

Zmiana nazw kolumn w ramce danych Pandas jest powszechną operacją. Poznaj cztery różne metody zmiany nazw kolumn pandas.
Pandas to popularna biblioteka Pythona do analizy danych. Dane, które musimy przeanalizować, są często dostępne w różnych formatach, w tym w plikach csv i tsv, relacyjnych bazach danych i nie tylko. Musisz przeprowadzić wstępne sprawdzenie danych, obsłużyć brakujące wartości i przygotować dane do dalszej analizy.
Dzięki pandom możesz:
- Pozyskuj dane z różnych źródeł
- Eksploruj zestaw danych i obsługuj w nim brakujące wartości
- Analizuj zestaw danych, aby uzyskać szczegółowe informacje
We wszystkich projektach analizy danych będziesz często tworzyć ramki danych ze struktur danych Pythona, takich jak słownik. Możesz też wczytać dane z innych źródeł, takich jak plik csv do ramki danych.
Dataframe to podstawowa struktura danych w pandach. Zawiera rekordy wzdłuż wierszy oraz różne pola lub atrybuty wzdłuż kolumn.
Jednak może być konieczna zmiana nazw kolumn — aby były bardziej opisowe i poprawiały czytelność. Tutaj poznasz cztery różne sposoby zmiany nazw kolumn. Zaczynajmy!
Spis treści:
Tworzenie Pandas DataFrame
Możesz śledzić samouczek w środowisku notebooka Jupyter z zainstalowanymi pandami. Możesz też śledzić w Google Colab.
Najpierw utworzymy ramkę danych Pandas i będziemy z nią pracować przez pozostałą część samouczka.
Oto słownik book_dict:
books_dict = {
"one": [
"Atomic Habits",
"His Dark Materials",
"The Midnight Library",
"The Broken Earth",
"Anxious People",
],
"two": [
"James Clear",
"Philip Pullman",
"Matt Haig",
"N.K.Jemisin",
"Fredrik Backman",
],
"three": ["Nonfiction", "Fantasy", "Magical Realism", "Fantasy", "Fiction"],
"four": [4, 5, 3, 5, 4],
}
Najpierw zaimportujemy pandy, a następnie utworzymy ramkę danych df z books_dict.
import pandas as pd
Uwaga: Będziemy wracać do następującej komórki kodu — aby utworzyć początkową wersję ramki danych — przed zmianą nazw kolumn.
df = pd.DataFrame(books_dict)
Możemy użyć funkcji df.head(), aby uzyskać kilka pierwszych wierszy ramki danych df. Domyślnie zwraca pierwsze pięć wierszy. Tutaj df ma tylko pięć wierszy; więc używając df.head() otrzymujemy całą ramkę danych.
df.head()
Widzimy, że nazwy kolumn są obecnie kluczami słownika. Ale to nie jest zbyt opisowe. Więc zmieńmy ich nazwy! 👩🏫
Metody zmiany nazw kolumn w pandach
Przyjrzyjmy się teraz różnym metodom zmiany nazw kolumn w pandach:
- Ustawienie atrybutu columns ramki danych na listę nowych nazw kolumn
- Użycie metody rename() w ramce danych
- Używanie str.replace do zmiany nazwy jednej lub więcej kolumn
- Użycie metody set_axis() na ramce danych
Ustawianie atrybutu kolumn
Dla dowolnej ramki danych atrybut columns zawiera listę nazw kolumn:
df.columns # Index(['one', 'two', 'three', 'four'], dtype="object")
Zmieńmy nazwy kolumn, aby oznaczyć, co oznacza każde pole, a następnie wywołajmy funkcję df.head(), aby zobaczyć wyniki:
df.columns = ['Title','Author','Genre','Rating'] df.head()
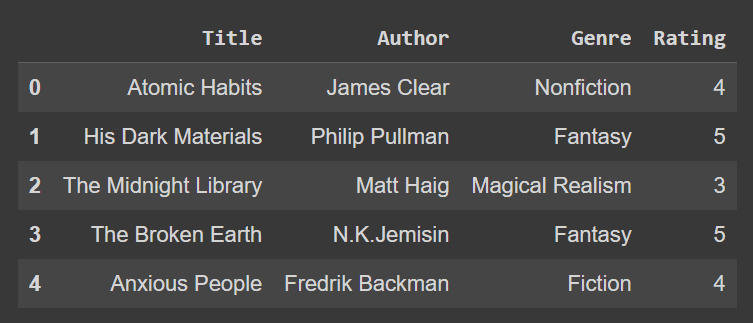
Używając metody rename().
Aby zmienić nazwy kolumn w pandach, możesz użyć metody rename() ze składnią:
df.rename(column={mapping})
To odwzorowanie może być słownikiem o następującej postaci:
{'old_col_name_1':'new_col_name_1', 'old_col_name_2':'new_col_name_2',...,
'old_col_name_n':'new_col_name_n'}
Stwórzmy df ze słownika books_dict:
df = pd.DataFrame(books_dict)
Używając metody rename() z powyższą składnią, otrzymujemy df_1. Która jest kopią ramki danych ze zmienionymi nazwami kolumn.
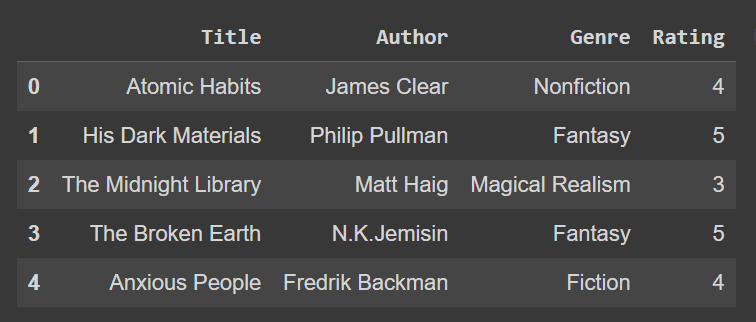
df_1 = df.rename(columns={'one':'Title','two':'Author','three':'Genre','four':'Rating'})
df_1.head()
Tak więc nazwy kolumn df_1 są modyfikowane:
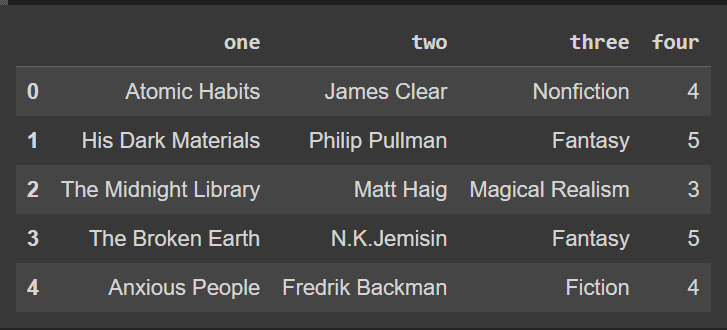
Ale nazwy kolumn oryginalnej ramki danych df nie zmieniają się:
df.head()
Ponieważ ta metoda pozwala nam zapewnić mapowanie między starymi i nowymi nazwami kolumn, możemy jej użyć do zmiany nazw zarówno pojedynczych, jak i wielu kolumn.
Zmień nazwy kolumn na miejscu
Co zrobić, jeśli chcesz zmodyfikować istniejącą ramkę danych — bez tworzenia nowej kopii?
Aby to zrobić, możesz ustawić miejsce równe True w wywołaniu metody.
df.rename(columns={'one':'Title','two':'Author','three':'Genre','four':'Rating'},inplace=True)
df.head()
Spowoduje to zmianę nazw kolumn oryginalnej ramki danych df:
Do tej pory widzieliśmy, jak:
- Zmień nazwy kolumn, udostępniając słownik, który odwzorowuje stare nazwy kolumn na nowe nazwy kolumn
- Zmieniaj nazwy kolumn na miejscu bez tworzenia nowej ramki danych
Możesz także użyć metody zmiany nazwy w inny sposób.
Inne podejście do zmiany nazw kolumn
Zmieńmy nazwy kolumn, aby były pisane wielkimi literami:
df = pd.DataFrame(books_dict)
df.columns = ['TITLE','AUTHOR','GENRE','RATING'] df.head()
Dataframe df wygląda teraz tak:
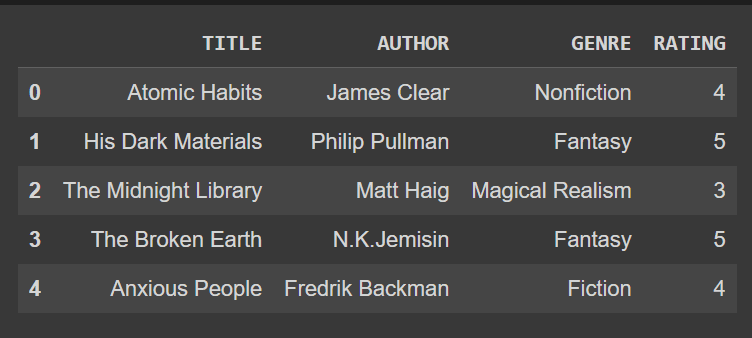
Załóżmy, że chcemy zmienić każdą z tych nazw kolumn, aby były w tytule. Zamiast dostarczać słownik dla każdej nazwy kolumny, możemy określić wywołanie funkcji lub metody dla obiektu, jak pokazano:
df.rename(str.title,axis="columns",inplace=True) df.head()
Tutaj ustawiamy oś na „kolumny” i używamy str.title do konwersji wszystkich nazw kolumn na wielkość liter w tytule.
Używanie str.replace() na ciągach nazw kolumn
Jak zawsze uruchom następującą komórkę kodu, aby utworzyć ramkę danych ze słownika:
df = pd.DataFrame(books_dict)
W Pythonie użyłbyś metody replace() o składni str.replace(this, with_this), aby uzyskać kopię łańcucha z wymaganymi zmianami. Oto przykład:
>>> str1 = 'Marathon'
>>> str1.replace('Mara','Py')
'Python'
Wiesz, że atrybut columns zawiera listę napisów zawierających nazwy kolumn. Możesz więc wywołać str.replace(’old_column_name’,’new_column_name’) w ten sposób:
df.columns = df.columns.str.replace('one','Title')
df.head()
Tutaj zmieniliśmy nazwę tylko kolumny „jeden” na „Tytuł”, więc pozostałe nazwy kolumn pozostają niezmienione.
Teraz zmieńmy nazwy innych kolumn, stosując to samo podejście:
df.columns = df.columns.str.replace('two','Author')
df.columns = df.columns.str.replace('three','Genre')
df.columns = df.columns.str.replace('four','Rating')
df.head()
Ta metoda zmiany nazw kolumn jest przydatna, gdy trzeba zmienić nazwę tylko jednego lub niewielkiego podzbioru kolumn.
Za pomocą metody set_axis().
Wróćmy do początkowej wersji ramki danych:
df = pd.DataFrame(books_dict)
Możesz także użyć metody set_axis() do zmiany nazw kolumn. Składnia jest następująca:
df.set_axis([list_of_column_names],axis="columns")
Domyślnie metoda set_axis() zwraca kopię ramki danych. Ale jeśli chcesz zmodyfikować ramkę danych na miejscu, możesz ustawić copy na False.
df = df.set_axis(['Title','Author','Genre','Rating'],axis="columns",copy=False) df.head()
Wniosek
Oto przegląd różnych metod zmiany nazw kolumn w ramce danych pandy:
- W przypadku przykładowej ramki danych df atrybut kolumn df.columns jest listą nazw kolumn. Aby zmienić nazwy kolumn, możesz ustawić ten atrybut na listę nowych nazw kolumn.
- Metoda rename() służąca do zmiany nazw kolumn działa ze składnią: df.rename(columns={mapping}) gdzie mapowanie odnosi się do mapowania starych nazw kolumn na nowe. Możesz także użyć metody rename(), określając funkcję, która ma być zastosowana do wszystkich nazw kolumn: df.rename(wywołanie funkcji lub metody, oś=’kolumny’).
- W taki sam sposób, w jaki używasz metody replace() na łańcuchu Pythona, możesz użyć df.columns.str.replace(’old_column_name’, 'new_column_name’) do zastąpienia nazw kolumn.
- Innym podejściem do zmiany nazwy w kolumnach jest użycie metody set_axis ze składnią: df.set_axis(list_of_col_names,axis=’columns’).
To wszystko w tym samouczku! Zapoznaj się z listą notatników do współpracy na potrzeby analizy danych.