

Jeśli używasz Linuksa od jakiegoś czasu, wiesz już o grep — Global Regular Expression Print, narzędziu do przetwarzania tekstu, którego możesz używać do wyszukiwania plików i katalogów. Jest bardzo przydatny w rękach zaawansowanego użytkownika Linuksa. Jednak używanie go bez wyrażenia regularnego może ograniczyć jego możliwości.
Ale co to jest regex?
Regex to wyrażenia regularne, których możesz użyć do ulepszenia funkcjonalności wyszukiwania grep. Regex z definicji jest zaawansowanym wzorcem filtrowania danych wyjściowych. Z praktyką możesz skutecznie używać wyrażeń regularnych, ponieważ możesz ich używać również z innymi poleceniami Linuksa.
W naszym samouczku nauczymy się, jak efektywnie używać Grep i Regex.
Spis treści:
Warunek wstępny
Używanie grep z wyrażeniem regularnym wymaga dobrej znajomości Linuksa. Jeśli jesteś początkującym, zapoznaj się z naszymi przewodnikami po systemie Linux.
Potrzebujesz również dostępu do laptopa lub komputera z systemem operacyjnym Linux. Możesz użyć dowolnej wybranej dystrybucji Linuksa. A jeśli masz komputer z systemem Windows, nadal możesz używać Linuksa z WSL2. Sprawdź nasze szczegółowe podejście do tego tutaj.
Dostęp do wiersza poleceń/terminala umożliwia uruchamianie wszystkich poleceń podanych w naszym samouczku grep/regex.
Ponadto potrzebujesz również dostępu do plików tekstowych, które będą potrzebne do uruchomienia przykładów. Użyłem ChatGPT do wygenerowania ściany tekstu, mówiąc mu, aby pisał o technologii. Monit, którego użyłem, jest następujący.
„Wygeneruj 400 słów na temat technologii. Powinien zawierać większość technologii. Upewnij się też, że powtarzasz nazwy technologii w całym tekście”.
Po wygenerowaniu tekstu skopiowałem go i zapisałem w pliku tech.txt, którego będziemy używać w całym samouczku.
Wreszcie, podstawowa znajomość polecenia grep jest koniecznością. Możesz sprawdzić 16 przykładów poleceń grep, aby odświeżyć swoją wiedzę. Na początek krótko przedstawimy też polecenie grep.
Składnia i przykłady polecenia grep
Składnia polecenia grep jest prosta.
$ grep -options [regex/pattern] [files]
Jak możesz zauważyć, oczekuje wzorca i listy plików, w których chcesz uruchomić polecenie.
Dostępnych jest wiele opcji grep, które modyfikują jego funkcjonalność. Obejmują one:
- – i: ignoruj przypadki
- -r: wykonaj wyszukiwanie rekurencyjne
- -w: przeprowadź wyszukiwanie, aby znaleźć tylko całe słowa
- -v: wyświetl wszystkie niepasujące linie
- -n: wyświetl wszystkie pasujące numery linii
- -l: wypisuje nazwy plików
- –kolor: kolorowy wydruk wyników
- -c: pokazuje liczbę dopasowań dla użytego wzorca
# 1. Wyszukaj całe słowo
Będziesz musiał użyć argumentu -w z grep do wyszukiwania całego słowa. Używając go, omijasz wszystkie ciągi pasujące do podanego wzorca.
$ grep -w ‘tech\|5G’ tech.txt
Jak widać, polecenie daje wynik, w którym szuka dwóch słów „5G” i „tech” w całym tekście. Następnie oznacza je czerwonym kolorem.
Tutaj | symbol potoku jest zmieniany, aby grep nie przetwarzał go jako metaznaku.
#2. Wyszukiwanie bez rozróżniania wielkości liter
Aby przeprowadzić wyszukiwanie bez rozróżniania wielkości liter, użyj polecenia grep z argumentem -i.
$ grep -i ‘tech’ tech.txt
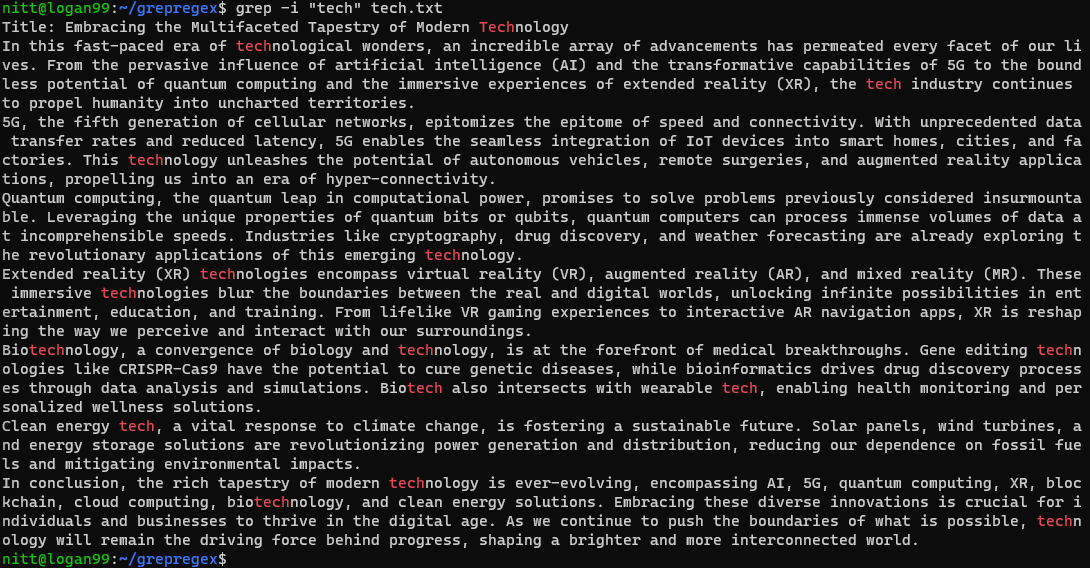
Polecenie wyszukuje dowolne wystąpienie ciągu „tech” bez rozróżniania wielkości liter, niezależnie od tego, czy jest to całe słowo, czy jego część.
#3. Wykonaj wyszukiwanie niedopasowanych wierszy
Aby wyświetlić wszystkie linie, które nie zawierają danego wzorca, musisz użyć argumentu -v.
$ grep -v ‘tech’ tech.txt

Dane wyjściowe pokazują wszystkie wiersze, które nie zawierają słowa „tech”. Zobaczysz również puste linie. Te wiersze to wiersze znajdujące się po akapicie.
#4. Wykonaj wyszukiwanie rekurencyjne
Aby przeprowadzić wyszukiwanie rekurencyjne, użyj argumentu -r z grep.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
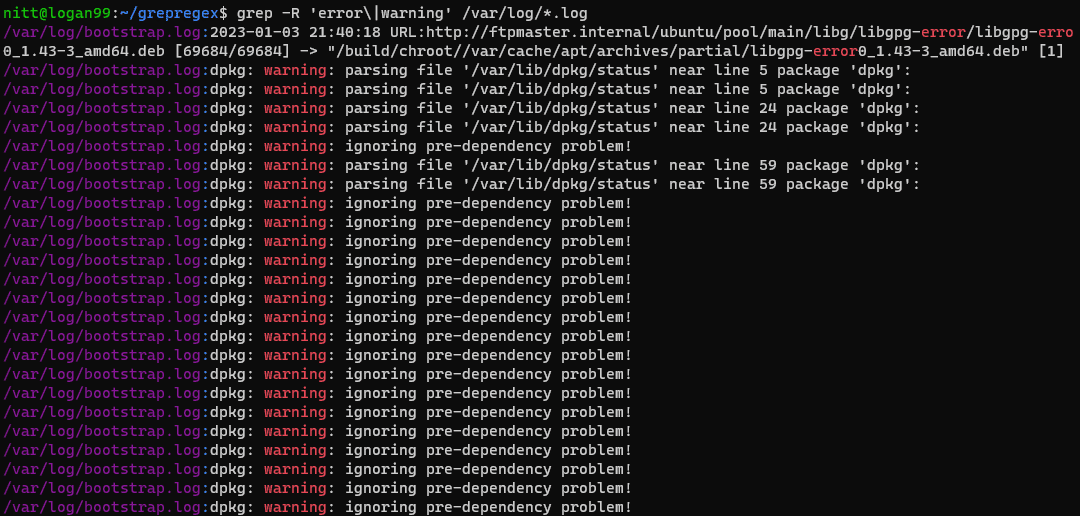
Polecenie grep rekurencyjnie wyszukuje dwa słowa „błąd” i „ostrzeżenie” w katalogu /var/log. Jest to przydatne polecenie, aby dowiedzieć się o wszelkich ostrzeżeniach i błędach w plikach dziennika.
Grep i Regex: co to jest i przykłady
Ponieważ pracujemy z wyrażeniami regularnymi, musisz wiedzieć, że wyrażenia regularne oferują trzy opcje składni. Obejmują one:
- Podstawowe wyrażenia regularne (BRE)
- Rozszerzone wyrażenia regularne (ERE)
- Wyrażenia regularne kompatybilne z Pearl (PCRE)
Polecenie grep używa BRE jako opcji domyślnej. Jeśli więc chcesz użyć innych trybów wyrażeń regularnych, musisz o nich wspomnieć. Polecenie grep traktuje również metaznaki takimi, jakie są. Tak więc, jeśli używasz metaznaków, takich jak ?, +, ), będziesz musiał zmienić ich znaczenie za pomocą polecenia odwrotnego ukośnika (\).
Składnia grep z wyrażeniem regularnym jest następująca.
$ grep [regex] [filenames]
Zobaczmy grep i regex w akcji na poniższych przykładach.
# 1. Dosłowne dopasowanie słów
Aby wykonać dosłowne dopasowanie słów, musisz podać ciąg jako wyrażenie regularne. W końcu słowo jest również wyrażeniem regularnym.
$ grep "technologies" tech.txt

Podobnie możesz również użyć dopasowań dosłownych, aby znaleźć bieżących użytkowników. W tym celu biegnij
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
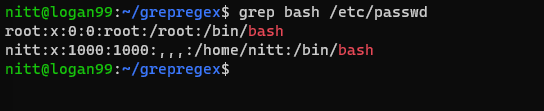
Spowoduje to wyświetlenie użytkowników, którzy mogą uzyskać dostęp do basha.
#2. Dopasowanie kotwicy
Dopasowywanie zakotwiczeń to przydatna technika zaawansowanego wyszukiwania przy użyciu znaków specjalnych. W wyrażeniu regularnym istnieją różne znaki zakotwiczenia, których można użyć do przedstawienia określonych pozycji w tekście. Obejmują one:
- „^” znak karetki: Symbol daszka pasuje do początku ciągu wejściowego lub wiersza i szuka pustego ciągu.
- Symbol dolara „$”: symbol dolara pasuje do końca ciągu wejściowego lub wiersza i szuka pustego ciągu.
Pozostałe dwa pasujące znaki zakotwiczenia obejmują granicę słowa „\ b” i granicę niebędącą słowem „\ B”.
- Granica słowa „\ b”: za pomocą \b można ustalić pozycję między słowem a znakiem innym niż słowo. W prostych słowach pozwala dopasować całe słowa. W ten sposób można uniknąć częściowych dopasowań. Możesz go również użyć do zamiany słów lub zliczenia wystąpień słów w ciągu znaków.
- \B granica niebędąca słowem: jest przeciwieństwem granicy słowa \b w wyrażeniu regularnym, ponieważ zapewnia pozycję, która nie znajduje się między znakami dwuwyrazowymi lub niebędącymi wyrazami.
Przeanalizujmy przykłady, aby uzyskać jasny obraz.
$ grep ‘^From’ tech.txt

Użycie daszka wymaga wpisania słowa lub wzoru w odpowiedniej wielkości. To dlatego, że rozróżniana jest wielkość liter. Jeśli więc uruchomisz następujące polecenie, nic nie zwróci.
$ grep ‘^from’ tech.txt
Podobnie możesz użyć symbolu $, aby znaleźć zdanie pasujące do danego wzorca, ciągu znaków lub słowa.
$ grep ‘technology.$' tech.txt

Możesz także łączyć symbole ^ i $. Spójrzmy na poniższy przykład.
$ grep “^From \| technology.$” tech.txt
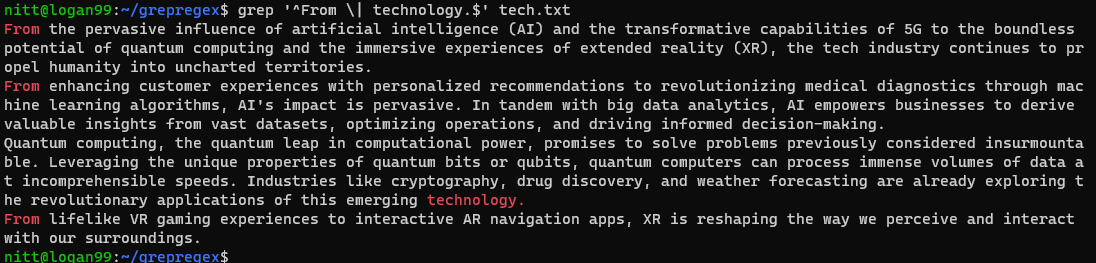
Jak widać, dane wyjściowe zawierają zdania zaczynające się od „From” i zdania kończące się na „technologia”.
#3. Grupowanie
Jeśli chcesz przeszukiwać wiele wzorców jednocześnie, musisz użyć grupowania. Pomaga tworzyć małe grupy znaków i wzorów, które można traktować jako jedną całość. Na przykład możesz utworzyć grupę (technologia), która zawiera termin „t”, „e”, „c”, „h”.
Aby uzyskać jasny obraz, spójrzmy na przykład.
$ grep 'technol\(ogy\)\?' tech.txt

Dzięki grupowaniu możesz dopasowywać powtarzające się wzorce, przechwytywać grupy i wyszukiwać alternatywy.
Alternatywne wyszukiwanie z grupowaniem
Zobaczmy przykład alternatywnego wyszukiwania.
$ grep "\(tech\|technology\)" tech.txt
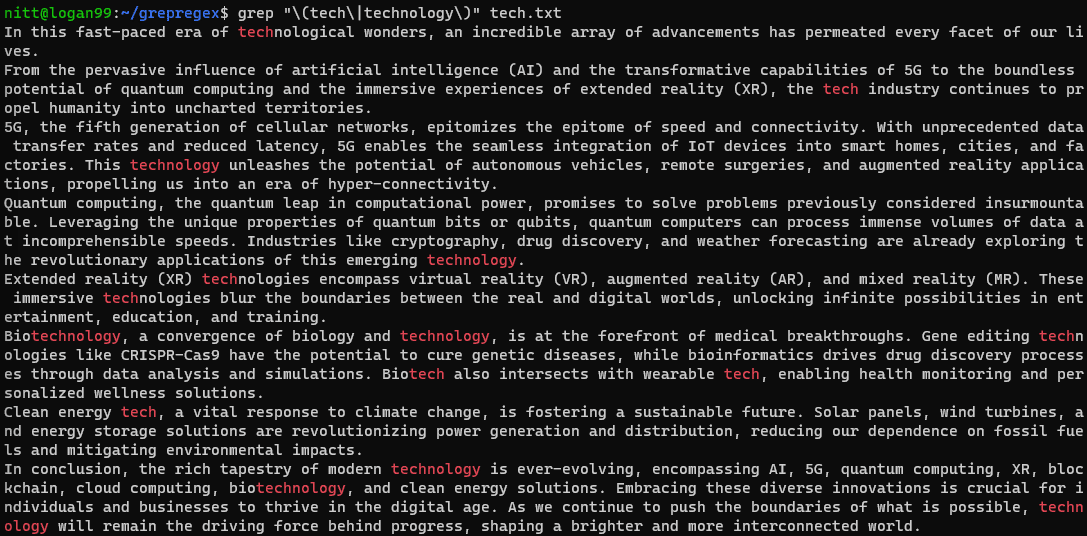
Jeśli chcesz przeprowadzić wyszukiwanie na łańcuchu, musisz przekazać go za pomocą symbolu potoku. Zobaczmy to na poniższym przykładzie.
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Grupy przechwytujące, grupy nieprzechwytujące i powtarzające się wzorce
A co z grupami przechwytującymi i nieprzechwytującymi?
Musisz utworzyć grupę w wyrażeniu regularnym i przekazać ją do łańcucha lub pliku do przechwytywania grup.
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

A w przypadku grup, które nie przechwytują, musisz użyć ?: w nawiasach.
Wreszcie mamy powtarzające się wzory. Musisz zmodyfikować wyrażenie regularne, aby sprawdzić powtarzające się wzorce.
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Tutaj wyrażenie regularne szuka jednego lub więcej wystąpień znaku „t”.
#4. Klasy postaci
Dzięki klasom znaków możesz łatwo pisać wyrażenia regularne. Te klasy znaków używają nawiasów kwadratowych. Niektóre z dobrze znanych klas postaci to:
- [:digit:] – od 0 do 9 cyfr
- [:alpha:] – znaki alfabetu
- [:alnum:] – znaki alfanumeryczne
- [:lower:] – małe litery
- [:upper:] – wielkie litery
- [:xdigit:] – cyfry szesnastkowe, w tym 0-9, AF, af
- [:blank:] – puste znaki, takie jak tabulator lub spacja
I tak dalej!
Sprawdźmy kilka z nich w akcji.
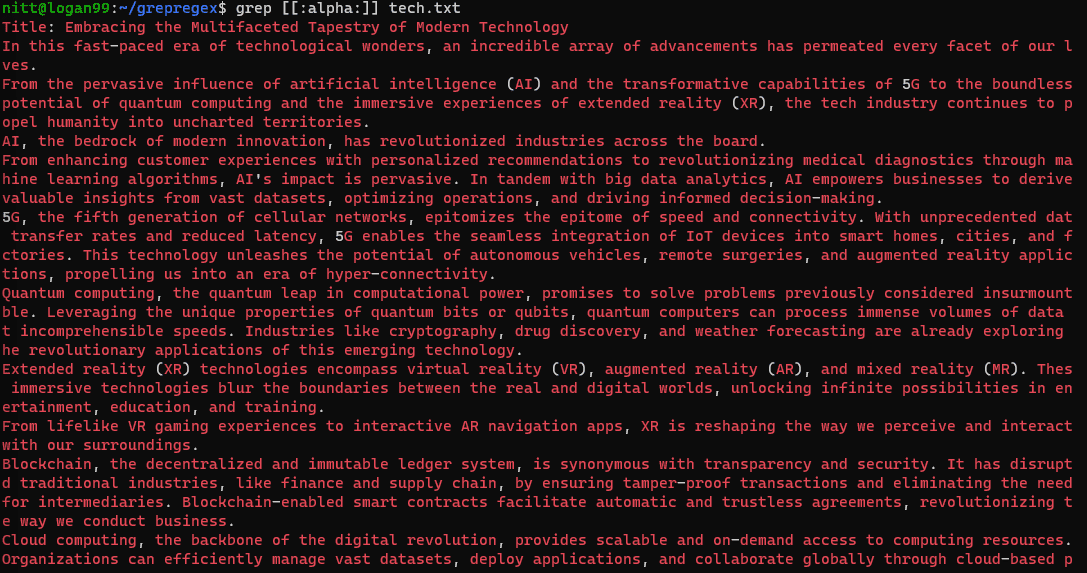
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
$ grep [[:xdigit:]] tech.txt
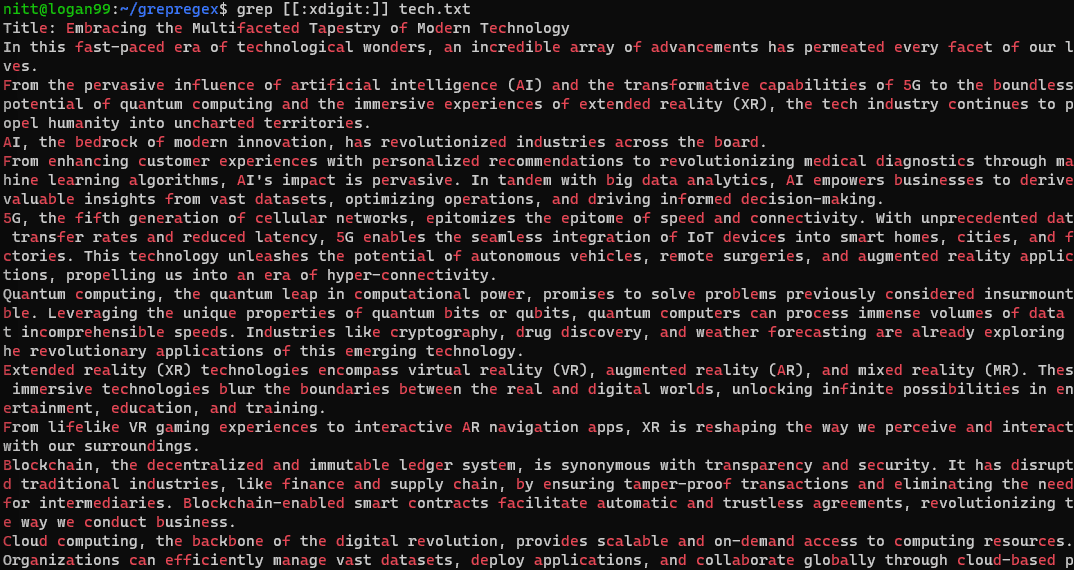
#5. Kwantyfikatory
Kwantyfikatory są metaznakami i stanowią rdzeń wyrażenia regularnego. Pozwalają one dokładnie dopasować wygląd. Przyjrzyjmy się im poniżej.
- * → Zero lub więcej dopasowań
- + → jedno lub więcej dopasowań
- ? → Zero lub jedno dopasowanie
- {x} → x dopasowań
- {x, } → x lub więcej dopasowań
- {x,z} → od x do z dopasowań
- {, z} → do z dopasowań
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Tutaj wyszukuje instancje znaku „t” dla jednego lub więcej dopasowań. Tutaj -E oznacza rozszerzone wyrażenie regularne (które omówimy później).

#6. Rozszerzone wyrażenie regularne
Jeśli nie lubisz dodawać znaków ucieczki we wzorcu wyrażenia regularnego, musisz użyć rozszerzonego wyrażenia regularnego. Eliminuje potrzebę dodawania znaków ucieczki. Aby to zrobić, musisz użyć flagi -E.
$ grep -E 'in+ovation' tech.txt

#7. Używanie PCRE do przeprowadzania złożonych wyszukiwań
PCRE (Perl Compatible Regular Expression) umożliwia znacznie więcej niż pisanie podstawowych wyrażeń. Na przykład możesz napisać „\d”, co oznacza [0-9].
Na przykład możesz użyć PCRE do wyszukiwania adresów e-mail.
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

Tutaj PCRE zapewnia dopasowanie wzorca. Podobnie możesz również użyć wzorca PCRE do sprawdzenia wzorców dat.
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Polecenie znajduje datę w formacie RRRR-MM-DD. Możesz go zmodyfikować, aby pasował również do innego formatu daty.
#8. Alternacja
Jeśli chcesz alternatywnych dopasowań, możesz użyć znaków potoku ucieczki (\|).
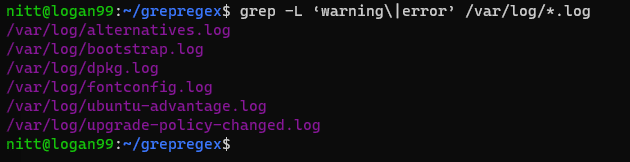
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Dane wyjściowe zawierają nazwy plików zawierające „ostrzeżenie” lub „błąd”.
Ostatnie słowa
To prowadzi nas do końca naszego przewodnika po grep i regex. Możesz szeroko używać grep z wyrażeniami regularnymi, aby zawęzić wyszukiwanie. Przy prawidłowym użyciu możesz zaoszczędzić mnóstwo czasu i zautomatyzować wiele zadań, zwłaszcza jeśli używasz ich do pisania skryptów lub używania wyrażeń regularnych do wyszukiwania w tekście.
Następnie sprawdź często zadawane pytania i odpowiedzi na rozmowy kwalifikacyjne dotyczące systemu Linux.