

W tym artykule omówimy wektoryzację – technikę NLP i zrozumiemy jej znaczenie, korzystając z obszernego przewodnika po różnych typach wektoryzacji.
Omówiliśmy podstawowe koncepcje wstępnego przetwarzania NLP i czyszczenia tekstu. Przyjrzeliśmy się podstawom NLP, jego różnym zastosowaniom i technikom, takim jak tokenizacja, normalizacja, standaryzacja i czyszczenie tekstu.

Zanim omówimy wektoryzację, przyjrzyjmy się jeszcze raz, czym jest tokenizacja i czym różni się od wektoryzacji.
Spis treści:
Co to jest tokenizacja?
Tokenizacja to proces dzielenia zdań na mniejsze jednostki zwane tokenami. Token pomaga komputerom łatwo zrozumieć tekst i pracować z nim.
BYŁY. „Ten artykuł jest dobry”
Tokeny- [‘This’, ‘article’, ‘is’, ‘good’.]
Co to jest wektoryzacja?
Jak wiemy, modele i algorytmy uczenia maszynowego rozumieją dane liczbowe. Wektoryzacja to proces przekształcania danych tekstowych lub kategorycznych na wektory liczbowe. Konwertując dane na dane liczbowe, możesz dokładniej trenować swój model.
Dlaczego potrzebujemy wektoryzacji?
❇️ Tokenizacja i wektoryzacja mają różne znaczenie w przetwarzaniu języka naturalnego (NPL). Tokenizacja dzieli zdania na małe tokeny. Wektoryzacja konwertuje go na format numeryczny, aby model komputera/ML mógł go zrozumieć.
❇️ Wektoryzacja jest przydatna nie tylko do konwersji do postaci liczbowej, ale także przydatna do uchwycenia znaczenia semantycznego.
❇️ Wektoryzacja może zmniejszyć wymiarowość danych i zwiększyć ich wydajność. Może to być bardzo przydatne podczas pracy na dużym zbiorze danych.
❇️ Wiele algorytmów uczenia maszynowego wymaga wprowadzania danych liczbowych, np. sieci neuronowe, aby wektoryzacja mogła nam pomóc.
Istnieją różne rodzaje technik wektoryzacji, które zrozumiemy w tym artykule.
Torba słów
Jeśli masz kilka dokumentów lub zdań i chcesz je przeanalizować, Bag of Words upraszcza ten proces, traktując dokument jak torbę wypełnioną słowami.
Podejście oparte na worku słów może być przydatne w klasyfikacji tekstu, analizie tonacji i wyszukiwaniu dokumentów.
Załóżmy, że pracujesz nad dużą ilością tekstu. Zbiór słów pomoże Ci reprezentować dane tekstowe, tworząc słownictwo unikalnych słów w naszych danych tekstowych. Po utworzeniu słownictwa każde słowo zostanie zakodowane jako wektor w oparciu o częstotliwość (jak często każde słowo pojawia się w tekście) tych słów.
Wektory te składają się z liczb nieujemnych (0,1,2…..), które reprezentują liczbę częstotliwości w tym dokumencie.
Zbiór słów składa się z trzech kroków:
Krok 1: Tokenizacja
Podzieli dokumenty na tokeny.
Ex – (Zdanie: „Kocham pizzę i uwielbiam burgery”)
Krok 2: Unikalna separacja słów/tworzenie słownictwa
Utwórz listę wszystkich unikalnych słów, które pojawiają się w Twoich zdaniach.
[“I”, “love”, “Pizza”, “and”, “Burgers”]
Krok 3: Liczenie występowania słów/tworzenie wektorów
W tym kroku zliczymy, ile razy każde słowo zostało powtórzone ze słownika, i zapiszemy je w rzadkiej macierzy. W macierzy rzadkiej każdy wiersz wektora zdań, którego długość (kolumny macierzy) jest równa wielkości słownictwa.
Importuj CountVectorizer
Zamierzamy zaimportować CountVectorizer, aby wytrenować nasz model Bag of Words
from sklearn.feature_extraction.text import CountVectorizer
Utwórz wektoryzator
W tym kroku utworzymy nasz model za pomocą CountVectorizer i przeszkolimy go, korzystając z naszego przykładowego dokumentu tekstowego.
# Sample text documents
documents = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a CountVectorizer
cv = CountVectorizer()
# Fit and Transform X = cv.fit_transform(documents)
Konwertuj na gęstą tablicę
W tym kroku przekształcimy nasze reprezentacje w gęstą tablicę. Otrzymamy również nazwy funkcji lub słowa.
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert to dense array X_dense = X.toarray()
Wydrukujmy macierz terminów dokumentu i słowa charakterystyczne
# Print the DTM and feature names
print("Document-Term Matrix (DTM):")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Dokument – Matryca Terminów (DTM):
 Matryca
Matryca
Nazwy funkcji:
 Charakterystyczne słowa
Charakterystyczne słowa
Jak widać, wektory składają się z liczb nieujemnych (0,1,2…), które reprezentują częstotliwość występowania słów w dokumencie.
Mamy cztery przykładowe dokumenty tekstowe i zidentyfikowaliśmy w nich dziewięć unikalnych słów. Zapisaliśmy te unikalne słowa w naszym słowniku, przypisując im „Nazwy funkcji”.
Następnie nasz model Bag of Words sprawdza, czy w naszym pierwszym dokumencie występuje pierwsze unikalne słowo. Jeśli jest obecny, przypisuje wartość 1, w przeciwnym razie przypisuje 0.
Jeśli słowo pojawia się wielokrotnie (np. 2 razy), przypisuje mu odpowiednią wartość.
Przykładowo w drugim dokumencie słowo „dokument” powtarza się dwukrotnie, więc jego wartość w macierzy będzie wynosić 2.
Jeśli chcemy, aby pojedyncze słowo było cechą klucza słownictwa – reprezentacja Unigram.
n – gramy = Unigramy, bigramy… itd.
Istnieje wiele bibliotek, takich jak scikit-learn do implementowania zestawu słów: Keras, Gensim i inne. Jest to proste i może być przydatne w różnych przypadkach.
Jednak Bag of Words jest szybszy, ale ma pewne ograniczenia.
Aby rozwiązać ten problem, możemy wybrać lepsze podejście, jednym z nich jest TF-IDF. Zrozummy szczegółowo.
TF-IDF
TF-IDF, czyli częstotliwość terminów – odwrotna częstotliwość dokumentów, to reprezentacja numeryczna określająca ważność słów w dokumencie.
Dlaczego potrzebujemy TF-IDF zamiast Bag of Words?
Zbiór słów traktuje wszystkie słowa jednakowo i skupia się jedynie na częstotliwości występowania unikalnych słów w zdaniach. TF-IDF przywiązuje wagę do słów w dokumencie, biorąc pod uwagę zarówno częstotliwość, jak i niepowtarzalność.
Słowa, które są powtarzane zbyt często, nie przyćmiewają słów rzadszych i ważniejszych.
TF: Częstotliwość terminów mierzy, jak ważne jest słowo w pojedynczym zdaniu.
IDF: Odwrotna częstotliwość dokumentów mierzy, jak ważne jest słowo w całym zbiorze dokumentów.
TF = Częstotliwość słów w dokumencie / Całkowita liczba słów w tym dokumencie
DF = Dokument zawierający słowo w / Całkowita liczba dokumentów
IDF = log(Całkowita liczba dokumentów / Dokumenty zawierające słowo w)
IDF jest odwrotnością DF. Dzieje się tak dlatego, że im częściej słowo to pojawia się we wszystkich dokumentach, tym mniejsze jest jego znaczenie w bieżącym dokumencie.
Końcowy wynik TF-IDF: TF-IDF = TF * IDF
Jest to sposób na sprawdzenie, które słowa są wspólne w jednym dokumencie i niepowtarzalne we wszystkich dokumentach. Słowa te mogą być przydatne w odnalezieniu głównego tematu dokumentu.
Na przykład,
Doc1 = „Uwielbiam uczenie maszynowe”
Doc2 = „Kocham newsblog.pl”
Musimy znaleźć macierz TF-IDF dla naszych dokumentów.
Najpierw stworzymy słownictwo unikalnych słów.
Słownictwo = [“I,” “love,” “machine,” “learning,” “Geekflare”]
Mamy więc 5 pięciu słów. Znajdźmy TF i IDF dla tych słów.
TF = Częstotliwość słów w dokumencie / Całkowita liczba słów w tym dokumencie
TF:
- Dla „I” = TF dla Doc1: 1/4 = 0,25 i dla Doc2: 1/3 ≈ 0,33
- Dla „miłości”: TF dla Doc1: 1/4 = 0,25 i dla Doc2: 1/3 ≈ 0,33
- Dla „Maszyny”: TF dla Doc1: 1/4 = 0,25 i dla Doc2: 0/3 ≈ 0
- Dla „Nauki”: TF dla Doc1: 1/4 = 0,25 i dla Doc2: 0/3 ≈ 0
- Dla „newsblog.pl”: TF dla Doc1: 0/4 = 0 i dla Doc2: 1/3 ≈ 0,33
Teraz obliczmy IDF.
IDF = log(Całkowita liczba dokumentów / Dokumenty zawierające słowo w)
IDF:
- Dla „I”: IDF wynosi log(2/2) = 0
- Dla „miłości”: IDF wynosi log(2/2) = 0
- Dla „Maszyny”: IDF wynosi log(2/1) = log(2) ≈ 0,69
- Dla „Uczenia się”: IDF to log(2/1) = log(2) ≈ 0,69
- Dla „newsblog.pl”: IDF wynosi log(2/1) = log(2) ≈ 0,69
Teraz obliczmy końcowy wynik TF-IDF:
- Dla „I”: TF-IDF dla Doc1: 0,25 * 0 = 0 i TF-IDF dla Doc2: 0,33 * 0 = 0
- Dla „miłości”: TF-IDF dla Doc1: 0,25 * 0 = 0 i TF-IDF dla Doc2: 0,33 * 0 = 0
- Dla „Maszyny”: TF-IDF dla Doc1: 0,25 * 0,69 ≈ 0,17 i TF-IDF dla Doc2: 0 * 0,69 = 0
- Dla „Nauki”: TF-IDF dla Doc1: 0,25 * 0,69 ≈ 0,17 i TF-IDF dla Doc2: 0 * 0,69 = 0
- Dla „newsblog.pl”: TF-IDF dla Doc1: 0 * 0,69 = 0 i TF-IDF dla Doc2: 0,33 * 0,69 ≈ 0,23
Macierz TF-IDF wygląda następująco:
I love machine learning newsblog.pl Doc1 0.0 0.0 0.17 0.17 0.0 Doc2 0.0 0.0 0.0 0.0 0.23
Wartości w macierzy TF-IDF informują, jak ważny jest każdy termin w każdym dokumencie. Wysokie wartości wskazują, że termin jest ważny w konkretnym dokumencie, natomiast niskie wartości sugerują, że termin jest mniej ważny lub powszechny w tym kontekście.
TF-IDF jest najczęściej używany do klasyfikacji tekstu, budowania wyszukiwania informacji o chatbocie i podsumowywania tekstu.
Zaimportuj TfidfVectorizer
Zaimportujmy TfidfVectorizer ze sklearn
from sklearn.feature_extraction.text import TfidfVectorizer
Utwórz wektoryzator
Jak widzisz, utworzymy nasz model Tf Idf za pomocą TfidfVectorizer.
# Sample text documents
text = [
"This is the first document.",
"This document is the second document.",
"And this is the third one.",
"Is this the first document?",
]
# Create a TfidfVectorizer
cv = TfidfVectorizer()
Utwórz macierz TF-IDF
Wytrenujmy nasz model, podając tekst. Następnie przekonwertujemy reprezentatywną macierz na gęstą tablicę.
# Fit and transform to create the TF-IDF matrix X = cv.fit_transform(text)
# Get the feature names/words feature_names = vectorizer.get_feature_names_out() # Convert the TF-IDF matrix to a dense array for easier manipulation (optional) X_dense = X.toarray()
Wydrukuj matrycę TF-IDF i słowa charakterystyczne
# Print the TF-IDF matrix and feature words
print("TF-IDF Matrix:")
print(X_dense)
print("\nFeature Names:")
print(feature_names)
Macierz TF-IDF:
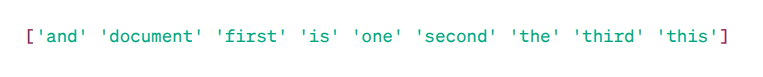 Słowa charakterystyczne
Słowa charakterystyczne
Jak widać, te liczby całkowite z ułamkiem dziesiętnym wskazują znaczenie słów w określonych dokumentach.
Możesz także łączyć słowa w grupy po 2,3,4 itd., używając n-gramów.
Istnieją inne parametry, które możemy uwzględnić: min_df, max_feature, subliner_tf itp.
Do tej pory badaliśmy podstawowe techniki oparte na częstotliwościach.
Jednak TF-IDF nie jest w stanie zapewnić semantycznego znaczenia i kontekstowego zrozumienia tekstu.
Przyjrzyjmy się bardziej zaawansowanym technikom, które zmieniły świat osadzania słów i które są lepsze dla znaczenia semantycznego i zrozumienia kontekstu.
Word2Vec
Word2vec jest popularny osadzanie słów (rodzaj wektora słów i przydatna do uchwycenia podobieństwa semantycznego i syntaktycznego) w NLP. Zostało to opracowane przez Tomasa Mikolova i jego zespół w Google w 2013 roku. Word2vec reprezentuje słowa jako wektory ciągłe w przestrzeni wielowymiarowej.
Celem Word2vec jest reprezentowanie słów w sposób oddający ich znaczenie semantyczne. Wektory słów generowane przez word2vec są umieszczane w ciągłej przestrzeni wektorowej.
Przykład – wektory „Kot” i „Pies” będą bliżej niż wektory „kot” i „dziewczyna”.
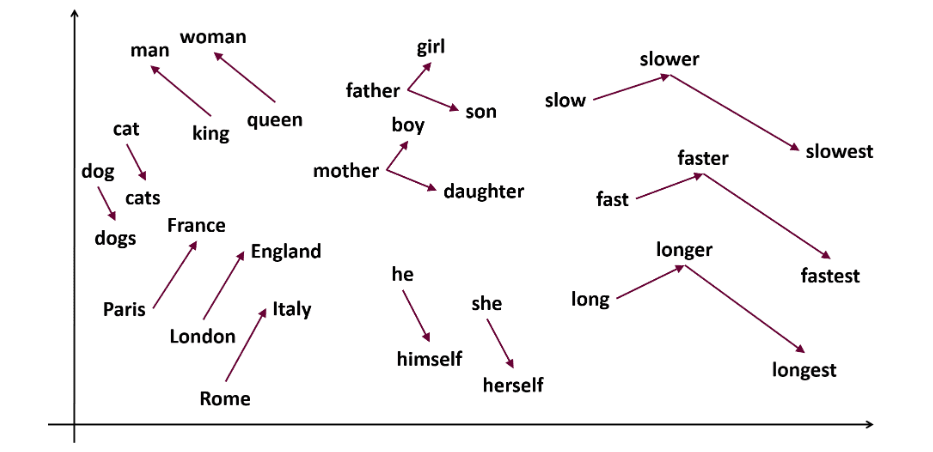 Źródło: usna.edu
Źródło: usna.edu
Word2vec może wykorzystać dwie architektury modeli do osadzania słów.
CBOW: Ciągły zbiór słów lub CBOW próbuje przewidzieć słowo, uśredniając znaczenie pobliskich słów. Pobiera stałą liczbę lub okno słów wokół słowa docelowego, następnie konwertuje je na postać liczbową (Osadzanie), następnie uśrednia wszystko i wykorzystuje tę średnią do przewidywania słowa docelowego za pomocą sieci neuronowej.
Ex-Przewiduj cel: „Lis”
Słowa w zdaniu: „The”, „szybki”, „brązowy”, „przeskakuje”, „nad”, „the”
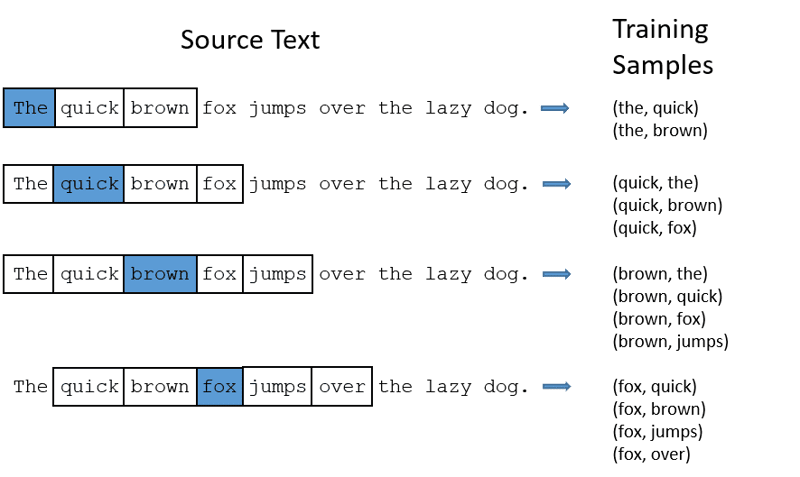 Word2Vec
Word2Vec
- CBOW przyjmuje okno o stałym rozmiarze (liczbę) słów, np. 2 (2 po lewej i 2 po prawej)
- Konwertuj na osadzanie słów.
- CBOW uśrednia osadzanie słów.
- CBOW uśrednia osadzanie słów w stosunku do słów kontekstu.
- Uśredniony wektor próbuje przewidzieć słowo docelowe za pomocą sieci neuronowej.
Teraz zrozumiemy, czym skip-gram różni się od CBOW.
Skip-gram: Jest to model osadzania słów, ale działa inaczej. Zamiast przewidywać słowo docelowe, skip-gram przewiduje słowa kontekstu dla podanych słów docelowych.
Skip-gramy lepiej oddają relacje semantyczne między słowami.
Były „Król – mężczyźni + kobiety = królowa”
Jeśli chcesz pracować z Word2Vec, masz dwie możliwości: możesz wytrenować własny model lub skorzystać z modelu wstępnie wytrenowanego. Będziemy przechodzić przez wstępnie wytrenowany model.
Importuj gensima
Możesz zainstalować gensim za pomocą pip install:
pip install gensim
Tokenizuj zdanie za pomocą word_tokenize:
Najpierw zamienimy zdania na niższe. Następnie będziemy tokenizować nasze zdania za pomocą word_tokenize.
# Import necessary libraries
from gensim.models import Word2Vec
from nltk.tokenize import word_tokenize
# Sample sentences
sentences = [
"I love thor",
"Hulk is an important member of Avengers",
"Ironman helps Spiderman",
"Spiderman is one of the popular members of Avengers",
]
# Tokenize the sentences
tokenized_sentences = [word_tokenize(sentence.lower()) for sentence in sentences]
Wytrenujmy nasz model:
Będziemy trenować nasz model, dostarczając tokenizowane zdania. W tym modelu szkoleniowym używamy 5 okien, możesz dostosować je do swoich wymagań.
# Train a Word2Vec model
model = Word2Vec(sentences=tokenized_sentences, vector_size=100, window=5, min_count=1, sg=0)
# Find similar words
similar_words = model.wv.most_similar("avengers")
# Print similar words
print("Similar words to 'avengers':")
for word, score in similar_words:
print(f"{word}: {score}")
Podobne słowa do słowa „avengers”:
 Podobieństwo Word2Vec
Podobieństwo Word2Vec
Oto niektóre słowa podobne do „mścicieli” w oparciu o model Word2Vec, wraz z ich wynikami podobieństwa.
Model oblicza stopień podobieństwa (głównie podobieństwo cosinusowe) pomiędzy wektorami słów „mściciele” i innymi słowami w swoim słownictwie. Wynik podobieństwa wskazuje, jak blisko spokrewnione są dwa słowa w przestrzeni wektorowej.
Były –
Tutaj słowo „pomaga” z podobieństwem cosinus -0,005911458611011982 ze słowem „mściciele”. Wartość ujemna sugeruje, że mogą się one od siebie różnić.
Wartości podobieństwa cosinus wahają się od -1 do 1, gdzie:
- 1 wskazuje, że oba wektory są identyczne i wykazują dodatnie podobieństwo.
- Wartości bliskie 1 wskazują na duże dodatnie podobieństwo.
- Wartości bliskie 0 wskazują, że wektory nie są silnie powiązane.
- Wartości bliskie -1 wskazują na dużą odmienność.
- -1 wskazuje, że te dwa wektory są całkowicie przeciwne i mają doskonałe ujemne podobieństwo.
Odwiedź to połączyć jeśli chcesz lepiej zrozumieć modele word2vec i wizualną reprezentację ich działania. To naprawdę fajne narzędzie do oglądania CBOW i skip-gram w akcji.
Podobnie jak Word2Vec, mamy GloVe. GloVe może tworzyć osadzanie, które wymagają mniej pamięci w porównaniu do Word2Vec. Dowiedzmy się więcej o GloVe.
Rękawica
Globalne wektory do reprezentacji słów (GloVe) to technika podobna do word2vec. Służy do przedstawiania słów jako wektorów w przestrzeni ciągłej. Koncepcja stojąca za GloVe jest taka sama jak w przypadku Word2Vec: tworzy kontekstowe osadzanie słów, biorąc pod uwagę doskonałą wydajność Word2Vec.
Dlaczego potrzebujemy GloVe?
Word2vec jest metodą opartą na oknach i wykorzystuje pobliskie słowa do zrozumienia słów. Oznacza to, że na znaczenie semantyczne słowa docelowego wpływają jedynie otaczające go słowa w zdaniach, co oznacza nieefektywne wykorzystanie statystyk.
Natomiast GloVe rejestruje zarówno globalne, jak i lokalne statystyki związane z osadzaniem słów.
Kiedy stosować GloVe?
Użyj GloVe, jeśli chcesz osadzać słowa, które oddaje szersze relacje semantyczne i globalne skojarzenia słów.
GloVe jest lepszy od innych modeli w zakresie zadań rozpoznawania nazwanych jednostek, analogii słów i podobieństwa słów.
Najpierw musimy zainstalować Gensim:
pip install gensim
Krok 1: Zainstalujemy ważne biblioteki
# Import the required libraries import numpy as np import matplotlib.pyplot as plt from sklearn.manifold import TSNE import gensim.downloader as api
Krok 2: Zaimportuj model rękawicy
import gensim.downloader as api
glove_model = api.load('glove-wiki-gigaword-300')
Krok 3: Pobierz wektorową reprezentację słowa „słodki”
glove_model["cute"]
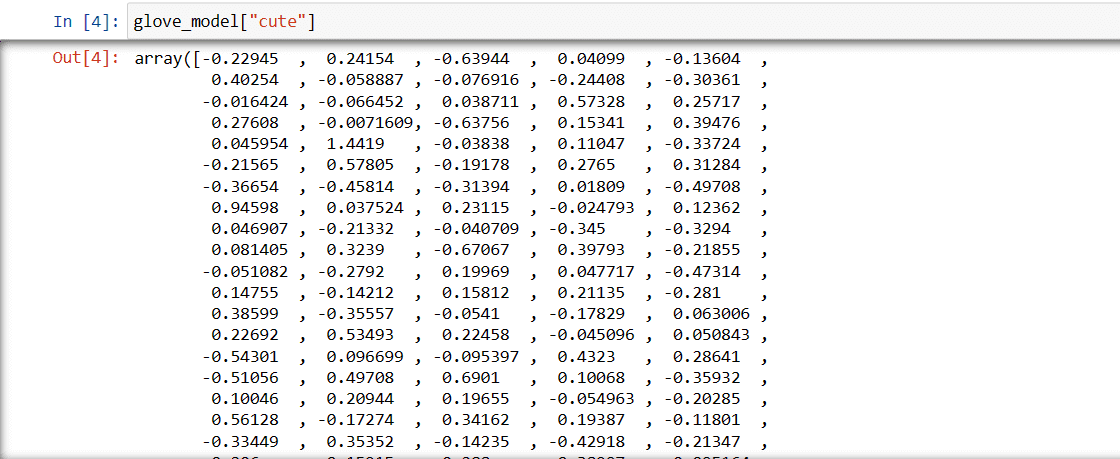 Wektor słowa „słodki”
Wektor słowa „słodki”
Wartości te oddają znaczenie słowa i relacje z innymi słowami. Wartości dodatnie wskazują na pozytywne skojarzenia z określonymi pojęciami, natomiast wartości ujemne wskazują na negatywne skojarzenia z innymi pojęciami.
W modelu GloVe każdy wymiar wektora słowa reprezentuje pewien aspekt znaczenia lub kontekstu słowa.
Wartości ujemne i dodatnie w tych wymiarach wpływają na to, jak „urocze” jest semantycznie powiązane z innymi słowami w słowniku modelki.
Wartości mogą być różne dla różnych modeli. Znajdźmy słowa podobne do słowa „chłopiec”
Top 10 podobnych słów, które według modelki są najbardziej podobne do słowa „chłopiec”
# find similar word
glove_model.most_similar("boy")
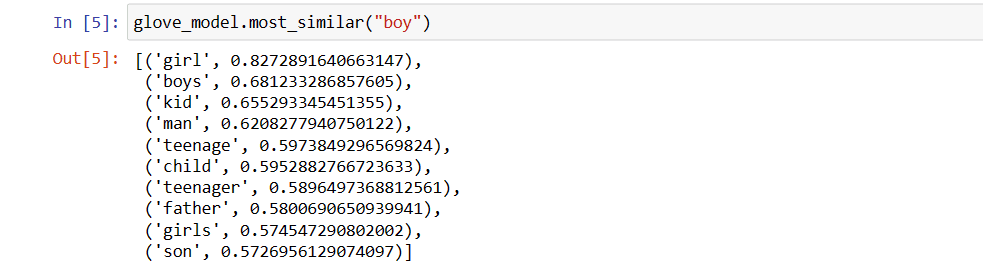 10 najpopularniejszych słów podobnych do „chłopiec”
10 najpopularniejszych słów podobnych do „chłopiec”
Jak widać, najbardziej podobnym słowem do słowa „chłopiec” jest słowo „dziewczyna”.
Teraz spróbujemy sprawdzić, jak dokładnie model uzyska znaczenie semantyczne na podstawie podanych słów.
glove_model.most_similar(positive=['boy', 'queen'], negative=['girl'], topn=1)
 Najbardziej odpowiednie słowo dla „królowej”
Najbardziej odpowiednie słowo dla „królowej”
Nasz model jest w stanie znaleźć idealną relację między słowami.
Zdefiniuj listę słówek:
Spróbujmy teraz zrozumieć znaczenie semantyczne lub związek między słowami za pomocą fabuły. Zdefiniuj listę słów, które chcesz zwizualizować.
# Define the list of words you want to visualize vocab = ["boy", "girl", "man", "woman", "king", "queen", "banana", "apple", "mango", "cow", "coconut", "orange", "cat", "dog"]
Utwórz macierz osadzania:
Napiszmy kod tworzący macierz osadzającą.
# Your code for creating the embedding matrix
EMBEDDING_DIM = glove_model.vectors.shape[1]
word_index = {word: index for index, word in enumerate(vocab)}
num_words = len(vocab)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word_index.items():
embedding_vector = glove_model[word]
if embedding_vector is not None:
embedding_matrix[i] = embedding_vector
Zdefiniuj funkcję wizualizacji t-SNE:
Na podstawie tego kodu zdefiniujemy funkcję dla naszego wykresu wizualizacyjnego.
def tsne_plot(embedding_matrix, words):
tsne_model = TSNE(perplexity=3, n_components=2, init="pca", random_state=42)
coordinates = tsne_model.fit_transform(embedding_matrix)
x, y = coordinates[:, 0], coordinates[:, 1]
plt.figure(figsize=(14, 8))
for i, word in enumerate(words):
plt.scatter(x[i], y[i])
plt.annotate(word,
xy=(x[i], y[i]),
xytext=(2, 2),
textcoords="offset points",
ha="right",
va="bottom")
plt.show()
Zobaczmy jak wygląda nasza Działka:
# Call the tsne_plot function with your embedding matrix and list of words tsne_plot(embedding_matrix, vocab)
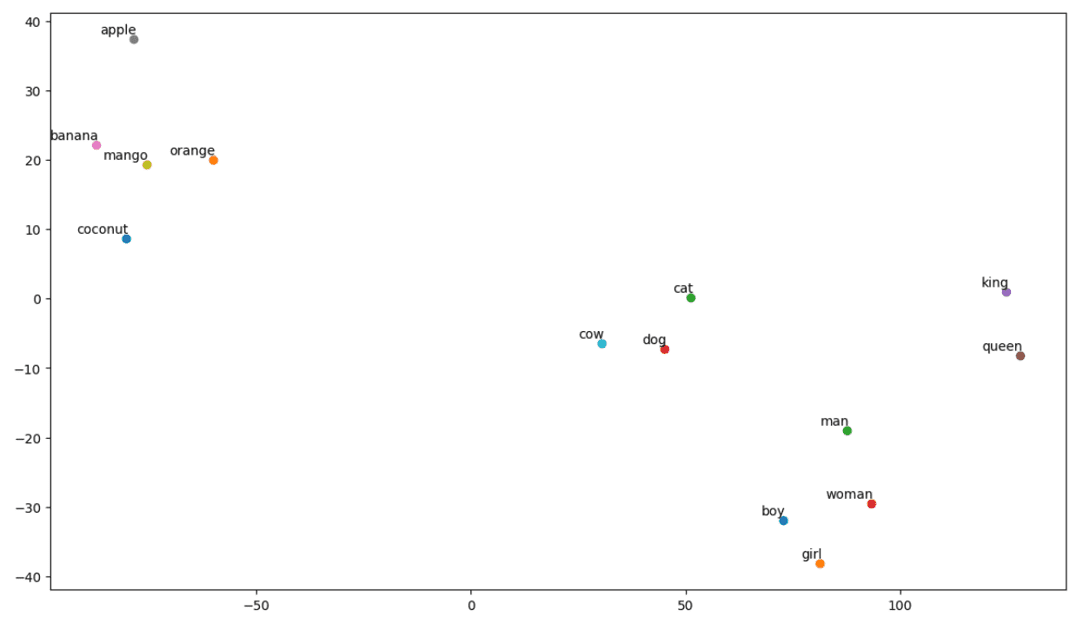 wykres t-SNE
wykres t-SNE
Jak więc widzimy, po lewej stronie naszej działki znajdują się słowa takie jak „banan”, „mango”, „pomarańcza”, „kokos” i „jabłko”. Natomiast „krowa”, „pies” i „kot” są do siebie podobne, ponieważ są zwierzętami.
Zatem nasz model może znaleźć także znaczenie semantyczne i relacje między słowami!
Zmieniając słownictwo lub tworząc model od zera, możesz eksperymentować z różnymi słowami.
Możesz użyć tej matrycy osadzania, jakkolwiek chcesz. Można go zastosować do samych zadań związanych z podobieństwem słów lub wprowadzić do warstwy osadzającej sieci neuronowej.
GloVe trenuje na macierzy współwystępowań, aby uzyskać znaczenie semantyczne. Opiera się na założeniu, że współwystępowania słów są istotną częścią wiedzy i że ich wykorzystanie jest skutecznym sposobem wykorzystania statystyk do tworzenia osadzania słów. W ten sposób GloVe dokonuje dodania „globalnych statystyk” do produktu końcowego.
A to jest GloVe; Inną popularną metodą wektoryzacji jest FastText. Porozmawiajmy o tym więcej.
Szybki Tekst
FastText to biblioteka typu open source wprowadzona przez zespół badawczy AI Facebooka do klasyfikacji tekstu i analizy nastrojów. FastText udostępnia narzędzia do uczenia osadzania słów, które są gęstymi wektorami reprezentującymi słowa. Jest to przydatne do uchwycenia semantycznego znaczenia dokumentu. FastText obsługuje zarówno klasyfikację wieloetykietową, jak i wieloklasową.
Dlaczego FastText?
FastText jest lepszy od innych modeli ze względu na możliwość uogólniania na nieznane słowa, czego brakowało w innych metodach. FastText udostępnia wstępnie wytrenowane wektory słów dla różnych języków, które mogą być przydatne w różnych zadaniach, w których potrzebna jest wcześniejsza wiedza na temat słów i ich znaczenia.
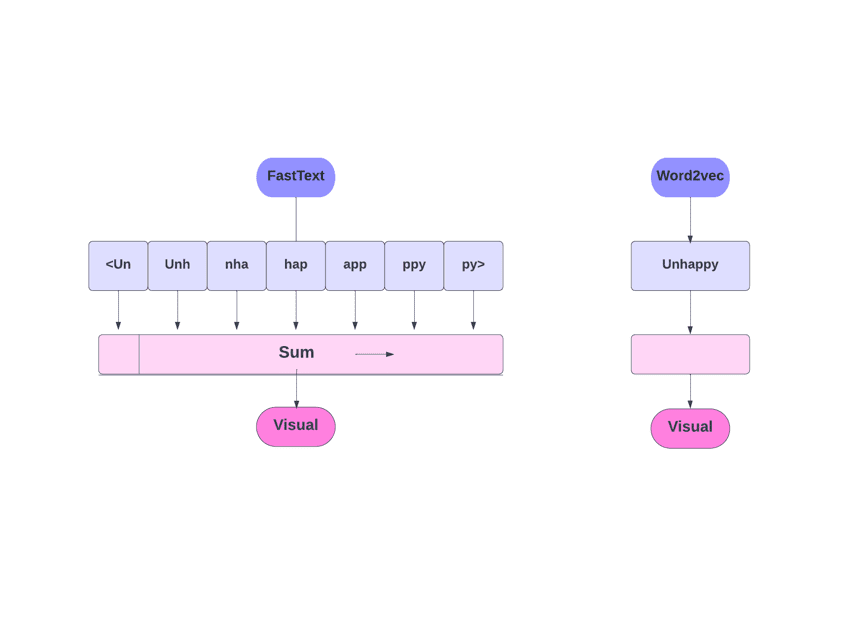 FastText kontra Word2Vec
FastText kontra Word2Vec
Jak to działa?
Jak już wspomnieliśmy, inne modele, takie jak Word2Vec i GloVe, używają słów do osadzania słów. Jednak podstawą FastText są litery, a nie słowa. Oznacza to, że używają liter do osadzania słów.
Używanie znaków zamiast słów ma jeszcze jedną zaletę. Do szkolenia potrzeba mniej danych. Gdy słowo staje się jego kontekstem, z tekstu można wydobyć więcej informacji.
Osadzanie słów uzyskane za pośrednictwem FastText jest kombinacją osadzania niższego poziomu.
Przyjrzyjmy się teraz, jak FastText wykorzystuje informacje o podsłowach.
Powiedzmy, że mamy słowo „czytanie”. Dla tego słowa n-gramy znaków o długości 3-6 zostaną wygenerowane w następujący sposób:
- Początek i koniec są oznaczone nawiasami ostrymi.
- Używa się haszowania, ponieważ liczba n-gramów może być duża; zamiast uczyć się osadzania dla każdego odrębnego n-gramu, uczymy się osadzania całkowitego B, gdzie B oznacza rozmiar wiadra. W oryginalnym papierze zastosowano wiadro o pojemności 2 milionów.
- Każdy n-gramowy znak, taki jak „eadi”, jest odwzorowywany na liczbę całkowitą z zakresu od 1 do B przy użyciu tej funkcji mieszającej, a ten indeks ma odpowiednie osadzenie.
- Uśredniając te składowe osadzania n-gramowe, uzyskuje się następnie pełne osadzenie słów.
- Nawet jeśli takie podejście do mieszania powoduje kolizje, w dużym stopniu pomaga poradzić sobie z rozmiarem słownictwa.
- Sieć używana w FastText jest podobna do Word2Vec. Podobnie jak tam, FastText możemy trenować w dwóch trybach – CBOW i skip-gram. Dlatego nie musimy ponownie powtarzać tej części.
Można wytrenować własny model lub skorzystać z modelu wstępnie wytrenowanego. Będziemy używać wcześniej wytrenowanego modelu.
Najpierw musisz zainstalować FastText.
pip install fasttext
Użyjemy zbioru danych składającego się z tekstów konwersacyjnych dotyczących kilku narkotyków i musimy sklasyfikować te teksty na 3 typy. Podobnie jak w przypadku narkotyków, z którymi są powiązane.
 Zbiór danych
Zbiór danych
Teraz, aby wytrenować model FastText na dowolnym zbiorze danych, musimy przygotować dane wejściowe w określonym formacie, czyli:
__label__
Zróbmy to także dla naszego zbioru danych.
all_texts = train['text'].tolist()
all_labels = train['drug type'].tolist()
prep_datapoints=[]
for i in range(len(all_texts)):
sample="__label__"+ str(all_labels[i]) + ' '+ all_texts[i]
prep_datapoints.append(sample)
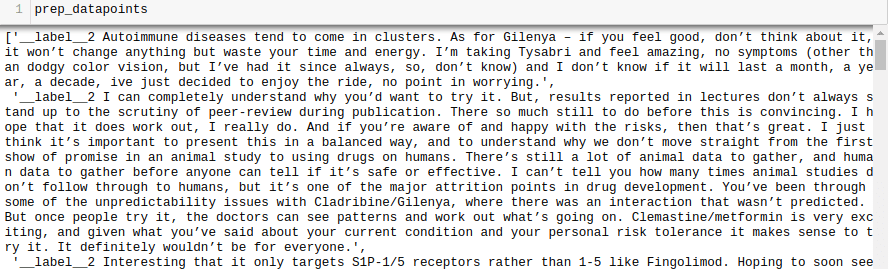 prep_datapoints
prep_datapoints
Na tym etapie pominęliśmy wiele procesów wstępnego przetwarzania. W przeciwnym razie nasz artykuł będzie za duży. W przypadku problemów występujących w świecie rzeczywistym najlepiej jest przeprowadzić przetwarzanie wstępne, aby dane nadawały się do modelowania.
Teraz zapisz przygotowane punkty danych do pliku .txt.
with open('train_fasttext.txt','w') as f:
for datapoint in prep_datapoints:
f.write(datapoint)
f.write('n')
f.close()
Wytrenujmy nasz model.
model = fasttext.train_supervised('train_fasttext.txt')
Otrzymamy prognozy z naszego modelu.

Model przewiduje etykietę i przypisuje jej poziom pewności.
Podobnie jak w przypadku każdego innego modelu, wydajność tego modelu zależy od wielu zmiennych, ale jeśli chcesz szybko zorientować się, jaka jest oczekiwana dokładność, FastText może być świetną opcją.
Wniosek
Podsumowując, metody wektoryzacji tekstu, takie jak Bag of Words (BoW), TF-IDF, Word2Vec, GloVe i FastText, zapewniają różnorodne możliwości zadań NLP.
Podczas gdy Word2Vec przechwytuje semantykę słów i można go dostosować do różnych zadań NLP, BoW i TF-IDF są proste i odpowiednie do klasyfikacji i rekomendacji tekstów.
W przypadku zastosowań takich jak analiza nastrojów GloVe oferuje wstępnie wyszkolone osadzania, a FastText dobrze radzi sobie z analizą na poziomie podsłów, dzięki czemu jest przydatny w przypadku języków o bogatej strukturze i rozpoznawania jednostek.
Wybór techniki zależy od zadania, danych i zasobów. W miarę rozwoju tej serii będziemy głębiej omawiać złożoność NLP. Miłej nauki!
Następnie sprawdź najlepsze kursy NLP do nauki przetwarzania języka naturalnego.