Informacje to cenny element, który może znacząco wpłynąć na sprawność działania, efektywność, obsługę klienta oraz procesy decyzyjne.
W związku z tym, przedsiębiorstwa i instytucje tworzą, gromadzą i archiwizują ogromne ilości danych z różnorodnych źródeł. Niemniej jednak, wraz ze wzrostem wolumenu danych, odnalezienie najbardziej wartościowych informacji może stanowić wyzwanie, zwłaszcza gdy są one chaotyczne i rozmieszczone w wielu miejscach.
Jednym ze sposobów na pokonanie tych trudności jest przechowywanie danych w dedykowanym repozytorium. Zapewnia ono jednolite źródło danych, z którego informacje można filtrować, przeszukiwać, a następnie analizować i wykorzystywać w raportach.
Źródło: aws.amazon.com
W dalszej części artykułu przyjrzymy się bliżej definicji repozytorium danych, jego zaletom, różnym typom oraz najlepszym praktykom.
Czym jest repozytorium danych?
Repozytorium danych to biblioteka lub archiwum przechowujące dane, które wspierają analizę i raportowanie w badaniach lub operacjach biznesowych. W praktyce termin ten odnosi się do centralnej lokalizacji, gdzie dane są przechowywane. Może to być pojedyncze urządzenie pamięci masowej lub rozbudowany zestaw baz danych na różnych nośnikach.
W typowym działaniu organizacje mogą pozyskiwać różnorodne dane z systemów sprzedaży, CRM, ERP, arkuszy kalkulacyjnych i innych źródeł. Następnie dane te są przenoszone do repozytorium, gdzie są sortowane, oczyszczane, weryfikowane, formatowane, porządkowane i przechowywane.
Zazwyczaj organizacje przechowują konkretne typy danych w repozytorium w celach analitycznych lub sprawozdawczych. Ze względu na długoterminowe przechowywanie, mogą być one wielokrotnie wykorzystywane do różnorodnych analiz.
Typowe repozytorium danych składa się z trzech głównych warstw:
- Warstwa źródeł danych
- Warstwa przetwarzania danych, czyli hurtownia
- Warstwa docelowa aplikacji, np. użytkownicy, analitycy i generowanie raportów
Dlaczego warto korzystać z repozytorium danych?
Dane pochodzą z wielu punktów styku z klientem, internetu, badań, marketingu, aplikacji i innych źródeł. Często są one w surowej formie, a organizacje potrzebują odpowiednich narzędzi, aby wydobyć z nich wartościowe informacje pomocne w osiąganiu celów. Utworzenie repozytorium danych to praktyczny sposób na uporządkowanie danych i ich przygotowanie do analizy.
Repozytorium zapewnia autoryzowanym użytkownikom łatwy i szybki dostęp do danych, ich pobieranie i zarządzanie za pomocą wyszukiwania, zapytań i innych narzędzi. W efekcie użytkownicy i firmy mogą przeprowadzać analizy, badania oraz generować raporty. Umożliwia to usprawnienie operacji i podejmowanie lepszych decyzji w oparciu o solidne dane.
Załóżmy, że chcesz sprawdzić, który dział w twojej firmie generuje najwyższe koszty operacyjne. Możesz utworzyć repozytorium danych, gromadząc informacje o czynszu, ochronie, kosztach energii i innych wydatkach. Przechowywanie danych w jednym miejscu ułatwia analizę i identyfikację działu z największymi wydatkami, co pozwala na bardziej świadome decyzje w celu optymalizacji kosztów.
Choć repozytoria danych są powszechnie stosowane w instytucjach badawczych i naukowych, ich zastosowanie jest uniwersalne i przydatne dla każdej organizacji.
Zalety repozytoriów danych
Obecnie wiele organizacji wykorzystuje repozytoria danych, aby skuteczniej zarządzać swoimi danymi i wykorzystywać ich potencjał. Koncepcja ta zyskuje na popularności dzięki łatwemu dostępowi do informacji, zarządzaniu, analizie i raportowaniu.
Dodatkowe korzyści to:
- Lepsza widoczność: Zapisywanie danych w centralnym, bezpiecznym miejscu zapewnia do nich stały dostęp. Przechowywanie danych w nieudostępnianych aplikacjach lub lokalnych silosach ogranicza dostęp do pojedynczych osób lub niewielkiej grupy. Zmniejsza to widoczność i użyteczność danych. Zespoły mogą potrzebować więcej czasu i dodatkowych zasobów, aby uzyskać dostęp do potrzebnych informacji.
- Prosty dostęp do wartościowych danych: Cyfrowe dane są łatwe do wyszukiwania i uzyskiwania. Dodanie metadanych do danych w repozytorium ułatwia użytkownikom ich zrozumienie i skuteczne wykorzystanie.
- Łatwiejsza ochrona i zgodność z przepisami: Łatwiej jest zabezpieczyć dane w centralnej lokalizacji, niż gdy są rozproszone. Repoza zytorium ułatwia również spełnienie wymagań różnych norm prawnych.
- Powtórne wykorzystanie danych: Repozytorium danych zawiera różnorodne dane do analizy i raportowania. Analitycy mogą wykorzystywać te same dane do generowania różnych rodzajów raportów.
- Dostarczanie przydatnych informacji: Wykorzystanie odpowiednich narzędzi w repozytoriach danych pozwala uzyskać wielowymiarowy obraz danych, a nie analizować informacje z różnych źródeł.
Rodzaje repozytoriów danych
Repozytorium danych to ogólny termin oznaczający archiwum informacji. Istnieją jednak różne rodzaje repozytoriów, zależne od docelowej aplikacji lub celu. Poniżej omówiono cztery podstawowe typy.
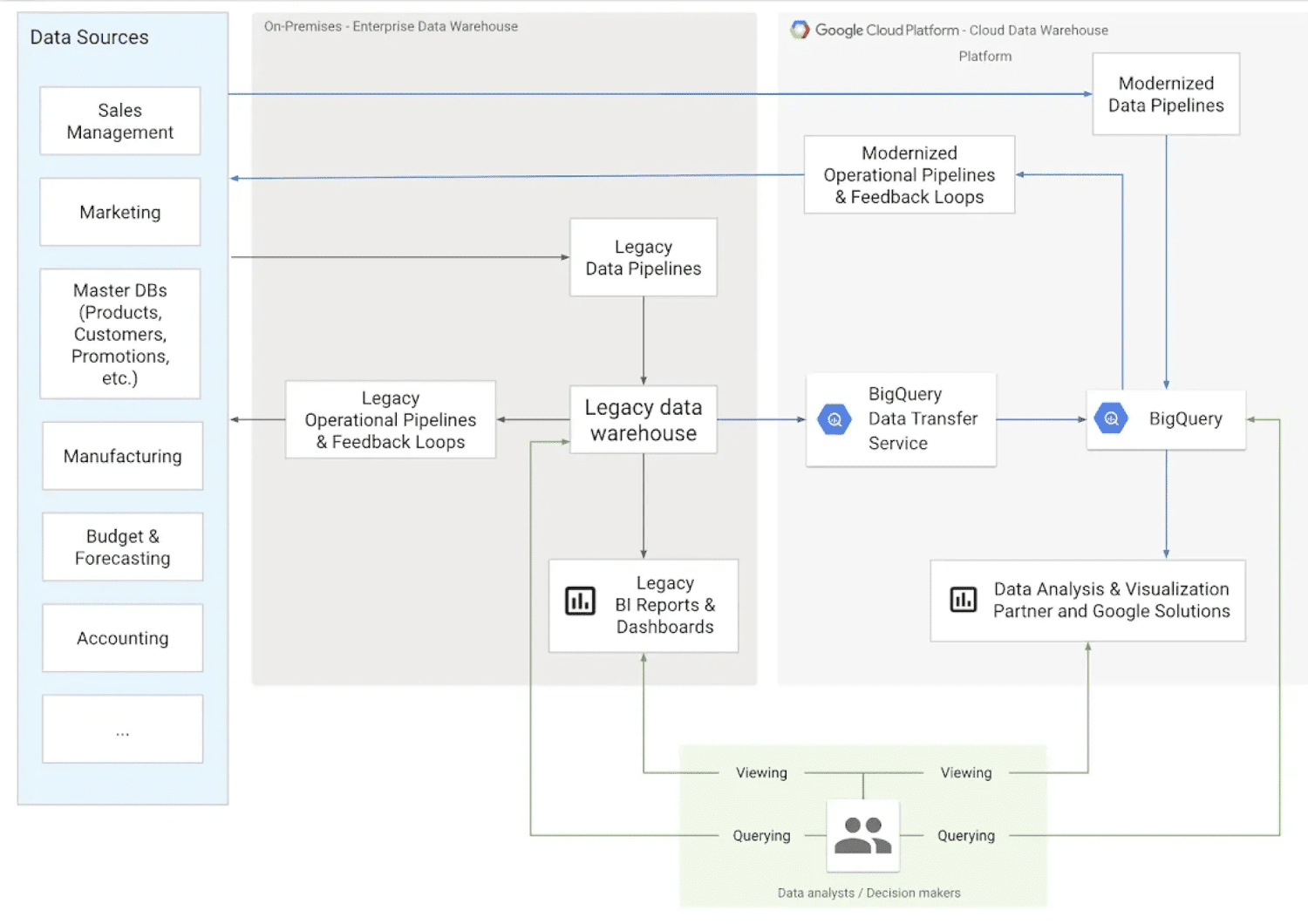
# 1. Hurtownia danych
 Źródło: cloud.google.com
Źródło: cloud.google.com
Hurtownia danych jest jednym z największych rodzajów repozytoriów danych. W tej kategorii firmy mogą gromadzić dane z wielu źródeł i w różnych formatach. Typowa hurtownia danych przechowuje duże ilości informacji pochodzących z różnych źródeł. Jej struktura umożliwia firmom łatwe porządkowanie, analizowanie danych i tworzenie raportów. Dzięki temu zespoły mogą podejmować lepsze decyzje na podstawie danych.
Informacje w hurtowni danych mogą obejmować wiele tematów i zazwyczaj są oczyszczone, przefiltrowane i dostosowane do konkretnego zastosowania.
#2. Magazyn danych
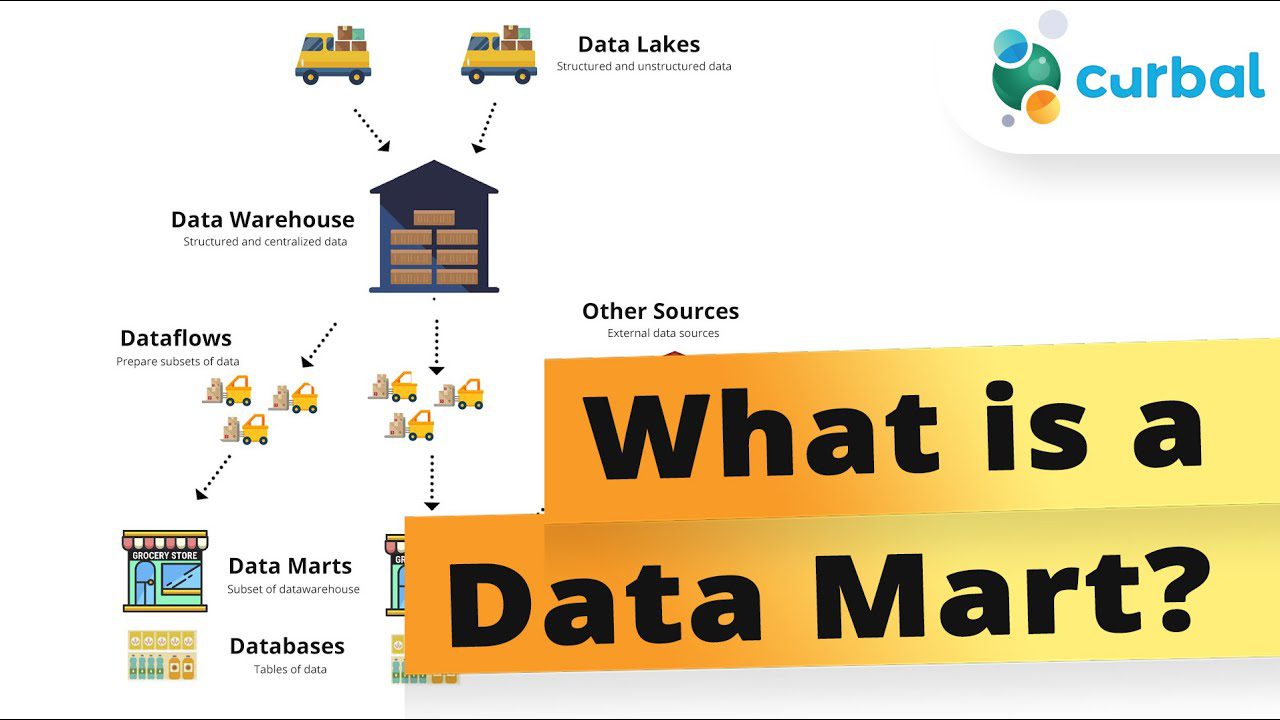
Magazyn danych to wydzielona część hurtowni danych. Repozytorium danych tematycznych przechowuje podzbiór informacji, skupiając się na konkretnej funkcji biznesowej lub dziale, takim jak finanse, wsparcie, zakupy lub marketing.
Zazwyczaj magazyn danych jest mniejszy. Przyspiesza to procesy biznesowe, umożliwiając szybki dostęp do odpowiednich informacji. Są one opłacalnym sposobem na szybkie uzyskanie przydatnych informacji.
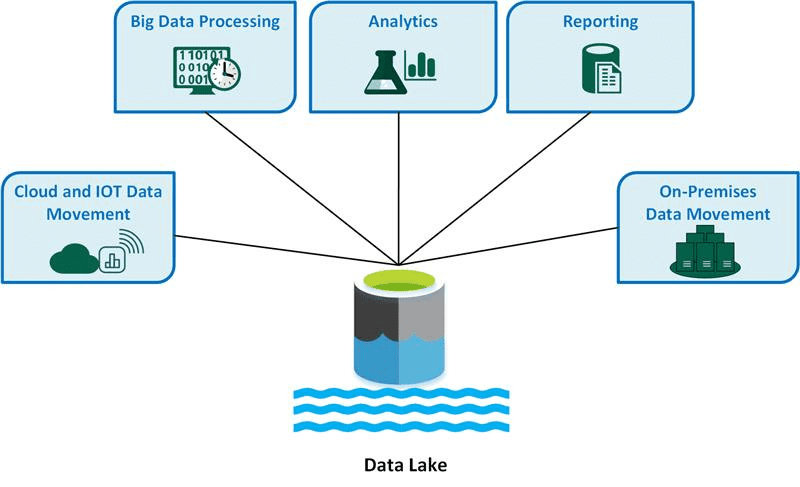
#3. Jezioro danych
 Źródło: microsoft.com
Źródło: microsoft.com
Jezioro danych to rozległe archiwum przechowujące dane w dowolnej formie. Obejmuje dane nieustrukturyzowane, częściowo ustrukturyzowane i ustrukturyzowane. Wykorzystuje metadane do kategoryzacji i opisywania danych, które w dużej mierze są nieustrukturyzowane. Jezioro danych zapewnia całkowitą kontrolę i lepsze zarządzanie informacjami niż hurtownia danych.
#4. Kostki danych
Kostki danych to wielowymiarowe repozytoria danych, koncentrujące się na bardziej złożonych informacjach, które nie są obsługiwane przez inne typy. Mają one trzy lub więcej wymiarów, z których każdy reprezentuje konkretną cechę, np. dzienne, miesięczne lub roczne koszty lub sprzedaż. Kostki danych umożliwiają analitykom ocenę informacji z różnych perspektyw.
Przeczytaj także: Data Lake a hurtownia danych: jakie są różnice?
Najlepsze praktyki projektowania i utrzymywania repozytoriów danych
Typowe repozytorium danych posiada narzędzia do przechowywania, zarządzania i ochrony informacji. Ma funkcje takie jak kontrola dostępu, indeksowanie, kompresja, raportowanie, szyfrowanie i inne.
Projektując i tworząc repozytorium danych, oprócz współpracy z inżynierami potoków danych, analitykami i innymi ekspertami, należy wziąć pod uwagę szereg czynników związanych ze sprzętem i oprogramowaniem. W zależności od dziedziny należy zaangażować ekspertów branżowych. Przykładowo, tworząc repozytorium danych medycznych, będziesz współpracować z lekarzami i innymi pracownikami służby zdrowia.
Skuteczna strategia zarządzania danymi obejmuje:
✅ Porządkowanie plików
✅ Bezpieczne przechowywanie i odpowiednia kontrola dostępu
✅ Kontrola wersji i dokumentacji
✅ Wspieranie współpracy
✅ Jasne zasady dotyczące ponownego wykorzystywania i udostępniania
✅ Archiwizowanie i zachowywanie danych do przyszłego wykorzystania.
Chociaż etapy projektowania, tworzenia i zarządzania repozytorium danych mogą się różnić w zależności od branży lub organizacji, poniżej przedstawiono kilka najlepszych praktyk.
Ograniczenie zakresu na początku
Na początkowych etapach dobrą praktyką jest rozpoczęcie od mniejszego zakresu repozytorium danych. Jedną ze strategii jest wykorzystanie mniejszej liczby obszarów tematycznych i zestawów danych, a następnie stopniowe rozszerzanie zakresu.
Wybór odpowiednich narzędzi
Narzędzia są kluczowe w tworzeniu, przechowywaniu, udostępnianiu, analizowaniu i zarządzaniu repozytoriami danych. Od jakości używanych narzędzi zależy jakość i analiza danych. Ponieważ istnieje wiele narzędzi o różnych funkcjach, należy upewnić się, że wybór jest zgodny z potrzebami.
Automatyzacja jak największej liczby procesów
W miarę możliwości należy automatyzować zadania ładowania i konserwacji, aby zwiększyć efektywność, zmniejszyć straty czasu i ograniczyć ryzyko błędów.
Projekt elastycznego i skalowalnego repozytorium
Aby uwzględnić rosnące ilości danych, zmieniające się typy i formaty, najlepiej zaprojektować i utworzyć skalowalne repozytorium. Taki system spełni bieżące potrzeby i będzie można go rozbudować w przyszłości, aby obsługiwać większe ilości danych. Powinien być również elastyczny i współpracować z różnymi narzędziami oraz nowymi technologiami.
Ochrona danych przez cały czas
Należy zadbać o integralność i bezpieczeństwo danych, ponieważ wszelkie rozbieżności, naruszenia lub kradzież mogą prowadzić do nieprawidłowych wyników analiz i błędnych decyzji. Należy ustawić odpowiednie reguły dostępu i przyznać uprawnionym użytkownikom tylko te, które są niezbędne do wykonywania obowiązków. Dodatkowo należy szyfrować dane w spoczynku i podczas przesyłania. Należy również rozważyć inne środki, takie jak uwierzytelnianie wieloskładnikowe, aby zapewnić dodatkową warstwę ochrony.
Wykorzystanie standardowych modeli danych
Modelowanie danych pomaga przekształcić dane w cenne informacje, które badacze i liderzy biznesowi mogą lepiej zrozumieć. Zazwyczaj informacje w repozytorium danych nadają się do ponownego wykorzystania.
Organizacje mogą wykorzystywać te same dane do wydobywania wartościowych informacji w różnych obszarach. Dane mają wiele kontekstów w zależności od tego, jak są wykorzystywane w różnych procesach i aplikacjach analitycznych. W związku z tym organizacja może korzystać z kilku modeli danych, aby zaspokoić różne potrzeby analityczne.
Indeksowanie danych
Tworzenie indeksów w tabelach repozytorium danych zwiększa efektywność zapytań i powinno być standardową praktyką. Przyspiesza wykonywanie zapytań, udostępniając zorganizowaną tabelę wyszukiwania opartą na określonych atrybutach i wpisach wskazujących na lokalizację danych.
Indeksowanie w repozytoriach danych może być różne, zależnie od zastosowania. Może być lekkie lub rozbudowane. W idealnej sytuacji strategia indeksowania powinna koncentrować się na przyspieszeniu procesów ETL. Jedną z najlepszych praktyk podczas przekształcania danych jest upewnienie się, że indeks zawiera niezbędne informacje bez utraty przydatnych danych i nie jest niepotrzebnie duży.
Należy również wyważyć kompromis między poprawą wydajności zapytań repozytorium danych a związanymi z tym kosztami utrzymania indeksowania.
Przeczytaj także: Najlepsze narzędzia ETL dla małych i średnich firm.
Przykłady repozytoriów danych
Repozytoria danych dzielą się na różne kategorie:
Przypadki użycia repozytoriów danych
Branże takie jak fintech, opieka zdrowotna, e-commerce, łańcuch dostaw i inne mogą skorzystać z repozytoriów danych. Dzięki pełnemu wykorzystaniu zgromadzonych danych mogą uzyskać lepszy wgląd w optymalizację usług, a także zapewnić lepszą i szybszą obsługę.
Badania kliniczne
Badania kliniczne to obszar wymagający dużych ilości danych. Maksymalne wykorzystanie informacji pomaga kierować branżę opieki zdrowotnej we właściwym kierunku. Analiza dużych zbiorów danych umożliwia naukowcom i specjalistom pogłębianie badań klinicznych i uzyskiwanie wiedzy, która pomaga ulepszać opiekę zdrowotną i ratować życie.
Usługi finansowe

Branża usług finansowych może wiele zyskać analizując ogromne ilości posiadanych danych. Analiza dostarcza im informacji, które można wykorzystać do ulepszenia usług, zwiększenia efektywności i przychodów. Przykładowe obszary zastosowania repozytoriów danych przez instytucje finansowe to:
- Generowanie raportów finansowych poprzez analizę danych z centralnej lokalizacji.
- Umożliwia podejmowanie automatycznych decyzji opartych na sztucznej inteligencji.
Podsumowanie
Informacje są kluczowym elementem procesu decyzyjnego. Jednak organizacje przechowujące duże ilości danych potrzebują skutecznych rozwiązań do gromadzenia, przechowywania, zarządzania i analizowania tych informacji.
W tym celu repozytorium danych stanowi rozwiązanie umożliwiające konsolidację i zarządzanie istotnymi informacjami. Repozytoria umożliwiają organizacjom analizowanie danych, uzyskiwanie wglądu i podejmowanie trafniejszych decyzji w oparciu o solidne dane.
Repozytorium danych zapewnia scentralizowane przechowywanie różnych typów informacji w uporządkowany sposób, który ułatwia dostęp, wyszukiwanie, analizę i zarządzanie. Pomaga także organizacjom w zabezpieczaniu, udostępnianiu, utrzymywaniu oraz zapewnieniu integralności i jakości danych, a także zgodności ze standardami regulacyjnymi.
Następnie sprawdź najlepsze narzędzia do zarządzania danymi dla średnich i dużych firm.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.