

Interesuje Cię analiza danych przy użyciu języka naturalnego? Dowiedz się, jak to zrobić, korzystając z biblioteki Pythona PandasAI.
W świecie, w którym dane mają kluczowe znaczenie, ich zrozumienie i analiza jest niezbędna. Jednak tradycyjna analiza danych może być złożona. I tu właśnie wkracza PandasAI. Upraszcza analizę danych, umożliwiając komunikację z danymi przy użyciu języka naturalnego.
Pandas AI działa poprzez przekształcanie Twoich pytań w kod do analizy danych. Opiera się na popularnych pandach z biblioteki Pythona. PandyAI to biblioteka Pythona, która rozszerza pandy, dobrze znane narzędzie do analizy i manipulacji danymi, o funkcje generatywnej sztucznej inteligencji. Ma raczej uzupełniać pandy, niż je zastępować.
PandasAI wprowadza aspekt konwersacyjny do pand (a także innych powszechnie używanych bibliotek analizy danych), umożliwiając interakcję z danymi za pomocą zapytań w języku naturalnym.
Ten samouczek przeprowadzi Cię przez etapy konfigurowania sztucznej inteligencji Pand, używania jej z zestawem danych ze świata rzeczywistego, tworzenia wykresów, odkrywania skrótów oraz odkrywania mocnych i ograniczeń tego potężnego narzędzia.
Po jego ukończeniu będziesz mógł łatwiej i intuicyjnie przeprowadzić analizę danych, korzystając z języka naturalnego.
Odkryjmy więc fascynujący świat analizy danych w języku naturalnym za pomocą Pandas AI!
Spis treści:
Konfigurowanie środowiska
Aby rozpocząć pracę z PandasAI, należy zacząć od zainstalowania biblioteki PandasAI.
W tym projekcie używam Jupyter Notebook. Ale możesz użyć Google Collab lub VS Code zgodnie ze swoimi wymaganiami.
Jeśli planujesz używać modeli dużych języków Open AI (LLM), ważne jest również zainstalowanie pakietu SDK Open AI Python SDK, aby zapewnić płynne działanie.
# Installing Pandas AI !pip install pandas-ai # Pandas AI uses OpenAI's language models, so you need to install the OpenAI Python SDK !pip install openai
Teraz zaimportujmy wszystkie niezbędne biblioteki:
# Importing necessary libraries import pandas as pd import numpy as np # Importing PandasAI and its components from pandasai import PandasAI, SmartDataframe from pandasai.llm.openai import OpenAI
Kluczowym aspektem analizy danych przy użyciu PandasAI jest klucz API. To narzędzie obsługuje kilka modeli dużych języków (LLM) i LangChains, które służą do generowania kodu na podstawie zapytań w języku naturalnym. Dzięki temu analiza danych jest bardziej dostępna i przyjazna dla użytkownika.
PandasAI jest wszechstronny i może współpracować z różnymi typami modeli. Należą do nich modele Hugging Face, Azure OpenAI, Google PALM i Google VertexAI. Każdy z tych modeli ma swoje mocne strony, zwiększając możliwości PandasAI.
Pamiętaj, aby korzystać z tych modeli, będziesz potrzebować odpowiednich kluczy API. Klucze te uwierzytelniają Twoje żądania i pozwalają wykorzystać moc tych zaawansowanych modeli językowych w zadaniach związanych z analizą danych. Dlatego pamiętaj, aby mieć pod ręką klucze API podczas konfigurowania PandasAI dla swoich projektów.
Możesz pobrać klucz API i wyeksportować go jako zmienną środowiskową.
W następnym kroku dowiesz się, jak używać PandasAI z różnymi typami dużych modeli językowych (LLM) z OpenAI i Hugging Face Hub.
Korzystanie z modeli wielkojęzykowych
Możesz wybrać LLM, tworząc jego instancję i przekazując go do konstruktora SmartDataFrame lub SmartDatalake, albo możesz określić go w pliku pandasai.json.
Jeśli model oczekuje jednego lub więcej parametrów, możesz przekazać je konstruktorowi lub określić w pliku pandasai.json w parametrze llm_options w następujący sposób:
{
"llm": "OpenAI",
"llm_options": {
"api_token": "API_TOKEN_GOES_HERE"
}
}
Jak korzystać z modeli OpenAI?
Aby korzystać z modeli OpenAI, musisz posiadać klucz API OpenAI. Możesz dostać jeden Tutaj.
Gdy już posiadasz klucz API, możesz go użyć do utworzenia instancji obiektu OpenAI:
#We have imported all necessary libraries in privious step
llm = OpenAI(api_token="my-api-key")
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Nie zapomnij zastąpić „my-api-key” oryginalnym kluczem API
Alternatywnie możesz ustawić zmienną środowiskową OPENAI_API_KEY i utworzyć instancję obiektu OpenAI bez przekazywania klucza API:
# Set the OPENAI_API_KEY environment variable
llm = OpenAI() # no need to pass the API key, it will be read from the environment variable
pandas_ai = SmartDataframe("data.csv", config={"llm": llm})
Jeśli znajdujesz się za jawnym serwerem proxy, możesz określić openai_proxy podczas tworzenia instancji obiektu OpenAI lub ustawić zmienną środowiskową OPENAI_PROXY tak, aby przechodziła.
Ważna uwaga: podczas korzystania z biblioteki PandasAI do analizy danych za pomocą klucza API ważne jest śledzenie wykorzystania tokena w celu zarządzania kosztami.
Zastanawiasz się, jak to zrobić? Po prostu uruchom następujący kod licznika tokenów, aby uzyskać jasny obraz wykorzystania tokena i odpowiednich opłat. W ten sposób możesz efektywnie zarządzać swoimi zasobami i uniknąć niespodzianek w rozliczeniach.
Możesz policzyć liczbę tokenów używanych przez zachętę w następujący sposób:
"""Example of using PandasAI with a pandas dataframe"""
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
from pandasai.helpers.openai_info import get_openai_callback
import pandas as pd
llm = OpenAI()
# conversational=False is supposed to display lower usage and cost
df = SmartDataframe("data.csv", {"llm": llm, "conversational": False})
with get_openai_callback() as cb:
response = df.chat("Calculate the sum of the gdp of north american countries")
print(response)
print(cb)
Otrzymasz takie wyniki:
# The sum of the GDP of North American countries is 19,294,482,071,552. # Tokens Used: 375 # Prompt Tokens: 210 # Completion Tokens: 165 # Total Cost (USD): $ 0.000750
Jeśli masz ograniczony kredyt, nie zapomnij zapisać całkowitego kosztu!
Jak korzystać z modeli przytulania twarzy?
Aby korzystać z modeli HuggingFace musisz posiadać klucz API HuggingFace. Możesz utworzyć konto HuggingFace Tutaj i uzyskaj klucz API Tutaj.
Gdy już posiadasz klucz API, możesz go użyć do utworzenia instancji jednego z modeli HuggingFace.
W tej chwili PandasAI obsługuje następujące modele HuggingFace:
- Starcoder: bigcode/starcoder
- Falcon: tiiuae/falcon-7b-instruktaż
from pandasai.llm import Starcoder, Falcon
llm = Starcoder(api_token="my-huggingface-api-key")
# or
llm = Falcon(api_token="my-huggingface-api-key")
df = SmartDataframe("data.csv", config={"llm": llm})
Alternatywnie możesz ustawić zmienną środowiskową HUGGINGFACE_API_KEY i utworzyć instancję obiektu HuggingFace bez przekazywania klucza API:
from pandasai.llm import Starcoder, Falcon
llm = Starcoder() # no need to pass the API key, it will be read from the environment variable
# or
llm = Falcon() # no need to pass the API key, it will be read from the environment variable
df = SmartDataframe("data.csv", config={"llm": llm})
Starcoder i Falcon to modele LLM dostępne w Hugging Face.
Pomyślnie skonfigurowaliśmy nasze środowisko i zbadaliśmy, jak używać modeli LLM OpenAI i Hugging Face. Teraz przejdźmy dalej w naszej podróży związanej z analizą danych.
Wykorzystamy zbiór danych Big Mart Sales, który zawiera informacje o sprzedaży różnych produktów w różnych placówkach Big Mart. Zbiór danych składa się z 12 kolumn i 8524 wierszy. Link otrzymasz na końcu artykułu.
Analiza danych za pomocą PandasAI
Teraz, gdy pomyślnie zainstalowaliśmy i zaimportowaliśmy wszystkie niezbędne biblioteki, przejdźmy do ładowania naszego zestawu danych.
Załaduj zestaw danych
Możesz wybrać LLM, tworząc jego instancję i przekazując go do SmartDataFrame. Link do zbioru danych znajdziesz na końcu artykułu.
#Load the dataset from device path = r"D:\Pandas AI\Train.csv" df = SmartDataframe(path)
Użyj modelu LLM OpenAI
Po załadowaniu naszych danych. Zamierzam użyć modelu LLM OpenAI do korzystania z PandasAI
llm = OpenAI(api_token="API_Key") pandas_ai = PandasAI(llm, conversational=False)
Wszystko dobrze! Spróbujmy teraz użyć podpowiedzi.
Wydrukuj pierwsze 6 wierszy naszego zbioru danych
Spróbujmy załadować pierwsze 6 wierszy, podając instrukcje:
Result = pandas_ai(df, "Show the first 6 rows of data in tabular form") Result
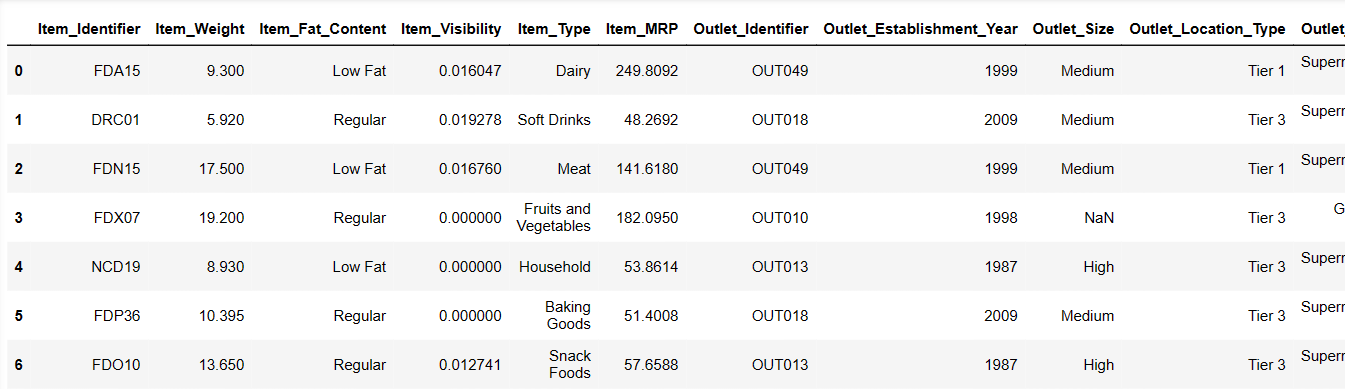 Pierwsze 6 wierszy ze zbioru danych
Pierwsze 6 wierszy ze zbioru danych
To było naprawdę szybkie! Rozumiemy nasz zbiór danych.
Generowanie statystyk opisowych DataFrame
# To get descriptive statistics Result = pandas_ai(df, "Show the description of data in tabular form") Result
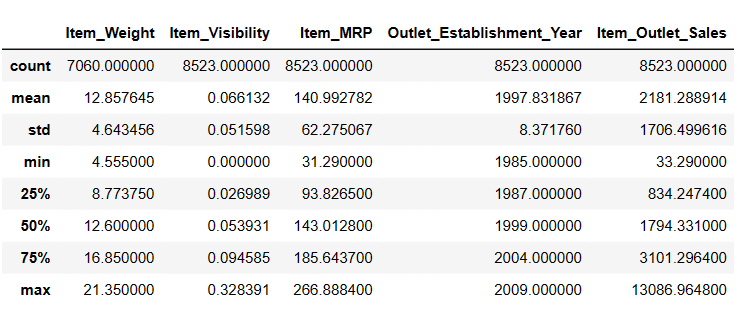 Opis
Opis
W Item_Weigth znajduje się 7060 wartości; może brakuje jakichś wartości.
Znajdź brakujące wartości
Istnieją dwa sposoby znajdowania brakujących wartości za pomocą Pandas AI.
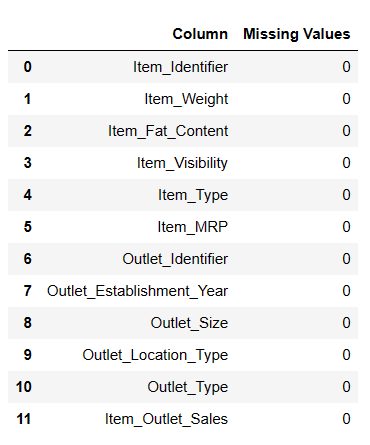
#Find missing values Result = pandas_ai(df, "Show the missing values of data in tabular form") Result
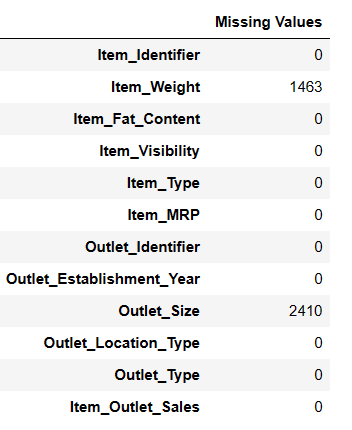 Znajdowanie brakujących wartości
Znajdowanie brakujących wartości
# Skrót do czyszczenia danych
df = SmartDataframe('data.csv')
df.clean_data()
Ten skrót spowoduje wyczyszczenie danych w ramce danych.
Teraz uzupełnijmy brakujące wartości null.
Uzupełnij brakujące wartości
#Fill Missing values result = pandas_ai(df, "Fill Item Weight with median and Item outlet size null values with mode and Show the missing values of data in tabular form") result
 Wypełnione wartości null
Wypełnione wartości null
Jest to przydatna metoda wypełniania wartości null, ale podczas wypełniania wartości null napotkałem pewne problemy.
# Skrót do wypełniania wartości pustych
df = SmartDataframe('data.csv')
df.impute_missing_values()
Ten skrót spowoduje przypisanie brakujących wartości do ramki danych.
Usuń wartości zerowe
Jeśli chcesz usunąć wszystkie wartości null z pliku df, możesz wypróbować tę metodę.
result = pandas_ai(df, "Drop the row with missing values with inplace=True") result
Analiza danych jest niezbędna do identyfikowania trendów, zarówno krótko-, jak i długoterminowych, co może być nieocenione dla przedsiębiorstw, rządów, badaczy i osób prywatnych.
Spróbujmy znaleźć ogólny trend sprzedaży na przestrzeni lat od jej powstania.
Znalezienie trendu sprzedażowego
# finding trend in sales result = pandas_ai(df, "What is the overall trend in sales over the years since outlet establishment?") result
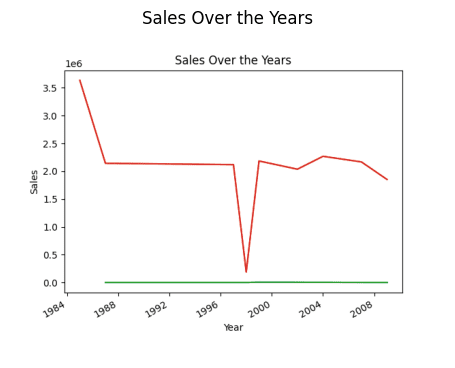 Sprzedaż w ciągu roku (wykres liniowy)
Sprzedaż w ciągu roku (wykres liniowy)
Początkowy proces tworzenia fabuły był nieco powolny, ale po ponownym uruchomieniu jądra i uruchomieniu wszystkiego, działał szybciej.
# Skrót do wykresów liniowych
df.plot_line_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Ten skrót spowoduje wykreślenie wykresu liniowego ramki danych.
Być może zastanawiasz się, dlaczego trend jest spadkowy. Dzieje się tak dlatego, że nie mamy danych za lata 1989–1994.
Znalezienie roku najwyższej sprzedaży
Teraz dowiedzmy się, który rok ma najwyższą sprzedaż.
# finding year of highest sales result = pandas_ai(df, "Explain which years have highest sales") result

Zatem rokiem najwyższej sprzedaży jest rok 1985.
Chcę jednak dowiedzieć się, który typ przedmiotu generuje najwyższą średnią sprzedaż, a który typ generuje najniższą średnią sprzedaż.
Najwyższa i najniższa średnia sprzedaż
# finding highest and lowest average sale result = pandas_ai(df, "Which item type generates the highest average sales, and which one generates the lowest?") result

Produkty Starchy Foods mają najwyższą średnią sprzedaż, a inne mają najniższą średnią sprzedaż. Jeśli nie chcesz, aby inne sprzedaże były najniższe, możesz poprawić szybkość sprzedaży zgodnie ze swoimi potrzebami.
Wspaniały! Teraz chcę sprawdzić rozkład sprzedaży w różnych punktach sprzedaży.
Dystrybucja sprzedaży w różnych punktach sprzedaży
Istnieją cztery rodzaje sklepów: Supermarket Typ 1/2/3 i Sklepy spożywcze.
# distribution of sales across different outlet types since establishment response = pandas_ai(df, "Visualize the distribution of sales across different outlet types since establishment using bar plot, plot size=(13,10)") response
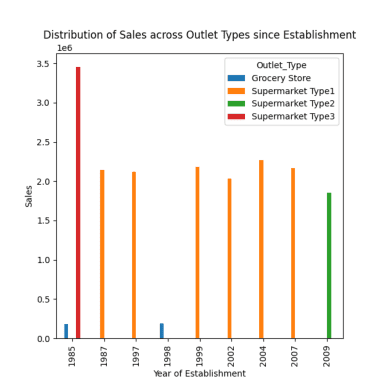 Dystrybucja sprzedaży w różnych punktach sprzedaży
Dystrybucja sprzedaży w różnych punktach sprzedaży
Jak zauważono w poprzednich podpowiedziach, szczyt sprzedaży przypadł na rok 1985, a wykres ten ukazuje najwyższą sprzedaż w roku 1985 w supermarketach typu 3.
# Skrót do wykresu słupkowego
df = SmartDataframe('data.csv')
df.plot_bar_chart(x = ['a', 'b', 'c'], y = [1, 2, 3])
Ten skrót spowoduje wykreślenie wykresu słupkowego ramki danych.
# Skrót do wykresu histogramu
df = SmartDataframe('data.csv')
df.plot_histogram(column = 'a')
Ten skrót spowoduje wykreślenie histogramu ramki danych.
Teraz dowiedzmy się, jaka jest średnia sprzedaż produktów o „niskiej zawartości tłuszczu” i „regularnej” zawartości tłuszczu.
Znajdź średnią sprzedaż produktów zawierających tłuszcz
# finding index of a row using value of a column result = pandas_ai(df, "What is the average sales for the items with 'Low Fat' and 'Regular' item fat content?") result
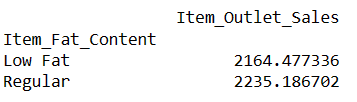
Pisanie takich podpowiedzi pozwala porównać dwa lub więcej produktów.
Średnia sprzedaż dla każdego typu przedmiotu
Chcę porównać wszystkie produkty z ich średnią sprzedażą.
#Average Sales for Each Item Type result = pandas_ai(df, "What are the average sales for each item type over the past 5 years?, use pie plot, size=(6,6)") result
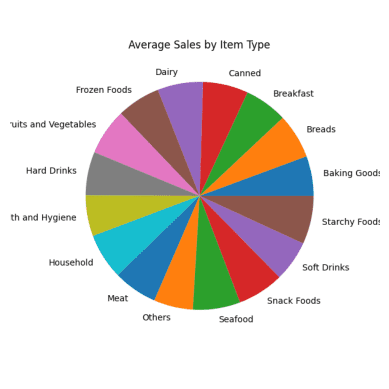 Wykres kołowy średniej sprzedaży
Wykres kołowy średniej sprzedaży
Wszystkie sekcje wykresu kołowego wyglądają podobnie, ponieważ mają prawie takie same dane dotyczące sprzedaży.
# Skrót do wykresu kołowego
df.plot_pie_chart(labels = ['a', 'b', 'c'], values = [1, 2, 3])
Ten skrót spowoduje wykreślenie wykresu kołowego ramki danych.
5 najlepiej sprzedających się typów przedmiotów
Chociaż porównaliśmy już wszystkie produkty na podstawie średniej sprzedaży, teraz chciałbym zidentyfikować 5 produktów o najwyższej sprzedaży.
#Finding top 5 highest selling items result = pandas_ai(df, "What are the top 5 highest selling item type based on average sells? Write in tablular form") result
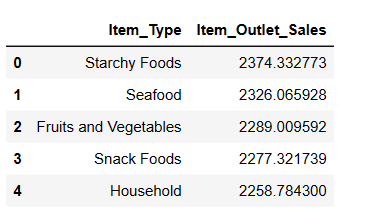
Zgodnie z oczekiwaniami, Starchy Foods jest najlepiej sprzedającym się produktem na podstawie średniej sprzedaży.
5 najniżej sprzedających się typów przedmiotów
result = pandas_ai(df, "What are the top 5 lowest selling item type based on average sells?") result
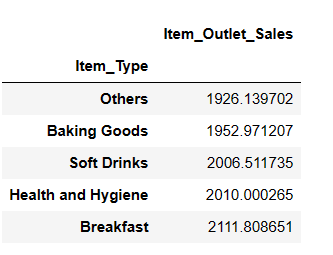
Możesz być zaskoczony, widząc napoje bezalkoholowe w kategorii najniżej sprzedającej się. Należy jednak zauważyć, że dane te obejmują tylko rok 2008, a trend w zakresie napojów bezalkoholowych nasilił się kilka lat później.
Sprzedaż kategorii produktów
Tutaj użyłem słowa „kategoria produktu” zamiast „typ przedmiotu”, a PandasAI nadal tworzyła wykresy, pokazując, jak rozumie podobne słowa.
result = pandas_ai(df, "Give a stacked large size bar chart of the sales of the various product categories for the last FY") result
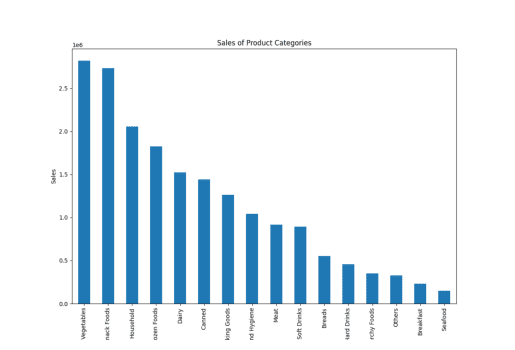 Sprzedaż typu przedmiotu
Sprzedaż typu przedmiotu
Możesz znaleźć nasze pozostałe skróty Tutaj.
Możesz zauważyć, że kiedy piszemy zachętę i przekazujemy instrukcje PandasAI, zapewnia ona wyniki wyłącznie w oparciu o tę konkretną zachętę. Nie analizuje poprzednich podpowiedzi, aby zapewnić dokładniejsze odpowiedzi.
Jednak przy pomocy agenta czatu możesz również osiągnąć tę funkcjonalność.
Agent czatu
Dzięki agentowi na czacie możesz prowadzić dynamiczne rozmowy, podczas których agent zachowuje kontekst przez całą dyskusję. Umożliwia to bardziej interaktywną i znaczącą wymianę zdań.
Kluczowe funkcje umożliwiające tę interakcję obejmują przechowywanie kontekstu, dzięki któremu agent zapamiętuje historię rozmów, co pozwala na płynne interakcje uwzględniające kontekst. Możesz skorzystać z metody pytań wyjaśniających, aby poprosić o wyjaśnienie dowolnego aspektu rozmowy, upewniając się, że w pełni rozumiesz przekazane informacje.
Co więcej, dostępna jest metoda wyjaśniająca, która pozwala uzyskać szczegółowe wyjaśnienia, w jaki sposób agent doszedł do konkretnego rozwiązania lub odpowiedzi, zapewniając przejrzystość i wgląd w proces podejmowania decyzji przez agenta.
Możesz inicjować rozmowy, szukać wyjaśnień i szukać wyjaśnień, aby poprawić swoje interakcje z agentem czatu!
from pandasai import Agent
agent = Agent(df, config={"llm": llm}, memory_size=10)
result = agent.chat("Which are top 5 items with highest MRP")
result
W przeciwieństwie do SmartDataframe czy SmartDatalake, agent będzie na bieżąco śledził stan rozmowy i będzie mógł odpowiadać na rozmowy wieloetapowe.
Przejdźmy do zalet i ograniczeń PandasAI
Zalety PandasAI
Korzystanie z Pandas AI ma kilka zalet, które czynią go cennym narzędziem do analizy danych, takich jak:
- Dostępność: PandasAI upraszcza analizę danych, czyniąc je dostępnymi dla szerokiego grona użytkowników. Każdy, niezależnie od wykształcenia technicznego, może za jego pomocą wyciągać wnioski z danych i odpowiadać na pytania biznesowe.
- Zapytania w języku naturalnym: Możliwość bezpośredniego zadawania pytań i otrzymywania odpowiedzi z danych za pomocą zapytań w języku naturalnym sprawia, że eksploracja i analiza danych są bardziej przyjazne dla użytkownika. Ta funkcja umożliwia efektywną interakcję z danymi nawet użytkownikom nietechnicznym.
- Funkcja czatu z agentem: Funkcja czatu umożliwia użytkownikom interaktywną interakcję z danymi, podczas gdy funkcja czatu z agentem wykorzystuje historię poprzednich rozmów, aby zapewnić odpowiedzi zależne od kontekstu. Promuje to dynamiczne i konwersacyjne podejście do analizy danych.
- Wizualizacja danych: PandasAI zapewnia szereg opcji wizualizacji danych, w tym mapę cieplną, wykresy punktowe, wykresy słupkowe, wykresy kołowe, wykresy liniowe i inne. Wizualizacje te pomagają zrozumieć i zaprezentować wzorce i trendy danych.
- Skróty oszczędzające czas: dostępność skrótów i funkcji oszczędzających czas usprawnia proces analizy danych, pomagając użytkownikom pracować wydajniej i efektywniej.
- Zgodność plików: PandasAI obsługuje różne formaty plików, w tym CSV, Excel, Arkusze Google i inne. Ta elastyczność pozwala użytkownikom pracować z danymi z różnych źródeł i formatów.
- Niestandardowe podpowiedzi: użytkownicy mogą tworzyć niestandardowe podpowiedzi, korzystając z prostych instrukcji i kodu Pythona. Ta funkcja umożliwia użytkownikom dostosowywanie interakcji z danymi do konkretnych potrzeb i zapytań.
- Zapisz zmiany: Możliwość zapisywania zmian wprowadzonych w ramkach danych gwarantuje, że Twoja praca zostanie zachowana, a Ty możesz w dowolnym momencie ponownie przeglądać i udostępniać swoje analizy.
- Niestandardowe odpowiedzi: Opcja tworzenia niestandardowych odpowiedzi umożliwia użytkownikom definiowanie konkretnych zachowań lub interakcji, dzięki czemu narzędzie jest jeszcze bardziej wszechstronne.
- Integracja modelu: PandasAI obsługuje różne modele językowe, w tym modele z Hugging Face, Azure, Google Palm, Google VertexAI i LangChain. Integracja ta zwiększa możliwości narzędzia i umożliwia zaawansowane przetwarzanie i zrozumienie języka naturalnego.
- Wbudowana obsługa LangChain: Wbudowana obsługa modeli LangChain dodatkowo rozszerza zakres dostępnych modeli i funkcjonalności, zwiększając głębokość analizy i wniosków, które można wyciągnąć z danych.
- Zrozumienie nazw: PandasAI demonstruje zdolność zrozumienia korelacji między nazwami kolumn a terminologią z życia codziennego. Na przykład, nawet jeśli w podpowiedziach użyjesz terminów takich jak „kategoria produktu” zamiast „typ produktu”, narzędzie może nadal dostarczać trafne i dokładne wyniki. Ta elastyczność w rozpoznawaniu synonimów i mapowaniu ich do odpowiednich kolumn danych zwiększa wygodę użytkownika i możliwość dostosowania narzędzia do zapytań w języku naturalnym.
Chociaż PandasAI oferuje kilka zalet, wiąże się również z pewnymi ograniczeniami i wyzwaniami, o których użytkownicy powinni wiedzieć:
Ograniczenia PandasAI
Oto kilka ograniczeń, które zaobserwowałem:
- Wymagania dotyczące klucza API: Aby korzystać z PandasAI, niezbędne jest posiadanie klucza API. Jeśli nie masz wystarczających środków na swoim koncie OpenAI, możesz nie być w stanie korzystać z usługi. Warto jednak zauważyć, że OpenAI zapewnia nowym użytkownikom kredyt w wysokości 5 dolarów, dzięki czemu jest dostępny dla nowych użytkowników platformy.
- Czas przetwarzania: Czasami usługa może doświadczać opóźnień w dostarczaniu wyników, które można przypisać dużemu wykorzystaniu lub obciążeniu serwera. Użytkownicy powinni być przygotowani na potencjalny czas oczekiwania podczas wysyłania zapytań do usługi.
- Interpretacja podpowiedzi: choć za pomocą podpowiedzi można zadawać pytania, zdolność systemu do wyjaśniania odpowiedzi może nie być w pełni rozwinięta, a jakość wyjaśnień może być różna. Ten aspekt PandasAI może zostać ulepszony w przyszłości wraz z dalszym rozwojem.
- Czułość podpowiedzi: użytkownicy muszą zachować ostrożność podczas tworzenia podpowiedzi, ponieważ nawet niewielkie zmiany mogą prowadzić do różnych rezultatów. Ta wrażliwość na frazowanie i strukturę podpowiedzi może mieć wpływ na spójność wyników, zwłaszcza podczas pracy z wykresami danych lub bardziej złożonymi zapytaniami.
- Ograniczenia dotyczące złożonych podpowiedzi: PandasAI może nie obsługiwać bardzo złożonych podpowiedzi lub zapytań tak skutecznie, jak prostsze. Użytkownicy powinni mieć świadomość złożoności swoich pytań i upewnić się, że narzędzie jest odpowiednie dla ich konkretnych potrzeb.
- Niespójne zmiany ramek danych: Użytkownicy zgłaszali problemy z wprowadzaniem zmian w ramkach DataFrame, takie jak wypełnianie wartości null lub usuwanie wierszy z wartościami null, nawet w przypadku określenia „Inplace=True”. Ta niespójność może być frustrująca dla użytkowników próbujących modyfikować swoje dane.
- Zmienne wyniki: Podczas ponownego uruchamiania jądra lub ponownego uruchamiania monitów możliwe jest otrzymanie różnych wyników lub interpretacji danych z poprzednich uruchomień. Ta zmienność może stanowić wyzwanie dla użytkowników, którzy wymagają spójnych i powtarzalnych wyników. Nie dotyczy wszystkich monitów.
Możesz pobrać zbiór danych Tutaj.
Kod jest dostępny na GitHub.
Wniosek
PandasAI oferuje przyjazne dla użytkownika podejście do analizy danych, dostępne nawet dla osób nieposiadających rozbudowanych umiejętności kodowania.
W tym artykule opisałem, jak skonfigurować i wykorzystać PandasAI do analizy danych, w tym do tworzenia wykresów, obsługi wartości null i korzystania z funkcji czatu z agentami.
Zapisz się do naszego newslettera, aby otrzymywać więcej artykułów informacyjnych. Być może zainteresuje Cię poznanie modeli sztucznej inteligencji do tworzenia generatywnej sztucznej inteligencji.
Czy ten artykuł był pomocny?
Dziękujemy za twoją opinię!