
W dziedzinie nowoczesnej sztucznej inteligencji (AI) uczenie się przez wzmacnianie (RL) jest jednym z najfajniejszych tematów badawczych. Twórcy sztucznej inteligencji i uczenia maszynowego (ML) koncentrują się również na praktykach RL, aby improwizować inteligentne aplikacje lub opracowywane przez siebie narzędzia.
Uczenie maszynowe to podstawa wszystkich produktów AI. Ludzi programiści używają różnych metodologii ML do trenowania swoich inteligentnych aplikacji, gier itp. ML to bardzo zróżnicowana dziedzina, a różne zespoły programistyczne oferują nowatorskie metody szkolenia maszyny.
Jedną z takich lukratywnych metod uczenia maszynowego jest głębokie uczenie się ze wzmocnieniem. Tutaj karzesz niepożądane zachowania maszyny i nagradzasz pożądane działania inteligentnej maszyny. Eksperci uważają, że ta metoda uczenia maszynowego zmusi sztuczną inteligencję do uczenia się na podstawie własnych doświadczeń.
Kontynuuj czytanie tego ostatecznego przewodnika po metodach uczenia się przez wzmacnianie dla inteligentnych aplikacji i maszyn, jeśli rozważasz karierę w sztucznej inteligencji i uczeniu maszynowym.
Spis treści:
Co to jest uczenie się przez wzmacnianie w uczeniu maszynowym?
RL to nauczanie modeli uczenia maszynowego programów komputerowych. Następnie aplikacja może podejmować szereg decyzji w oparciu o modele uczenia się. Oprogramowanie uczy się osiągać cel w potencjalnie złożonym i niepewnym środowisku. W tego rodzaju modelu uczenia maszynowego sztuczna inteligencja ma do czynienia ze scenariuszem podobnym do gry.
Aplikacja AI wykorzystuje metody prób i błędów, aby wymyślić kreatywne rozwiązanie problemu. Gdy aplikacja AI nauczy się odpowiednich modeli ML, instruuje maszynę, którą kontroluje, aby wykonała pewne zadania, których chce programista.
Na podstawie prawidłowej decyzji i wykonania zadania AI otrzymuje nagrodę. Jeśli jednak sztuczna inteligencja dokona niewłaściwych wyborów, narażona jest na kary, takie jak utrata punktów nagrody. Ostatecznym celem aplikacji AI jest zgromadzenie maksymalnej liczby punktów nagrody, aby wygrać grę.
Programista aplikacji AI ustala zasady gry lub politykę nagród. Programista zapewnia również problem, który AI musi rozwiązać. W przeciwieństwie do innych modeli ML, program AI nie otrzymuje żadnej wskazówki od programisty.
Sztuczna inteligencja musi wymyślić, jak rozwiązywać wyzwania w grze, aby zdobyć maksymalne nagrody. Aplikacja może wykorzystywać metody prób i błędów, próby losowe, umiejętności korzystania z superkomputera i wyrafinowane taktyki procesu myślowego, aby znaleźć rozwiązanie.
Musisz wyposażyć program AI w potężną infrastrukturę obliczeniową i połączyć jego system myślenia z różnymi równoległymi i historycznymi rozgrywkami. Następnie sztuczna inteligencja może wykazać krytyczną i wysokopoziomową kreatywność, której ludzie nie mogą sobie wyobrazić.
Popularne przykłady uczenia się przez wzmacnianie
#1. Pokonanie najlepszego gracza Human Go
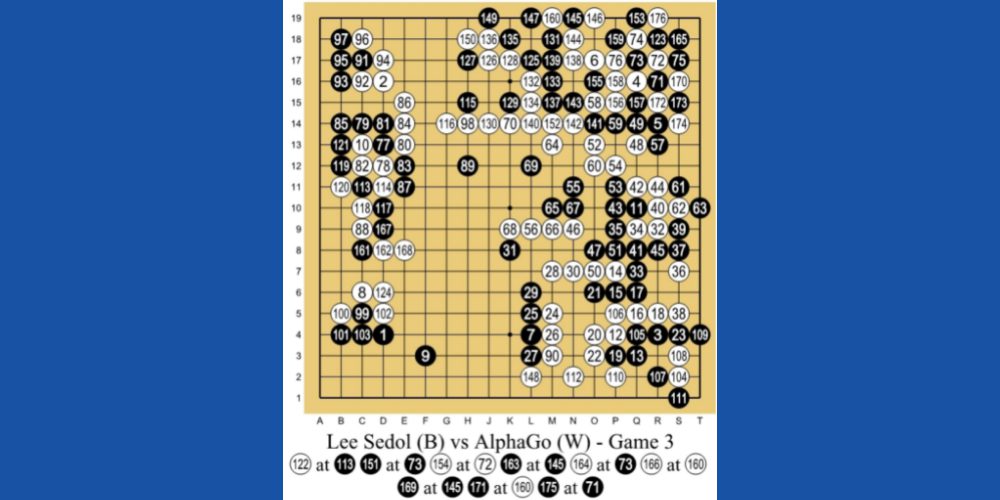
AlphaGo AI firmy DeepMind Technologies, spółki zależnej Google, jest jednym z wiodących przykładów uczenia maszynowego opartego na RL. AI gra w chińską grę planszową o nazwie Go. Jest to gra mająca 3000 lat, która skupia się na taktyce i strategiach.
Programiści zastosowali metodę nauczania RL dla AlphaGo. Zagrał tysiące sesji gry Go z ludźmi i sobą. Następnie, w 2016 roku, pokonał w pojedynku jeden na jednego najlepszego gracza na świecie w go, Lee Se-dola.
#2. Robotyka w świecie rzeczywistym
Ludzie od dawna używają robotyki na liniach produkcyjnych, gdzie zadania są wcześniej zaplanowane i powtarzalne. Ale jeśli potrzebujesz stworzyć robota ogólnego przeznaczenia do rzeczywistego świata, w którym działania nie są wcześniej zaplanowane, jest to wielkie wyzwanie.
Ale sztuczna inteligencja z obsługą uczenia się przez wzmacnianie może odkryć gładką, nawigacyjną i krótką trasę między dwoma lokalizacjami.
#3. Pojazdy autonomiczne
Badacze pojazdów autonomicznych powszechnie stosują metodę RL, aby uczyć swoich SI w zakresie:
- Dynamiczne ścieżki
- Optymalizacja trajektorii
- Planowanie ruchu, takie jak parkowanie i zmiana pasa
- Sterowniki optymalizujące, (elektroniczna jednostka sterująca) ECU, (mikrokontrolery) MCU itp.
- Nauka oparta na scenariuszach na autostradach
#4. Zautomatyzowane systemy chłodzenia

AI oparte na RL może pomóc zminimalizować zużycie energii przez systemy chłodzenia w gigantycznych budynkach biurowych, centrach biznesowych, centrach handlowych i, co najważniejsze, centrach danych. AI zbiera dane z tysięcy czujników ciepła.
Gromadzi również dane dotyczące działalności ludzi i maszyn. Na podstawie tych danych sztuczna inteligencja może przewidzieć przyszły potencjał wytwarzania ciepła i odpowiednio włączać i wyłączać systemy chłodzenia w celu oszczędzania energii.
Jak skonfigurować model uczenia się wzmacniania
Możesz skonfigurować model RL na podstawie następujących metod:
#1. Oparte na zasadach
Takie podejście umożliwia programiście sztucznej inteligencji znalezienie idealnej polityki dla maksymalnych nagród. Tutaj programista nie korzysta z funkcji wartości. Po ustawieniu metody opartej na zasadach, agent uczenia się wzmacniającego próbuje zastosować zasady, aby działania, które wykonuje na każdym kroku, umożliwiały sztucznej inteligencji maksymalizację punktów nagrody.
Istnieją przede wszystkim dwa rodzaje polis:
#1. Deterministyczny: polityka może generować te same działania w dowolnym stanie.
#2. Stochastyczny: Wytworzone działania są określane przez prawdopodobieństwo wystąpienia.
#2. Oparte na wartości
Wręcz przeciwnie, podejście oparte na wartości pomaga programiście znaleźć optymalną funkcję wartości, która jest maksymalną wartością w ramach polityki w danym stanie. Po zastosowaniu agent RL oczekuje długoterminowego zwrotu w jednym lub wielu stanach w ramach wspomnianej polityki.
#3. Oparte na modelu
W podejściu RL opartym na modelu programista AI tworzy wirtualny model środowiska. Następnie agent RL porusza się po środowisku i uczy się od niego.
Rodzaje uczenia się przez wzmacnianie
#1. Pozytywne uczenie się przez wzmacnianie (PRL)
Pozytywne uczenie się oznacza dodanie pewnych elementów, aby zwiększyć prawdopodobieństwo, że oczekiwane zachowanie powtórzy się. Ta metoda uczenia się pozytywnie wpływa na zachowanie agenta RL. PRL poprawia również siłę niektórych zachowań twojej sztucznej inteligencji.
Wzmocnienie uczenia się typu PRL powinno przygotowywać sztuczną inteligencję do przystosowania się do zmian przez długi czas. Ale wstrzykiwanie zbyt dużej ilości pozytywnego uczenia się może prowadzić do przeciążenia stanami, które mogą zmniejszyć wydajność sztucznej inteligencji.

#2. Uczenie negatywnego wzmocnienia (NRL)
Kiedy algorytm RL pomaga AI uniknąć lub zatrzymać negatywne zachowanie, uczy się od niego i poprawia swoje przyszłe działania. Nazywa się to negatywną nauką. Zapewnia sztucznej inteligencji tylko ograniczoną inteligencję, aby spełnić określone wymagania behawioralne.
Rzeczywiste przypadki użycia uczenia się przez wzmacnianie
#1. Twórcy rozwiązań eCommerce zbudowali spersonalizowane narzędzia do sugerowania produktów lub usług. Interfejs API narzędzia można połączyć z witryną zakupów online. Następnie sztuczna inteligencja będzie uczyć się od indywidualnych użytkowników i proponować niestandardowe towary i usługi.
#2. Gry wideo z otwartym światem oferują nieograniczone możliwości. Jednak za programem gry stoi program AI, który uczy się z danych wejściowych graczy i modyfikuje kod gry wideo, aby dostosować się do nieznanej sytuacji.
#3. Platformy handlu akcjami i inwestycje oparte na sztucznej inteligencji wykorzystują model RL, aby uczyć się na podstawie ruchu akcji i globalnych indeksów. W związku z tym formułują model prawdopodobieństwa, aby sugerować akcje do inwestycji lub handlu.
#4. Biblioteki wideo online, takie jak YouTube, Metacafe, Dailymotion itp., używają botów AI wyszkolonych w modelu RL, aby sugerować użytkownikom spersonalizowane filmy.
Uczenie się przez wzmacnianie vs. Nadzorowana nauka
Uczenie się przez wzmacnianie ma na celu wyszkolenie agenta AI w podejmowaniu decyzji sekwencyjnie. Krótko mówiąc, można uznać, że wyjście AI zależy od stanu obecnego wejścia. Podobnie, następne dane wejściowe algorytmu RL będą zależeć od danych wyjściowych poprzednich danych wejściowych.

Oparta na sztucznej inteligencji automatyczna maszyna grająca w szachy przeciwko ludzkiemu szachistowi jest przykładem modelu uczenia maszynowego RL.
Wręcz przeciwnie, w uczeniu nadzorowanym programista szkoli agenta AI, aby podejmował decyzje na podstawie danych wejściowych podanych na początku lub jakichkolwiek innych wstępnych danych wejściowych. Sztuczna inteligencja autonomicznej jazdy samochodem rozpoznająca obiekty środowiskowe jest doskonałym przykładem nadzorowanego uczenia się.
Uczenie się przez wzmacnianie vs. Nauka nienadzorowana
Do tej pory zrozumiałeś, że metoda RL popycha agenta AI do uczenia się na podstawie zasad modelu uczenia maszynowego. Głównie sztuczna inteligencja wykona tylko te kroki, za które otrzyma maksymalną liczbę punktów nagrody. RL pomaga sztucznej inteligencji improwizować się metodą prób i błędów.
Z drugiej strony, w nienadzorowanym uczeniu się programista AI wprowadza oprogramowanie AI z nieoznakowanymi danymi. Ponadto instruktor ML nie mówi AI nic o strukturze danych ani o tym, czego szukać w danych. Algorytm uczy się różnych decyzji, katalogując własne obserwacje na danych nieznanych zbiorach danych.
Kursy na temat wzmacniania
Teraz, gdy nauczyłeś się podstaw, oto kilka kursów online, aby nauczyć się zaawansowanego uczenia się ze wzmocnieniem. Otrzymasz również certyfikat, który możesz zaprezentować na LinkedIn lub innych platformach społecznościowych:
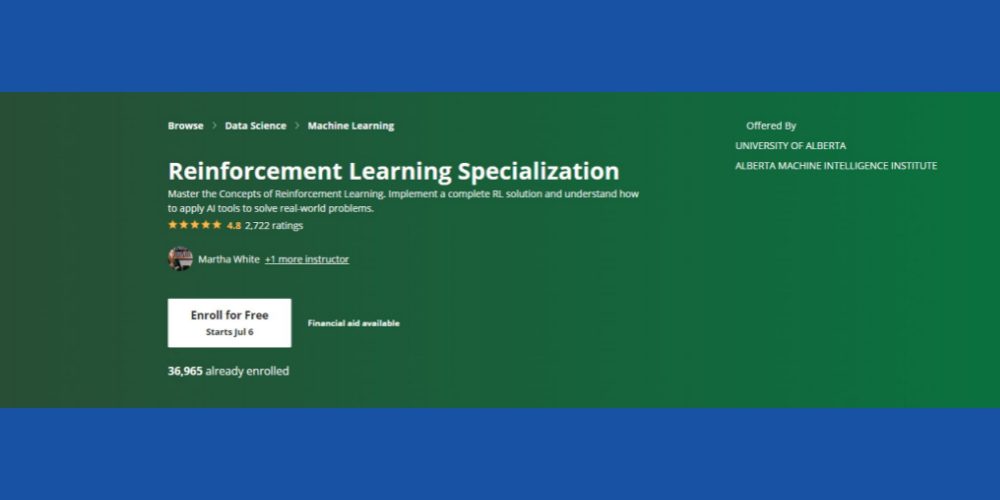
Specjalizacja uczenia się przez wzmacnianie: Coursera
Czy chcesz opanować podstawowe koncepcje uczenia się przez wzmacnianie w kontekście ML? Możesz tego spróbować Kurs Coursera RL który jest dostępny online i zawiera opcję samodzielnego uczenia się i certyfikacji. Kurs będzie dla Ciebie odpowiedni, jeśli wniesiesz następujące umiejętności jako podstawy:
- Znajomość programowania w Pythonie
- Podstawowe pojęcia statystyczne
- Możesz konwertować pseudokody i algorytmy na kody Pythona
- Doświadczenie w tworzeniu oprogramowania od dwóch do trzech lat
- Uprawnieni są również studenci II roku kierunku informatyka
Kurs ma ocenę 4,8 gwiazdki, a ponad 36 000 studentów zapisało się już na kurs na różnych kursach. Ponadto kurs obejmuje pomoc finansową pod warunkiem, że kandydat spełnia określone kryteria kwalifikacyjne Coursera.
Wreszcie, Alberta Machine Intelligence Institute na Uniwersytecie Alberta oferuje ten kurs (bez przyznania punktów). Cenionymi profesorami w dziedzinie informatyki będą służyć jako instruktorzy kursu. Po ukończeniu kursu otrzymasz certyfikat Coursera.
Nauka wzmacniania AI w Pythonie: Udemy
Jeśli interesujesz się rynkiem finansowym lub marketingiem cyfrowym i chcesz rozwijać inteligentne pakiety oprogramowania dla tych dziedzin, musisz to sprawdzić Kurs Udemy na RL. Oprócz podstawowych zasad RL, treści szkoleniowe poprowadzą Cię również w zakresie opracowywania rozwiązań RL dla reklamy online i handlu akcjami.

Niektóre godne uwagi tematy poruszane na kursie to:
- Ogólny przegląd RL
- Programowanie dynamiczne
- Moneta Carlo .a
- Metody aproksymacji
- Projekt giełdowy z RL
Do tej pory w kursie wzięło udział ponad 42 tys. studentów. Internetowy zasób edukacyjny ma obecnie 4,6-gwiazdkową ocenę, co jest imponujące. Ponadto kurs ma na celu zaspokojenie globalnej społeczności studentów, ponieważ treści edukacyjne są dostępne w języku francuskim, angielskim, hiszpańskim, niemieckim, włoskim i portugalskim.
Nauka głębokiego wzmacniania w Pythonie: Udemy
Jeśli masz ciekawość i podstawową wiedzę z zakresu głębokiego uczenia i sztucznej inteligencji, możesz spróbować tego zaawansowanego Kurs RL w Pythonie od Udemy. Z oceną 4,6 gwiazdki od studentów, jest to kolejny popularny kurs do nauki RL w kontekście AI / ML.

Kurs składa się z 12 sekcji i obejmuje następujące ważne tematy:
- OpenAI Gym i podstawowe techniki RL
- TD Lambda
- A3C
- Podstawy Theano
- Podstawy Tensorflow
- Kodowanie w Pythonie na początek
Cały kurs będzie wymagał zaangażowania 10 godzin i 40 minut. Oprócz tekstów zawiera 79 wykładów eksperckich.
Ekspert uczenia głębokiego wzmacniania: Udacity
Chcesz nauczyć się zaawansowanego uczenia maszynowego od światowych liderów AI/ML, takich jak Nvidia Deep Learning Institute i Unity? Udacity pozwala spełnić Twoje marzenie. Sprawdź to Nauka głębokiego wzmacniania kurs na eksperta ML.

Musisz jednak wywodzić się z zaawansowanego Pythona, średniozaawansowanych statystyk, teorii prawdopodobieństwa, TensorFlow, PyTorch i Keras.
Ukończenie kursu zajmie rzetelnej nauki do 4 miesięcy. Podczas kursu nauczysz się ważnych algorytmów RL, takich jak Deep Deterministic Policy Gradients (DDPG), Deep Q-Networks (DQN) itp.
Ostatnie słowa
Uczenie się przez wzmacnianie to kolejny krok w rozwoju sztucznej inteligencji. Agencje rozwoju AI i firmy IT inwestują w ten sektor, aby stworzyć niezawodne i zaufane metodologie szkolenia AI.
Chociaż RL znacznie się rozwinęło, istnieje więcej możliwości rozwoju. Na przykład oddzielni agenci RL nie dzielą się wiedzą. Dlatego, jeśli uczysz aplikację do prowadzenia samochodu, proces uczenia się spowolni. Ponieważ agenci RL, tacy jak wykrywanie obiektów, odniesienia do dróg itp., nie będą udostępniać danych.
Istnieją możliwości zainwestowania swojej kreatywności i doświadczenia w zakresie ML w takie wyzwania. Zapisanie się na kursy online pomoże Ci poszerzyć swoją wiedzę na temat zaawansowanych metod RL i ich zastosowań w rzeczywistych projektach.
Inną powiązaną metodą uczenia się są różnice między sztuczną inteligencją, uczeniem maszynowym i głębokim uczeniem.