9 najlepszych platform MLOps do tworzenia i wdrażania modeli uczenia maszynowego
Stworzenie pojedynczego modelu uczenia maszynowego nie jest specjalnie skomplikowane. Prawdziwe wyzwanie pojawia się przy zarządzaniu setkami lub tysiącami modeli, a także przy powtarzaniu istniejących procesów.
W takim natłoku zadań łatwo stracić kontrolę. Sytuacja staje się jeszcze bardziej skomplikowana, gdy pracujesz w zespole, ponieważ musisz śledzić postępy wszystkich członków. Aby zapanować nad chaosem, cały zespół musi trzymać się określonego procesu i skrupulatnie dokumentować swoje działania. To właśnie stanowi istotę MLOps.
Czym jest MLOps?
Źródło: ml-ops.org
Według MLOps.org, operacjonalizacja uczenia maszynowego (Machine Learning Operationalization) ma na celu stworzenie wszechstronnego procesu rozwoju uczenia maszynowego, który obejmuje projektowanie, tworzenie i zarządzanie powtarzalnym, testowalnym i skalowalnym oprogramowaniem opartym na uczeniu maszynowym. W istocie MLOps to adaptacja zasad DevOps do środowiska uczenia maszynowego.
Podobnie jak w DevOps, kluczowym elementem MLOps jest automatyzacja, która ma na celu zminimalizowanie interwencji manualnych i zwiększenie wydajności. Co więcej, tak jak DevOps, MLOps obejmuje zarówno ciągłą integrację (CI), jak i ciągłe dostarczanie (CD). Dodatkowo wprowadza również ciągłe szkolenie (CT). CT polega na ponownym uczeniu modeli na podstawie nowych danych i ich wdrażaniu.
Zatem MLOps to kultura inżynierska, która propaguje metodyczne podejście do rozwoju modeli uczenia maszynowego i automatyzację na różnych etapach tego procesu. Proces ten obejmuje przede wszystkim pozyskiwanie danych, ich analizę, przygotowanie, szkolenie modeli, ocenę, udostępnianie modeli i monitorowanie.
Korzyści z MLOps
Ogólnie rzecz biorąc, zalety stosowania zasad MLOps są analogiczne do korzyści płynących z wdrożenia standardowych procedur operacyjnych. Główne korzyści to:
- Dobrze zdefiniowany proces stanowi mapę drogową wszystkich istotnych kroków niezbędnych w procesie rozwoju modelu. Dzięki temu żadne kluczowe etapy nie zostaną pominięte.
- Identyfikacja i automatyzacja etapów procesu, które można zautomatyzować. Redukuje to ilość powtarzalnej pracy i przyspiesza tempo rozwoju. Dodatkowo eliminuje błędy ludzkie, jednocześnie zmniejszając pracochłonność.
- Łatwiejsza ocena postępu rozwoju modelu, dzięki świadomości, na jakim etapie potoku się on znajduje.
- Lepsza komunikacja w zespołach dzięki wspólnemu językowi opisującemu kroki procesu rozwoju.
- Możliwość wielokrotnego zastosowania procesu do rozwoju wielu modeli, co pozwala efektywnie zarządzać złożonością projektów.
Podsumowując, MLOps odgrywa kluczową rolę w zapewnieniu metodycznego podejścia do tworzenia modeli, które można w maksymalnym stopniu zautomatyzować.
Platformy do budowy potoków
Aby pomóc w implementacji MLOps w Twoich potokach, możesz skorzystać z jednej z wielu dostępnych platform, które tutaj omówimy. Chociaż poszczególne funkcje tych platform mogą się różnić, generalnie pomagają one w realizacji następujących zadań:
- Przechowywanie wszystkich modeli wraz z powiązanymi metadanymi, takimi jak konfiguracje, kod, dokładność i wyniki eksperymentów. Platformy te oferują także kontrolę wersji modeli.
- Przechowywanie metadanych zbiorów danych, w tym danych wykorzystanych do uczenia modeli.
- Monitorowanie modeli w środowisku produkcyjnym w celu wykrywania potencjalnych problemów, takich jak dryf modelu.
- Wdrażanie modeli do produkcji.
- Tworzenie modeli w środowiskach z minimalną lub zerową ilością kodu.
Przyjrzyjmy się teraz najlepszym platformom MLOps.
MLflow

MLflow jest jedną z najpopularniejszych platform do zarządzania cyklem życia uczenia maszynowego. Jest dostępna bezpłatnie jako oprogramowanie open source. Oferuje następujące funkcje:
- śledzenie, które umożliwia rejestrowanie eksperymentów uczenia maszynowego, kodu, danych, konfiguracji i uzyskanych wyników;
- projekty, które umożliwiają spakowanie kodu w formacie łatwym do odtworzenia;
- wdrażanie do deploymentu modeli uczenia maszynowego;
- rejestr do przechowywania wszystkich modeli w centralnym repozytorium.
MLflow integruje się z powszechnie używanymi bibliotekami uczenia maszynowego, takimi jak TensorFlow i PyTorch. Ponadto współpracuje z platformami takimi jak Apache Spark, H20.ai, Google Cloud, Amazon SageMaker, Azure Machine Learning i Databricks. Współpracuje również z różnymi dostawcami usług w chmurze, takimi jak AWS, Google Cloud i Microsoft Azure.
Azure Machine Learning
Azure Machine Learning to rozbudowana platforma uczenia maszynowego. Zarządza różnorodnymi aspektami cyklu życia uczenia maszynowego w potoku MLOps. Do tych zadań zalicza się przygotowywanie danych, tworzenie i trenowanie modeli, ich walidację i wdrażanie, a także zarządzanie i monitorowanie wdrożeń.
Azure Machine Learning umożliwia tworzenie modeli za pomocą preferowanego środowiska IDE i wybranej struktury, np. PyTorch lub TensorFlow.
Platforma integruje się również z ONNX Runtime i Deepspeed, aby zoptymalizować proces treningu i wnioskowania, co przekłada się na wzrost wydajności. Wykorzystuje infrastrukturę sztucznej inteligencji na platformie Microsoft Azure, która łączy procesory graficzne NVIDIA i sieć Mellanox, wspierając tworzenie klastrów uczenia maszynowego. AML umożliwia utworzenie centralnego rejestru do przechowywania i udostępniania modeli oraz zbiorów danych.
Azure Machine Learning łączy się z akcjami Git i GitHub, umożliwiając tworzenie efektywnych przepływów pracy. Platforma obsługuje również konfiguracje hybrydowe i wielochmurowe. Możliwa jest także integracja z innymi usługami platformy Azure, takimi jak Synapse Analytics, Data Lake, Databricks i Security Center.
Google Vertex AI

Google Vertex AI to ujednolicona platforma danych i sztucznej inteligencji. Oferuje narzędzia niezbędne do tworzenia niestandardowych i wstępnie wytrenowanych modeli. Stanowi również kompleksowe rozwiązanie do implementacji MLOps. Dla zwiększenia wygody użytkowania platforma integruje się z BigQuery, Dataproc i Spark, zapewniając swobodny dostęp do danych w trakcie szkolenia.
Oprócz interfejsu API, Google Vertex AI udostępnia środowisko narzędziowe z niską ilością kodu lub bez kodu, dzięki czemu jest dostępne dla użytkowników niebędących programistami, takich jak analitycy biznesowi, analitycy danych i inżynierowie. Interfejs API pozwala programistom zintegrować platformę z istniejącymi systemami.
Google Vertex AI pozwala również na tworzenie generatywnych aplikacji AI przy użyciu Generative AI Studio. Upraszcza to i przyspiesza proces wdrażania i zarządzania infrastrukturą. Kluczowe zastosowania Google Vertex AI obejmują przygotowywanie danych, inżynierię cech, szkolenie i dostrajanie hiperparametrów, udostępnianie modeli, ich dostrajanie i zrozumienie, monitorowanie oraz zarządzanie.
Databricks

Databricks to usługa Data Lakehouse, która umożliwia przygotowywanie i przetwarzanie danych. Za pomocą Databricks można zarządzać całym cyklem życia uczenia maszynowego, od fazy eksperymentowania aż po produkcję.
W praktyce Databricks udostępnia zarządzane MLflow, które oferuje funkcje takie jak rejestrowanie danych w wersji modelu ML, śledzenie eksperymentów, udostępnianie modeli, rejestr modeli i śledzenie metryk. Rejestr modeli służy do przechowywania modeli w celu ich odtworzenia, a rejestr wspomaga śledzenie wersji i etapu cyklu życia, w którym się znajdują.
Wdrożenie modeli za pomocą Databricks jest możliwe za pomocą jednego kliknięcia, co zapewnia dostęp do punktów końcowych interfejsu API REST, które można wykorzystać do prognozowania. Platforma integruje się z istniejącymi, wstępnie wytrenowanymi modelami generatywnymi i dużymi modelami językowymi, takimi jak te z biblioteki Hugging Face Transformers.
Databricks oferuje notebooki Databricks do współpracy, które obsługują języki Python, R, SQL i Scala. Dodatkowo upraszcza zarządzanie infrastrukturą, zapewniając wstępnie skonfigurowane klastry zoptymalizowane pod kątem zadań uczenia maszynowego.
AWS SageMaker
AWS SageMaker to usługa w chmurze AWS, która zapewnia narzędzia niezbędne do opracowywania, trenowania i wdrażania modeli uczenia maszynowego. Głównym celem SageMaker jest zautomatyzowanie żmudnych i powtarzalnych zadań ręcznych związanych z tworzeniem modeli uczenia maszynowego.
W efekcie SageMaker dostarcza narzędzi do budowy potoku produkcyjnego dla modeli uczenia maszynowego, wykorzystując różnorodne usługi AWS, takie jak instancje Amazon EC2 i pamięć masową Amazon S3.
SageMaker współpracuje z Jupyter Notebooks zainstalowanymi w instancji EC2, wraz ze wszystkimi popularnymi pakietami i bibliotekami potrzebnymi do kodowania modelu uczenia maszynowego. Jeśli chodzi o dane, SageMaker może je pobierać z usługi Amazon Simple Storage Service.
Domyślnie użytkownik otrzymuje implementacje typowych algorytmów uczenia maszynowego, takich jak regresja liniowa i klasyfikacja obrazów. SageMaker jest również wyposażony w monitor modelu, który zapewnia ciągłe i automatyczne dostrajanie, w celu znalezienia zestawu parametrów zapewniających najlepszą wydajność modeli. Wdrażanie jest również uproszczone, gdyż model można łatwo wdrożyć w AWS jako bezpieczny punkt końcowy HTTP, który można monitorować za pomocą CloudWatch.
DataRobot
DataRobot to popularna platforma MLOps, która umożliwia zarządzanie różnymi fazami cyklu życia uczenia maszynowego, takimi jak przygotowanie danych, eksperymentowanie z uczeniem maszynowym, walidacja i zarządzanie modelami.
Posiada narzędzia do automatyzacji eksperymentów z wykorzystaniem różnych źródeł danych, testowania tysięcy modeli i oceny najlepszych do wdrożenia w środowisku produkcyjnym. Obsługuje budowanie modeli dla różnych typów AI, rozwiązując problemy z szeregami czasowymi, przetwarzaniem języka naturalnego i wizją komputerową.
Za pomocą DataRobot można budować modele, korzystając z gotowych rozwiązań, dzięki czemu nie ma konieczności pisania kodu. Alternatywnie, użytkownik może wybrać podejście oparte na kodzie i wdrażać modele z wykorzystaniem niestandardowego kodu.
DataRobot oferuje notatniki do pisania i edycji kodu. Alternatywnie, można użyć interfejsu API do tworzenia modeli w preferowanym środowisku IDE. Korzystając z GUI, można śledzić eksperymenty dotyczące modeli.
Run AI

Run AI dąży do rozwiązania problemu niepełnego wykorzystania infrastruktury AI, w szczególności GPU. Problem ten jest rozwiązywany poprzez zwiększenie widoczności całej infrastruktury i upewnienie się, że jest ona w pełni wykorzystywana podczas szkolenia.
Aby to osiągnąć, Run AI znajduje się pomiędzy oprogramowaniem MLOps a sprzętem firmy. Zajmując to miejsce, wszystkie zadania szkoleniowe są uruchamiane za pomocą Run AI. Platforma natomiast planuje uruchomienie każdego z tych zadań.
Nie ma ograniczeń co do tego, czy sprzęt musi być oparty na chmurze, takiej jak AWS i Google Cloud, on-premises czy rozwiązanie hybrydowe. Run AI stanowi warstwę abstrakcji dla zespołów uczenia maszynowego, działając jako platforma wirtualizacji GPU. Zadania można uruchamiać z Jupyter Notebook, terminala bash lub zdalnego PyCharm.
H2O.ai
H2O to rozproszona platforma uczenia maszynowego typu open source. Pozwala zespołom współpracować i tworzyć centralne repozytorium modeli, w którym analitycy danych mogą eksperymentować i porównywać różne modele.
Jako platforma MLOps, H2O oferuje szereg kluczowych funkcji. Po pierwsze, H2O upraszcza wdrażanie modelu na serwerze jako punkt końcowy REST. Platforma udostępnia różne strategie wdrażania, takie jak testy A/B, modele Champoion-Challenger oraz proste wdrażanie pojedynczego modelu.
Podczas szkolenia H2O przechowuje i zarządza danymi, artefaktami, eksperymentami, modelami i wdrożeniami. Umożliwia to powtarzalność modeli. Platforma umożliwia również zarządzanie uprawnieniami na poziomie grupy i użytkownika, w celu zarządzania modelami i danymi. Gdy model jest już w użyciu, H2O zapewnia również monitorowanie w czasie rzeczywistym dryfu modelu i innych wskaźników operacyjnych.
Paperspace Gradient
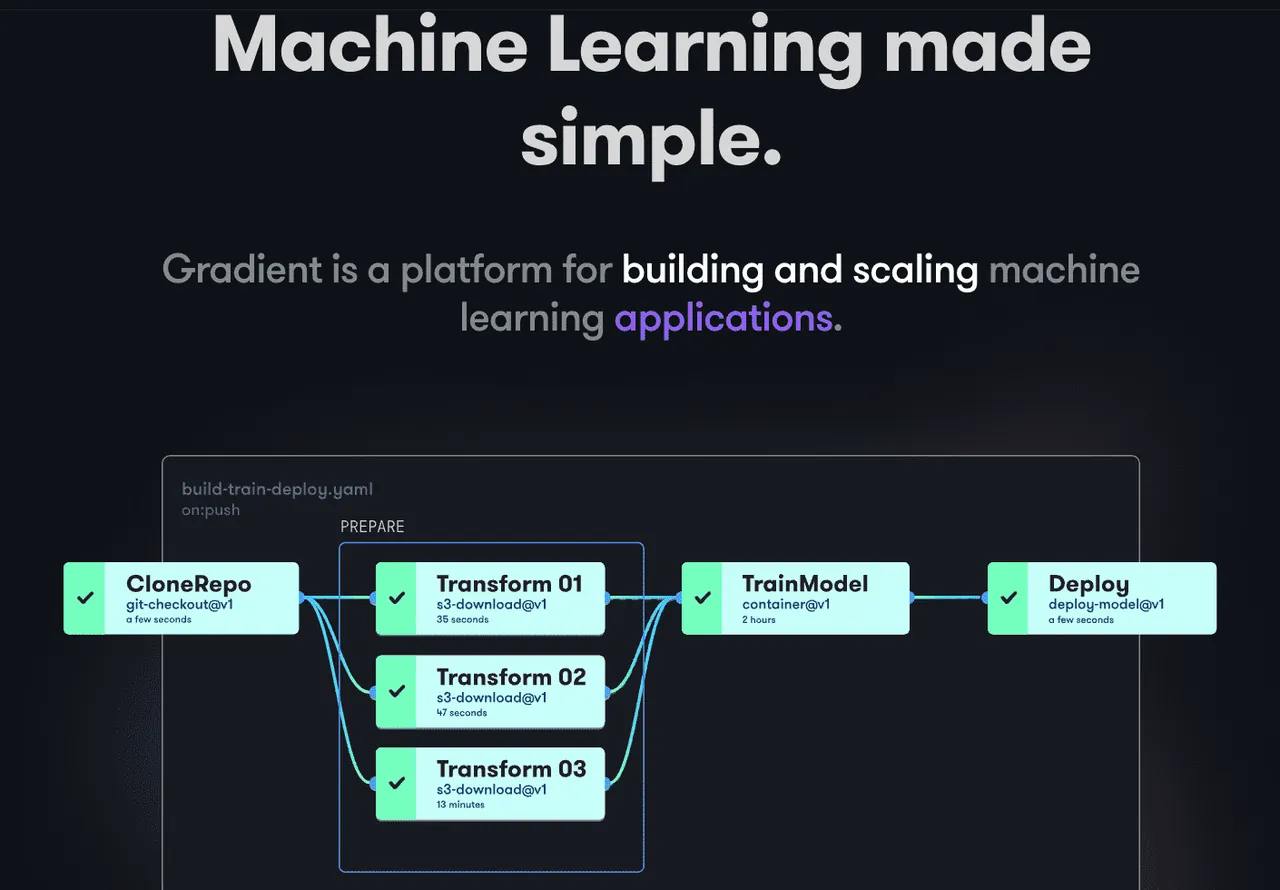
Gradient wspiera programistów na wszystkich etapach cyklu rozwoju Machine Learning. Oferuje notebooki obsługiwane przez platformę Jupyter o otwartym kodzie źródłowym, służące do opracowywania modeli i szkolenia w chmurze z wykorzystaniem wydajnych procesorów graficznych. Umożliwia to szybkie eksplorowanie i tworzenie prototypów modeli.
Potoki wdrażania można zautomatyzować poprzez tworzenie przepływów pracy. Przepływy pracy są definiowane przez opisywanie zadań w języku YAML. Wykorzystanie przepływów pracy sprawia, że tworzenie wdrożeń i udostępnianie modeli jest łatwe do odtworzenia, a tym samym skalowalne.
Ogólnie rzecz biorąc, Gradient oferuje kontenery, maszyny, dane, modele, metryki, dzienniki i klucze tajne, pomagając w zarządzaniu różnymi etapami potoku opracowywania modelu uczenia maszynowego. Potoki działają w klastrach Gradient. Klastry te mogą być zlokalizowane w Paperspace Cloud, AWS, GCP, Azure lub na innych serwerach. Z Gradientem można wchodzić w interakcję za pomocą CLI lub SDK programowo.
Podsumowanie
MLOps to skuteczne i uniwersalne podejście do budowania, wdrażania i zarządzania modelami uczenia maszynowego na dużą skalę. MLOps jest łatwe w obsłudze, skalowalne i bezpieczne, co czyni go dobrym rozwiązaniem dla organizacji każdej wielkości.
W niniejszym artykule omówiliśmy czym jest MLOps, dlaczego warto go wdrożyć, co się z tym wiąże oraz przykłady popularnych platform MLOps.
Zachęcamy również do zapoznania się z naszym porównaniem Dataricks i Snowflake.
