
Rozpoznawanie jednostek nazwanych (NER) to świetny sposób na zrozumienie danej informacji tekstowej i identyfikację w niej określonych jednostek lub znaczników dla różnych zastosowań.
Od kategoryzowania nazwisk po wskazywanie dat, organizacji, lokalizacji i nie tylko, NER wypracowuje własny sposób na lepsze zrozumienie języka.
Wiele organizacji ma do czynienia z dużą ilością danych w postaci treści, danych osobowych, opinii klientów, szczegółów produktów i wielu innych.
Kiedy potrzebujesz informacji natychmiast, będziesz musiał przeprowadzić operacje wyszukiwania, aby uzyskać wynik, co może pochłonąć dużo czasu, energii i zasobów, szczególnie w przypadku dużych ilości danych.
Aby zapewnić organizacjom skuteczne rozwiązanie do wyszukiwania i znajdowania właściwych danych, NER jest doskonałą opcją.
W tym artykule szczegółowo omówię NER, jego koncepcję matematyczną, różne zastosowania i inne ważne punkty.
Zaczynajmy!
Spis treści:
Co to jest rozpoznawanie nazwanych jednostek?
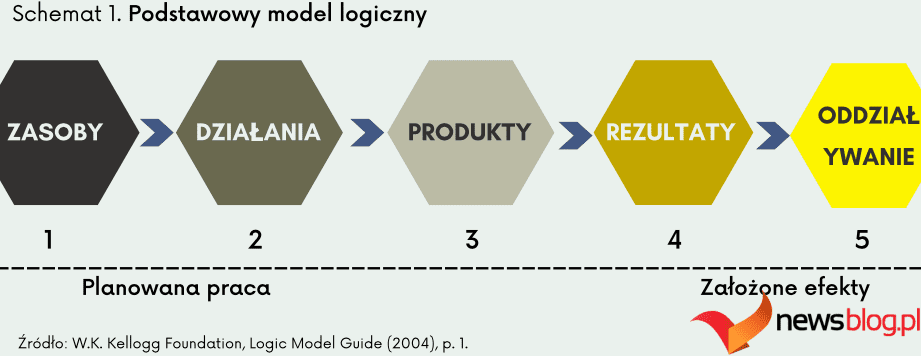
Rozpoznawanie jednostek nazwanych (NER) to metoda przetwarzania języka naturalnego (NLP), która umożliwia identyfikację i klasyfikację jednostek w tekstowych, nieustrukturyzowanych danych.
Podmioty te zawierają szeroki zakres informacji, takich jak organizacje, lokalizacje, nazwiska osób, wartości liczbowe, daty i inne. Umożliwia maszynom wyodrębnianie powyższych elementów, dzięki czemu jest użytecznym narzędziem do zastosowań takich jak tłumaczenia, odpowiadanie na pytania itp. w kilku branżach.
 Źródło: Skaler
Źródło: Skaler
Dlatego NER stara się zlokalizować i kategoryzować różne elementy w nieustrukturyzowanym tekście w predefiniowane grupy, takie jak organizacje, kody medyczne, ilości, nazwiska osób, wartości procentowe, wartości pieniężne, wyrażenia czasu i inne.
Rozumiemy to na przykładzie:
[William] kupił nieruchomość od [Z1 Corp.] W [2023]. Tutaj bloki to podmioty zidentyfikowane przez NER. Są one klasyfikowane jako:
- William – Imię osoby
- Z1 Corp. – Organizacja
- 2003 – Czas
NER jest wykorzystywany w kilku obszarach sztucznej inteligencji, w tym w głębokim uczeniu się, uczeniu maszynowym (ML) i sieciach neuronowych. Jest kluczowym elementem systemów NLP, takich jak narzędzia do analizy nastrojów, wyszukiwarki i chatboty. Ponadto można go stosować w finansach, obsłudze klienta, szkolnictwie wyższym, opiece zdrowotnej, zasobach ludzkich i analizie mediów społecznościowych.
Mówiąc najprościej, NER identyfikuje, klasyfikuje i wydobywa istotne informacje z nieustrukturyzowanego tekstu bez żadnej analizy wykonywanej przez człowieka. Potrafi szybko wyodrębnić kluczowe informacje z dostępnego zestawu dużych danych.
Co więcej, NER dostarcza Twojej organizacji niezbędnych informacji na temat produktów, trendów rynkowych, klientów i konkurencji. Na przykład instytucje opieki zdrowotnej korzystają z NER w celu wyodrębnienia niezbędnych danych medycznych z dokumentacji pacjenta. Wiele firm używa go do sprawdzenia, czy wspomniano o nich w jakichkolwiek publikacjach.
Kluczowe pojęcia: NER

Ważne jest, aby znać podstawowe pojęcia związane z NER. Omówmy kilka kluczowych terminów związanych z NER, które warto znać.
- Nazwana jednostka: dowolne słowo odnoszące się do miejsca, organizacji, osoby lub innego podmiotu.
- Korpus: Zbiór różnych tekstów używanych do analizy języków i uczenia modeli NER.
- Tagowanie POS: proces, podczas którego tekst jest oznaczany zgodnie z odpowiednią wymową, np. przymiotnikami, czasownikami i rzeczownikami.
- Dzielenie na kawałki: Jest to proces stosowany do grupowania słów w różne znaczące frazy w oparciu o strukturę syntaktyczną i część mowy.
- Uczenie i testowanie danych: jest to proces używany do uczenia modelu za pomocą oznaczonych danych i oceny wydajności pierwszego zestawu na innym zestawie danych.
Zastosowanie NER w NLP

NER ma wiele zastosowań w NLP, takich jak analiza nastrojów, systemy rekomendacji, odpowiadanie na pytania, ekstrakcja informacji i inne.
- Analiza nastrojów: NER służy do wykrywania nastrojów wyrażonych w zdaniu lub akapicie wobec określonej nazwanej Podmiotu, takiej jak produkt lub usługa. Dane te służą do poprawy jakości obsługi klienta i identyfikacji obszarów wymagających poprawy.
- Systemy rekomendacji: NER służy do identyfikacji preferencji i zainteresowań użytkowników na podstawie nazwanych podmiotów wymienionych w interakcjach online lub zapytaniach wyszukiwania. Dane te są wykorzystywane w celu poprawy ulepszeń użytkowników poprzez dostarczanie spersonalizowanych rekomendacji.
- Odpowiadanie na pytania: NER służy do wykrywania określonych elementów w tekście, który jest następnie używany do udzielenia odpowiedzi na zapytanie lub konkretne pytanie. Jest to zwykle używane w przypadku wirtualnych asystentów i chatbotów.
- Ekstrakcja informacji: NER służy do wyodrębniania niezbędnych informacji z większego zestawu nieustrukturyzowanego tekstu. Obejmuje to posty w mediach społecznościowych, recenzje online, artykuły prasowe i nie tylko. Dane te służą do generowania cennych spostrzeżeń i podejmowania decyzji w oparciu o dane.
Pojęcia matematyczne: NER
Proces NER obejmuje różne koncepcje matematyczne, takie jak uczenie maszynowe, uczenie głębokie, teoria prawdopodobieństwa i inne. Oto kilka technik matematycznych:
- Ukryte modele Markowa: Ukryte modele Markowa lub HMM to statystyczne podejście do sekwencjonowania zadań klasyfikacyjnych, takich jak NER. Polega na przedstawieniu pewnej sekwencji słów w tekście jako różnych stanów, przy czym każdy stan reprezentuje określoną nazwaną jednostkę. Analizując prawdopodobieństwa, można zidentyfikować wymienione podmioty na podstawie tekstu.
- Głębokie uczenie się: techniki głębokiego uczenia się, takie jak sieci neuronowe, są wykorzystywane w zadaniach NER. Umożliwia to skuteczną i dokładną identyfikację i kategoryzację nazwanych podmiotów.
- Warunkowe pola losowe: należą do modelu graficznego używanego w zadaniach oznaczania sekwencji. Oferują warunkowe modelowanie prawdopodobieństwa każdego znacznika zawierającego sekwencję słów. Pozwala to na identyfikację nazwanych podmiotów w tekście.
Jak działa NER?
 Źródło: Publikacje ACS
Źródło: Publikacje ACS
Rozpoznawanie jednostek nazwanych (NER) działa na zasadzie ekstrakcji informacji. Jego funkcjonowanie jest podzielone na różne kluczowe etapy:
#1. Wstępnie przetwórz tekst
W pierwszym etapie NER polega na przygotowaniu informacji tekstowych do analizy. Zwykle obejmuje zadania takie jak tokenizacja. Tutaj tekst początkowo został podzielony na tokeny, zanim NER zaczął identyfikować podmioty.
Na przykład „Bill Gates założył Microsoft” można podzielić na różne tokeny, takie jak „Bill”, „Gates”, „założony” i „Microsoft”.
#2. Identyfikuj podmioty
Potencjalne nazwane podmioty można wykryć za pomocą metod statystycznych lub reguł językowych. Ten krok obejmuje rozpoznanie wzorców, takich jak określone formaty (daty) lub wielkie litery w nazwiskach („Bill Gates”). Po zakończeniu funkcji wstępnego przetwarzania algorytmy NER skanują tekst w celu zidentyfikowania słów w sekwencjach odpowiadających jednostkom.
#3. Klasyfikuj podmioty
Po zidentyfikowaniu jednostek NER kategoryzuje te rozpoznane jednostki na typy, klasy lub grupy. Typowe kategorie to organizacja, data, lokalizacja, osoba i inne. Osiąga się to za pomocą modeli uczenia maszynowego, które są szkolone na oznakowanych danych.
Na przykład „Bill Gates” zostanie rozpoznany jako „osoba”, a „Microsoft” jako „organizacja”.
#4. Analiza kontekstowa
NER nigdy nie poprzestaje na rozpoznawaniu i klasyfikowaniu podmiotów. Często uwzględnia kontekst, aby zwiększyć dokładność. Na tym etapie uwzględnia się kontekst, w którym pojawiają się jednostki, zapewniając dokładną kategoryzację.
Na przykład „Bill Gates założył firmę Microsoft”. W tym przypadku kontekst pozwala systemom zidentyfikować „Rachunek” jako imię i nazwisko osoby, a nie rachunek płatniczy.
#5. Przetwarzanie końcowe
Po wstępnej identyfikacji i kategoryzacji konieczna jest obróbka końcowa w celu udoskonalenia wyników końcowych. Obejmuje to rozwiązywanie niejasności, korzystanie z baz wiedzy, łączenie jednostek zawierających wiele tokenów i nie tylko w celu ulepszania danych jednostek.
Niesamowitą częścią NER jest to, że potrafi interpretować i rozumieć nieustrukturyzowany tekst, który zawiera dane potrzebne Twojej firmie. Otrzymuje istotną część danych z artykułów prasowych, stron internetowych, artykułów naukowych, postów w mediach społecznościowych i nie tylko.
Rozpoznając i kategoryzując nazwane byty, NER dodaje dodatkową warstwę znaczenia i struktury do krajobrazu tekstowego.
Metody NER

Najczęściej stosowane metody są następujące:
#1. Metoda oparta na nadzorowanym uczeniu maszynowym
Ta metoda wykorzystuje modele uczenia maszynowego, które są trenowane na tekstach, które są wstępnie oznaczone przez ludzi etykietami nazwanych kategorii jednostek.
Podejście to wykorzystuje algorytmy, w tym maksymalną entropię i warunkowe pola losowe, w celu uzyskania złożonych modeli języka statystycznego. Jest skuteczny w rozwiązywaniu znaczeń językowych i innych złożoności, ale do wykonania tej operacji wymaga dużej ilości danych szkoleniowych.
#2. Systemy oparte na regułach
Metoda ta wykorzystuje różne zasady gromadzenia informacji. Obejmuje tytuły lub wielkie litery, takie jak „Er”. W tej metodzie konieczna jest duża interwencja człowieka, aby zapewnić wkład, monitorować i zmieniać zasady. W tej metodzie mogą zostać pominięte różnice tekstowe, które nie są uwzględnione w adnotacjach szkoleniowych. Dlatego systemy oparte na regułach nie są w stanie poradzić sobie ze złożonością i modelami uczenia maszynowego.
#3. Systemy oparte na słownikach
W tej metodzie do identyfikacji i sprawdzania tożsamości nazwanych używany jest słownik zawierający dużą liczbę synonimów i zbiór słownictwa. Ta metoda napotyka problemy w kategoryzowaniu nazwanych jednostek, które mają różne różnice w pisowni.
Istnieje również wiele innych pojawiających się metod NER. Omówmy je również:
#4. Nienadzorowane systemy uczenia maszynowego
Te systemy ML korzystają z modeli uczenia maszynowego, które nie są wstępnie przeszkolone na podstawie danych tekstowych. Modele uczenia się bez nadzoru są w stanie lepiej wykonywać złożone zadania niż modele nadzorowane.
#5. Systemy ładowania początkowego
Systemy ładowania początkowego są również znane jako systemy samonadzorowane, które kategoryzują nazwane jednostki w zależności od cech gramatycznych, w tym części znaczników mowy, wielkości liter i innych wstępnie wyszkolonych kategorii.
Następnie człowiek modyfikuje system ładowania początkowego, oznaczając przewidywania systemu jako nieprawidłowe lub poprawne i dodając właściwe do nowego zbioru uczącego.
#6. Systemy sieci neuronowych
Buduje model rozpoznawania nazwanych jednostek przy użyciu modeli uczenia się architektury dwukierunkowej (dwukierunkowe reprezentacje koderów z transformatorów), sieci neuronowych i technik kodowania. Ta metoda minimalizuje interakcję między ludźmi.
#7. Systemy statystyczne
W tej metodzie wykorzystuje się modele probabilistyczne, które uczą się relacji i wzorców tekstowych. Pomaga łatwo przewidzieć nazwane jednostki na podstawie nowych danych tekstowych.
#8. Semantyczne systemy etykietowania ról
System ten wstępnie przetwarza model rozpoznawania nazwanych jednostek, korzystając z technik uczenia się semantycznego, które uczą relacji między kategoriami i kontekstem.
#9. Systemy hybrydowe
Metoda ta jest interesująca i wykorzystuje aspekty kilku podejść w sposób łączny.
Korzyści z NER
Modele NER zapewniają liczne korzyści.
- NER automatyzuje proces ekstrakcji danych w przypadku dużej ilości danych.
- Jest stosowany w każdej branży do wydobywania kluczowych informacji z nieustrukturyzowanego tekstu.
- Może to zaoszczędzić czas Tobie i Twoim pracownikom podczas wykonywania zadań wyodrębniania danych.
- Może zwiększyć dokładność procesów i zadań NLP.
- Zapewnia bezpieczeństwo danych, hostując niestandardowe modele NER, eliminując potrzebę udostępniania poufnych informacji zewnętrznym dostawcom.
- Uwzględnia nowe typy jednostek i terminologię w miarę ewolucji domeny.
Wyzwania NER
- Dwuznaczność: Wiele słów użytych w tekście może wprowadzać w błąd. Na przykład słowo „Amazonka” odnosi się do firmy, rzeki i lasu. Można go rozróżnić na podstawie określonego kontekstu. Dlatego rozpoznawanie jednostek jest nieco trudniejsze.
- Zależność od kontekstu: słowa wywodzące się z otaczającego kontekstu mają różne znaczenia; na przykład „Apple” w tekście technologicznym odnosi się do korporacji, natomiast w otoczeniu odnosi się do owoców. Rozpoznanie dokładnej jednostki nie jest trudne.
- Rzadkość danych: w przypadku metod NER opartych na uczeniu maszynowym dostępność oznakowanych danych jest niezbędna. Jednak wyodrębnienie takich danych, zwłaszcza w przypadku domen specjalistycznych lub mniej popularnych języków, może być trudne.
- Różnice językowe: Języki ludzkie mają różne formy w zależności od ich dialektów, różnic regionalnych i slangu. Dlatego też wyodrębnienie tekstu w języku obcym jest trudne.
- Generalizacja modelu: modele NER mogą przodować w klasyfikowaniu jednostek w jednej domenie, ale mogą mylić uogólnienia w innej domenie. Zatem modele NER mogą zachowywać się inaczej w różnych domenach.
Wyzwaniom tym można sprostać, łącząc zaawansowane algorytmy, wiedzę językową i dane wysokiej jakości. Ponieważ NER ewoluuje, zespoły badawczo-rozwojowe muszą udoskonalić różne techniki, aby sprostać tym wyzwaniom.
Przypadki użycia NER
#1. Kategoryzacja treści

Wydawnictwa i domy informacyjne generują dużą ilość treści online. Dlatego efektywne zarządzanie nimi ma kluczowe znaczenie, aby jak najlepiej wykorzystać artykuł lub wiadomość.
Funkcja rozpoznawania nazw automatycznie skanuje całą zawartość i wyodrębnia dane, takie jak organizacje, miejsca i nazwiska osób użyte w treści. Znajomość niezbędnych tagów dla każdego artykułu pomaga kategoryzować artykuły w określonej hierarchii, usprawniając dostarczanie treści.
#2. Szukaj algorytmów
Załóżmy, że masz wewnętrzny algorytm wyszukiwania dla swojego wydawcy internetowego, który zawiera miliony artykułów. Dla każdego zapytania Twój wewnętrzny algorytm wyszukiwania zbiera wszystkie słowa z tych artykułów. Jest to proces czasochłonny.
Teraz, jeśli użyjesz NER dla swojego wydawcy internetowego, z łatwością pobierze on niezbędne elementy ze wszystkich artykułów i zapisze je osobno. Przyspieszy to proces wyszukiwania.
#3. Zalecenia dotyczące treści
Automatyzacja procesu rekomendacji jest głównym przypadkiem użycia NER. Systemy rekomendacji pomagają w odkrywaniu nowych pomysłów i treści.
Najlepszym tego przykładem jest Netflix. To dowód na to, że zbudowanie skutecznego systemu rekomendacji pomoże Ci stać się bardziej uzależniającym i angażującym wydarzeniem.
W przypadku wydawców wiadomości NER skutecznie poleca podobne artykuły. Można to zrobić, zbierając tagi z konkretnego artykułu i polecając inne treści zawierające podobne elementy.
#4. Obsługa klienta

Dla każdej organizacji obsługa klienta jest sprawą najważniejszą. Dlatego istnieje wiele sposobów, aby funkcja obsługi opinii klientów przebiegała sprawnie. NER jest jednym z nich. Rozumiemy to na przykładzie.
Załóżmy, że klient przekazuje informację zwrotną: „Personelowi outletu Adidas w San Diego brakuje bardziej szczegółowych informacji na temat obuwia sportowego”. Tutaj NER wyciąga metki „San Diego” (lokalizacja) i „obuwie sportowe” (produkt).
Zatem NER służy do klasyfikowania każdej skargi i przesyłania jej do odpowiedniego działu w organizacji w celu rozwiązania problemu. Możesz stworzyć bazę danych składającą się z opinii podzielonych na różne działy i analizować każdą opinię.
#5. Artykuły badawcze
Publikacja internetowa lub strona internetowa czasopisma zawiera wiele artykułów naukowych i prac badawczych. Można znaleźć setki artykułów o podobnej tematyce z niewielkimi modyfikacjami. Zatem uporządkowanie wszystkich tych danych w uporządkowany sposób może być skomplikowanym zadaniem.
Aby pominąć długi proces, możesz posegregować te dokumenty na podstawie odpowiednich tagów.
Istnieją na przykład tysiące artykułów na temat uczenia maszynowego. Aby znaleźć ten, który wspomniał o użyciu splotowych sieci neuronowych (CNN), musisz umieścić na nich encje. Pomoże Ci to szybko znaleźć artykuł zgodnie z Twoimi wymaganiami.
Wniosek
Technika NLP, rozpoznawanie nazwanych podmiotów (NER), pomaga w identyfikacji nazwanych podmiotów w nieustrukturyzowanym tekście i kategoryzacji tych podmiotów na predefiniowane grupy, takie jak lokalizacje, nazwiska osób, produkty i inne.
Podstawowym celem NER jest zebranie ustrukturyzowanych informacji z nieustrukturyzowanego tekstu i przedstawienie ich w czytelnym formacie. Obejmuje różne modele i procesy i przynosi wiele korzyści profesjonalistom i przedsiębiorstwom. Jest również używany do różnych zastosowań poza NLP.
Mam nadzieję, że rozumiesz powyższe wyjaśnienia dotyczące tej techniki, aby móc wdrożyć ją w swojej firmie i uzyskać na czas istotne, cenne informacje.
Możesz także zapoznać się z najlepszymi kursami NLP, aby nauczyć się przetwarzania języka naturalnego