

Świat, w którym żyjemy, jest napędzany przez dane. Uzyskanie zaawansowanego wglądu w rzeczywiste dane w czasie rzeczywistym pozwala Twojej firmie zyskać przewagę. Strumieniowe przesyłanie danych umożliwia ciągłe przechwytywanie i przetwarzanie danych pochodzących z różnych źródeł, dlatego tak ważne są dobre platformy do przesyłania strumieniowego danych.
Platformy strumieniowania danych to skalowalne, rozproszone i wysoce wydajne systemy, które zapewniają niezawodne przetwarzanie strumieni danych. Obsługują agregację i analizę danych i często są wyposażone w ujednolicony pulpit nawigacyjny do wizualizacji danych.
Możesz wybierać spośród szerokiej gamy platform i rozwiązań do strumieniowego przesyłania danych — od w pełni zarządzanych systemów, takich jak Confluent Cloud i Amazon Kinesis, po rozwiązania typu open source, takie jak Arroyo i Fluvio.
Spis treści:
Jakie są przypadki użycia strumieniowego przesyłania danych?
Platformy do strumieniowego przesyłania danych mają szeroki zakres zastosowań, które obejmują. Omówmy szybko kilka z nich:
- Wykrywanie oszustw odbywa się poprzez ciągłą analizę transakcji, zachowań użytkowników i wzorców.
- Dane giełdowe są przechwytywane przez wiele systemów, które wykonują niezwykle szybkie transakcje o dużym wolumenie w oparciu o analizę rynku.
- Niestandardowe spostrzeżenia za pośrednictwem danych rynkowych w czasie rzeczywistym zapewniają rynkom e-commerce odpowiednią grupę odbiorców do kierowania ich produktów.
- Istnieją miliony czujników w różnych systemach, które dostarczają rzeczywistych danych i pomagają w przewidywaniu informacji, takich jak prognozy pogody.
Oto najlepsze platformy danych spełniające wszystkie Twoje potrzeby związane z analizą i przetwarzaniem w czasie rzeczywistym.
Zlewająca się chmura

W pełni chmurowa oferta Apache Kafka, Zlewająca się chmura zapewnia odporność, skalowalność i wysoką wydajność. Otrzymujesz moc niestandardowego silnika Kora, który zapewnia 10 razy lepszą wydajność niż uruchomienie własnego klastra Kafka. Zapewnia następujące funkcje:
- Klastry bezserwerowe oferują skalowalność i elastyczność. Możesz natychmiast spełnić wymagania dotyczące strumieniowania danych dzięki automatycznemu zwiększaniu i zmniejszaniu na żądanie.
- Twoje wymagania dotyczące przechowywania danych są spełnione dzięki nieskończonemu przechowywaniu i integralności danych. Bez problemów z trwałością możesz uczynić Confluent Cloud swoim źródłem prawdy.
- Confluent Cloud oferuje gwarancję dostępności na poziomie 99,99%, jedną z najlepszych w branży. W połączeniu z replikacją wielostrefową zyskujesz ochronę przed uszkodzeniem lub utratą danych.
Projektant strumieni zapewnia interfejs użytkownika typu „przeciągnij i upuść”, aby wizualnie utworzyć potok przetwarzania. Ponadto gotowe złącza Kafka umożliwiają podłączenie do dowolnej aplikacji lub dostawcy danych.
Confluent Cloud udostępnia Stream Governance, jedyny w branży pakiet zarządzania danymi, który jest w pełni zarządzany. Posiadanie zabezpieczeń i zgodności w chmurze klasy korporacyjnej pozwala chronić dane i kontrolować dostęp.
Confluent Cloud oferuje coś innego opcje cenowe. Oferuje również szeroką gamę zasobów, które pomogą Ci od razu się zanurzyć.
Aiven

Aiven pomaga realizować potrzeby związane z przesyłaniem strumieniowym danych w ramach w pełni zarządzanej usługi w chmurze Apache Kafka. Obsługuje wszystkich głównych dostawców chmury, w tym AWS, Google Cloud, Microsoft Azure, Digital Ocean i UpCloud.
Skonfiguruj własną usługę Kafka w mniej niż 10 minut za pomocą konsoli internetowej lub programowo przez API i CLI. Dodatkowo masz możliwość uruchamiania go w kontenerach.
Pomiń kłopoty związane z zarządzaniem Kafką dzięki w pełni zarządzanej usłudze w chmurze. Możesz szybko skonfigurować potok danych wraz z pulpitem nawigacyjnym monitorowania. Rzućmy okiem na korzyści, jakie uzyskasz:
- Otrzymuj automatyczne aktualizacje dla swojego klastra i zarządzaj aktualizacjami wersji oraz konserwacją za pomocą zaledwie kilku kliknięć.
- Aiven zapewnia 99,99% czasu pracy bez przestojów i prawie zerowych przerw.
- Zwiększ swoją pamięć masową na żądanie, dodaj więcej węzłów Kafka lub wdrażaj w różnych regionach.
Miesięcznik Aiven cennik zaczyna się od 200 USD i różni się w zależności od Twojej lokalizacji i wybranego dostawcy usług w chmurze.
Arroyo
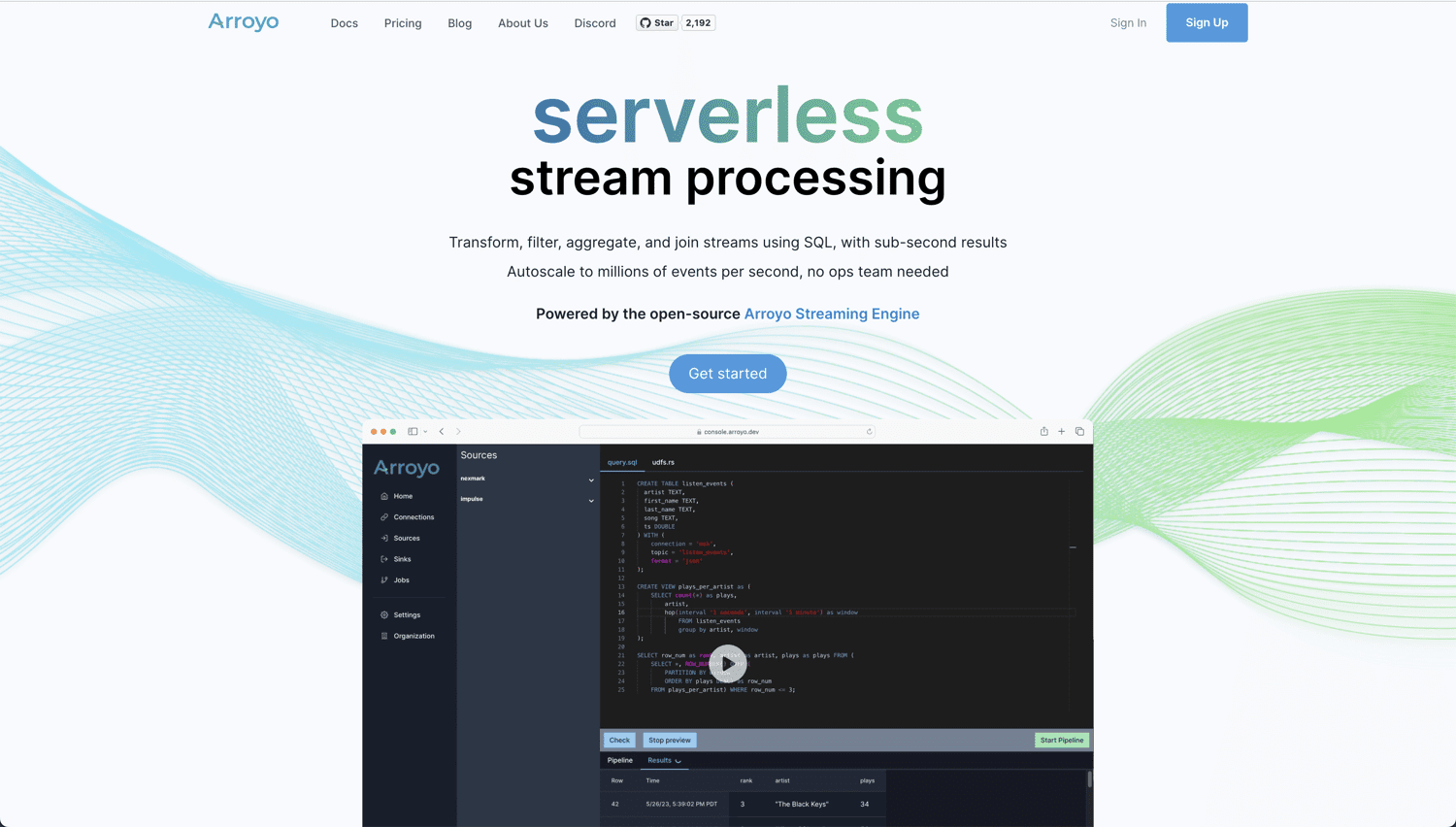
Jeśli szukasz prawdziwie chmurowego rozwiązania typu open source do analizy i przetwarzania w czasie rzeczywistym, Arroyo jest świetnym narzędziem. Jest zasilany przez Arroyo Streaming Engine — rozwiązanie do przetwarzania rozproszonego strumienia, które wyróżnia się, jeśli chodzi o wyszukiwanie danych w czasie rzeczywistym, z wynikami poniżej sekundy.
Arroyo zostało stworzone, aby przetwarzanie w czasie rzeczywistym było tak proste, jak przetwarzanie wsadowe. Ponieważ projekt jest bardzo przyjazny dla użytkownika, nie musisz być ekspertem, aby zbudować swój rurociąg. Oto, co zyskujesz dzięki Arroyo:
- Istnieje natywna obsługa różnych łączników, w tym Kafka, Pulsar, Redpanda, WebSockets i Server Sent Events.
- Po pobraniu i przetworzeniu danych wychodzące wyniki można zapisać w różnych systemach — takich jak Kafka, Amazon S3 i Postgres.
- Otrzymujesz najnowocześniejszy, wydajny i wydajny kompilator, który przekształca zapytania SQL, aby działały z maksymalną wydajnością.
- Przepływ danych dla Twoich platform danych można skalować w poziomie, aby obsługiwać miliony zdarzeń na sekundę.
Możesz uruchomić samodzielnie hostowaną instancję Arroyo, która jest bezpłatna, lub skorzystać z pomocy Arroyo Cloud, zaczynając od 200 USD miesięcznie. Jednak Arroyo jest obecnie w fazie alfa i może mieć brakujące funkcje.
Kineza Amazonki

Dane kinezy Amazona Strumienie umożliwiają zbieranie i przetwarzanie dużych strumieni danych w celu szybkiego i ciągłego pozyskiwania. Ma ogromną skalowalność, trwałość i niski koszt. Przyjrzyjmy się najważniejszym funkcjom, które otrzymujesz:
- Amazon Kinesis działa w chmurze AWS w trybie bezserwerowym na żądanie. Za pomocą kilku kliknięć w konsoli zarządzania AWS możesz uruchomić swoje strumienie danych Kinesis.
- Kinesis może działać w maksymalnie 3 strefach dostępności (AZ). Oferuje również 365 dni przechowywania danych.
- Strumienie danych Kinesis umożliwiają podłączenie do 20 konsumentów. Ponadto każdy konsument ma swoją dedykowaną przepustowość odczytu i może publikować w ciągu 70 milisekund od przetworzenia.
- Spełnij wymagania bezpieczeństwa, szyfrując swoje dane za pomocą szyfrowania po stronie serwera.
- Bycie częścią AWS pozwala Kinesis na bezproblemową integrację z innymi usługami AWS, takimi jak Cloudwatch, DynamoDB i AWS Lambda.
Z Amazon Kinesis płacisz za to, czego używasz. Biorąc pod uwagę 1000 rekordów na sekundę po 3 KB każdy, dzienny koszt trybu na żądanie na początek wyniesie około 30,61 USD. Możesz użyć Kalkulator AWS aby poznać koszt oparty na użyciu.
Kostki danych

Jeśli szukasz jednej platformy danych do przetwarzania wsadowego i strumieniowego, Datakostki Platforma Lakehouse to świetny wybór. Dodatkowo otrzymujesz analitykę w czasie rzeczywistym, uczenie maszynowe i aplikacje na jednej platformie.
Platforma Databricks Lakehouse ma własny widok danych o nazwie Delta Live Tables (DLT) z następującymi korzyściami:
- DLT pozwala łatwo zdefiniować kompleksowy potok danych.
- Otrzymujesz automatyczne testowanie jakości danych. Jednocześnie możesz monitorować trendy jakości danych w czasie.
- Jeśli Twoje obciążenie jest nieprzewidywalne, ulepszone automatyczne skalowanie DLT sobie z tym poradzi.
Otrzymujesz najlepsze miejsce do uruchamiania obciążeń Apache Spark, z technologią Spark Structured Streaming jako podstawową technologią. W połączeniu z Delta Lake, jedyną platformą pamięci masowej typu open source, która obsługuje zarówno przesyłanie strumieniowe, jak i dane wsadowe.
Dzięki platformie Databricks Lakehouse możesz korzystać z 14-dniowego bezpłatnego okresu próbnego, po którym zostaniesz automatycznie zasubskrybowany do dotychczasowego planu.
Qlik Data Streaming (CDC)

CDC lub Change Data Capture to technika powiadamiania innych systemów o wszelkich zmianach w danych. Proste i uniwersalne rozwiązanie, Qlik Data Streaming (CDC) umożliwia łatwe przenoszenie danych ze źródła do miejsca docelowego w czasie rzeczywistym. Możesz zarządzać wszystkim za pomocą prostego interfejsu graficznego.
Qlik Data Streaming (CDC) zapewnia usprawnioną i automatyczną konfigurację. W ten sposób możesz łatwo konfigurować, kontrolować i monitorować potok danych w czasie rzeczywistym.
Otrzymujesz wsparcie szerokiej gamy źródeł, celów i platform. Pozwala to nie tylko pozyskiwać szeroką gamę danych, ale także synchronizować dane lokalne, w chmurze i hybrydowe.
Qlik Enterprise Manager to Twoje centralne centrum dowodzenia, które pozwala łatwo skalować i monitorować przepływ danych za pomocą alertów.
Istnieje elastyczna opcja wdrażania, jeśli chodzi o wybór sposobu uruchamiania potoku CDC. W zależności od wymagań możesz wybrać jedną z następujących opcji:
Możesz zacząć od A bezpłatny okres próbny bez pobierania lub instalowania czegokolwiek.
Fluvio

Szukasz natywnego rozwiązania do przesyłania strumieniowego typu open source, które zapewnia niskie opóźnienia i wysoką wydajność? Fluvio pasuje do tego opisu. Zyskujesz możliwość wykonywania obliczeń inline przy użyciu SmartModules, które zwiększają funkcjonalność platformy Fluvio.
Fluvio ma rozproszone przetwarzanie strumienia z kontrolami, aby zapobiec utracie danych i przestojom. Ponadto dostępne jest natywne wsparcie API dla popularnych języków programowania, takich jak Rust, Node.js, Python, Java i Go. Rzućmy okiem na to, co platforma ma dla Ciebie w sklepie:
- Moc łączenia obliczeń i przesyłania strumieniowego w ujednoliconym klastrze zapewnia zminimalizowanie opóźnień.
- Fluvio dynamicznie ładuje niestandardowe moduły, które rozszerzają możliwości obliczeniowe.
- Otrzymujesz wysoką skalowalność, od małych urządzeń IoT po systemy wielordzeniowe.
- Ma możliwości automatycznego naprawiania przy użyciu zarządzania deklaratywnego, uzgadniania i replikacji.
- Ponieważ został zbudowany z myślą o społeczności programistów, otrzymujesz potężny interfejs CLI zapewniający wydajność.
Niezależnie od tego, czy jest to twój laptop, korporacyjne centrum danych, czy wybrana chmura publiczna, możesz zainstalować Fluvio na dowolnej platformie.
Ze względu na fakt, że jest to open source, nie ma żadnych opłat za uruchomienie Fluvio.
Przetwarzanie strumieniowe Cloudera (CSP)

Obsługiwane przez Apache Flink i Apache Kafka, Przetwarzanie strumieniowe Cloudera (CSP) zapewnia możliwości analizowania w celu uzyskania wglądu w dane przesyłane strumieniowo. Posiada natywną obsługę standardowych technologii, takich jak SQL i REST. Dodatkowo otrzymujesz kompletne rozwiązanie do zarządzania strumieniem w połączeniu z przetwarzaniem stanowym, które jest stworzone dla przedsiębiorstw.
Cloudera Stream Processing odczytuje i analizuje duże ilości danych w czasie rzeczywistym, aby uzyskać wyniki z opóźnieniem poniżej sekundy. Uzyskaj wsparcie dla chmury wielochmurowej i chmury hybrydowej wraz z niezbędnymi narzędziami do tworzenia wysoce zaawansowanych analiz opartych na danych. Korzystaj z następujących narzędzi i funkcji:
- Obsługując miliony wiadomości na sekundę, możesz nadążać za ciągle zmieniającymi się potrzebami dzięki wysoce skalowalnemu przesyłaniu strumieniowemu.
- Streams Messaging Manager oferuje kompleksowy wgląd w sposób przemieszczania danych w potoku przetwarzania danych.
- Streams Replication Manager oferuje replikację, dostępność i odzyskiwanie po awarii.
- Ogranicz niedopasowanie schematów i przerwy w działaniu dzięki Schema Registry, które pozwala zarządzać wszystkim we współdzielonym repozytorium.
- Cloudera SDX, automatycznie egzekwowane, scentralizowane zabezpieczenia, oferuje ujednoliconą kontrolę i nadzór nad wszystkimi komponentami.
Dzięki Cloudera Stream Processing w mniej niż 10 minut możesz przyspieszyć potok przetwarzania strumieniowego na wybranej platformie chmurowej — czy to AWS, Azure, czy Google Cloud Platform.
Chmura Striima
Czy Twoja platforma danych i analiza w czasie rzeczywistym wymagają szerokiej gamy producentów i konsumentów danych? Chmura Striima, z wbudowaną obsługą ponad 100 złączy, może być idealnym wyborem. Z łatwością integruj się z istniejącymi magazynami danych i przesyłaj strumieniowo dane w czasie rzeczywistym za pomocą w pełni zarządzanej platformy SaaS zaprojektowanej dla chmury.
Striim Cloud oferuje prosty interfejs typu „przeciągnij i upuść”, który nie tylko pomaga w tworzeniu potoku, ale także zapewnia wgląd w dane. Obsługuje najpopularniejsze narzędzia analityczne, w tym Google BigQuery, Snowflake, Azure Synapse i Databricks. Oprócz tego otrzymujesz:
- Twoje obawy dotyczące zmian w strukturze danych są obsługiwane przez możliwości ewolucji schematów Striim. Możesz skonfigurować go do automatycznego rozwiązania lub ręcznej interwencji.
- Zbudowany na platformie rozproszonego przesyłania strumieniowego SQL, Striim umożliwia uruchamianie ciągłych zapytań.
- Striim oferuje wysoką skalowalność i przepustowość. Następnie możesz skalować potok bez dodatkowego planowania lub kosztów.
- Metoda „ReadOnlyWriteMany” umożliwia dodawanie i usuwanie nowych obiektów docelowych bez wpływu na magazyny danych.
Płać tylko za to, z czego korzystasz. Środowisko programistyczne Striim jest bezpłatne i umożliwia wypróbowanie platformy z 10 milionami wydarzeń miesięcznie. W przypadku rozwiązania chmurowego na skalę przedsiębiorstwa cena zaczyna się od 2500 USD miesięcznie.
Platforma danych strumieniowych VK
Dzięki najwyższym standardom produktów i spostrzeżeń dotyczących danych, Vertical Knowledge (VK) pomaga osobom fizycznym i firmom podejmować ważne decyzje na dużą skalę. Platforma danych strumieniowych VK umożliwia przetwarzanie ogromnych ilości danych za pośrednictwem internetowego środowiska strumieniowego przesyłania danych.
Uzyskaj przydatne informacje dzięki zautomatyzowanemu wykrywaniu danych. Oto kluczowe zalety platformy danych strumieniowych VK:
- Otrzymujesz solidne bezpieczeństwo cybernetyczne dzięki stabilnej infrastrukturze VK, która chroni Cię przed złośliwymi treściami. Możesz także pobierać dane za pośrednictwem środowiska wirtualnego.
- Zautomatyzowane strumienie danych umożliwiają łatwą obsługę wielu źródeł danych.
- Dzięki szybkiemu wykrywaniu można zredukować ręczne procesy, które często są czasochłonne.
- Generuj głębokie kolekcje danych, uruchamiając współbieżne potoki z wielu źródeł. W ten sposób możesz wygenerować globalne wyniki dla wybranych słów kluczowych.
- Możesz wyeksportować swoje kolekcje danych w surowym formacie JSON lub CSV lub użyć interfejsów API do integracji z systemami innych firm.
Platforma HStream
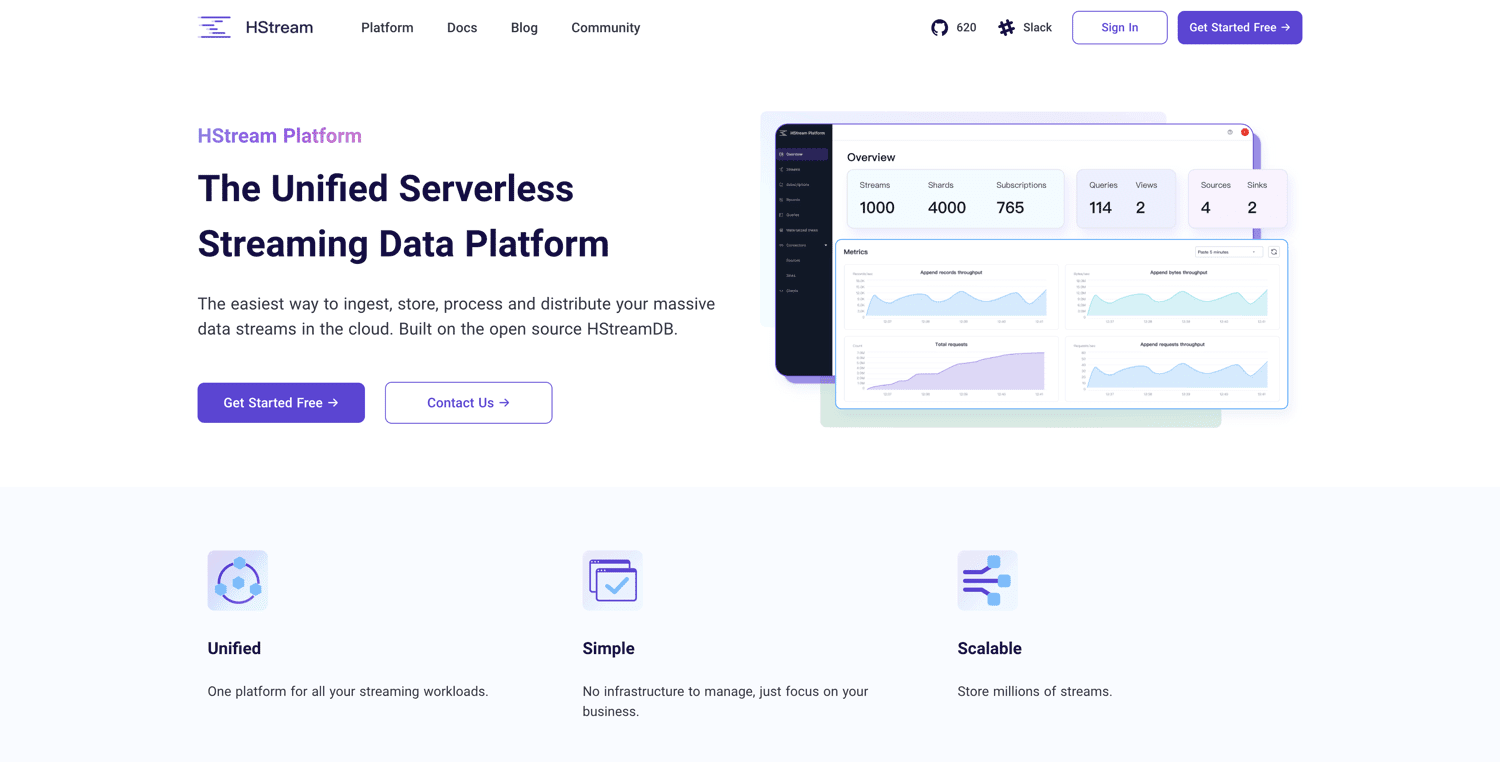
Zbudowany na bazie HStreamDB typu open source, Platforma HStream oferuje bezserwerową platformę przesyłania strumieniowego danych. Możesz przetwarzać ogromne ilości danych i niezawodnie przechowywać miliony strumieni danych. HStreamDB jest tak szybki jak Kafka. Dodatkowo możesz odtwarzać dane historyczne
Za pomocą języka SQL można filtrować, przekształcać, agregować, a nawet łączyć wiele widoków danych. W ten sposób zyskujesz wgląd w swoje dane w czasie rzeczywistym. Platforma HStream pozwala zacząć od małych i jest oszczędna. Oto najważniejsze cechy:
- Ponieważ jest bezserwerowy, jest gotowy do użycia od samego początku.
- Nie potrzebujesz Kafki do swoich potrzeb związanych z transmisją strumieniową.
- Otrzymujesz przetwarzanie strumieniowe w miejscu przy użyciu standardowego języka SQL.
- Korzystaj i twórz w różnych systemach, czy to w bazach danych, hurtowniach danych czy jeziorach danych. Nie ma więc potrzeby stosowania dodatkowych narzędzi ETL.
- Możesz wydajnie zarządzać wszystkimi obciążeniami na jednej ujednoliconej platformie do przesyłania strumieniowego.
- Architektura natywna dla chmury umożliwia niezależne skalowanie potrzeb w zakresie przetwarzania i przechowywania.
Platforma HStream jest obecnie w fazie publicznej wersji beta. Korzystanie z niego jest bezpłatne — wystarczy zapisać się dla tego.
Wniosek
Wybór dobrej platformy do strumieniowego przesyłania danych zależy od Twojej skali, zapotrzebowania na różne złącza, czasu pracy i niezawodności.
Podczas gdy niektóre platformy są w pełni zarządzanymi usługami, inne są open-source i zapewniają różne dostosowania. Przyjrzyj się swoim potrzebom i budżetowi i wybierz ten, który najbardziej Ci odpowiada.
Następnie, czy nadal zastanawiasz się, jak najlepiej wykorzystać wszystkie te dane? Wypróbuj oparte na sztucznej inteligencji narzędzia do prognozowania i przewidywania danych dla firm.