Apache Kafka i RabbitMQ to dwa popularne rozwiązania do obsługi przesyłania wiadomości, umożliwiające odseparowanie komunikacji między aplikacjami. Jakie są ich kluczowe cechy i w czym się różnią? Przyjrzyjmy się bliżej.
RabbitMQ
RabbitMQ to otwarte oprogramowanie, pełniące funkcję brokera wiadomości, dedykowane do komunikacji i wymiany informacji pomiędzy różnymi podmiotami. Zostało stworzone w języku Erlang, co zapewnia mu lekkość i wysoką efektywność. Erlang, opracowany przez firmę Ericsson, jest szczególnie ceniony w kontekście systemów rozproszonych.
Uważany jest za bardziej tradycyjnego brokera wiadomości. Działa w oparciu o model publikowania-subskrypcji, chociaż umożliwia komunikację synchroniczną lub asynchroniczną, w zależności od konfiguracji. Gwarantuje również dostarczanie i odpowiednią kolejność wiadomości pomiędzy producentami i konsumentami.
Obsługuje protokoły takie jak AMQP, STOMP, MQTT, HTTP i gniazda sieciowe. Wykorzystuje trzy modele wymiany wiadomości: tematyczny, rozgłoszeniowy i bezpośredni:
- Bezpośrednia wymiana, gdzie wiadomości są kierowane do odbiorców na podstawie tematu. [topic]
- Wiadomość jest dostarczana do wszystkich konsumentów podłączonych do danej kolejki. [fanout]
- Wiadomość jest kierowana do konkretnego odbiorcy. [direct]
Oto kluczowe komponenty RabbitMQ:
Producenci
Producenci to aplikacje, które tworzą i wysyłają wiadomości do RabbitMQ. Może to być dowolna aplikacja, która potrafi połączyć się z RabbitMQ i publikować wiadomości.
Konsumenci
Konsumenci to aplikacje, które odbierają i przetwarzają wiadomości z RabbitMQ. Podobnie jak w przypadku producentów, może to być dowolna aplikacja, która potrafi nawiązać połączenie z RabbitMQ i subskrybować wiadomości.
Wymiany
Wymiany są odpowiedzialne za przyjmowanie wiadomości od producentów i kierowanie ich do odpowiednich kolejek. Istnieje kilka rodzajów wymian, w tym bezpośrednie, rozgłoszeniowe, tematyczne i oparte na nagłówkach, z których każdy ma swoje własne zasady przekazywania wiadomości.
Kolejki
Kolejki to miejsca, gdzie wiadomości są przechowywane, dopóki nie zostaną przetworzone przez konsumentów. Są tworzone przez aplikacje lub automatycznie przez RabbitMQ, gdy wiadomość jest publikowana na wymianie.
Powiązania
Powiązania definiują relacje między wymianami a kolejkami. Określają zasady kierowania wiadomości, które są wykorzystywane przez wymiany do przesyłania wiadomości do odpowiednich kolejek.
Architektura RabbitMQ
RabbitMQ wykorzystuje model „pull” do dostarczania wiadomości. W tym modelu, konsumenci aktywnie żądają wiadomości od brokera. Wiadomości są publikowane na wymianach, które są odpowiedzialne za kierowanie wiadomości do odpowiednich kolejek na podstawie kluczy routingu.
Architektura RabbitMQ opiera się na modelu klient-serwer i składa się z kilku elementów, które współpracują ze sobą w celu zapewnienia niezawodnej i skalowalnej platformy do przesyłania wiadomości. Koncepcja AMQP obejmuje komponenty takie jak Wymiany, Kolejki, Powiązania oraz Wydawcy i Subskrybenci. Wydawcy wysyłają wiadomości do wymian.
Wymiany odbierają te wiadomości i dystrybuują je do kolejek (od 0 do n) w oparciu o określone reguły (powiązania). Wiadomości przechowywane w kolejkach są następnie pobierane przez konsumentów. W uproszczeniu, zarządzanie wiadomościami w RabbitMQ wygląda następująco:
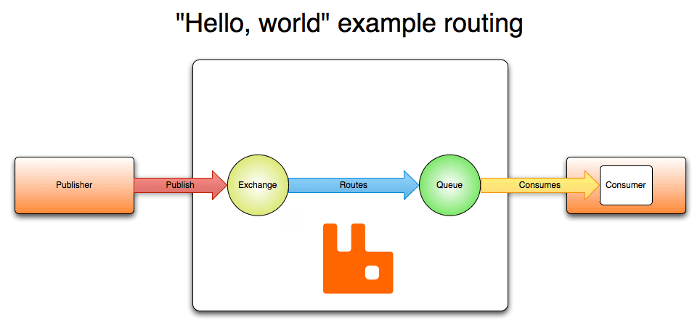 Źródło obrazu: VMware
Źródło obrazu: VMware
- Wydawcy wysyłają wiadomości do wymiany.
- Wymiana przekazuje wiadomości do kolejek i innych wymian.
- Po otrzymaniu wiadomości, RabbitMQ wysyła potwierdzenia do nadawców.
- Konsumenci utrzymują stałe połączenia TCP z RabbitMQ i deklarują, którą kolejkę subskrybują.
- RabbitMQ kieruje wiadomości do konsumentów.
- Konsumenci wysyłają potwierdzenia o pomyślnym lub nieudanym odbiorze wiadomości.
- Po pomyślnym odebraniu, wiadomość jest usuwana z kolejki.
Apache Kafka
Apache Kafka to rozproszone rozwiązanie open-source do przesyłania wiadomości, stworzone przez LinkedIn w języku Scala. Umożliwia przetwarzanie wiadomości i ich przechowywanie w modelu publikuj-subskrybuj, charakteryzując się wysoką skalowalnością i wydajnością.

Aby przechowywać odebrane zdarzenia lub wiadomości, Kafka rozdziela tematy pomiędzy węzły za pomocą partycji. Łączy w sobie cechy modelu publikuj-subskrybuj oraz kolejki komunikatów, a także odpowiada za zapewnienie odpowiedniej kolejności wiadomości dla każdego konsumenta.
Kafka jest szczególnie efektywna w obsłudze strumieni danych w czasie rzeczywistym, charakteryzując się dużą przepustowością i niskimi opóźnieniami. Osiąga to poprzez minimalizację logiki po stronie serwera (brokera) oraz dzięki pewnym specyficznym rozwiązaniom implementacyjnym.
Przykładowo, Kafka w ogóle nie używa pamięci RAM, zapisując dane bezpośrednio w systemie plików serwera. Dzięki sekwencyjnemu zapisowi danych, osiągana jest wydajność odczytu i zapisu porównywalna z użyciem pamięci RAM.
Oto kluczowe koncepcje Kafki, które czynią ją skalowalną, wydajną i odporną na błędy:
Temat
Temat to sposób kategoryzacji lub oznaczania wiadomości. Wyobraźmy sobie szafę z 10 szufladami; każda szuflada może być tematem, a szafą jest platforma Apache Kafka. Oprócz kategoryzowania i grupowania wiadomości, inną trafną analogią do tematu byłoby umieszczenie go w relacyjnej bazie danych.
Producent
Producent to podmiot, który łączy się z platformą przesyłania wiadomości i wysyła jedną lub więcej wiadomości do określonego tematu.
Konsument
Konsument to podmiot, który łączy się z platformą przesyłania wiadomości i odbiera jedną lub więcej wiadomości z określonego tematu.
Broker
Broker w kontekście platformy Kafka to w zasadzie sama Kafka, która zarządza tematami i określa sposób przechowywania wiadomości, dzienników, itd.
Klaster
Klaster to zestaw brokerów, które komunikują się ze sobą w celu zwiększenia skalowalności i odporności na awarie.
Plik dziennika
Każdy temat przechowuje swoje rekordy w formie dziennika, czyli w uporządkowany i sekwencyjny sposób. Plik dziennika to zatem plik zawierający informacje dotyczące danego tematu.
Partycje
Partycje to warstwa, która dzieli wiadomości w temacie. To partycjonowanie zapewnia elastyczność, odporność na błędy i skalowalność Apache Kafka, dzięki czemu każdy temat może mieć wiele partycji w różnych lokalizacjach.
Architektura Apache Kafka
Kafka działa w oparciu o model „push” dostarczania wiadomości. W tym modelu wiadomości w Kafce są aktywnie „wypychane” do konsumentów. Wiadomości są publikowane w tematach, które są podzielone na partycje i dystrybuowane do różnych brokerów w klastrze.
Konsumenci mogą subskrybować jeden lub więcej tematów i otrzymywać wiadomości w miarę ich pojawiania się w tych tematach.
W Kafce każdy temat jest podzielony na jedną lub więcej partycji. To w partycjach kończą się zdarzenia.
Jeśli w klastrze znajduje się więcej niż jeden broker, partycje są równomiernie rozłożone pomiędzy brokerów (w miarę możliwości), co pozwala na skalowanie obciążenia zapisu i odczytu w ramach jednego tematu, wykorzystując jednocześnie wielu brokerów. Ponieważ jest to klaster, do synchronizacji wykorzystuje się ZooKeeper.
Kafka przyjmuje, przechowuje i dystrybuuje rekordy. Rekord to dane wygenerowane przez węzeł systemu, które mogą być zdarzeniem lub informacją. Rekord jest wysyłany do klastra, a klaster przechowuje go w partycji danego tematu.
Każdy rekord ma swoje przesunięcie sekwencyjne, a konsument może kontrolować przesunięcie, które wykorzystuje. W ten sposób, jeśli istnieje potrzeba ponownego przetworzenia tematu, można to zrobić na podstawie przesunięcia.
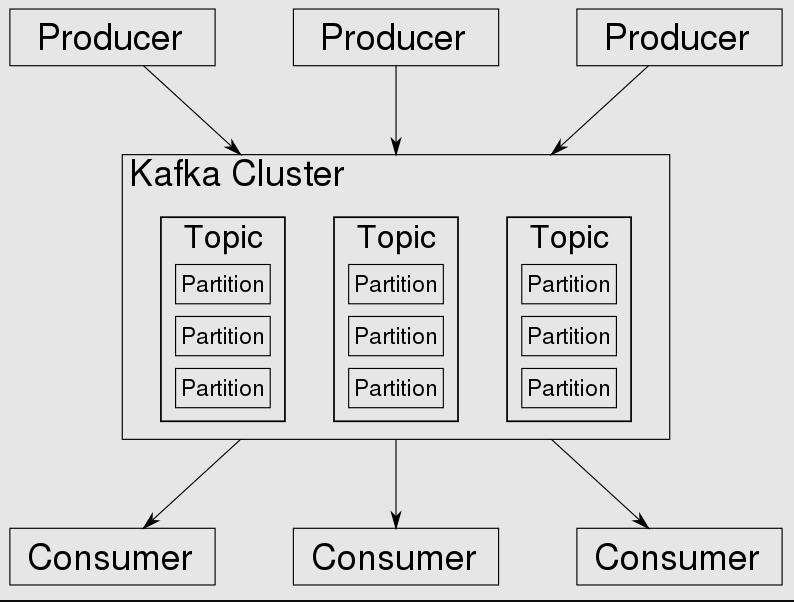 Źródło obrazu: Wikipedia
Źródło obrazu: Wikipedia
Logika, taka jak zarządzanie ostatnim odczytanym identyfikatorem wiadomości konsumenta lub decyzja, do której partycji należy zapisać nowo nadesłane dane, jest w całości przeniesiona na klienta (producenta lub konsumenta).
Oprócz koncepcji producenta i konsumenta, istotne są także koncepcje tematu, partycji i replikacji.
Temat opisuje kategorię wiadomości. Kafka osiąga odporność na awarie poprzez replikowanie danych w temacie i skaluje się, dzieląc temat na wiele serwerów.
RabbitMQ kontra Kafka
Główne różnice pomiędzy Apache Kafka a RabbitMQ wynikają z odmiennych modeli dostarczania wiadomości, które są zaimplementowane w tych systemach.
Apache Kafka działa w oparciu o zasadę „pull”, gdzie to konsumenci sami pobierają wiadomości z tematu.
Z kolei RabbitMQ realizuje model „push”, wysyłając wiadomości bezpośrednio do odbiorców. W związku z tym, Kafka różni się od RabbitMQ w następujący sposób:
#1. Architektura
Jedną z kluczowych różnic między RabbitMQ a Kafką jest ich architektura. RabbitMQ stosuje tradycyjną architekturę kolejki komunikatów opartą na brokerze, podczas gdy Kafka wykorzystuje architekturę rozproszonej platformy strumieniowej.
Ponadto, RabbitMQ używa modelu dostarczania wiadomości opartego na ściąganiu, a Kafka – modelu opartego na wypychaniu.
#2. Zapisywanie wiadomości
RabbitMQ umieszcza wiadomość w kolejce FIFO (First In – First Out) i monitoruje jej status, natomiast Kafka dodaje wiadomość do dziennika (zapisuje na dysku), pozostawiając odbiorcy odpowiedzialność za pobranie potrzebnych informacji z tematu.
RabbitMQ usuwa wiadomość po jej dostarczeniu do odbiorcy, a Kafka przechowuje wiadomość, dopóki nie zostanie zaplanowane wyczyszczenie dziennika.
W ten sposób Kafka rejestruje obecny i wszystkie poprzednie stany systemu, co czyni ją wiarygodnym źródłem danych historycznych, w przeciwieństwie do RabbitMQ.
#3. Równoważenie obciążenia
Dzięki modelowi „pull” dostarczania wiadomości, RabbitMQ minimalizuje opóźnienia. Jednak odbiorcy mogą zostać przeciążeni, jeśli wiadomości napływają do kolejki szybciej niż są w stanie je przetwarzać.
Ponieważ w RabbitMQ każdy odbiorca żąda/przesyła inną liczbę wiadomości, podział pracy może stać się nierównomierny, co spowoduje opóźnienia i utratę kolejności wiadomości podczas przetwarzania.
Aby temu zapobiec, każdy odbiorca w RabbitMQ konfiguruje limit pobierania wstępnego, czyli limit liczby niepotwierdzonych wiadomości. W Kafce równoważenie obciążenia odbywa się automatycznie poprzez redystrybucję odbiorców pomiędzy partycjami tematu.
#4. Rozgromienie
RabbitMQ oferuje cztery sposoby kierowania wiadomości do różnych giełd, co pozwala na elastyczne i zaawansowane wzorce przesyłania wiadomości. Kafka implementuje tylko jeden sposób zapisywania wiadomości na dysku bez routingu.
#5. Kolejność wiadomości
RabbitMQ umożliwia zachowanie kolejności wiadomości w ramach dowolnych zestawów zdarzeń, podczas gdy Apache Kafka zapewnia łatwy sposób utrzymania kolejności z zachowaniem skalowalności poprzez sekwencyjne zapisywanie wiadomości w replikowanym dzienniku (temacie).
FeatureRabbitMQKafka ArchitectureZapisuje wiadomości na dysku dołączonym do brokeraArchitektura rozproszonej platformy streamingowejModel dostarczaniaPull basedPush basedZapisywanie wiadomościNie może zapisywać wiadomościUtrzymuje kolejność przez zapisywanie do tematuLoad BalancingKonfiguruje limit pobierania z wyprzedzeniemWykonywane automatycznieRoutingObejmuje 4 sposoby routinguMa tylko 1 sposób routingu wiadomościKolejność wiadomościPozwala zachować porządek w grupachUtrzymuje kolejność przez zapisywanie do tematuProcesy zewnętrzneNie wymagaWymaga uruchomionej instancji ZookeeperWtyczkiKilka wtyczekMa ograniczoną obsługę wtyczek
RabbitMQ i Kafka to powszechnie stosowane systemy przesyłania wiadomości, z których każdy ma swoje mocne strony i zastosowania. RabbitMQ to elastyczny, niezawodny i skalowalny system przesyłania wiadomości, który doskonale radzi sobie z kolejkowaniem wiadomości, co czyni go idealnym wyborem dla aplikacji wymagających niezawodnego i elastycznego dostarczania wiadomości.
Z drugiej strony, Kafka to rozproszona platforma strumieniowa zaprojektowana do wysokoprzepustowego przetwarzania dużych ilości danych w czasie rzeczywistym, co czyni ją doskonałym wyborem dla aplikacji wymagających przetwarzania i analizy danych w czasie rzeczywistym.
Główne zastosowania RabbitMQ:
E-commerce

RabbitMQ jest wykorzystywany w aplikacjach e-commerce do zarządzania przepływem danych między różnymi systemami, takimi jak zarządzanie zapasami, przetwarzanie zamówień i realizacja płatności. Potrafi obsłużyć duże ilości wiadomości, gwarantując ich dostarczenie w sposób niezawodny i we właściwej kolejności.
Opieka zdrowotna
W branży opieki zdrowotnej, RabbitMQ służy do wymiany danych pomiędzy różnymi systemami, takimi jak elektroniczna dokumentacja medyczna (EHR), urządzenia medyczne i systemy wspomagania decyzji klinicznych. Może pomóc w poprawie opieki nad pacjentem i zmniejszeniu liczby błędów, zapewniając dostępność odpowiednich informacji we właściwym czasie.
Usługi finansowe
RabbitMQ umożliwia przesyłanie wiadomości w czasie rzeczywistym między systemami, takimi jak platformy transakcyjne, systemy zarządzania ryzykiem i bramki płatnicze. Pomaga zapewnić szybkie i bezpieczne przetwarzanie transakcji.
Systemy IoT
RabbitMQ jest wykorzystywany w systemach IoT do zarządzania przepływem danych pomiędzy różnymi urządzeniami i czujnikami. Może pomóc w zapewnieniu bezpiecznego i wydajnego dostarczania danych, nawet w środowiskach o ograniczonej przepustowości i przerywanej łączności.
Kafka to rozproszona platforma do przesyłania strumieniowego, zaprojektowana do obsługi dużych ilości danych w czasie rzeczywistym.
Główne zastosowania Kafki
Analizy w czasie rzeczywistym

Kafka jest wykorzystywana w aplikacjach analitycznych w czasie rzeczywistym do przetwarzania i analizy danych w miarę ich generowania, umożliwiając firmom podejmowanie decyzji na podstawie aktualnych informacji. Potrafi obsługiwać duże ilości danych i skalować się, aby zaspokoić potrzeby nawet najbardziej wymagających aplikacji.
Agregacja dzienników
Kafka może agregować dzienniki z różnych systemów i aplikacji, umożliwiając firmom monitorowanie i rozwiązywanie problemów w czasie rzeczywistym. Może być również wykorzystywana do przechowywania dzienników do długoterminowej analizy i raportowania.
Uczenie maszynowe
Kafka jest wykorzystywana w aplikacjach uczenia maszynowego do strumieniowego przesyłania danych do modeli w czasie rzeczywistym, umożliwiając firmom dokonywanie prognoz i podejmowanie działań w oparciu o aktualne informacje. Może pomóc w poprawie dokładności i skuteczności modeli uczenia maszynowego.
Moja opinia na temat RabbitMQ i Kafki
Zaletą szerokich i różnorodnych możliwości RabbitMQ w zakresie elastycznego zarządzania kolejkami komunikatów jest zwiększone zużycie zasobów, co może prowadzić do spadku wydajności przy większym obciążeniu. Chociaż RabbitMQ dobrze sprawdza się w złożonych systemach, w większości przypadków Apache Kafka jest lepszym wyborem do zarządzania wiadomościami.
Na przykład, w przypadku gromadzenia i agregowania wielu zdarzeń z dziesiątek systemów i serwisów, z uwzględnieniem geolokalizacji, metryk klienta, plików dzienników i analiz, z perspektywą powiększania się źródeł informacji, preferowałbym Kafkę. Jeśli jednak potrzebujesz tylko szybkiego przesyłania wiadomości, RabbitMQ również dobrze spełni swoje zadanie!
Możesz także przeczytać, jak zainstalować Apache Kafka w systemach Windows i Linux.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.