

Przygotuj się, aby dowiedzieć się wszystkiego o przyszłości baz danych nowej generacji, tj. bezserwerowych bazach danych!
Każda baza danych zgodna z podstawowymi zasadami przetwarzania bezserwerowego jest bezserwerową bazą danych. Bezserwerowa baza danych została stworzona z myślą o obciążeniach, które są nieprzewidywalne i mogą się szybko zmieniać.
Bezserwerowy nie oznacza, że serwery nie są potrzebne. Oznacza to, że serwery bazowe nie muszą być zarządzane, udostępniane ani opłacane przez użytkownika.
Płacisz za zasoby, z których korzystasz, na podstawie ich pojemności procesora i pamięci RAM oraz ich aktywności.
Spis treści:
Jak działa bezserwerowa baza danych
Model bezserwerowej bazy danych opiera się na rozdzieleniu przetwarzania i przechowywania. Musisz utworzyć punkt końcowy i ustawić minimalną i maksymalną wydajność.
Źródło obrazu: Simform
Następnie możesz wysyłać zapytania do punktu końcowego. Ten serwer proxy działa jako łącze do dużej liczby zasobów bazy danych. Dzięki temu Twoje połączenia pozostają nienaruszone, nawet operacje skalowania odbywają się za kulisami.
Oddzielenie przechowywania od przetwarzania ma jeszcze jedną zaletę. Możliwe jest skalowanie do zera przetwarzania, a płacisz tylko za przechowywanie. Skalowanie można wykonać w zaledwie 5 sekund, w zależności od zastosowania. Masz również dostęp do puli „ciepłych” zasobów gotowych, aby pomóc Ci w zaspokojeniu Twoich potrzeb.
Bezserwerowa baza danych: zalety

Efektywność kosztowa
Stała liczba serwerów jest droższa niż bezserwerowa baza danych, a jej zakup zajmuje więcej czasu. Może to być tańsze niż skonfigurowanie grupy skalowania automatycznego, a także bardziej opłacalne, ponieważ upakowanie zasobów maszynowych do kosza zwiększa ich wydajność.
Obejmuje to licencjonowanie, instalację, konserwację, wsparcie i instalowanie poprawek. Opłata jest naliczana tylko za czas i pamięć używaną do uruchomienia kodu.
Zautomatyzowana skalowalność
Deweloperzy nie muszą konfigurować ani konfigurować żadnych zasad ani systemów automatycznego skalowania, aby uzyskać skalowanie bezserwerowe na podstawie obciążenia. To wszystko spada na barki dostawcy chmury, który musi sprostać rzeczywistym wymaganiom z odpowiednimi mocami wykonawczymi.
Szybkie wdrożenia i aktualizacje
Infrastruktura bezserwerowa eliminuje konieczność przesyłania kodu na serwery i konfigurowania ustawień zaplecza w celu stworzenia działającej aplikacji. Deweloperom łatwo jest przesłać małe fragmenty kodu, a następnie wypuścić nowy produkt. Deweloperzy mogą przesyłać jednocześnie oba kody i jedną funkcję w danym momencie.
Ułatwia to szybkie aktualizowanie, łatanie, naprawianie lub dodawanie nowych funkcji do aplikacji. Deweloperzy mogą wprowadzać niewielkie zmiany w aplikacji zamiast aktualizować całą aplikację.
Wyższa produktywność
Wydobędziesz więcej ze swojego systemu bezserwerowego, jeśli poświęcisz mu mniej czasu, włożysz mniej wysiłku w obszary, w których wymagana jest interakcja, i zatrudnisz zespół profesjonalistów o optymalnej wielkości, aby osiągnąć lepsze wyniki.
Bezserwerowa baza danych: wady
Problemy z zimnym startem
Obsługa zimnego rozruchu jest jednym z najważniejszych i najtrudniejszych aspektów w tej dziedzinie. Bezserwerowa baza danych, która nie jest używana, po prostu przejdzie w stan bezczynności, aby oszczędzać zasoby i zapobiegać niepotrzebnej wydajności.
System „budzi się” i potrzebuje czasu na ponowne uruchomienie wszystkich swoich procesów. Opóźnienia i długi czas reakcji mogą wystąpić, jeśli jesteś pierwszą osobą, która dotyka systemu podczas jego zimnego startu.
Trudności w testowaniu i debugowaniu aplikacji
Model bezserwerowy stanowi kolejne wyzwanie. Trudno jest replikować środowisko bezserwerowe w celu testowania i monitorowania wydajności kodu przed jego uruchomieniem. Wynika to częściowo z faktu, że programiści nie mają dostępu do usług zaplecza dostawcy chmury.
Aby dogłębnie i wydajnie debugować złożone systemy, nie można używać profilera ani debuggera. Masz możliwość wypróbowania narzędzi innych firm, które są coraz częściej dostępne na rynku.
Więcej monitoringu
Rozwiązania bezserwerowe wymagają położenia większego nacisku na monitorowanie i sygnalizowanie problemów z wydajnością lub nadmiernego wykorzystania zasobów. Wynika to w dużej mierze z faktu, że rozwiązania chmurowe rzadko są open-source.
Blokada dostawcy
Podczas migracji do innego dostawcy wybór modelu bezserwerowego może powodować problemy. Wynika to z faktu, że każdy dostawca ma inny przepływ pracy i funkcje.
Funkcje bezserwerowej bazy danych
Bezserwerowe bazy danych oferują jedne z najbardziej ekscytujących funkcji, takie jak:
# 1. Architektura wielu dzierżawców
Bezserwerowe bazy danych oferują tę zaletę, że mogą korzystać z jednego zasobu puli, który można wykorzystać w wielu projektach w organizacji. Jest to duży plus dla programistów, ponieważ nie muszą tworzyć odizolowanych źródeł danych specyficznych dla aplikacji.
Umożliwia to architektura wielodostępna. Deweloperzy mogą instalować, konfigurować i wdrażać wiele aplikacji w jednym klastrze bazy danych.
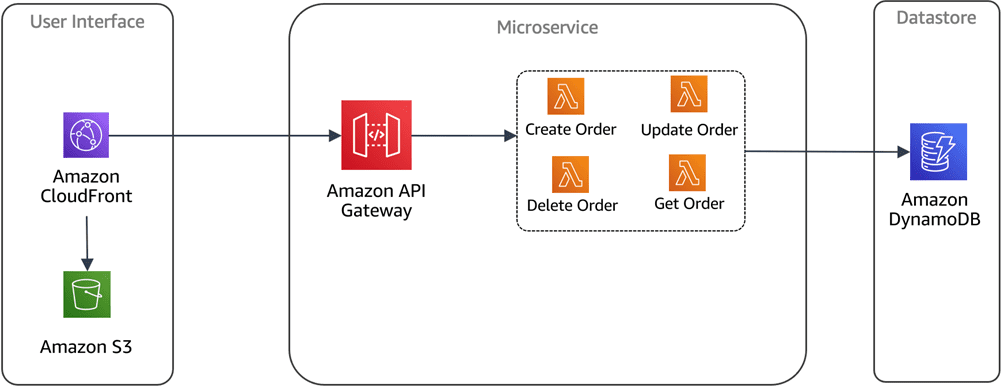 Źródło obrazu: AWS
Źródło obrazu: AWS
#2. Dystrybucja geograficzna
Ponieważ większość firm działa na skalę globalną, ważne jest, aby dane były dostępne na całym świecie. Doświadczenia w czasie rzeczywistym można poprawić dzięki bliskości centrów danych. Eliminowany jest również punkt awarii, więc możliwość wystąpienia awarii jest bardzo mało prawdopodobna.
Bezserwerowe bazy danych umożliwiają replikację wielu zestawów danych na całym świecie bez żadnych dodatkowych narzędzi ani niestandardowego programowania.
#3. Niewielka lub żadna ręczna administracja serwerem
Serverless to błędne określenie. Jest to zbiór serwerów, które zostały wyabstrahowane i zautomatyzowane, aby ułatwić zarządzanie nimi. Wszystkie zadania ręczne, takie jak udostępnianie, planowanie pojemności, skalowanie, konserwacja, aktualizacje itd., nadal są wykonywane w tle. Są bardzo łatwe w użyciu i wymagają niewielkiej lub żadnej interwencji ręcznej.
#4. Rozliczenia oparte na zużyciu
Bezserwerowa baza danych, ponieważ jej opłaty są oparte na użyciu, jest najbardziej opłacalna. Przechowywanie nie jest wymagane. Płacisz tylko za to, z czego korzystasz. Jeśli chcesz uniknąć przekroczenia budżetu, możesz ustawić limit wydatków.
Relacyjne a nierelacyjne bezserwerowe bazy danych

Dane ery cyfrowej można podzielić na operacyjne i analityczne. Przyjrzyjmy się kilku różnym opcjom baz danych, do których sięgają programiści, i zobaczmy, jak się one porównują.
Większość firm wymaga systemów OLTP (operacyjnych) i OLAP (analitycznych) do przechowywania danych. Mogą używać relacyjnej lub nierelacyjnej bazy danych do obsługi swoich potrzeb biznesowych.
Relacyjna bezserwerowa baza danych
Relacyjna baza danych to typ bazy danych, który organizuje i gromadzi dane zgodnie z predefiniowanymi relacjami między kluczowymi punktami danych. Organizuje dane, dzięki czemu wielu użytkowników może wyszukiwać i sortować dane bez zmiany logicznej kategoryzacji danych.
Eliminuje powielanie danych w procesach przechowywania. Structured Query Language to interfejs programu aplikacji (API) dla relacyjnego banku danych.
System ten prezentuje dane w formie tabelarycznej. Ta tabela reprezentuje encję, taką jak produkt lub aplikacja mobilna. Każdy wiersz to rzeczywista wartość, a każdy wiersz ma unikalny identyfikator, który jest instancją tego typu encji. Dlatego nazywa się rekordy.
Z drugiej strony kolumny przechowują atrybuty danych. Stanowią rzeczywistą wartość podmiotu. Dostęp do danych jest możliwy bez konieczności reorganizacji tabeli bazy danych.
Bezserwerowa baza danych NoSQL (nierelacyjna).
Nierelacyjne bazy danych (NoSQL) są częściej dystrybuowane niż bazy danych SQL. Może być używany z dużą liczbą baz danych. Przedsiębiorstwa muszą korzystać z nowoczesnych możliwości, takich jak bazy danych NoSQL, aby tworzyć aplikacje natywne w chmurze.
Bezserwerowe bazy danych NoSQL są używane w aplikacjach internetowych czasu rzeczywistego. Są proste w konstrukcji i mogą szybko obsługiwać duże ilości danych ze skalowaniem poziomym. Jest to idealne rozwiązanie w sytuacjach, w których schemat jest niejasny i mogą być wymagane wysokie współczynniki pozyskiwania.
Bezserwerowe bazy danych NoSQL są bardzo popularne, ponieważ przechowują duże ilości danych w wielu formach, w tym wykresy, dokumenty, pary klucz/wartość i struktury danych zorientowane na kolumny. Ułatwia to programistom modyfikowanie struktury danych.
Dlaczego warto korzystać z bezserwerowych baz danych?
Bezserwerowe bazy danych to świetna opcja dla małych zespołów, które nie mają wystarczającej liczby pracowników do zarządzania i skalowania tradycyjnych baz danych. Bezserwerowe bazy danych wymagają niewielkiej infrastruktury i konserwacji. Oznacza to, że Twój zespół będzie musiał poświęcić mniej czasu na konserwację systemu. Łatwo jest również tworzyć nowe tabele i testować nowe funkcje przy użyciu bezserwerowej bazy danych.
Wreszcie koszty. Bezserwerowe bazy danych pozwalają płacić tylko za to, czego używasz, bez konieczności konfigurowania i dostosowywania kosztów, jak w przypadku tradycyjnych baz danych. Bezserwerowe bazy danych są świetne dla programistów i zespołów, które muszą szybko wprowadzać nowe funkcje.
Przypadki użycia bezserwerowej bazy danych

# 1. Nowe aplikacje
Kilka minut użytkowania w ciągu tygodnia lub dnia. Jeśli posiadasz bloga o małym ruchu i chcesz płacić tylko za czas, w którym dowolny użytkownik uzyskuje dostęp do Twojej witryny, jest to opcja. Płacisz za każdą sekundę używanych zasobów bazy danych.
#2. Elastyczna zmiana rozmiaru do transmisji wideo na żywo
Transmisja wideo na żywo jest możliwa dzięki architekturze bezserwerowej. Wielu odbiorców może wchodzić w interakcje w scenariuszach transmisji wideo na żywo. Host może być podłączony do wielu mikrofonów jednocześnie. Gospodarz może połączyć kilku widzów lub znajomych z ekranem, a następnie zsyntetyzować obraz w jeden scenariusz, który jest prezentowany widzom transmisji na żywo.
#3. Rzadko używane aplikacje
Jeśli masz aplikację, z której jesteś dumny i nie wiesz, jak zostanie odebrana, a nie chcesz, aby aplikacja zawiodła, ta metoda jest dla Ciebie. Po prostu utwórz punkt końcowy, a bezserwerowa baza danych zostanie automatycznie przeskalowana do potrzeb Twojej aplikacji.
#4. Internet rzeczy (IoT)
Internet rzeczy można opisać jako termin opisujący urządzenia znajdujące się w dzisiejszych domach, które mogą łączyć się z Internetem w celu wykonywania różnych funkcji. FaaS jest coraz częściej wykorzystywany przez te urządzenia do wykonywania swoich zadań. Wysyłają i odbierają dane tylko wtedy, gdy wyzwala je zdarzenie.
Firmy oszczędzają pieniądze, nie musząc dodatkowo płacić za moc obliczeniową, której nie używają. FaaS umożliwia szybkie i automatyczne skalowanie, dzięki czemu programiści nie muszą martwić się o nieprzewidywalne wzorce użytkowania.
Wniosek
Te scenariusze pokazują, że architektura bezserwerowa ma wiele zalet dla programistów i firm. Bezserwerowe bazy danych mogą poprawić szybkość przetwarzania i odporność, jednocześnie skracając czas i koszt skalowania i zasobów. Istnieje wiele rodzajów bezserwerowych baz danych, zarówno relacyjnych, jak i nierelacyjnych. Jednak wszystkie mają ten sam cel: skalować na żądanie bez dodawania obciążeń związanych z zarządzaniem i redukować koszty tylko o