Wyjaśnione w 5 minut lub mniej
Współczesne przedsiębiorstwa opierają swoje działanie na danych, które stanowią fundament ich rozwoju i sukcesu. Umożliwiają one dogłębną analizę, podejmowanie strategicznych decyzji oraz optymalizację procesów.
Każda firma, niezależnie od wielkości, na co dzień korzysta z różnorodnych baz danych i aplikacji. Co jednak w sytuacji, gdy jeden z tych kluczowych systemów ulegnie awarii?
W takim przypadku istnieje realne zagrożenie utraty ważnych informacji i danych biznesowych, co może mieć poważne konsekwencje dla działalności firmy.
Na szczęście istnieją skuteczne metody zapobiegania takim sytuacjom. Jedną z najefektywniejszych technik ochrony danych jest replikacja baz danych, którą powinna wdrożyć każda firma, aby utrzymać konkurencyjność na rynku.
W niniejszym artykule przybliżymy, czym jest replikacja danych, jak działa oraz jakie są jej kluczowe aspekty.
Zacznijmy zatem!
Czym jest replikacja bazy danych?
Replikacja bazy danych to proces przesyłania danych z jednej, źródłowej bazy danych do jednej lub wielu baz docelowych. Najczęściej polega to na kopiowaniu lub strumieniowym przesyłaniu danych, tak aby wszyscy użytkownicy mieli dostęp do aktualnych i zsynchronizowanych informacji, niezależnie od systemu, z którego korzystają.
Gdy dane w bazie źródłowej ulegną zmianie, system replikacji automatycznie wprowadzi te same zmiany w bazach docelowych. W efekcie powstaje rozproszona sieć przechowywania danych o wysokiej dostępności, umożliwiająca szybki dostęp do istotnych informacji z wielu lokalizacji.
Wdrożenie skutecznego rozwiązania do replikacji danych prowadzi do poprawy spójności danych w każdym węźle, redukcji redundancji, zwiększenia niezawodności oraz w ostateczności - wzrostu wydajności.
Replikacja bazy danych może zachodzić w czasie rzeczywistym, gdy zmiany są wprowadzane w bazie źródłowej, lub w ramach zdefiniowanych operacji wsadowych.
Jak działa replikacja danych?
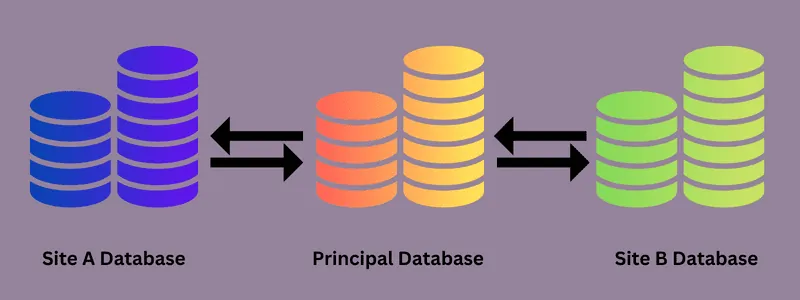
Replikacja bazy danych może być realizowana jako jednorazowy proces lub jako ciągła operacja. Obejmuje wszystkie źródła danych organizacji, a system zarządzania rozproszoną bazą danych (DDBMS) służy do przesyłania danych pomiędzy nimi.
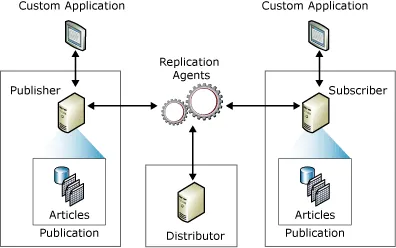
Wszelkie modyfikacje, aktualizacje czy usunięcia danych w bazie źródłowej są automatycznie synchronizowane z bazami docelowymi. Zgodnie z paradygmatem wydawca-subskrybent w procesie replikacji biorą udział co najmniej jeden „wydawca” i co najmniej jeden „subskrybent”.
 Źródło obrazu: Microsoft
Źródło obrazu: Microsoft
„Wydawcą” jest system lub baza danych, w której dokonuje się zmian, a „subskrybentem” jest system, do którego te zmiany są replikowane.
Modyfikacje dokonane w systemie „wydawcy” są następnie odzwierciedlane w bazach danych „subskrybentów”. Użytkownicy mogą również wprowadzać zmiany w bazach subskrybentów, które następnie zostają replikowane do bazy wydawcy i rozpowszechnione do wszystkich subskrybentów w sieci (w systemach dwukierunkowych).
Dodatkowo, większość subskrybentów utrzymuje stałe połączenie z wydawcą, co pozwala na automatyczną aktualizację danych bez konieczności manualnej interwencji. Aktualizacje mogą być wprowadzane partiami w regularnych odstępach czasu lub na bieżąco w czasie rzeczywistym.
Rodzaje replikacji baz danych
Poniżej przedstawiamy najpopularniejsze typy replikacji baz danych:
# 1. Replikacja pełnej tabeli
Replikacja pełnej tabeli tworzy kopię całej źródłowej bazy danych w docelowym miejscu przechowywania. Obejmuje ona wszystkie wiersze, zarówno nowe, zmodyfikowane, jak i te, które istniały już wcześniej.
Jednak takie podejście jest kosztowne z powodu wysokich wymagań dotyczących mocy obliczeniowej i przepustowości sieci, niezbędnych do skopiowania całej bazy. Może to prowadzić do obciążenia sieci i opóźnień w replikacji, szczególnie w przypadku dużych baz danych.
#2. Replikacja migawkowa
Replikacja migawkowa polega na tworzeniu kopii źródłowej bazy danych w określonym momencie. Nie uwzględnia ona bieżących zmian danych, takich jak nowe wiersze, aktualizacje czy usunięcia, a jedynie kopiuje stan bazy w danym czasie.
Ta technika replikacji jest najczęściej stosowana w sytuacjach, gdy zmiany danych są rzadkie. Jest szybsza niż replikacja pełnej tabeli, ale nie śledzi trwale usuniętych danych.

#3. Replikacja scalająca
Replikacja scalająca polega na przesyłaniu i dystrybucji obiektów bazy danych pomiędzy wieloma bazami z jednoczesną synchronizacją. Jest to proces skomplikowany, ponieważ zarówno subskrybenci, jak i wydawcy mogą modyfikować dane, co często prowadzi do konfliktów wersji.
Agenci scalania działający na serwerach synchronizują wszystkie zmiany i wykonują predefiniowane procedury rozwiązywania konfliktów danych.
#4. Replikacja przyrostowa oparta na kluczach
Replikacja przyrostowa oparta na kluczach analizuje klucze lub indeksy w bazie danych w poszukiwaniu zmian, takich jak wstawienia, usunięcia i aktualizacje. Następnie mechanizm replikacji kopiuje tylko te klucze do bazy repliki, które uległy zmianie od ostatniej aktualizacji. Klucze te to zazwyczaj znaczniki czasu, daty lub liczby całkowite.
Proces replikacji jest szybszy, ponieważ kopiowane są tylko zmienione dane. Wadą tej metody jest brak możliwości trwałego usunięcia danych, ponieważ usunięcie rekordu w bazie podstawowej powoduje jedynie usunięcie wartości klucza.
#5. Replikacja przyrostowa oparta na logach
Ten rodzaj replikacji wykorzystuje binarny plik dziennika bazy danych do duplikowania danych. Plik ten zawiera informacje o wszystkich zmianach wprowadzonych w bazie źródłowej, takich jak aktualizacje, wstawienia i usunięcia. Następnie te same operacje są wykonywane w bazie docelowej.
Jest to jedna z najczęściej stosowanych metod replikacji, ze względu na jej efektywność, szczególnie w przypadku statycznych baz danych. Jest ona również obsługiwana przez większość dostawców baz danych, takich jak Oracle, MongoDB, MySQL i PostgreSQL.
#6. Replikacja transakcyjna
W przypadku wystąpienia nowych danych w bazie źródłowej, replikacja transakcyjna przenosi wszystkie dane z bazy źródłowej do lokalizacji docelowej. Następnie, operacje wykonywane na bazie źródłowej są odtwarzane w replice.
Chociaż jest to efektywna metoda replikacji, najczęściej znajduje zastosowanie w operacjach odczytu i może nie obsługiwać operacji tworzenia, usuwania i aktualizacji.
Dlaczego replikacja bazy danych jest ważna?

Replikacja bazy danych jest ważna z następujących powodów:
Niezawodność i dostępność danych
Replikacja danych znacząco zwiększa ich dostępność. Odgrywa kluczową rolę w przypadku awarii serwera, zapewniając zapasowe kopie bazy danych. Dzięki temu dane są dostępne w wielu lokalizacjach. Dodatkowo, wzrasta niezawodność, ponieważ aktualne dane są bezpiecznie przechowywane na wielu serwerach.
Odzyskiwanie po awarii
Replikacja bazy danych jest nieoceniona w sytuacjach awaryjnych, gdy dochodzi do awarii serwera. Jest to efektywna metoda zarządzania kryzysowego i odzyskiwania, ponieważ dane i ostatnie zmiany są replikowane i przechowywane w innych lokalizacjach, zamiast polegania na pojedynczym serwerze.
Wydajność serwera
Dostęp do danych staje się znacznie szybszy, gdy są one przetwarzane i obsługiwane przez kilka serwerów. Administratorzy mogą również zwolnić zasoby serwera głównego, kierując operacje odczytu do repliki, a na serwerze głównym pozostawiając bardziej wymagające operacje zapisu.
Lepsza wydajność sieci
Przechowywanie wielu kopii danych w różnych lokalizacjach redukuje czas dostępu do danych, ponieważ można je pobrać z miejsca, gdzie jest wykonywana transakcja.
Na przykład użytkownicy w Europie mogą doświadczać opóźnień podczas uzyskiwania dostępu do danych z centrów danych w Australii. W takim przypadku umieszczenie repliki danych blisko użytkownika może skrócić czas dostępu, a jednocześnie zrównoważyć obciążenie sieci.
Poprawiona wydajność systemu testowego

Replikacja bazy danych usprawnia dystrybucję i synchronizację danych w systemach testowych, które wymagają szybkiego dostępu do informacji w celu szybkiego podejmowania decyzji.
Kopia zapasowa bazy danych a replikacja bazy danych
Kopia zapasowa i replikacja bazy danych różnią się pod wieloma względami. Oto kilka z nich:
- Kopie zapasowe wymagają odtworzenia i przywrócenia, zanim będzie można z nich korzystać. Replikacja danych natomiast nie wymaga odtworzenia i można z niej korzystać natychmiast.
- Kopie zapasowe bazy danych to pliki lub foldery z plikami danych bazy i aplikacji, w zależności od protokołów organizacyjnych. Replikacja natomiast, często służy do duplikowania całych wolumenów lub systemów plików, baz danych i aplikacji.
- Zarówno kopia zapasowa, jak i replikacja są metodami ochrony danych. Pierwsza ma na celu redukcję docelowego punktu odzyskiwania (RPO) i zapobieganie utracie danych. Druga ma na celu skrócenie docelowego czasu odzyskiwania (RTO), zapewnienie ciągłości biznesowej i minimalizację przestojów.
- Kopia zapasowa jest tanim sposobem na uniknięcie całkowitej utraty danych. Jest niezbędna do zachowania zgodności i nie gwarantuje ciągłości działania. Replikacja natomiast gwarantuje dostępność aplikacji i procesów biznesowych, nawet po awarii.
- Kopia zapasowa bazy danych służy zgodności i szczegółowemu odzyskiwaniu, np. długoterminowemu przechowywaniu dokumentów firmy. Replikacja skupia się na odzyskiwaniu po awarii, czyli szybkim i łatwym wznowieniu operacji po awarii lub uszkodzeniu.
- Kopia zapasowa jest powszechnie stosowana w firmach, zarówno na serwerach produkcyjnych, jak i komputerach stacjonarnych. Replikacja natomiast jest często stosowana w aplikacjach o znaczeniu krytycznym, które muszą być zawsze dostępne.
Techniki replikacji baz danych

Organizacje mogą replikować dane, stosując różne techniki przenoszenia danych. Różnią się one od typów replikacji opisanych wcześniej.
# 1. Pełna replikacja bazy danych
Pełna replikacja bazy danych polega na replikowaniu całej bazy danych do użytku na różnych serwerach. Zapewnia to najwyższą nadmiarowość i dostępność danych. Globalne przedsiębiorstwa mogą w ten sposób umożliwić użytkownikom w Azji dostęp do tych samych danych, co użytkownikom w Ameryce Północnej, z tą samą szybkością. Jeżeli serwer azjatycki ulegnie awarii, użytkownicy mogą wykorzystać serwery europejskie lub północnoamerykańskie jako kopię zapasową.
Wadą tej techniki jest powolny proces aktualizacji. Trudne jest również zachowanie spójności lokalizacji każdego pliku, co jest istotne w przypadku częstych zmian danych.
#2. Częściowa replikacja bazy danych
Częściowa replikacja bazy danych polega na podziale danych na części i zapisywaniu ich w różnych lokalizacjach, w zależności od istotności każdej z nich.
Z tego typu replikacji korzystają m.in. likwidatorzy ubezpieczeń, doradcy finansowi i specjaliści ds. sprzedaży. Mogą oni przenosić częściowe bazy danych na inne urządzenia lub laptopy i synchronizować je z centralnym serwerem.
Dla analityków bardziej opłacalne może być przechowywanie danych europejskich w Europie, danych australijskich w Australii, itd. Pozwala to na przechowywanie danych blisko konsumentów i jednocześnie zachowanie kompletnego zestawu danych w centrali do zaawansowanej analizy.
Wady replikacji bazy danych

Replikacja danych, mimo że wnosi znaczną wartość, ma również swoje wady:
Wyższe koszty
Replikowanie danych i przechowywanie ich w wielu lokalizacjach wymaga większej przestrzeni dyskowej i zasobów obliczeniowych. To z kolei prowadzi do wyższych kosztów, w tym zakupu i utrzymania dodatkowych urządzeń pamięci masowej, serwerów i infrastruktury sieciowej.
Ograniczenia czasowe
Replikacja danych to złożony proces, który obejmuje kopiowanie danych z jednej lokalizacji do wielu innych i utrzymanie spójności pomiędzy kopiami. Może to być czasochłonne, szczególnie w przypadku organizacji, które muszą replikować duże ilości danych.
Przepustowość łącza
Wraz ze wzrostem ilości replikowanych danych rosną również wymagania dotyczące przepustowości łącza, co może obciążyć sieć.
Niespójne dane
Podczas replikacji danych w środowisku rozproszonym istnieje ryzyko utraty synchronizacji, jeżeli aktualizacje nie są przeprowadzane konsekwentnie we wszystkich replikach. Może to prowadzić do niespójności danych, a rozwiązanie tego problemu może wymagać dodatkowego wysiłku.
Przypadki użycia replikacji bazy danych

Replikacja danych znajduje zastosowanie w wielu sytuacjach, między innymi:
Równoważenie obciążenia
Dzięki replikacji danych na wiele serwerów, obciążenie jest rozkładane między nie, co poprawia ich wydajność. Równoważenie obciążenia zapewnia, że żaden serwer nie zostanie przeciążony, a system pozostanie dostępny i responsywny nawet w okresach wzmożonego ruchu.
Magazyn danych
Magazyn danych to scentralizowane repozytorium do przechowywania dużych ilości danych z wielu źródeł. Replikacja danych z tych źródeł do magazynu danych umożliwia organizacjom analizowanie i raportowanie danych w sposób scentralizowany i uporządkowany.
Wdrożenie międzyregionalne
Replikowanie danych do wielu regionów poprawia dostępność i nadmiarowość. Jeżeli w jednym regionie wystąpi awaria, dostęp do danych będzie nadal możliwy z innego regionu. Ponadto, posiadanie danych w wielu regionach może przyspieszyć dostęp dla użytkowników w różnych częściach świata.
Kopie zapasowe i archiwizacja
Replikacja danych do dodatkowej pamięci masowej pomaga organizacjom w zachowaniu długoterminowych kopii danych. Pozwala to na łatwy dostęp do danych i gwarantuje, że nie zostaną one utracone, nawet w przypadku awarii pamięci podstawowej.
Synchronizacja danych
Replikacja danych pomiędzy różnymi systemami gwarantuje, że dane są synchronizowane, spójne i aktualne w każdym z nich. Jest to istotne w przypadku aplikacji, takich jak e-commerce, gdzie te same dane muszą być dostępne z wielu systemów.
Współpraca wielu lokalizacji
Replikacja danych pomiędzy wieloma lokalizacjami umożliwia organizacjom udostępnianie danych w czasie rzeczywistym, co zwiększa efektywność współpracy i produktywność. Jest to szczególnie przydatne w organizacjach z rozproszonymi zespołami lub firmach, które muszą udostępniać dane partnerom lub klientom.
Zasoby edukacyjne
Poniżej przedstawiamy kilka źródeł, które pomogą Ci lepiej zrozumieć temat replikacji baz danych:
# 1. Replikacja bazy danych autorstwa Bettiny Kemme
Książka ta pomoże Ci zrozumieć mechanizmy kontroli współbieżności i replikacji oraz związane z nimi zagadnienia.
#2. Replikacja bazy danych: kompletny przewodnik
Ta książka pomoże Ci przygotować się na wyzwania związane z replikacją baz danych, wyjaśniając i odpowiadając na kluczowe pytania.
Wniosek
Replikacja danych jest niedocenianą, ale niezwykle ważną strategią w dzisiejszym świecie, gdzie dane odgrywają kluczową rolę. Jeśli prowadzisz firmę, powinieneś rozważyć wdrożenie tej technologii.
Jednak wraz ze wzrostem liczby źródeł i miejsc docelowych, firmy muszą być przygotowane na wyzwania, które się z tym wiążą. Dlatego tak ważna jest niezawodna i skalowalna strategia replikacji danych.
Warto również rozważyć wdrożenie oprogramowania do monitorowania baz danych, aby na bieżąco analizować ich wydajność.
