

Protokół sieciowy to zestaw reguł używanych przez urządzenia do komunikowania się ze sobą w sieci.
Przypomina to sposób, w jaki ludzie zachowują się i przestrzegają pewnych procedur, rozmawiając ze sobą.
Określają takie rzeczy, jak struktura pakietów danych, sposób identyfikacji urządzeń oraz sposób obsługi błędów i konfliktów.
Protokoły sieciowe można podzielić na trzy główne typy: komunikacja, bezpieczeństwo i zarządzanie.
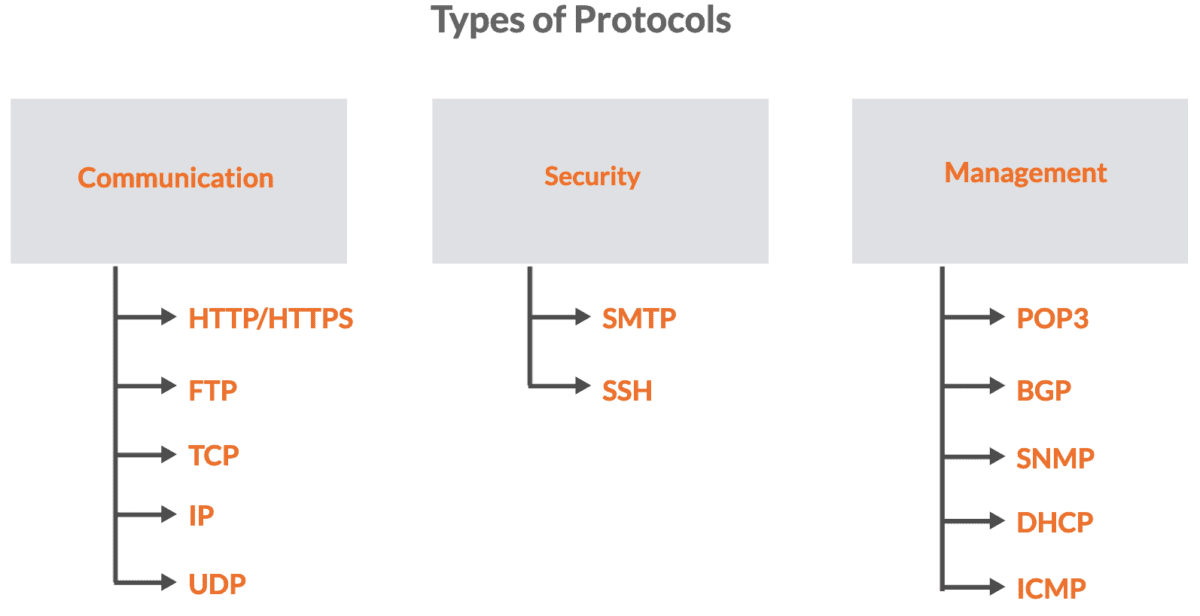
Spis treści:
#1. Protokoły komunikacyjne
Protokoły te skupiają się na umożliwieniu wymiany danych i informacji pomiędzy urządzeniami w sieci. Określają sposób formatowania, przesyłania i odbierania danych, co zapewnia efektywną komunikację. Przykładami są HTTP/HTTPS, FTP, TCP i UDP.
#2. Protokoły bezpieczeństwa
Protokoły bezpieczeństwa mają na celu ochronę poufności i autentyczności danych przesyłanych przez sieć. Tworzą bezpieczne kanały komunikacji i pilnują, aby wrażliwe informacje nie były podatne na przechwycenie lub manipulację.
Przykłady obejmują SSL/TLS do szyfrowania, SSH do bezpiecznego dostępu zdalnego i bezpieczne warianty protokołów e-mail, takie jak SMTPS i POP3S.
#3. Protokoły zarządzania
Protokoły zarządzania służą do administrowania, monitorowania i kontrolowania urządzeń/zasobów sieciowych. Pomagają administratorom sieci efektywnie konfigurować i rozwiązywać problemy ze składnikami sieci.
Przykładami są DHCP do dynamicznego przydzielania adresów IP, SNMP do zarządzania urządzeniami sieciowymi, ICMP do celów diagnostycznych oraz BGP do informacji o routingu i osiągalności.
Omówmy kilka typowych protokołów z każdej kategorii.
Protokoły komunikacyjne
HTTP
HTTP oznacza protokół przesyłania hipertekstu.
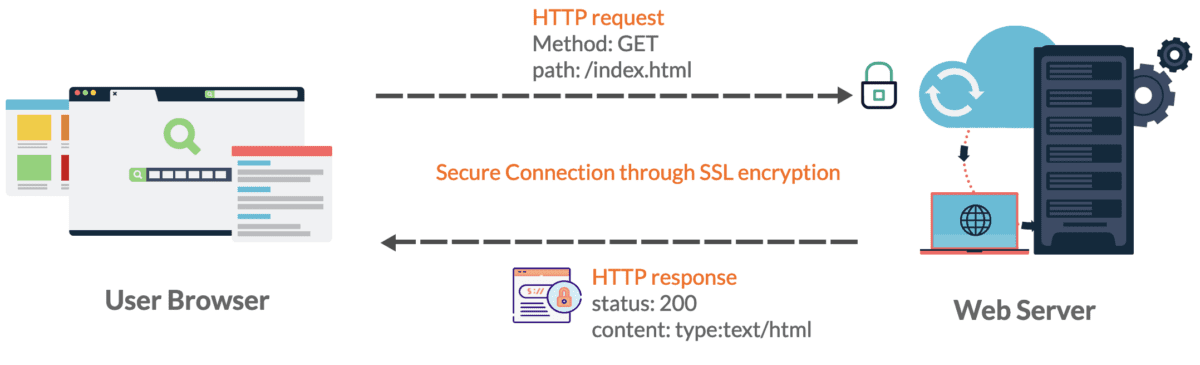
Jest to podstawowy protokół używany do komunikacji pomiędzy przeglądarką internetową a serwerem.
Jest to protokół warstwy aplikacji, który działa w oparciu o model OSI.
Po wprowadzeniu adresu URL w przeglądarce internetowej i naciśnięciu klawisza Enter wysyła ona żądanie HTTP do serwera internetowego, który następnie przetwarza żądanie i odsyła odpowiedź HTTP zawierającą żądane informacje.
Może to być strona internetowa, obraz, film lub dowolny inny zasób hostowany na serwerze.

HTTP jest protokołem bezstanowym. Oznacza to, że każde żądanie od klienta do serwera jest traktowane jako niezależna i izolowana transakcja.
Serwer nie przechowuje żadnych informacji o poprzednich żądaniach tego samego klienta. Ta prostota jest jednym z powodów, dla których protokół HTTP jest tak powszechnie stosowany.
HTTP definiuje kilka metod żądania, w tym GET (pobranie danych), POST (wysłanie danych do przetworzenia), PUT (aktualizacja zasobu), DELETE (usunięcie zasobu) i inne. Metody te określają typ operacji, którą klient chce wykonać na serwerze.
Ogólnie rzecz biorąc, odpowiedzi HTTP zawierają kod stanu wskazujący wynik żądania.
Na przykład – kod stanu 200 oznacza pomyślne żądanie, a 404 oznacza, że nie znaleziono żądanego zasobu.
Na przestrzeni lat protokół HTTP miał kilka wersji, przy czym HTTP/1.1 jest jedną z najczęściej używanych wersji od długiego czasu.
HTTP/2 i HTTP/3 (znane również jako QUIC) zostały opracowane w celu poprawy wydajności.
HTTPS
HTTPS oznacza bezpieczny protokół przesyłania hipertekstu.
Jest rozszerzeniem protokołu HTTP używanego do bezpiecznej komunikacji w sieciach komputerowych.
Dodaje warstwę bezpieczeństwa do standardowego protokołu HTTP, szyfrując dane wymieniane między przeglądarką a serwerem internetowym przy użyciu protokołów kryptograficznych, takich jak SSL/TLS. Nawet jeśli ktoś przechwyci przesyłane dane, nie będzie mógł ich łatwo odczytać ani rozszyfrować.
HTTPS obejmuje formę uwierzytelniania serwera.
Gdy przeglądarka łączy się z witryną internetową za pośrednictwem protokołu HTTPS, witryna prezentuje certyfikat cyfrowy wystawiony przez zaufany urząd certyfikacji (CA).
Certyfikat ten weryfikuje tożsamość strony internetowej, co daje pewność, że klient łączy się z zamierzonym serwerem, a nie złośliwym.
Strony internetowe korzystające z protokołu HTTPS są identyfikowane za pomocą „https://” na początku adresu URL. Użycie tego przedrostka wskazuje, że witryna korzysta z bezpiecznego połączenia.
HTTPS zazwyczaj używa portu 443 do komunikacji, podczas gdy HTTP używa portu 80. Dzięki temu rozróżnieniu serwery internetowe mogą łatwo rozróżnić połączenia bezpieczne i niezabezpieczone.
Wyszukiwarki takie jak Google priorytetowo traktują witryny korzystające z protokołu HTTPS w swoich rankingach wyszukiwania.
Przeglądarki mogą także ostrzegać użytkowników, gdy bezpieczna strona internetowa HTTPS zawiera elementy (obrazy lub skrypty) udostępniane przez niezabezpieczone połączenie HTTP. Nazywa się to „treścią mieszaną” i może zagrozić bezpieczeństwu.
Tutaj znajdziesz szczegółowy artykuł o tym, jak uzyskać certyfikat SSL dla strony internetowej. Zapraszamy do odwiedzenia tej strony.
FTP
File Transfer Protocol (FTP) to standardowy protokół sieciowy używany do przesyłania plików pomiędzy klientem a serwerem w sieci komputerowej.
FTP działa w modelu klient-serwer. Oznacza to, że klient inicjuje połączenie z innym komputerem (serwerem), aby zażądać i przesłać pliki.
FTP wykorzystuje do komunikacji dwa porty i może działać w dwóch trybach: trybie aktywnym i trybie pasywnym.
Port 21 jest używany do połączenia sterującego, podczas którego przesyłane są polecenia i odpowiedzi między klientem a serwerem.
Tryb aktywny to tryb tradycyjny, działający na zasadzie modelu klient-serwer. Tutaj otwierany jest dodatkowy port (zwykle z zakresu 1024-65535) do przesyłania danych.
Z drugiej strony tryb pasywny jest często używany, gdy klient znajduje się za zaporą sieciową lub urządzeniem NAT, a serwer otwiera losowy port o wysokim numerze do przesyłania danych.
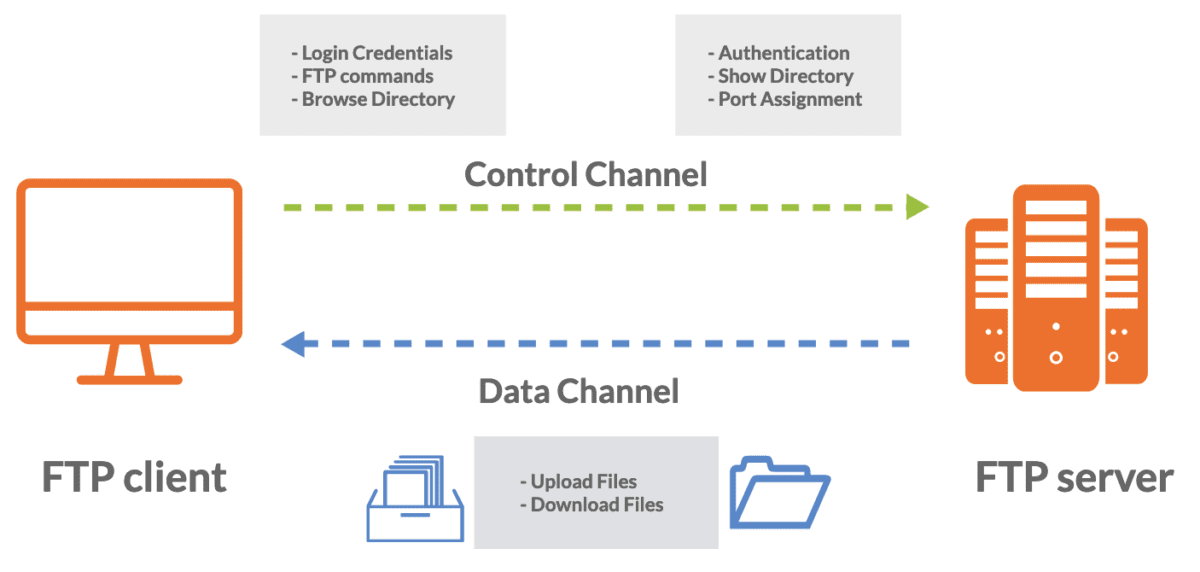
FTP zazwyczaj wymaga uwierzytelnienia w celu uzyskania dostępu do plików na serwerze. Aby się zalogować, użytkownicy muszą podać nazwę użytkownika i hasło.
Niektóre serwery FTP obsługują również dostęp anonimowy. Dzięki temu użytkownicy mogą logować się przy użyciu ogólnej nazwy użytkownika, takiej jak „anonimowy” lub „FTP”, i używać swojego adresu e-mail jako hasła.
FTP obsługuje dwa tryby przesyłania danych: tryb ASCII i tryb binarny.
Tryb ASCII jest używany w przypadku plików tekstowych, a tryb binarny jest używany w przypadku plików nietekstowych, takich jak obrazy i pliki wykonywalne. Tryb jest ustawiany w oparciu o typ przesyłanego pliku.
Tradycyjny FTP nie jest bezpiecznym protokołem, ponieważ przesyła dane, w tym nazwy użytkowników i hasła, w postaci zwykłego tekstu.
Bezpieczny FTP (SFTP) i FTP przez SSL/TLS (FTPS) to bezpieczniejsze alternatywy, które szyfrują transfer danych w celu ochrony poufnych informacji.
Oto szczegółowy artykuł na temat protokołu SFTP i FTPS oraz protokołu, którego należy użyć.
TCP
Protokół kontroli transmisji (TCP) to jeden z głównych protokołów warstwy transportowej w pakiecie IP.
Odgrywa główną rolę w zapewnieniu niezawodnej i uporządkowanej transmisji danych pomiędzy urządzeniami w sieciach IP.
Protokół TCP ustanawia połączenie pomiędzy nadawcą i odbiorcą przed rozpoczęciem przesyłania danych. Ta konfiguracja połączenia obejmuje trójstronne uzgadnianie (SYN, SYN-ACK, ACK) i proces zakończenia połączenia po zakończeniu wymiany danych.
Obsługuje także komunikację w trybie pełnego dupleksu, która umożliwia jednoczesne wysyłanie i odbieranie danych w obu kierunkach w ramach ustanowionego połączenia.
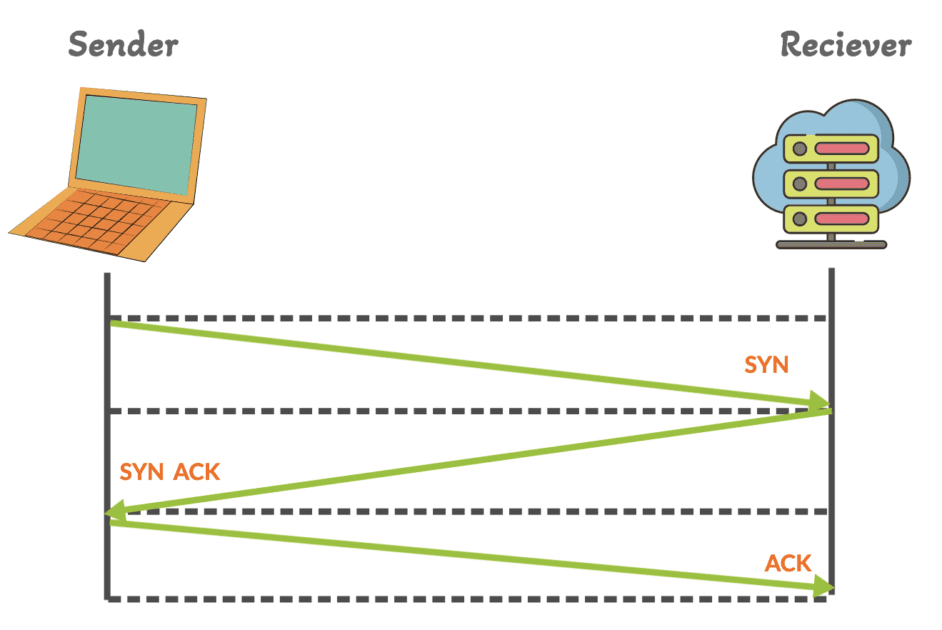
Ogólnie rzecz biorąc, protokół TCP monitoruje warunki sieciowe i dostosowuje szybkość transmisji, aby uniknąć przeciążenia sieci.
Protokół ten zawiera mechanizmy sprawdzania błędów w celu wykrywania i korygowania uszkodzeń danych podczas transmisji. Jeżeli okaże się, że segment danych jest uszkodzony, odbiorca żąda retransmisji.
Protokół TCP wykorzystuje numery portów do identyfikowania określonych usług lub aplikacji na urządzeniu. Numery portów pomagają kierować przychodzące dane do właściwej aplikacji.
Odbiornik w połączeniu TCP wysyła potwierdzenia (ACK) w celu potwierdzenia odbioru segmentów danych. Jeżeli nadawca nie otrzyma potwierdzenia w określonym czasie – retransmituje segment danych.
TCP przechowuje informacje o stanie połączenia zarówno po stronie nadawcy, jak i odbiorcy. Informacje te pomagają śledzić sekwencję segmentów danych i zarządzać połączeniem.
IP
IP oznacza protokół internetowy.
Jest to podstawowy protokół umożliwiający komunikację i wymianę danych w sieciach komputerowych, w tym w sieci globalnej, którą nazywamy Internetem.
IP wykorzystuje numeryczny system adresowania do identyfikacji urządzeń w sieci. Te adresy numeryczne nazywane są adresami IP i mogą to być adresy IPv4 lub IPv6.
Adresy IPv4 mają zazwyczaj postać czterech zestawów liczb dziesiętnych (np. 192.168.1.1), natomiast adresy IPv6 są dłuższe i korzystają z zapisu szesnastkowego.
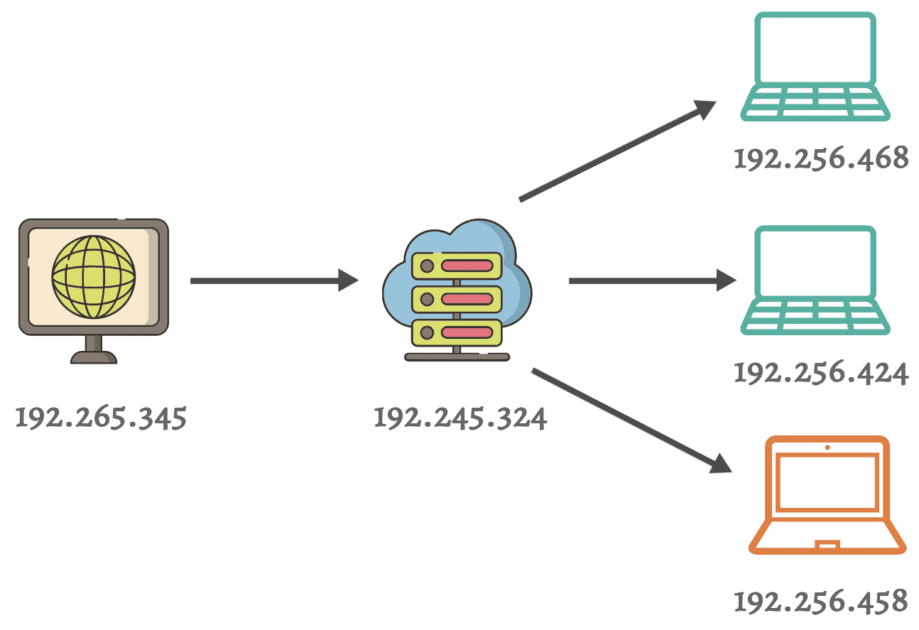
IP kieruje pakiety danych pomiędzy urządzeniami w różnych sieciach.
Routery i przełączniki odgrywają główną rolę w kierowaniu tych pakietów do zamierzonych miejsc docelowych na podstawie ich adresów IP.
Ogólnie rzecz biorąc, protokół IP wykorzystuje metodologię przełączania pakietów. Oznacza to, że dane są dzielone na mniejsze pakiety w celu transmisji w sieci. Każdy pakiet zawiera źródłowy i docelowy adres IP, który umożliwia routerom podejmowanie decyzji o przekazywaniu dalej.
IP jest uważany za protokół bezpołączeniowy. Nie ustanawia dedykowanego połączenia pomiędzy nadawcą i odbiorcą przed przesłaniem danych.
Każdy pakiet jest traktowany niezależnie i może dotrzeć do miejsca przeznaczenia różnymi drogami.
UDP
UDP oznacza protokół datagramów użytkownika.
Jest to bezpołączeniowy i lekki protokół, który umożliwia przesyłanie danych przez sieć bez ustanawiania formalnego połączenia.
W przeciwieństwie do protokołu TCP, UDP nie nawiązuje połączenia przed wysłaniem danych. Po prostu pakuje dane w datagramy i wysyła je do miejsca docelowego.
Nie gwarantuje dostarczenia danych i nie implementuje mechanizmów wykrywania i korygowania błędów. Jeśli pakiet zostanie utracony lub dotrze w nieodpowiedniej kolejności, zadaniem warstwy aplikacji będzie sobie z tym poradzić.
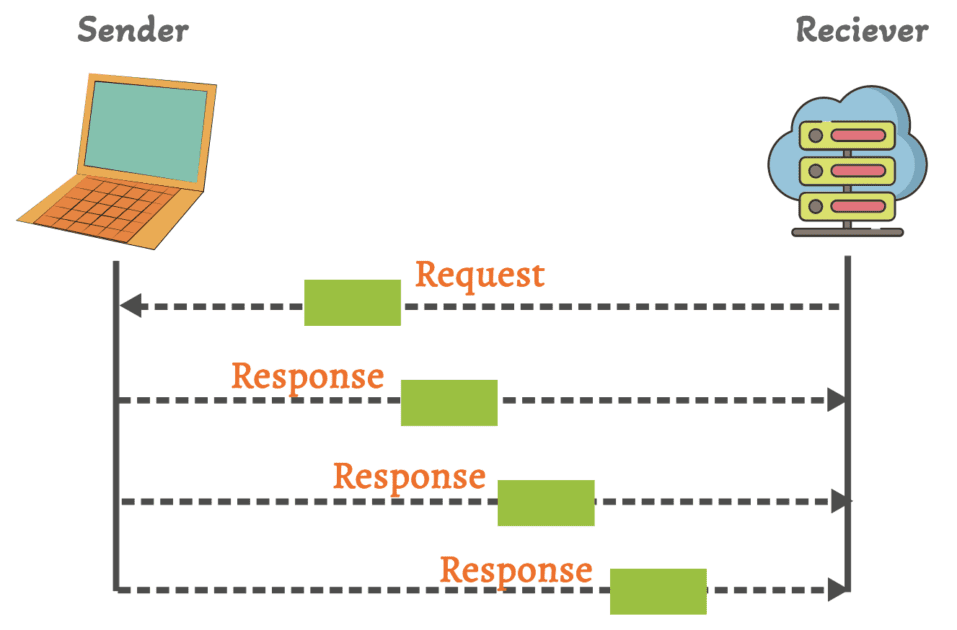
UDP ma mniejsze obciążenie niż TCP, ponieważ nie zawiera takich funkcji jak kontrola przepływu, korekcja błędów czy potwierdzenia. Dzięki temu jest szybszy, ale mniej niezawodny.
Nie ma również wbudowanych mechanizmów kontroli przeciążenia, więc możliwe jest zalewanie sieci ruchem UDP, co potencjalnie powoduje przeciążenie.
Protokół UDP jest powszechnie stosowany w sytuacjach, gdy małe opóźnienia i duża prędkość transmisji danych są ważniejsze niż gwarantowana dostawa. Typowymi przykładami są strumieniowe przesyłanie dźwięku i wideo w czasie rzeczywistym, gry online, DNS i niektóre aplikacje IoT.
Najlepszą rzeczą w UDP jest funkcja multipleksowania. Umożliwia wielu aplikacjom na tym samym urządzeniu korzystanie z tego samego portu UDP, co różnicuje strumienie danych na podstawie numerów portów.
zrozummy UDP na prostym przykładzie.
Wyobraź sobie, że chcesz wysłać wiadomość do znajomego po hałaśliwym placu zabaw, używając odbijającej się piłki. Decydujesz się na użycie UDP, co przypomina rzucenie piłki bez formalnej rozmowy. Oto jak to działa:
- Piszesz wiadomość na kartce papieru i owijasz ją wokół piłki.
- Rzucasz piłkę w stronę swojego przyjaciela. Nie czekasz, aż przyjaciel to złapie lub potwierdzi, że to otrzymał; po prostu go rzucasz i masz nadzieję, że go złapią.
- Piłka odbija się i dociera do Twojego przyjaciela, który próbuje ją złapać. Czasami jednak z powodu hałasu może wypaść z rąk lub przybyć nieprawidłowo.
- Twój przyjaciel czyta wiadomość na papierze i jeśli udało mu się złapać piłkę – otrzymuje wiadomość. Jeśli nie, mogą to przegapić i nie będziesz wiedział, ponieważ nie miałeś jak sprawdzić.
Zatem w tym przykładzie:
Kulka reprezentuje protokół UDP, który przesyła dane bez ustanawiania formalnego połączenia.
Wysyłanie piłki bez czekania na odpowiedź jest jak brak połączenia UDP i brak zapewnienia dostawy.
Możliwość odbicia się lub zgubienia piłki symbolizuje brak niezawodności w UDP.
Twój znajomy czytający wiadomość jest jak warstwa aplikacji obsługująca dane otrzymane przez UDP, która prawdopodobnie radzi sobie z brakującymi danymi.
Protokoły bezpieczeństwa
SSH
SSH oznacza Secure Shell.
Jest to protokół sieciowy używany do bezpiecznej komunikacji pomiędzy klientem a serwerem za pośrednictwem niezabezpieczonej sieci. Zapewnia sposób zdalnego dostępu i zarządzania urządzeniami za pośrednictwem interfejsu wiersza poleceń przy wysokim poziomie bezpieczeństwa.
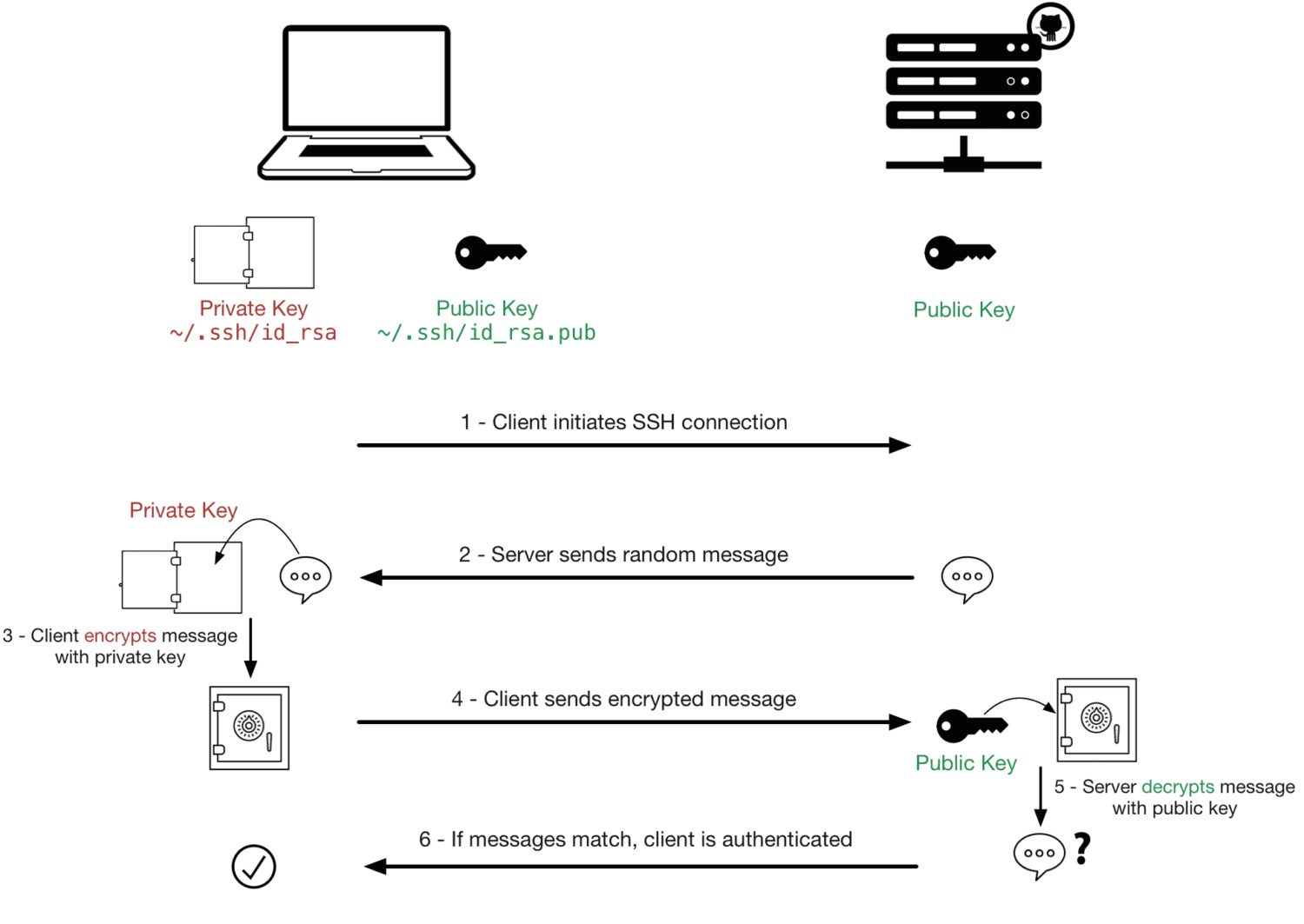
SSH wykorzystuje techniki kryptograficzne do uwierzytelniania zarówno klienta, jak i serwera. Dzięki temu masz pewność, że łączysz się z właściwym serwerem i że serwer może zweryfikować Twoją tożsamość przed zezwoleniem na dostęp.
Wszystkie dane przesyłane przez połączenie SSH są szyfrowane, co utrudnia osobie przechwytującej komunikację podsłuchanie wymienianych danych.
 Źródło obrazu: Przepełnienie stosu
Źródło obrazu: Przepełnienie stosu
SSH używa pary kluczy do uwierzytelnienia. Para kluczy składa się z klucza publicznego (współdzielonego z serwerem) i klucza prywatnego (który utrzymujesz w tajemnicy).
Oto artykuł o tym, jak to działa – Logowanie bez hasła SSH
Kiedy łączysz się z serwerem SSH, Twój klient używa Twojego klucza prywatnego, aby potwierdzić Twoją tożsamość.
Oprócz tego obsługuje również tradycyjne uwierzytelnianie za pomocą nazwy użytkownika i hasła. Jest to jednak mniej bezpieczne i często odradzane, szczególnie w przypadku serwerów połączonych z Internetem.
SSH domyślnie używa do komunikacji portu 22 – ale ze względów bezpieczeństwa można to zmienić. Zmiana numeru portu może pomóc w ograniczeniu automatycznych ataków.
SSH jest powszechnie używany do zdalnego administrowania serwerem, przesyłania plików (za pomocą narzędzi takich jak SCP i SFTP) oraz bezpiecznego dostępu do zdalnych interfejsów wiersza poleceń.
Jest szeroko stosowany w administrowaniu systemami operacyjnymi typu Unix i jest również dostępny w systemie Windows za pośrednictwem różnych rozwiązań programowych.
SMTP
SMTP oznacza prosty protokół przesyłania poczty.
Jest to standardowy protokół odpowiedzialny za wysyłanie wychodzących wiadomości e-mail od klienta lub serwera poczty e-mail do serwera poczty e-mail po stronie odbiorcy.
SMTP to podstawowa część komunikacji e-mail, która współpracuje z innymi protokołami poczty e-mail, takimi jak IMAP/POP3, umożliwiając pełny cykl życia wiadomości e-mail, w tym wysyłanie, odbieranie i przechowywanie wiadomości e-mail.
Kiedy tworzysz wiadomość e-mail i klikasz „wyślij” w swoim kliencie poczty e-mail, wykorzystuje on protokół SMTP do przekazania wiadomości na serwer Twojego dostawcy poczty e-mail.
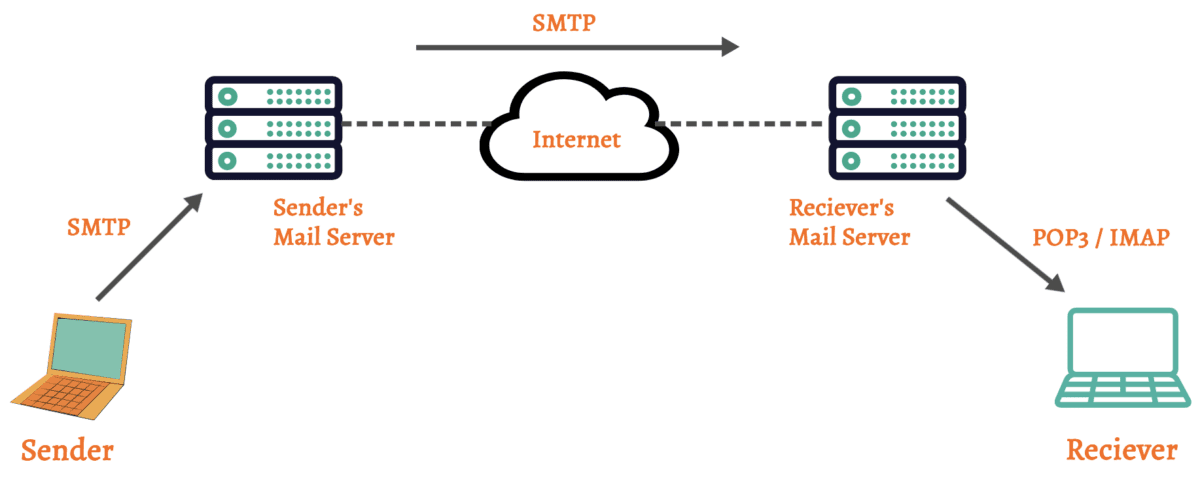
Używa portu 25 do komunikacji nieszyfrowanej i portu 587 do komunikacji szyfrowanej (przy użyciu STARTTLS). Port 465 był również używany do szyfrowanej komunikacji SMTP, ale jest mniej powszechny.
Wiele serwerów SMTP wymaga uwierzytelniania przy wysyłaniu wiadomości e-mail, aby zapobiec nieautoryzowanemu użyciu. Stosowane są metody uwierzytelniania, takie jak nazwa użytkownika i hasło, lub bezpieczniejsze metody, takie jak OAuth.
Te serwery SMTP są często używane jako przekaźniki, co oznacza, że akceptują wychodzące wiadomości e-mail od klientów (np. Twojej aplikacji pocztowej) i przekazują je na serwer poczty e-mail odbiorcy. Pomaga to w kierowaniu wiadomości e-mail przez Internet.
Komunikację można zabezpieczyć za pomocą szyfrowania TLS lub SSL – szczególnie w przypadku przesyłania wrażliwych lub poufnych informacji pocztą elektroniczną.
Protokoły zarządzania
POP3
POP3 oznacza protokół pocztowy w wersji 3.
Jest to jeden z najpopularniejszych protokołów pobierania wiadomości e-mail używanych do pobierania wiadomości e-mail z serwera pocztowego do aplikacji klienta poczty e-mail.
POP3 został zaprojektowany do pracy w trybie „przechowaj i przekaż”. Pobiera wiadomości e-mail z serwera, a następnie zazwyczaj usuwa je z serwera po zapisaniu kopii na urządzeniu klienta.
Niektóre programy poczty e-mail umożliwiają pozostawienie kopii wiadomości e-mail na serwerze — nie jest to jednak zachowanie domyślne.
Do komunikacji nieszyfrowanej wykorzystuje port 110. Port 995 jest powszechnie używany do bezpiecznej komunikacji POP3 przy użyciu protokołu TLS/SSL.
POP3 jest protokołem bezstanowym. Oznacza to, że nie śledzi wiadomości e-mail, które już pobrałeś. Za każdym razem, gdy łączysz się z serwerem, pobiera on wszystkie nieprzeczytane wiadomości. Może to prowadzić do problemów z synchronizacją, jeśli uzyskujesz dostęp do poczty e-mail z wielu urządzeń.
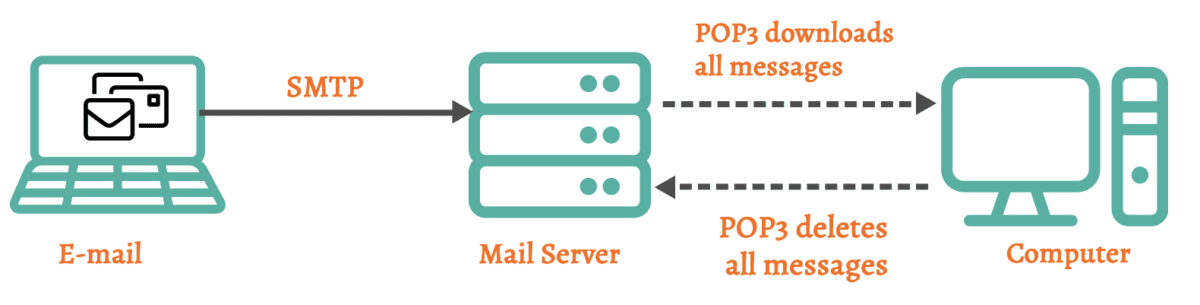
POP3 jest przeznaczony przede wszystkim do pobierania wiadomości e-mail ze skrzynki odbiorczej. Może nie obsługiwać pobierania wiadomości e-mail z innych folderów na serwerze, takich jak wysłane elementy lub wersje robocze.
Ponieważ POP3 nie synchronizuje folderów e-mail między serwerem a klientem – działania podjęte na jednym urządzeniu (np. usunięcie wiadomości e-mail) nie będą odzwierciedlone na innych urządzeniach.
Zalecane jest używanie bezpiecznej wersji POP3 (POP3S lub POP3 over SSL/TLS), która szyfruje komunikację pomiędzy klientem pocztowym a serwerem w celu zwiększenia bezpieczeństwa.
POP3 jest obecnie rzadziej używany w porównaniu do protokołu IMAP (Internet Message Access Protocol). Zapewnia bardziej zaawansowane funkcje, takie jak synchronizacja folderów, i pozwala wielu urządzeniom skuteczniej zarządzać tą samą skrzynką pocztową.
BGP
BGP oznacza protokół Border Gateway.
Jest to ustandaryzowany protokół bramy zewnętrznej używany w sieciach do wymiany informacji o routingu i osiągalności pomiędzy systemami autonomicznymi (AS).
System autonomiczny to zbiór sieci IP i routerów znajdujących się pod kontrolą jednej organizacji, która prezentuje wspólną politykę routingu do Internetu.
BGP to protokół wektora ścieżki. Oznacza to, że śledzi ścieżkę (listę systemów autonomicznych), którą pakiety danych pokonują, aby dotrzeć do miejsca docelowego. Informacje te pomagają routerom BGP podejmować decyzje dotyczące routingu w oparciu o zasady i atrybuty ścieżki.
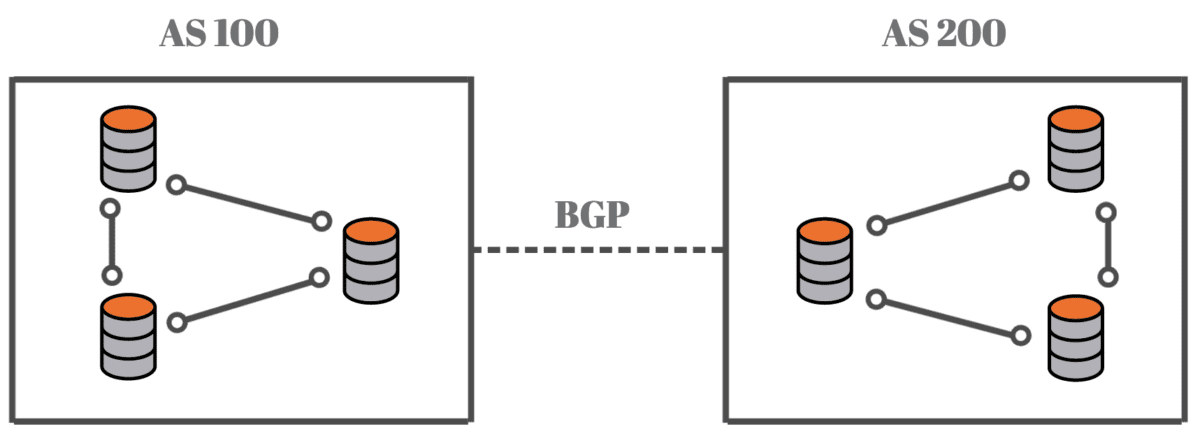
Służy przede wszystkim do określenia najlepszej ścieżki przesyłania danych podczas przechodzenia przez wiele sieci obsługiwanych przez różne organizacje lub dostawców usług internetowych.
Obsługuje także agregację tras, która pomaga zmniejszyć rozmiar globalnej tabeli routingu poprzez podsumowanie wielu prefiksów IP w jednym ogłoszeniu trasy.
Protokół BGP wykorzystuje różne mechanizmy zapobiegające pętlom routingu, w tym użycie atrybutu ścieżki AS i podział na horyzoncie reguła.
Wykorzystywany jest zarówno w publicznym Internecie, jak i sieciach prywatnych.
W publicznym Internecie służy do wymiany informacji o routingu pomiędzy dostawcami usług internetowych a dużymi sieciami. W sieciach prywatnych służy do routingu wewnętrznego i łączenia się z Internetem za pośrednictwem routera granicznego.
DHCP
DHCP oznacza protokół dynamicznej konfiguracji hosta.
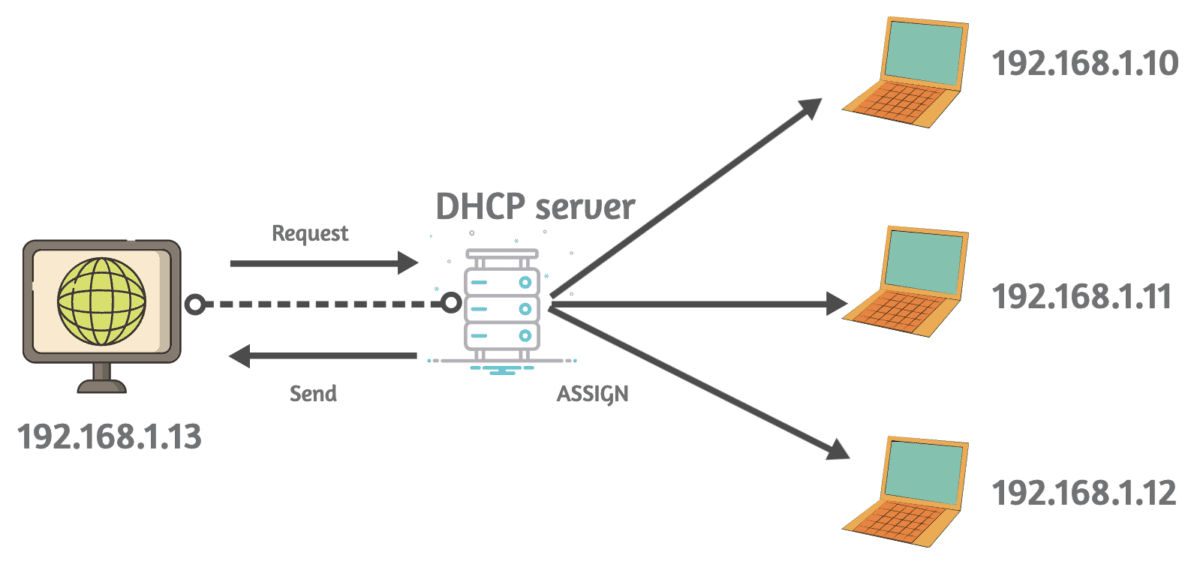
Służy do automatycznego przypisywania adresów IP i innych ustawień konfiguracji sieci do urządzeń w sieci TCP/IP.
Proces DHCP zazwyczaj obejmuje cztery główne etapy:
Wykrywanie DHCP
Gdy urządzenie przyłącza się do sieci, wysyła komunikat rozgłoszeniowy DHCP Discover w celu znalezienia dostępnych serwerów DHCP.
Oferta DHCP
Serwery DHCP w sieci odpowiadają na komunikat DHCP Discover, wysyłając ofertę DHCP. Każdy serwer zapewnia adres IP i powiązane opcje konfiguracji.
Żądanie DHCP
Urządzenie wybiera jedną z ofert DHCP i wysyła komunikat żądania DHCP do wybranego serwera, który żąda oferowanego adresu IP.
Potwierdzenie DHCP
Serwer DHCP potwierdza żądanie wysyłając wiadomość DHCP Acknowledgement, która potwierdza przypisanie adresu IP.
Rozumiemy zasadę działania DHCP na prostym przykładzie.
Wyobraź sobie, że masz domową sieć Wi-Fi i chcesz, aby Twoje urządzenia (takie jak telefony i laptopy) łączyły się z nią bez konieczności ręcznego konfigurowania ustawień sieciowych każdego urządzenia. I tu z pomocą przychodzi DHCP:
- Załóżmy, że Twój smartfon właśnie dołączył do Twojej domowej sieci Wi-Fi.
- Smartfon wysyła wiadomość o treści: „Hej, jestem tu nowy. Czy ktoś może mi podać adres IP i inne szczegóły sieci?”
- Twój router Wi-Fi działający jako serwer DHCP słyszy żądanie. Mówi: „Jasne, mam dostępny adres IP, a oto inne potrzebne ustawienia sieciowe – takie jak maska podsieci, brama domyślna i serwer DNS”.
- Smartfon otrzymuje te informacje i automatycznie konfiguruje się przy użyciu podanego adresu IP i ustawień sieciowych.
Smartfon jest teraz gotowy do korzystania z Internetu i komunikowania się z innymi urządzeniami w sieci domowej.
ICMP
Internet Control Message Protocol (ICMP) to protokół warstwy sieciowej używany w pakiecie IP w celu umożliwienia komunikacji i przekazywania informacji zwrotnych na temat stanu operacji sieciowych.
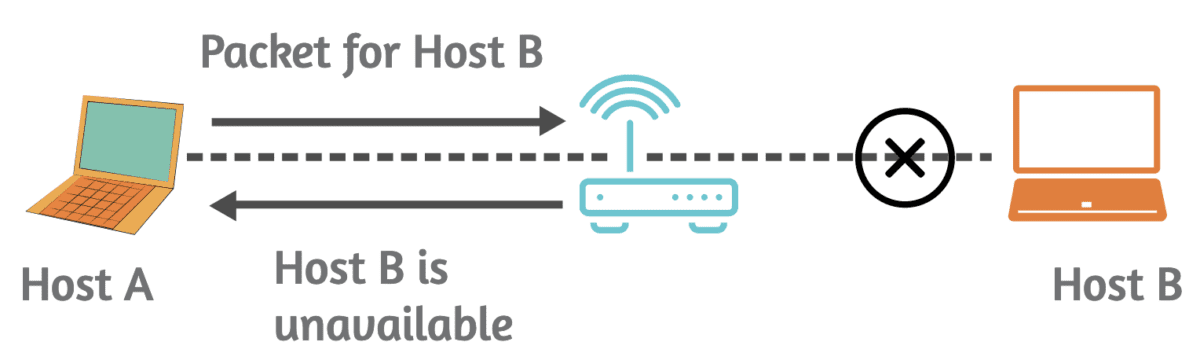
ICMP jest używany głównie do raportowania błędów i dostarczania informacji diagnostycznych związanych z przetwarzaniem pakietów IP.
Na przykład, jeśli router napotka problem podczas przekazywania pakietu IP – generuje komunikat o błędzie ICMP i odsyła go do źródła pakietu.
Typowe komunikaty o błędach ICMP to „Miejsce docelowe nieosiągalne”, „Przekroczono czas” i „Problem z parametrami”.
Jednym z najbardziej znanych zastosowań protokołu ICMP jest polecenie „ping” (używane do sprawdzania dostępności hosta).
To polecenie ping wysyła komunikaty żądania echa ICMP do hosta docelowego i jeśli host jest osiągalny, powinien odpowiedzieć komunikatem odpowiedzi echa ICMP. Jest to prosty sposób przetestowania łączności sieciowej.
ICMP jest również używany do wykrywania maksymalnej jednostki transmisji ścieżki (PMTU). PMTU to maksymalny rozmiar pakietu IP, który może zostać przesłany wzdłuż ścieżki bez fragmentacji.
Komunikaty ICMP takie jak „Wymagana fragmentacja” i „Pakiet za duży” służą do określenia odpowiedniego MTU dla danej ścieżki, co pozwala uniknąć fragmentacji i zoptymalizować transfer danych.
Komunikatów tych można także używać do śledzenia czasu potrzebnego na podróż pakietów od źródła do miejsca docelowego i z powrotem. W tym celu wykorzystywany jest komunikat „Przekroczono czas”.
SNMP
SNMP oznacza prosty protokół zarządzania siecią.
Jest to protokół warstwy aplikacji służący do zarządzania i monitorowania urządzeń/systemów sieciowych.
SNMP działa w oparciu o model menedżer-agent. Istnieją dwa główne elementy.
Menedżer SNMP
Menedżer jest odpowiedzialny za składanie żądań i zbieranie informacji od agentów SNMP. Może także ustawiać parametry konfiguracyjne agentów.
Agent SNMP
Agent to moduł oprogramowania lub proces działający na urządzeniach sieciowych. Przechowuje informacje o konfiguracji i wydajności urządzenia. Agent odpowiada na żądania menedżerów SNMP.
MIB (Management Information Base) to hierarchiczna baza danych, która definiuje strukturę i organizację zarządzanych obiektów na urządzeniu sieciowym. Służy jako punkt odniesienia zarówno dla menedżerów SNMP, jak i agentów, co zapewnia wzajemne zrozumienie danych.
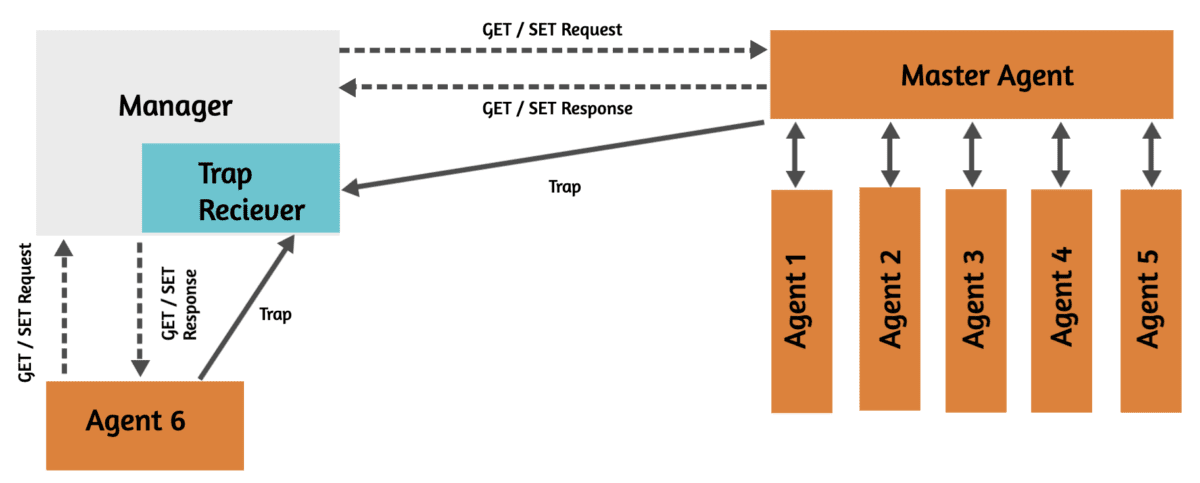
Istnieją trzy wersje protokołu SNMP, które są szeroko stosowane.
SNMPv1: Oryginalna wersja protokołu SNMP, która wykorzystuje ciągi znaków społeczności do uwierzytelniania. Brakuje mu funkcji bezpieczeństwa i jest uważany za mniej bezpieczny.
SNMPv2c: Ulepszenie w stosunku do SNMPv1 z obsługą dodatkowych typów danych i lepszą obsługą błędów.
SNMPv3: Najbezpieczniejsza wersja protokołu SNMP oferująca szyfrowanie, uwierzytelnianie i kontrolę dostępu. Rozwiązuje wiele problemów związanych z bezpieczeństwem wcześniejszych wersji.
Protokół SNMP jest używany do różnych zadań związanych z zarządzaniem siecią, takich jak monitorowanie wykorzystania przepustowości, śledzenie czasu pracy urządzeń, zdalna konfiguracja urządzeń sieciowych i odbieranie alertów w przypadku wystąpienia określonych zdarzeń (np. awarii systemu lub przekroczenia progów).
Wniosek✍️
Mam nadzieję, że ten artykuł był dla Ciebie bardzo przydatny w zdobywaniu wiedzy o różnych protokołach sieciowych. Być może zainteresuje Cię także wiedza na temat segmentacji sieci i sposobów jej wdrożenia.