Jak zaimplementować nieskończone przewijanie i paginację za pomocą Next.js i zapytania TanStack
Większość tworzonych aplikacji w pewnym stopniu przetwarza dane. Wraz z rozbudową programów, ilość tych danych może dynamicznie rosnąć. Jeśli aplikacje nie radzą sobie efektywnie z dużymi zbiorami informacji, ich wydajność może drastycznie spaść.
Paginacja i przewijanie nieskończone to dwie popularne strategie optymalizacji działania aplikacji. Umożliwiają one sprawniejsze renderowanie danych, co przekłada się na lepsze wrażenia użytkownika.
Paginacja i nieskończone przewijanie z wykorzystaniem TanStack Query
TanStack Query, będący adaptacją React Query, to potężna biblioteka do zarządzania stanem w aplikacjach JavaScript. Oferuje efektywne rozwiązania w zakresie zarządzania stanem, jak również szereg innych funkcji, w tym tych związanych z danymi, takich jak buforowanie.
Paginacja polega na dzieleniu dużego zbioru danych na mniejsze, łatwiejsze do opanowania strony, po których użytkownik może nawigować za pomocą przycisków. Z kolei przewijanie nieskończone oferuje bardziej dynamiczne przeglądanie – gdy użytkownik przesuwa stronę w dół, nowe dane są automatycznie ładowane, bez konieczności używania przycisków nawigacyjnych.
Zarówno paginacja, jak i przewijanie nieskończone, służą efektywnemu zarządzaniu i prezentowaniu dużych ilości danych. Wybór między nimi zależy od specyficznych wymagań aplikacji.
Kod tego projektu znajduje się w tym repozytorium GitHub.
Konfiguracja projektu Next.js
Na początek, utwórz nowy projekt Next.js. Zainstaluj najnowszą wersję Next.js 13, która korzysta z katalogu aplikacji.
npx create-next-app@latest next-project --app
Następnie, za pomocą menedżera pakietów Node, npm, zainstaluj bibliotekę TanStack w swoim projekcie.
npm i @tanstack/react-query
Integracja TanStack Query z aplikacją Next.js
Aby zintegrować TanStack Query z projektem Next.js, należy utworzyć i zainicjować nową instancję TanStack Query w głównym katalogu aplikacji – w pliku layout.js. W tym celu, zaimportuj QueryClient i QueryClientProvider z TanStack Query. Następnie, umieść element podrzędny (dziecko) wewnątrz QueryClientProvider, tak jak pokazano poniżej:
"use client"
import React from 'react'
import { QueryClient, QueryClientProvider } from '@tanstack/react-query';
const metadata = {
title: 'Create Next App',
description: 'Generated by create next app',
};
export default function RootLayout({ children }) {
const queryClient = new QueryClient();
return (
<html lang="en">
<body>
<QueryClientProvider client={queryClient}>
{children}
</QueryClientProvider>
</body>
</html>
);
}
export { metadata };
Ta konfiguracja zapewnia, że TanStack Query ma dostęp do stanu całej aplikacji.
Hook `useQuery` ułatwia pobieranie i zarządzanie danymi. Podając parametry paginacji, takie jak numery stron, można z łatwością pobrać konkretne fragmenty danych.
Ponadto, hook oferuje różnorodne opcje konfiguracyjne, pozwalające dostosować funkcjonalność pobierania danych, w tym ustawianie opcji pamięci podręcznej, a także efektywne zarządzanie stanami ładowania. Dzięki tym możliwościom, można bez problemu zaimplementować sprawną paginację.
Aby wdrożyć paginację w aplikacji Next.js, utwórz plik `Pagination/page.js` w katalogu `src/app`. Wewnątrz tego pliku, dokonaj następujących importów:
"use client"
import React, { useState } from 'react';
import { useQuery} from '@tanstack/react-query';
import './page.styles.css';
Następnie zdefiniuj komponent funkcyjny React. W tym komponencie zdefiniuj funkcję, która pobiera dane z zewnętrznego API. W tym przypadku skorzystaj z JSON Placeholder API, aby pobrać zestaw postów.
export default function Pagination() {
const [page, setPage] = useState(1);
const fetchPosts = async () => {
try {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts?
_page=${page}&_limit=10`);
if (!response.ok) {
throw new Error('Failed to fetch posts');
}
const data = await response.json();
return data;
} catch (error) {
console.error(error);
throw error;
}
};
}
Teraz zdefiniuj hook `useQuery` i przekaz parametry jako obiekty:
const { isLoading, isError, error, data } = useQuery({
keepPreviousData: true,
queryKey: ['posts', page],
queryFn: fetchPosts,
});
Ustawienie `keepPreviousData` na `true` gwarantuje, że aplikacja zachowa poprzednie dane podczas pobierania nowych. Parametr `queryKey` to tablica zawierająca klucz zapytania, w tym przypadku punkt końcowy oraz bieżącą stronę, dla której chcemy pobrać dane. Parametr `queryFn` `fetchPosts` uruchamia funkcję pobierającą dane.
Jak wspomniano, hook udostępnia kilka stanów, które można rozpakować, wykorzystując destrukturyzację tablic i obiektów. Te stany mogą być użyte do polepszenia doświadczenia użytkownika poprzez wyświetlanie odpowiednich interfejsów podczas pobierania danych. Stany te to między innymi: `isLoading`, `isError` i inne.
Aby zaimplementować ekrany komunikatów w zależności od bieżącego stanu procesu, dodaj następujący kod:
if (isLoading) {
return (<h2>Loading...</h2>);
}
if (isError) {
return (<h2 className="error-message">{error.message}</h2>);
}
Na koniec dodaj kod elementów JSX, które zostaną wyrenderowane na stronie. Kod ten pełni dwie funkcje:
- Gdy aplikacja pobierze posty z API, zapisuje je w zmiennej `data` dostarczonej przez hook `useQuery`. Ta zmienna ułatwia zarządzanie stanem aplikacji. Następnie można zmapować listę postów i wyrenderować je w przeglądarce.
- Dodaje dwa przyciski nawigacyjne, "Poprzednia strona" i "Następna strona", które umożliwiają użytkownikom przełączanie między stronami z danymi.
return (
<div>
<h2 className="header">Next.js Pagination</h2>
{data && (
<div className="card">
<ul className="post-list">
{data.map((post) => (
<li key={post.id} className="post-item">{post.title}</li>
))}
</ul>
</div>
)}
<div className="btn-container">
<button
onClick={() => setPage(prevState => Math.max(prevState - 1, 0))}
disabled={page === 1}
className="prev-button"
>Prev Page</button>
<button
onClick={() => setPage(prevState => prevState + 1)}
className="next-button"
>Next Page</button>
</div>
</div>
);
Na zakończenie uruchom serwer developerski.
npm run dev
Następnie przejdź do adresu http://localhost:3000/Pagination w przeglądarce.
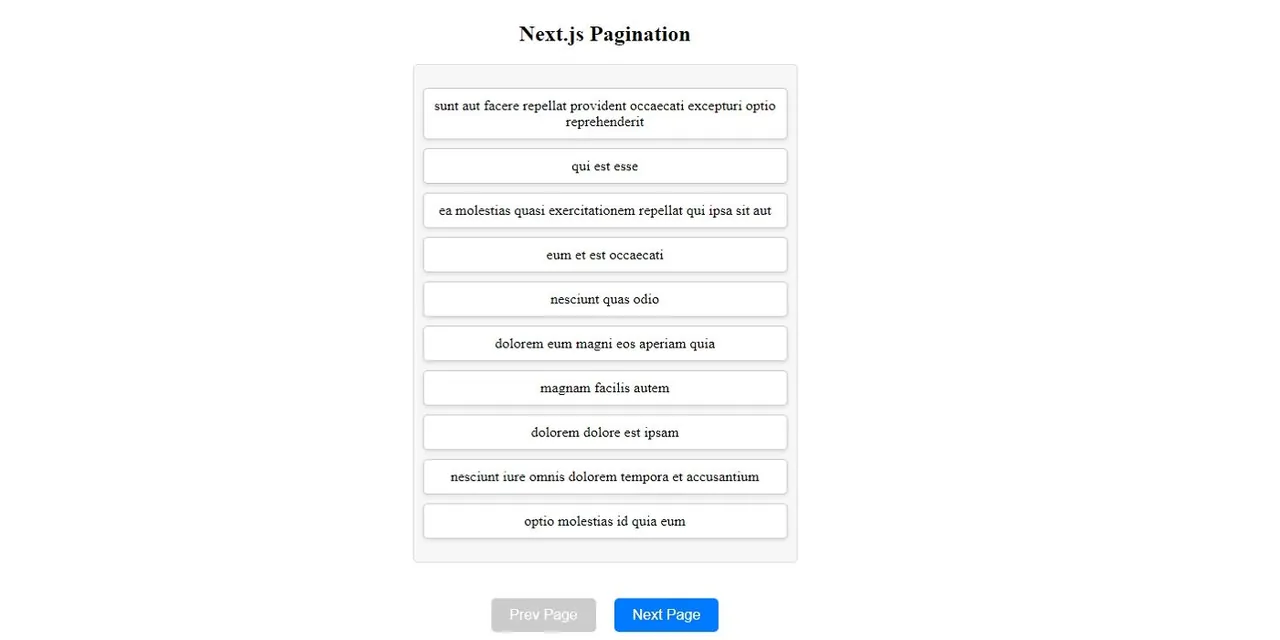
Ponieważ folder `Pagination` znajduje się w katalogu `app`, Next.js traktuje go jako trasę, umożliwiając dostęp do strony pod tym adresem URL.
Przewijanie nieskończone zapewnia płynne przeglądanie. Dobrym przykładem jest YouTube, który automatycznie pobiera nowe filmy podczas przewijania w dół.
Hook `useInfiniteQuery` umożliwia implementację przewijania nieskończonego poprzez pobieranie danych z serwera w podziałach na strony oraz automatyczne pobieranie i renderowanie kolejnych stron danych, gdy użytkownik przesuwa stronę w dół.
Aby wdrożyć nieskończone przewijanie, dodaj plik `InfiniteScroll/page.js` w katalogu `src/app`. Następnie dodaj następujące importy:
"use client"
import React, { useRef, useEffect, useState } from 'react';
import { useInfiniteQuery } from '@tanstack/react-query';
import './page.styles.css';
Następnie stwórz komponent funkcyjny React. Wewnątrz tego komponentu, podobnie jak w implementacji paginacji, utwórz funkcję, która będzie pobierać dane postów.
export default function InfiniteScroll() {
const listRef = useRef(null);
const [isLoadingMore, setIsLoadingMore] = useState(false);
const fetchPosts = async ({ pageParam = 1 }) => {
try {
const response = await fetch(`https://jsonplaceholder.typicode.com/posts?
_page=${pageParam}&_limit=5`);
if (!response.ok) {
throw new Error('Failed to fetch posts');
}
const data = await response.json();
await new Promise((resolve) => setTimeout(resolve, 2000));
return data;
} catch (error) {
console.error(error);
throw error;
}
};
}
W przeciwieństwie do implementacji paginacji, ten kod wprowadza dwusekundowe opóźnienie podczas pobierania danych, umożliwiając użytkownikowi eksplorację bieżących danych podczas przewijania, zanim uruchomi się pobieranie kolejnego zestawu danych.
Teraz zdefiniuj hook `useInfiniteQuery`. Po pierwszym zamontowaniu komponentu, hook pobierze pierwszą stronę danych z serwera. Gdy użytkownik przewija stronę w dół, hook automatycznie pobierze kolejną stronę danych i wyrenderuje ją w komponencie.
const { data, fetchNextPage, hasNextPage, isFetching } = useInfiniteQuery({
queryKey: ['posts'],
queryFn: fetchPosts,
getNextPageParam: (lastPage, allPages) => {
if (lastPage.length < 5) {
return undefined;
}
return allPages.length + 1;
},
});
const posts = data ? data.pages.flatMap((page) => page) : [];
Zmienna `posts` łączy wszystkie posty z różnych stron w jedną tablicę, tworząc spłaszczoną wersję zmiennej `data`. Umożliwia to łatwe mapowanie i renderowanie poszczególnych postów.
Aby śledzić przewijanie użytkownika i ładować więcej danych, gdy użytkownik jest blisko dołu listy, można zdefiniować funkcję wykorzystującą Intersection Observer API do wykrywania, kiedy elementy przecinają się z widocznym obszarem.
const handleIntersection = (entries) => {
if (entries[0].isIntersecting && hasNextPage && !isFetching && !isLoadingMore) {
setIsLoadingMore(true);
fetchNextPage();
}
};
useEffect(() => {
const observer = new IntersectionObserver(handleIntersection, { threshold: 0.1 });
if (listRef.current) {
observer.observe(listRef.current);
}
return () => {
if (listRef.current) {
observer.unobserve(listRef.current);
}
};
}, [listRef, handleIntersection]);
useEffect(() => {
if (!isFetching) {
setIsLoadingMore(false);
}
}, [isFetching]);
Na koniec dodaj elementy JSX do postów renderowanych w przeglądarce.
return (
<div>
<h2 className="header">Infinite Scroll</h2>
<ul ref={listRef} className="post-list">
{posts.map((post) => (
<li key={post.id} className="post-item">
{post.title}
</li>
))}
</ul>
<div className="loading-indicator">
{isFetching ? 'Fetching...' : isLoadingMore ? 'Loading more...' : null}
</div>
</div>
);
Po wprowadzeniu wszystkich zmian, odwiedź adres http://localhost:3000/InfiniteScroll, aby zobaczyć działanie nieskończonego przewijania.
TanStack Query: znacznie więcej niż tylko pobieranie danych
Paginacja i nieskończone przewijanie są dobrymi przykładami, które pokazują możliwości TanStack Query. W najprostszych słowach, jest to uniwersalna biblioteka do zarządzania danymi.
Dzięki bogatemu zestawowi funkcji, można usprawnić procesy zarządzania danymi w aplikacji, w tym efektywne zarządzanie stanem. Oprócz obsługi różnych zadań związanych z danymi, można poprawić wydajność aplikacji internetowych, jak również wygodę użytkowania.
