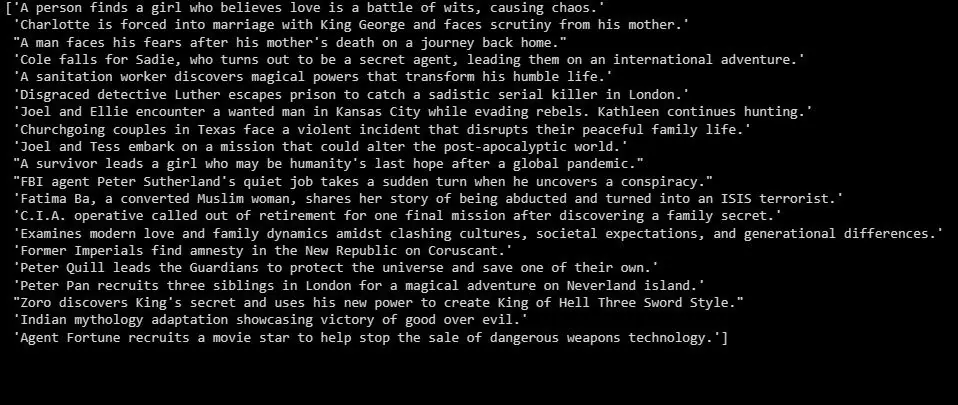
Powyżej przedstawiono streszczenia danych testowych.
Budowanie aplikacji w oparciu o LLM
Scikit-LLM otwiera nowe możliwości w zakresie analizy tekstu przy użyciu dużych modeli językowych. Zrozumienie technologii stojącej za dużymi modelami językowymi jest niezwykle ważne. Pozwala to poznać ich zalety i wady, co może być przydatne podczas tworzenia wydajnych aplikacji wykorzystujących tę zaawansowaną technologię.
