Ekstrakcja danych to proces, w którym pozyskuje się konkretne informacje ze stron internetowych. Użytkownicy mogą wydobywać różnorodne dane, takie jak teksty, zdjęcia, nagrania wideo, oceny, produkty i inne. Takie pozyskiwanie danych jest przydatne przy prowadzeniu badań rynkowych, analizowaniu opinii, śledzeniu działań konkurencji, jak i przy agregowaniu informacji.
W przypadku niewielkich ilości danych, możliwe jest manualne ich pobieranie, poprzez kopiowanie i wklejanie wybranych fragmentów ze stron internetowych do arkusza kalkulacyjnego lub dokumentu tekstowego. Przykładowo, konsument poszukujący opinii o produkcie może ręcznie zebrać te dane z różnych źródeł.
Jednak, gdy mamy do czynienia z dużymi zbiorami danych, konieczne staje się zastosowanie automatycznych technik. Możemy stworzyć własne oprogramowanie do ekstrakcji danych lub skorzystać z zewnętrznych rozwiązań, takich jak API proxy lub API do scrapingu.
Należy jednak pamiętać, że tego typu metody mogą napotkać trudności, ponieważ niektóre strony internetowe są zabezpieczone systemami CAPTCHA. Konieczne może być również zarządzanie botami oraz serwerami proxy, co pochłania czas i ogranicza ilość danych, które można wydobyć.
Przeglądarka do scrapingu: Rozwiązanie
Te wszystkie wyzwania można przezwyciężyć, korzystając z przeglądarki Scraping Browser od Bright Data. Jest to zaawansowane narzędzie, które ułatwia pozyskiwanie danych ze stron internetowych, które są trudne do wyekstrahowania. Przeglądarka ta posiada graficzny interfejs użytkownika i jest kontrolowana za pomocą API Puppeteer lub Playwright, co sprawia, że jest ona trudna do wykrycia przez boty.
Scraping Browser ma wbudowane mechanizmy odblokowujące, które automatycznie radzą sobie z wszelkimi zabezpieczeniami. Przeglądarka działa na serwerach Bright Data, co eliminuje konieczność posiadania własnej, kosztownej infrastruktury do przetwarzania danych na potrzeby dużych projektów.
Funkcje przeglądarki Bright Data Scraping
- Automatyczne odblokowywanie stron internetowych: nie ma potrzeby ręcznego odświeżania strony, ponieważ przeglądarka samodzielnie radzi sobie z CAPTCHA, nowymi zabezpieczeniami, odciskami palców przeglądarki i próbami blokowania. Scraping Browser działa jak prawdziwy użytkownik.
- Rozbudowana sieć serwerów proxy: możliwość kierowania zapytań z dowolnego kraju, dzięki 72 milionom adresów IP. Można wybrać konkretne miasta, a nawet operatorów sieci, korzystając z najlepszej dostępnej technologii.
- Skalowalność: możliwość otwierania tysięcy sesji jednocześnie, dzięki wykorzystaniu infrastruktury Bright Data.
- Kompatybilność z Puppeteer i Playwright: przeglądarka umożliwia wywoływanie API i obsługę wielu sesji za pomocą bibliotek Puppeteer (Python) lub Playwright (Node.js).
- Oszczędność czasu i zasobów: konfiguracja serwerów proxy odbywa się w tle. Eliminuje to konieczność budowania własnej infrastruktury.
Jak skonfigurować przeglądarkę do scrapingu
- Odwiedź stronę Bright Data i wybierz Scraping Browser z zakładki „Scraping Solutions”.
- Załóż konto. Do wyboru są opcje „Rozpocznij bezpłatny okres próbny” i „Rozpocznij bezpłatnie z Google”. Na potrzeby tego przewodnika wybierzmy „Rozpocznij bezpłatny okres próbny”. Konto można założyć ręcznie lub wykorzystać swoje konto Google.
- Po założeniu konta, na pulpicie pojawią się różne opcje. Wybierz „Proxy i infrastruktura do scrapingu”.
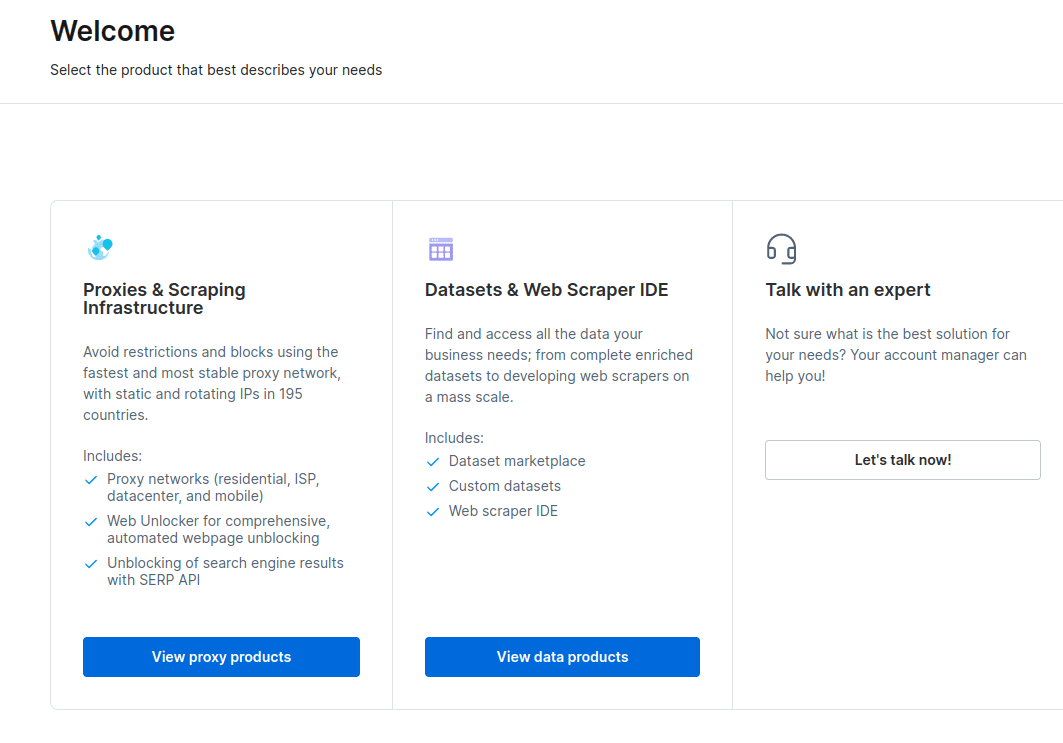
- W nowym oknie wybierz Scraping Browser i kliknij „Rozpocznij”.
- Zapisz i aktywuj swoją konfigurację.
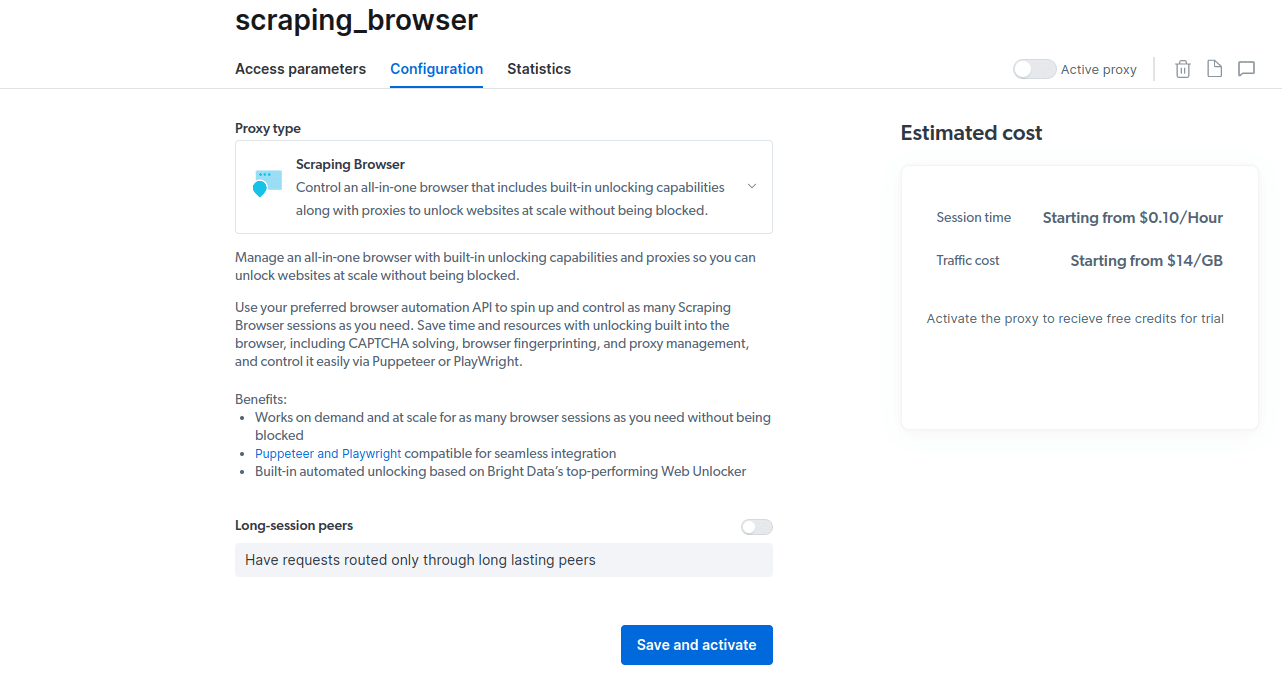
- Aktywuj bezpłatny okres próbny. Pierwsza opcja daje 5 USD kredytu na korzystanie z proxy. Wybierz ją, by przetestować produkt. Zaawansowani użytkownicy mogą wybrać drugą opcję, która oferuje 50 USD gratis przy doładowaniu konta kwotą 50 USD lub wyższą.
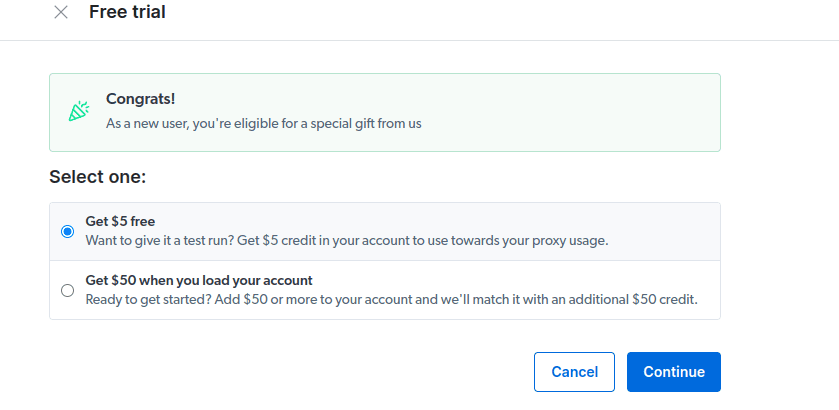
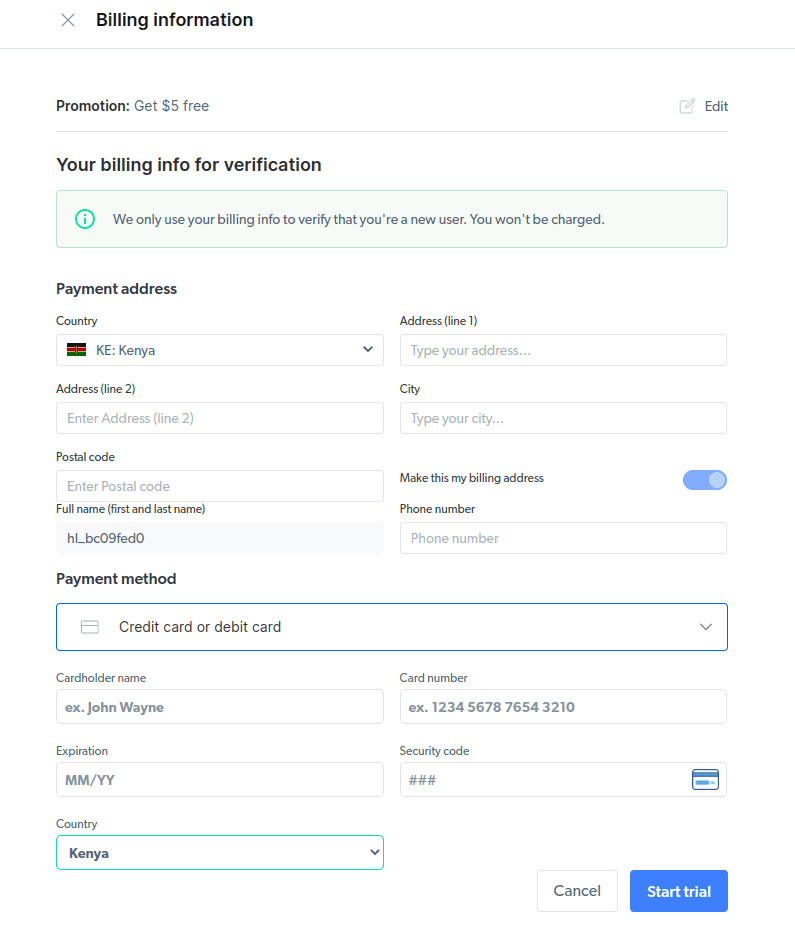
- Wprowadź dane rozliczeniowe. Nie obawiaj się, platforma nie pobierze żadnych opłat. Dane te służą jedynie weryfikacji, czy jesteś nowym użytkownikiem, a nie osobą próbującą wielokrotnie skorzystać z darmowego okresu próbnego.
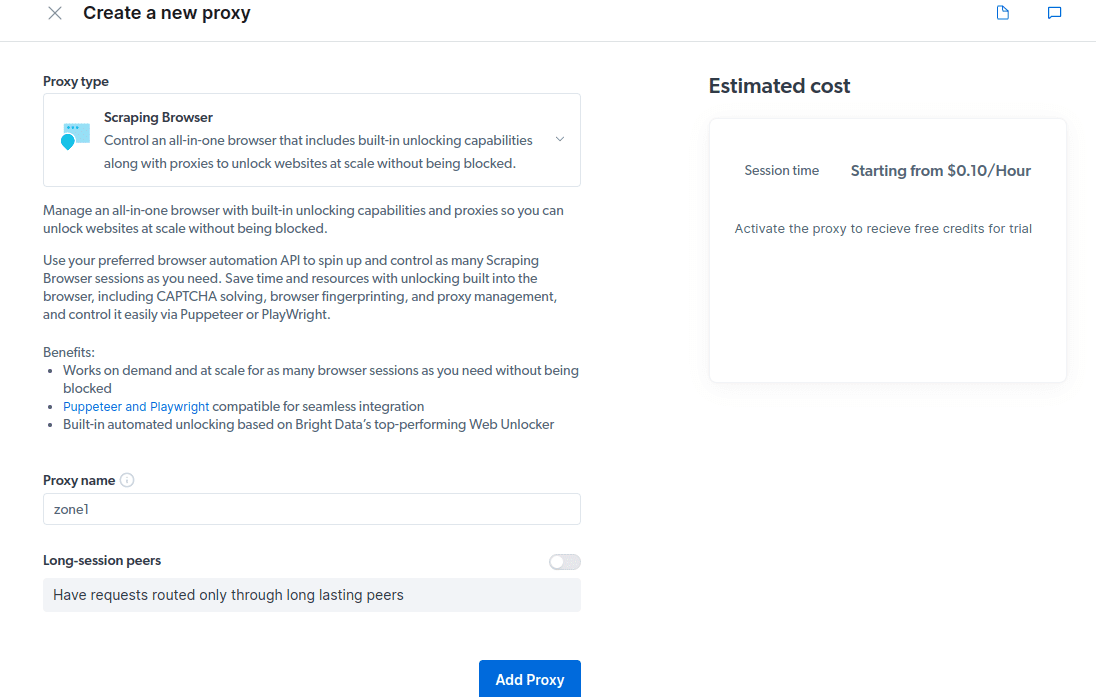
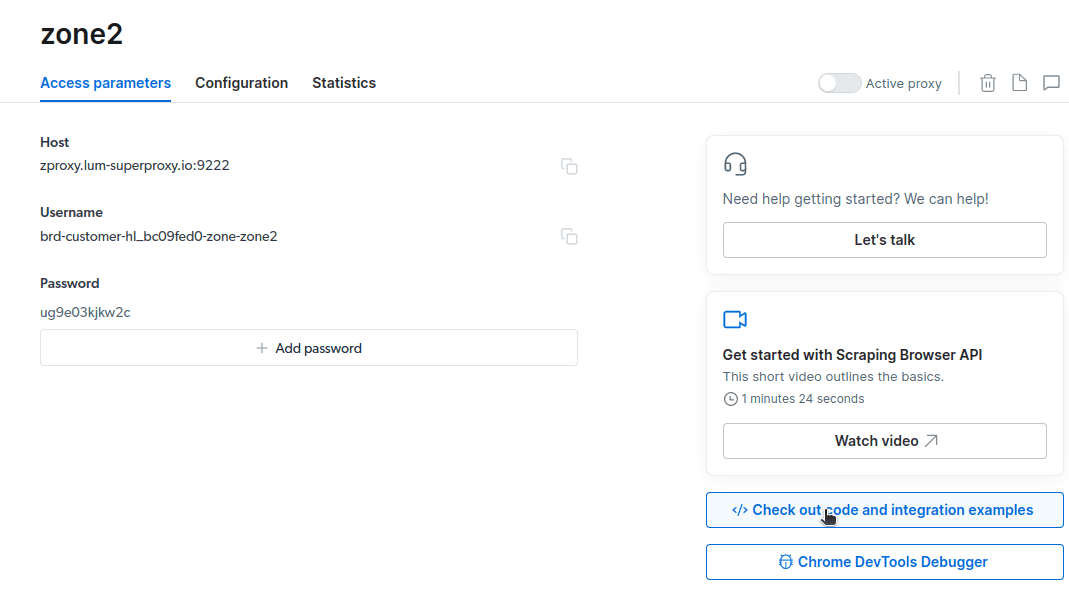
- Utwórz nowy serwer proxy. Po wprowadzeniu danych rozliczeniowych, możesz utworzyć nowe proxy. Kliknij ikonę „dodaj” i wybierz „Scraping Browser” jako „Typ serwera proxy”. Kliknij „Dodaj proxy” i przejdź do kolejnego kroku.
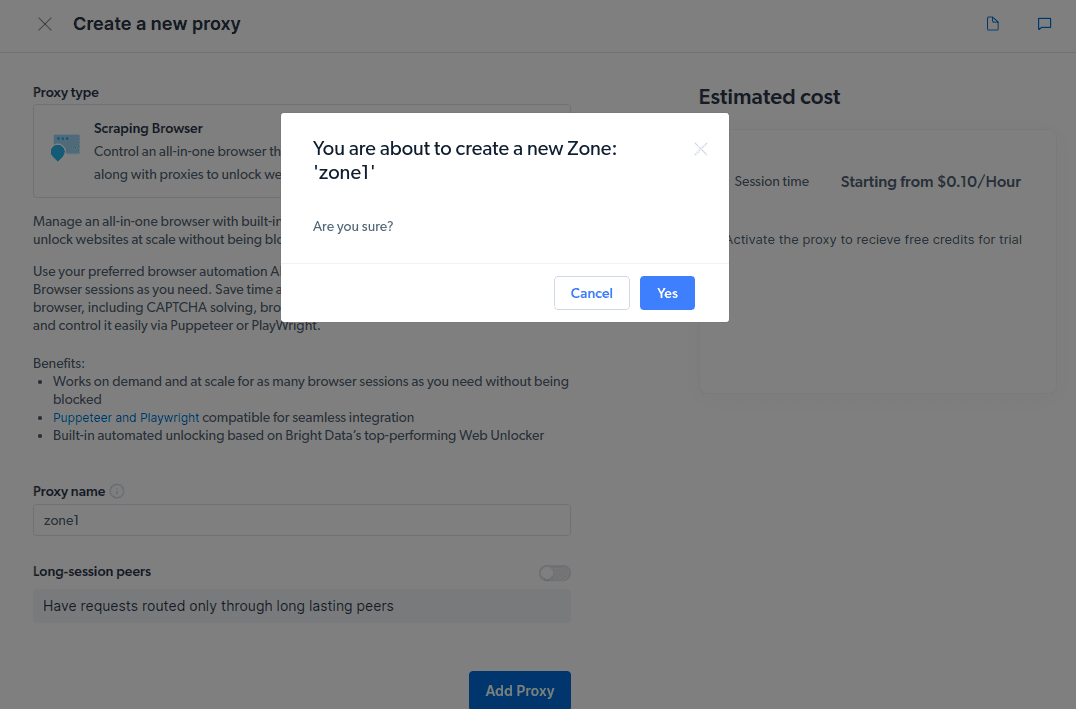
- Utwórz nową „strefę”. Pojawi się okno z pytaniem, czy chcesz utworzyć nową strefę; wybierz „Tak” i kontynuuj.
- Kliknij „Sprawdź przykłady kodu i integracji”. Otrzymasz przykłady integracji z serwerem proxy, które możesz użyć do pozyskiwania danych z wybranej strony internetowej. Możesz użyć Node.js lub Python do ekstrakcji informacji.
Masz już wszystko, czego potrzebujesz, by pobierać dane ze stron internetowych. Na przykładzie naszej strony newsblog.pl.com pokażemy, jak działa Scraping Browser. Użyjemy w tym celu pliku node.js. Postępuj zgodnie z instrukcjami, jeśli masz zainstalowane node.js.
Wykonaj następujące kroki:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="USERNAME:PASSWORD";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://example.com');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
Zmienimy linię 10 kodu na:
await page.goto(’https://newsblog.pl.com/authors/’);
Ostateczny kod będzie wyglądał tak:
const puppeteer = require('puppeteer-core');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run(){
let browser;
try {
browser = await puppeteer.connect({browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222`});
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2*60*1000);
await page.goto('https://newsblog.pl.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
console.log(html);
}
catch(e) {
console.error('run failed', e);
}
finally {
await browser?.close();
}
}
if (require.main==module)
run();
node script.js
W terminalu zobaczysz podobny wynik:
Jak wyeksportować dane
Istnieje kilka metod eksportowania danych, w zależności od tego, jak planujesz ich użyć. Dziś wyeksportujemy dane do pliku html, modyfikując skrypt tak, aby tworzył nowy plik data.html, zamiast drukować informacje na konsoli.
Zmodyfikuj swój kod w następujący sposób:
const puppeteer = require('puppeteer-core');
const fs = require('fs');
// should look like 'brd-customer-<ACCOUNT ID>-zone-<ZONE NAME>:<PASSWORD>'
const auth="brd-customer-hl_bc09fed0-zone-zone2:ug9e03kjkw2c";
async function run() {
let browser;
try {
browser = await puppeteer.connect({ browserWSEndpoint: `wss://${auth}@zproxy.lum-superproxy.io:9222` });
const page = await browser.newPage();
page.setDefaultNavigationTimeout(2 * 60 * 1000);
await page.goto('https://newsblog.pl.com/authors/');
const html = await page.evaluate(() => document.documentElement.outerHTML);
// Write HTML content to a file
fs.writeFileSync('data.html', html);
console.log('Data export complete.');
} catch (e) {
console.error('run failed', e);
} finally {
await browser?.close();
}
}
if (require.main == module) {
run();
}
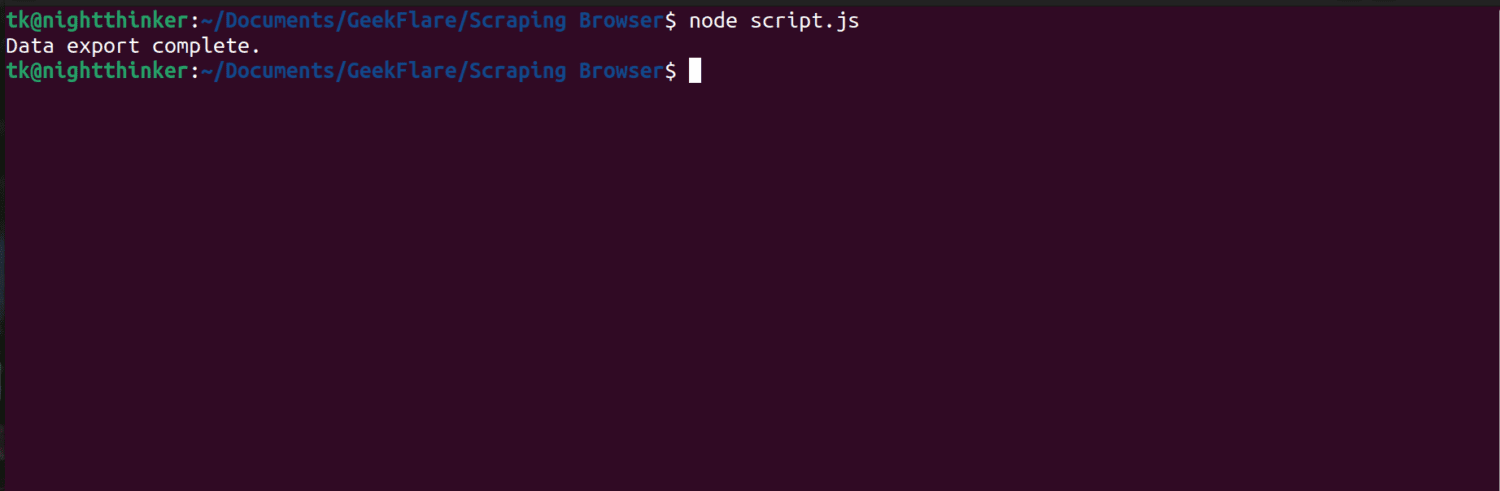
Teraz możesz uruchomić kod za pomocą polecenia:
node script.js
Jak widać na poniższym zrzucie ekranu, w terminalu wyświetla się komunikat „Eksport danych zakończony”.
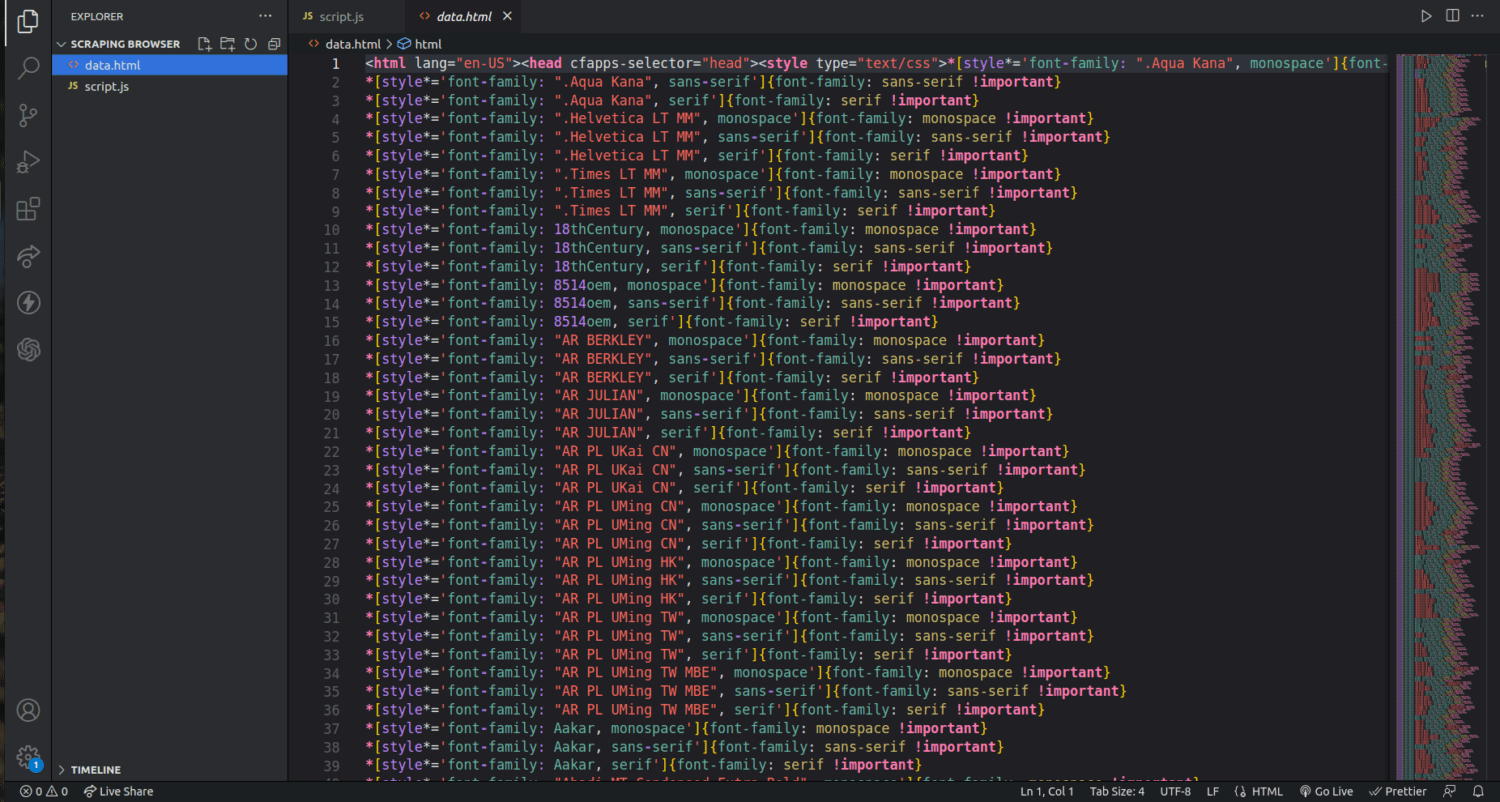
Sprawdzając folder projektu, zobaczymy nowy plik o nazwie data.html, zawierający tysiące linii kodu.
To tylko podstawowy przykład wykorzystania przeglądarki Scraping Browser do ekstrakcji danych. Za pomocą tego narzędzia możemy precyzyjnie wyselekcjonować i pozyskać tylko wybrane informacje, np. imiona i nazwiska autorów oraz ich opisy.
Aby skutecznie korzystać z przeglądarki do scrapingu, należy zdefiniować, jakie konkretne dane chcemy pozyskać, i odpowiednio zmodyfikować kod. Możliwe jest wydobywanie tekstu, obrazów, filmów, metadanych i linków, w zależności od specyfiki strony internetowej i struktury pliku HTML.
Często zadawane pytania
Czy ekstrakcja danych i web scraping są legalne?
Web scraping to temat kontrowersyjny. Jedni uważają go za niemoralny, inni za akceptowalny. Legalność scrapingu zależy od rodzaju treści i polityki strony internetowej. Pobieranie danych osobowych, takich jak adresy i informacje finansowe, jest zasadniczo uważane za nielegalne. Zanim rozpoczniesz proces scrapingu, upewnij się, że znasz wytyczne witryny. Upewnij się, że nie pobierasz danych, które nie są publicznie dostępne.
Czy Scraping Browser jest darmowym narzędziem?
Nie, Scraping Browser jest usługą płatną. Rejestrując się na bezpłatny okres próbny, otrzymujesz kredyt w wysokości 5 USD. Płatne pakiety zaczynają się od 15 USD za GB + 0,1 USD za godzinę. Można również skorzystać z opcji Pay As You Go, gdzie koszt to 20 USD za GB + 0,1 USD za godzinę.
Jaka jest różnica między przeglądarkami do scrapingu a przeglądarkami bezgłowymi?
Scraping Browser to zaawansowana przeglądarka, która ma graficzny interfejs użytkownika (GUI). Przeglądarki bezgłowe nie mają interfejsu graficznego. Przeglądarki bezgłowe, takie jak Selenium, są wykorzystywane do automatyzacji przeglądania stron internetowych, ale czasami ich działanie jest ograniczone, gdyż muszą radzić sobie z kodami CAPTCHA i wykrywaniem botów.
Podsumowanie
Jak widać, Scraping Browser upraszcza proces pozyskiwania danych ze stron internetowych. Jest łatwiejszy w obsłudze niż narzędzia takie jak Selenium. Dzięki intuicyjnemu interfejsowi i dobrej dokumentacji, nawet osoby bez doświadczenia w programowaniu mogą korzystać z tej przeglądarki. Narzędzie to posiada funkcje odblokowywania, niedostępne w innych programach do scrapingu, co czyni je skutecznym dla każdego, kto chce zautomatyzować ten proces.
Możesz również dowiedzieć się, jak zapobiegać pobieraniu treści z Twojej witryny przez wtyczki ChatGPT.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.