Jak je efektywnie wykorzystać?
Osoby korzystające z systemu Linux od pewnego czasu zazwyczaj znają narzędzie grep, czyli Global Regular Expression Print. Jest to program do przetwarzania tekstu, który umożliwia wyszukiwanie informacji w plikach i katalogach. Dla zaawansowanych użytkowników Linuksa stanowi ono niezwykle przydatne wsparcie. Jednakże, korzystanie z grep bez wykorzystania wyrażeń regularnych może ograniczyć jego potencjał.
Czym są zatem wyrażenia regularne (regex)?
Wyrażenia regularne to zaawansowane wzorce filtrowania danych wyjściowych, które można stosować w celu rozszerzenia funkcjonalności wyszukiwania grep. Dzięki praktyce, można skutecznie posługiwać się wyrażeniami regularnymi, zwłaszcza że znajdują one zastosowanie również w innych poleceniach systemu Linux.
W niniejszym poradniku pokażemy, jak efektywnie korzystać z połączenia grep i wyrażeń regularnych.
Wymagania wstępne
Aby sprawnie używać grep z wyrażeniami regularnymi, niezbędna jest solidna znajomość systemu Linux. Jeżeli dopiero rozpoczynasz swoją przygodę z tym systemem, zachęcamy do zapoznania się z naszymi wcześniejszymi przewodnikami.
Dodatkowo, potrzebujesz komputera z zainstalowanym systemem operacyjnym Linux. Możesz wybrać dowolną dystrybucję. Jeśli korzystasz z systemu Windows, istnieje możliwość użycia Linuksa za pośrednictwem WSL2. Szczegółowe informacje na ten temat znajdziesz w naszym dedykowanym artykule.
Dostęp do wiersza poleceń, czyli terminala, pozwoli na uruchamianie wszystkich przykładów poleceń prezentowanych w tym poradniku.
Ponadto, potrzebne będą pliki tekstowe, na których zostaną zademonstrowane przykłady użycia grep z wyrażeniami regularnymi. W celu wygenerowania potrzebnego tekstu, wykorzystano narzędzie ChatGPT, prosząc je o stworzenie tekstu o tematyce technologicznej. Użyta instrukcja miała następującą formę:
„Wygeneruj tekst o długości 400 słów na temat technologii. Tekst powinien obejmować różnorodne technologie i powtarzać nazwy technologii w różnych miejscach”.
Po wygenerowaniu tekstu, został on skopiowany i zapisany do pliku o nazwie tech.txt, który będzie wykorzystywany w kolejnych przykładach.
Podstawowa wiedza na temat polecenia grep jest niezbędna. W razie potrzeby, możesz przypomnieć sobie jego działanie, przeglądając 16 przykładowych poleceń grep. Na początek, pokrótce omówimy to polecenie.
Składnia i przykłady polecenia grep
Składnia polecenia grep jest bardzo prosta:
$ grep -opcje [wzorzec/regex] [pliki]
Jak widzisz, polecenie wymaga podania wzorca oraz listy plików, w których ma zostać przeprowadzone wyszukiwanie.
Dostępnych jest wiele opcji polecenia grep, które pozwalają na modyfikację jego funkcjonalności. Oto niektóre z nich:
-i: ignorowanie wielkości liter-r: wyszukiwanie rekurencyjne-w: wyszukiwanie tylko całych słów-v: wyświetlanie linii, które nie pasują do wzorca-n: wyświetlanie numerów pasujących linii-l: wypisywanie nazw plików--color: kolorowanie wyników-c: pokazywanie liczby dopasowań dla danego wzorca
# 1. Wyszukiwanie całego słowa
Aby wyszukać całe słowo, należy użyć argumentu -w. Takie podejście pozwala uniknąć dopasowania fragmentów słów, które jedynie zawierają dany wzorzec.
$ grep -w ‘tech\|5G’ tech.txt
Powyższe polecenie wyszuka w tekście wystąpienia słów „5G” oraz „tech”, zaznaczając je kolorem czerwonym.
Symbol | (potok) jest w tym przypadku traktowany jako znak specjalny, dzięki czemu grep nie interpretuje go dosłownie.
#2. Wyszukiwanie bez rozróżniania wielkości liter
Aby przeprowadzić wyszukiwanie bez uwzględniania wielkości liter, należy użyć argumentu -i.
$ grep -i ‘tech’ tech.txt
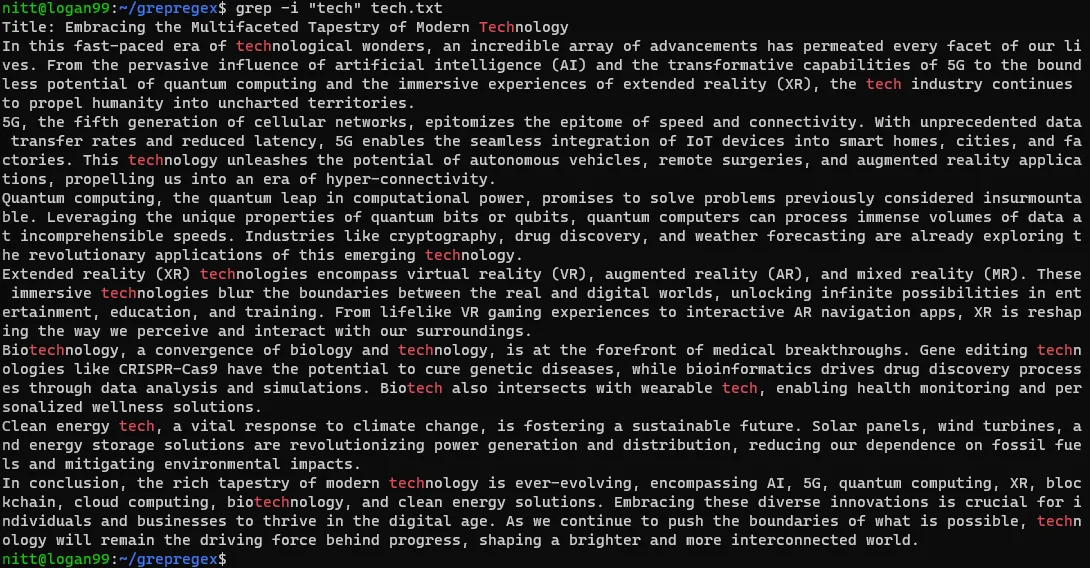
Polecenie to wyszuka wszystkie wystąpienia ciągu znaków "tech", niezależnie od tego, czy jest on częścią słowa, czy też stanowi całe słowo, oraz od użytych wielkich czy małych liter.
#3. Wyszukiwanie linii, które nie pasują do wzorca
Aby wyświetlić linie, które nie zawierają danego wzorca, należy użyć argumentu -v.
$ grep -v ‘tech’ tech.txt

Wynikiem działania tego polecenia są wszystkie linie, które nie zawierają słowa "tech", w tym także puste linie, które występują po akapitach.
#4. Wyszukiwanie rekurencyjne
Do przeszukiwania rekurencyjnego, należy użyć argumentu -r.
$ grep -R ‘error\|warning’ /var/log/*.log
#output /var/log/bootstrap.log:2023-01-03 21:40:18 URL:http://ftpmaster.internal/ubuntu/pool/main/libg/libgpg-error/libgpg-erro 0_1.43-3_amd64.deb [69684/69684] -> "/build/chroot//var/cache/apt/archives/partial/libgpg-error0_1.43-3_amd64.deb" [1] /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 5 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: parsing file '/var/lib/dpkg/status' near line 24 package 'dpkg': /var/log/bootstrap.log:dpkg: warning: ignoring pre-dependency problem!
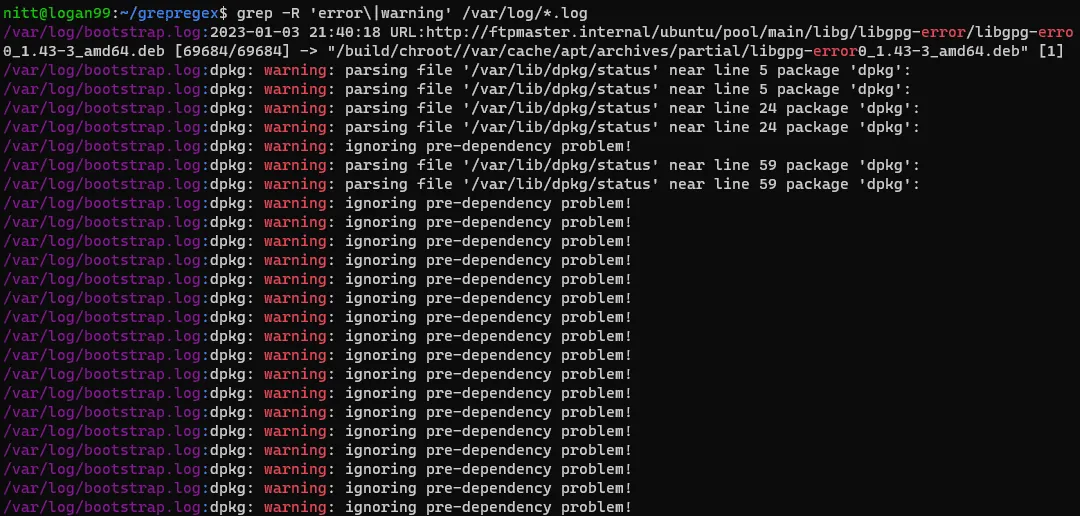
Powyższe polecenie rekurencyjnie przeszukuje pliki w katalogu /var/log, poszukując wystąpień słów "error" oraz "warning". Jest to bardzo przydatne narzędzie do identyfikacji błędów i ostrzeżeń w plikach logów.
Grep i wyrażenia regularne: czym są i przykłady użycia
W kontekście pracy z wyrażeniami regularnymi, należy pamiętać o istnieniu trzech opcji składni:
- Podstawowe wyrażenia regularne (BRE)
- Rozszerzone wyrażenia regularne (ERE)
- Wyrażenia regularne kompatybilne z Perlem (PCRE)
Domyślnie, polecenie grep wykorzystuje BRE. Jeżeli chcesz użyć innych trybów, należy o tym wyraźnie poinformować. Grep traktuje również metaznaki dosłownie. Oznacza to, że jeśli używasz metaznaków takich jak ?, +, ), musisz zmienić ich znaczenie za pomocą ukośnika odwrotnego (\).
Składnia grep z wyrażeniem regularnym ma następującą postać:
$ grep [regex] [nazwy plików]
Zobaczmy, jak działa połączenie grep i wyrażeń regularnych w poniższych przykładach.
# 1. Dosłowne dopasowanie słów
Aby dokonać dosłownego dopasowania słów, należy podać ciąg znaków jako wyrażenie regularne. W końcu, słowo również jest wyrażeniem regularnym.
$ grep "technologies" tech.txt

Podobnie, możesz użyć dosłownego dopasowania, aby znaleźć aktualnie zalogowanych użytkowników. W tym celu, użyj następującego polecenia:
$ grep bash /etc/passwd
#output root:x:0:0:root:/root:/bin/bash nitt:x:1000:1000:,,,:/home/nitt:/bin/bash
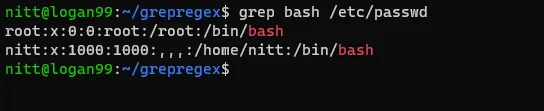
Powyższe polecenie wyświetli listę użytkowników, którzy mogą korzystać z Basha.
#2. Dopasowanie kotwicy
Dopasowanie kotwicy to zaawansowana technika wyszukiwania, wykorzystująca znaki specjalne. W wyrażeniach regularnych istnieje kilka znaków kotwicy, które wskazują określoną pozycję w tekście. Są to:
- Znak karetki „^”: dopasowuje początek ciągu wejściowego lub wiersza i szuka pustego ciągu znaków.
- Symbol dolara „$”: dopasowuje koniec ciągu wejściowego lub wiersza i również szuka pustego ciągu znaków.
Pozostałe dwa znaki zakotwiczenia to granica słowa „\b” oraz granica niebędąca słowem „\B”.
- Granica słowa „\b”: \b wskazuje pozycję pomiędzy słowem a znakiem, który nie jest słowem. Pozwala ona na dopasowanie całych słów i uniknięcie dopasowań częściowych. Można ją wykorzystać do zamiany słów oraz liczenia wystąpień słów w tekście.
- Granica niebędąca słowem „\B”: jest przeciwieństwem granicy słowa, wskazując pozycję, która nie znajduje się między znakami tworzącymi słowo.
Przeanalizujmy przykłady, aby lepiej zrozumieć te zagadnienia:
$ grep ‘^From’ tech.txt

Użycie daszka wymaga podania słowa z uwzględnieniem wielkości liter. Jest to istotne, ponieważ domyślnie grep rozróżnia wielkość liter. Uruchomienie poniższego polecenia nie zwróci żadnego wyniku:
$ grep ‘^from’ tech.txt
Podobnie, symbol dolara ($) można wykorzystać do znalezienia zdań, które kończą się na określony wzorzec.
$ grep ‘technology.$' tech.txt

Symbole ^ oraz $ można łączyć. Spójrzmy na poniższy przykład:
$ grep “^From \| technology.$” tech.txt
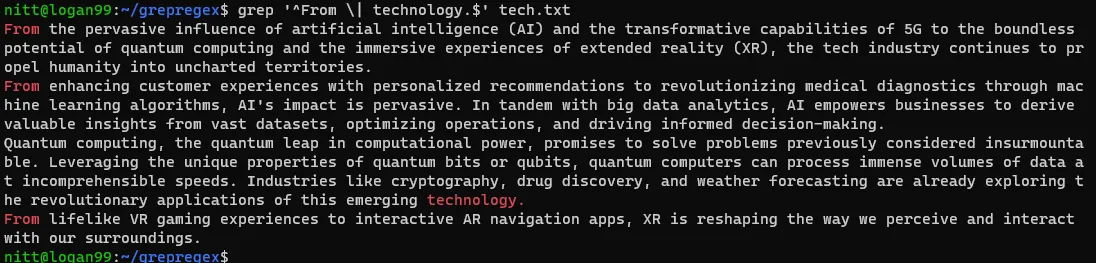
Jak widać, wynikiem są zdania, które zaczynają się od słowa „From” lub kończą na słowo „technology”.
#3. Grupowanie
Jeśli chcesz przeszukać tekst pod kątem wielu wzorców jednocześnie, użyj grupowania. Grupowanie umożliwia tworzenie mniejszych grup znaków lub wzorców, które traktowane są jako całość. Przykładowo, można utworzyć grupę (technologia), która zawiera termin t, e, c, h.
Aby lepiej to zobrazować, spójrzmy na przykład:
$ grep 'technol\(ogy\)\?' tech.txt
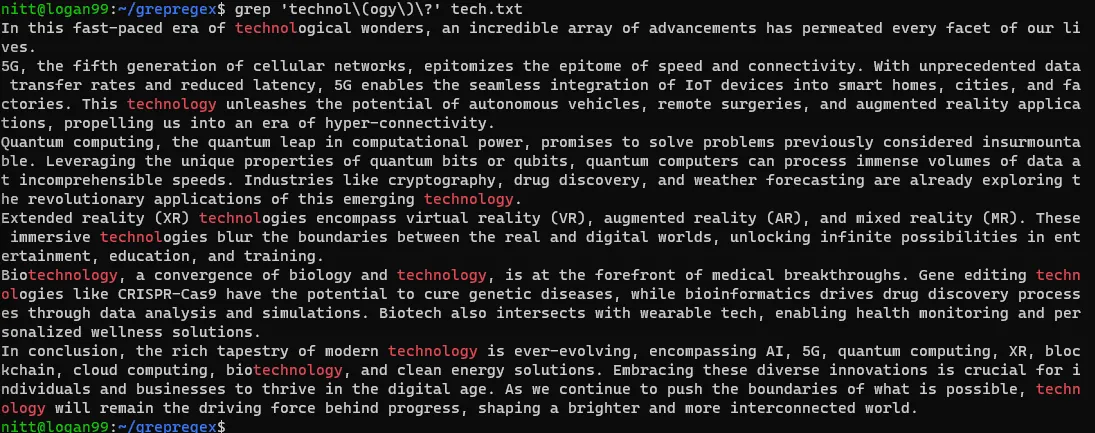
Dzięki grupowaniu, można dopasowywać powtarzające się wzorce, przechwytywać grupy, oraz wyszukiwać alternatywne dopasowania.
Alternatywne wyszukiwanie z grupowaniem
Spójrzmy na przykład alternatywnego wyszukiwania:
$ grep "\(tech\|technology\)" tech.txt
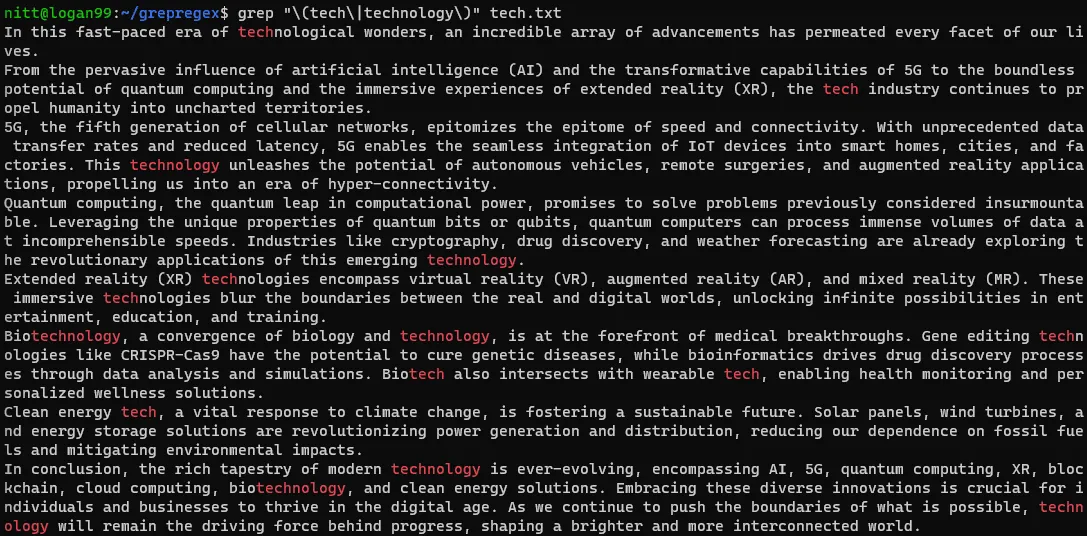
Jeśli chcesz wyszukać ciąg znaków, należy przekazać go za pomocą symbolu potoku. Zobaczmy to na poniższym przykładzie:
$ echo “tech technological technologies technical” | grep "\(tech\|technology\)"
#output “tech technological technologies technical”

Grupy przechwytujące, grupy nieprzechwytujące i powtarzające się wzorce
Jak wykorzystać grupy przechwytujące i nieprzechwytujące?
Aby przechwycić grupy, należy utworzyć grupę w wyrażeniu regularnym i przekazać ją do ciągu znaków lub pliku:
$ echo 'tech655 tech655nical technologies655 tech655-oriented 655' | grep "\(tech\)\(655\)"
#output tech655 tech655nical technologies655 tech655-oriented 655

W przypadku grup nieprzechwytujących, należy użyć ?: w nawiasach.
Na koniec, omówimy powtarzające się wzorce. Aby wyszukać powtarzające się wzorce, należy odpowiednio zmodyfikować wyrażenie regularne:
$ echo ‘teach tech ttrial tttechno attest’ | grep '\(t\+\)'
#output ‘teach tech ttrial tttechno attest’
Powyższe wyrażenie regularne szuka jednego lub więcej wystąpień litery "t".
#4. Klasy znaków
Klasy znaków upraszczają tworzenie wyrażeń regularnych. Klasy te wykorzystują nawiasy kwadratowe. Poniżej prezentujemy niektóre z najczęściej stosowanych klas:
[:digit:]– cyfry od 0 do 9[:alpha:]– znaki alfabetu[:alnum:]– znaki alfanumeryczne[:lower:]– małe litery[:upper:]– wielkie litery[:xdigit:]– cyfry szesnastkowe, czyli 0-9, A-F oraz a-f[:blank:]– puste znaki, takie jak tabulator i spacja
To tylko kilka przykładów! Zobaczmy, jak działają w praktyce:
$ grep [[:digit]] tech.txt

$ grep [[:alpha:]] tech.txt
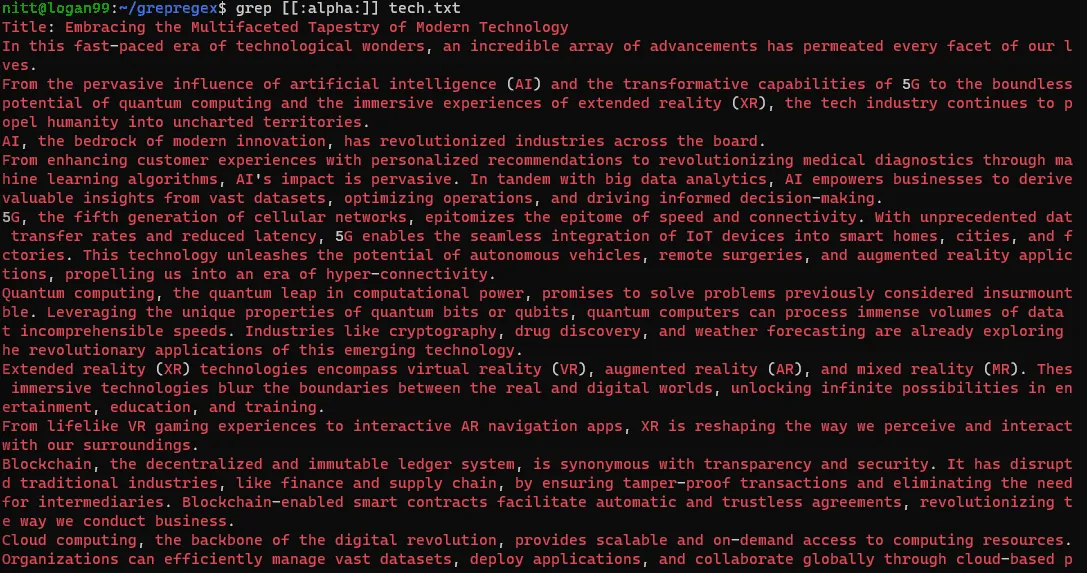
$ grep [[:xdigit:]] tech.txt
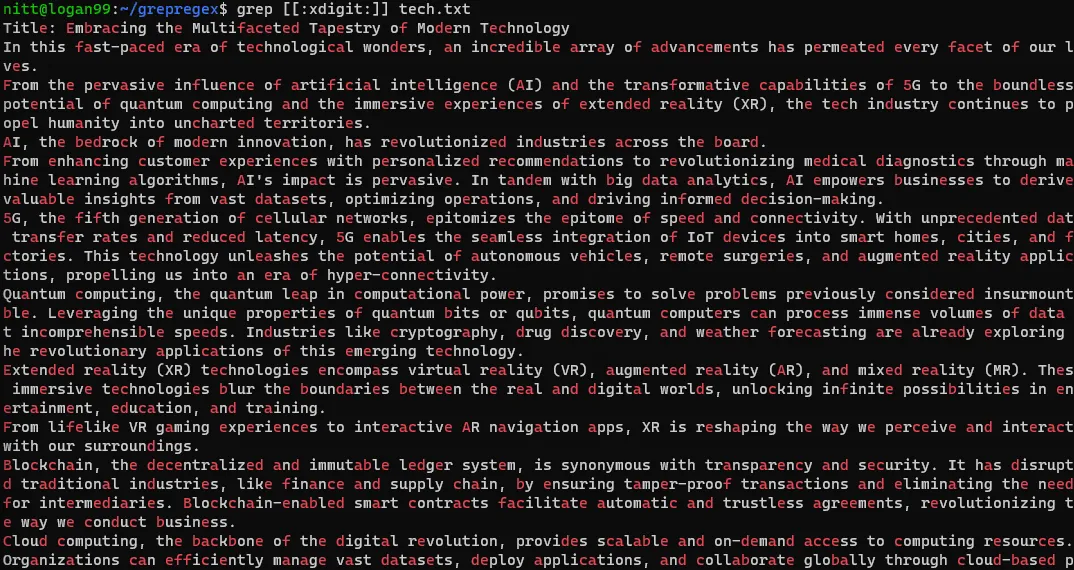
#5. Kwantyfikatory
Kwantyfikatory to metaznaki, które stanowią istotę wyrażeń regularnych. Pozwalają one na precyzyjne określenie, ile razy dany element ma się pojawić w tekście. Poniżej przedstawiamy dostępne kwantyfikatory:
*→ zero lub więcej dopasowań+→ jedno lub więcej dopasowań?→ zero lub jedno dopasowanie{x}→ dokładnie x dopasowań{x,}→ x lub więcej dopasowań{x,z}→ od x do z dopasowań{,z}→ do z dopasowań
$ echo ‘teach tech ttrial tttechno attest’ | grep -E 't+'
#output ‘teach tech ttrial tttechno attest’
Powyższe polecenie wyszukuje wystąpienia litery "t", występujące jedno lub więcej razy. Argument -E oznacza rozszerzone wyrażenie regularne (o którym powiemy później).

#6. Rozszerzone wyrażenia regularne
Jeśli nie chcesz dodawać znaków ucieczki w wyrażeniu regularnym, użyj rozszerzonego wyrażenia regularnego. Eliminuje ono potrzebę używania znaków ucieczki. Aby z niego skorzystać, należy użyć flagi -E.
$ grep -E 'in+ovation' tech.txt

#7. Używanie PCRE do zaawansowanych wyszukiwań
PCRE (Perl Compatible Regular Expression) oferuje znacznie więcej możliwości niż podstawowe wyrażenia regularne. Przykładowo, można użyć \d, co odpowiada [0-9].
Na przykład, można użyć PCRE do wyszukiwania adresów e-mail:
echo "Contact me at [email protected]" | grep -P "\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,}\b"
#output Contact me at [email protected]

W tym przypadku, PCRE dopasowuje wzorzec adresu e-mail. Podobnie, PCRE można użyć do wyszukiwania dat:
$ echo "The Sparkain site launched on 2023-07-29" | grep -P "\b\d{4}-\d{2}-\d{2}\b"
#output The Sparkain site launched on 2023-07-29

Powyższe polecenie znajduje datę w formacie RRRR-MM-DD. Możesz je zmodyfikować, aby wyszukiwało daty w innych formatach.
#8. Alternacja
Aby wyszukać alternatywne dopasowania, można użyć znaków potoku ze znakiem ucieczki (\|).
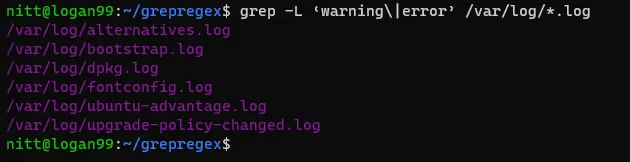
$ grep -L ‘warning\|error’ /var/log/*.log
#output /var/log/alternatives.log /var/log/bootstrap.log /var/log/dpkg.log /var/log/fontconfig.log /var/log/ubuntu-advantage.log /var/log/upgrade-policy-changed.log
Wynikiem działania tego polecenia są nazwy plików, które zawierają słowo "warning" lub "error".
Podsumowanie
W tym miejscu kończymy nasz przewodnik po grep i wyrażeniach regularnych. Jak widzisz, grep w połączeniu z wyrażeniami regularnymi to potężne narzędzie do precyzyjnego wyszukiwania. Dzięki jego właściwemu użyciu, możesz zaoszczędzić mnóstwo czasu i zautomatyzować wiele zadań, szczególnie podczas pisania skryptów lub przeszukiwania dużych ilości tekstu.
Na zakończenie, zachęcamy do przejrzenia często zadawanych pytań i odpowiedzi na rozmowach kwalifikacyjnych związanych z systemem Linux.
