Jak pobrać i zainstalować Llamę 2 lokalnie
Firma Meta udostępniła model Llama 2 w połowie 2023 roku. Nowa wersja tego modelu została poddana procesowi dostrajania na zbiorze danych o 40% większym niż pierwotny model Llama. Ponadto, podwojono długość kontekstu, co znacząco przewyższa inne, powszechnie dostępne modele z otwartym kodem źródłowym. Najszybszy i najprostszy dostęp do Llama 2 zapewnia interfejs API dostępny na platformie internetowej. Jednakże, jeśli zależy nam na optymalnej jakości działania, zalecane jest zainstalowanie i uruchomienie Llama 2 bezpośrednio na naszym komputerze.
Z tego powodu, przygotowaliśmy szczegółowy poradnik opisujący krok po kroku, jak wykorzystać interfejs Text-Generation-WebUI do załadowania skwantowanego modelu Llama 2 LLM lokalnie na naszym komputerze.
Dlaczego warto zainstalować Llamę 2 lokalnie?
Istnieje wiele motywacji, które skłaniają użytkowników do bezpośredniego uruchamiania Llama 2 na swoim sprzęcie. Niektórzy decydują się na to ze względów prywatności, inni z chęci dostosowania modelu do własnych potrzeb, a jeszcze inni z powodu dostępu offline. Jeśli prowadzisz badania, dostrajasz lub integrujesz Llama 2 w swoich projektach, korzystanie z API może nie być najodpowiedniejszym rozwiązaniem. Celem lokalnego uruchamiania modeli LLM na własnym komputerze jest ograniczenie zależności od zewnętrznych narzędzi AI i możliwość korzystania z tej technologii w dowolnym miejscu i czasie, bez ryzyka ujawnienia potencjalnie wrażliwych danych firmom lub innym organizacjom.
Mając to na uwadze, przejdźmy do naszego przewodnika po lokalnej instalacji Llama 2.
Dla uproszczenia procesu, wykorzystamy instalator "jednym kliknięciem" dla Text-Generation-WebUI (aplikacji służącej do ładowania Llama 2 z graficznym interfejsem użytkownika). Jednak, aby ten instalator działał prawidłowo, niezbędne jest pobranie i zainstalowanie narzędzi Visual Studio 2019 Build Tools.
Pobierz: Visual Studio 2019 (Bezpłatna wersja)
- Pobierz wersję Community tego oprogramowania.
- Następnie, zainstaluj Visual Studio 2019 i po uruchomieniu zaznacz opcję "Tworzenie aplikacji klasycznych w C++" i kliknij "Instaluj".
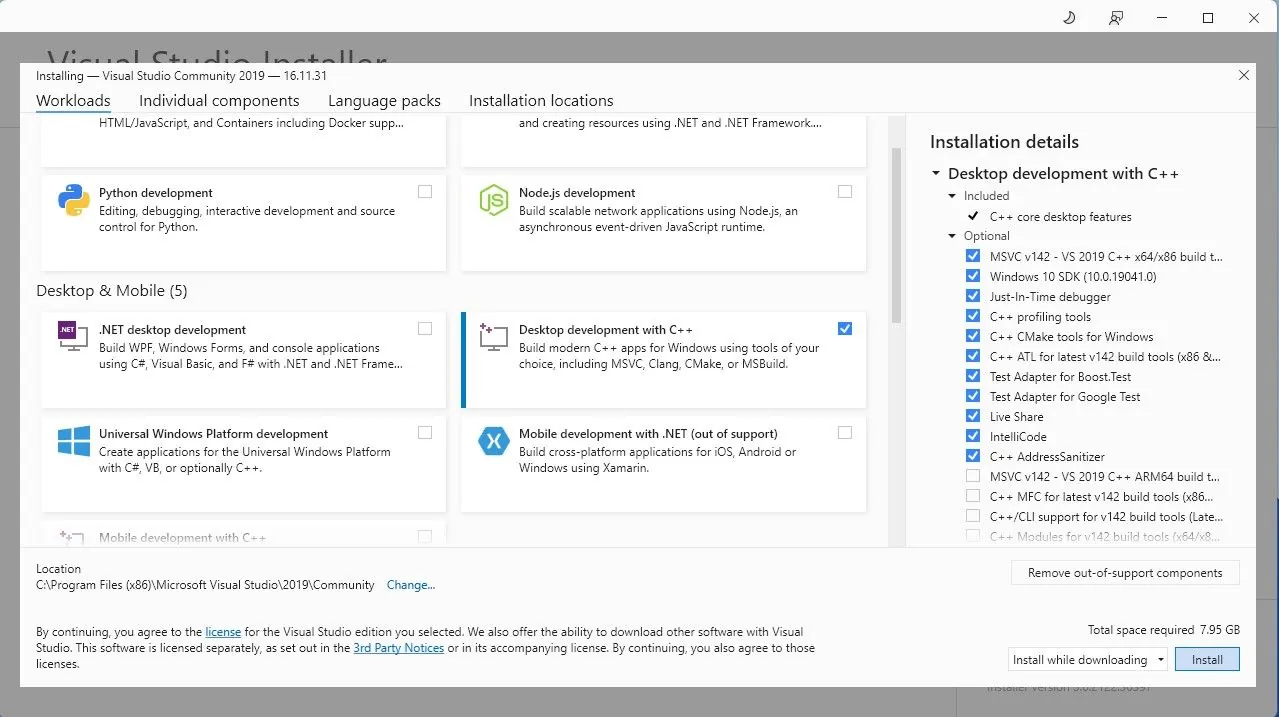
Po zainstalowaniu komponentu do tworzenia aplikacji klasycznych w języku C++, możemy przejść do pobrania instalatora Text-Generation-WebUI.
Krok 2: Instalacja Text-Generation-WebUI
Instalator Text-Generation-WebUI to skrypt, który automatycznie tworzy wszystkie wymagane foldery, konfiguruje środowisko Conda i wszystkie niezbędne zależności potrzebne do uruchomienia modelu AI.
Aby zainstalować skrypt, pobierz instalator "jednym kliknięciem" z sekcji Kod > Pobierz ZIP.
Pobierz: Instalator Text-Generation-WebUI (Bezpłatna wersja)
- Po pobraniu, rozpakuj plik ZIP do wybranej lokalizacji, a następnie przejdź do rozpakowanego folderu.
- W folderze odszukaj odpowiedni plik startowy dla Twojego systemu operacyjnego i uruchom go, klikając dwukrotnie.
- W przypadku systemu Windows wybierz plik wsadowy start_windows.
- W przypadku systemu macOS wybierz skrypt powłoki start_macos.
- W przypadku systemu Linux wybierz skrypt powłoki start_linux.
- Twój program antywirusowy może wyświetlić ostrzeżenie, co jest normalne. Jest to tzw. fałszywy alarm, wynikający z próby uruchomienia pliku wsadowego lub skryptu. Kliknij "Uruchom mimo to".
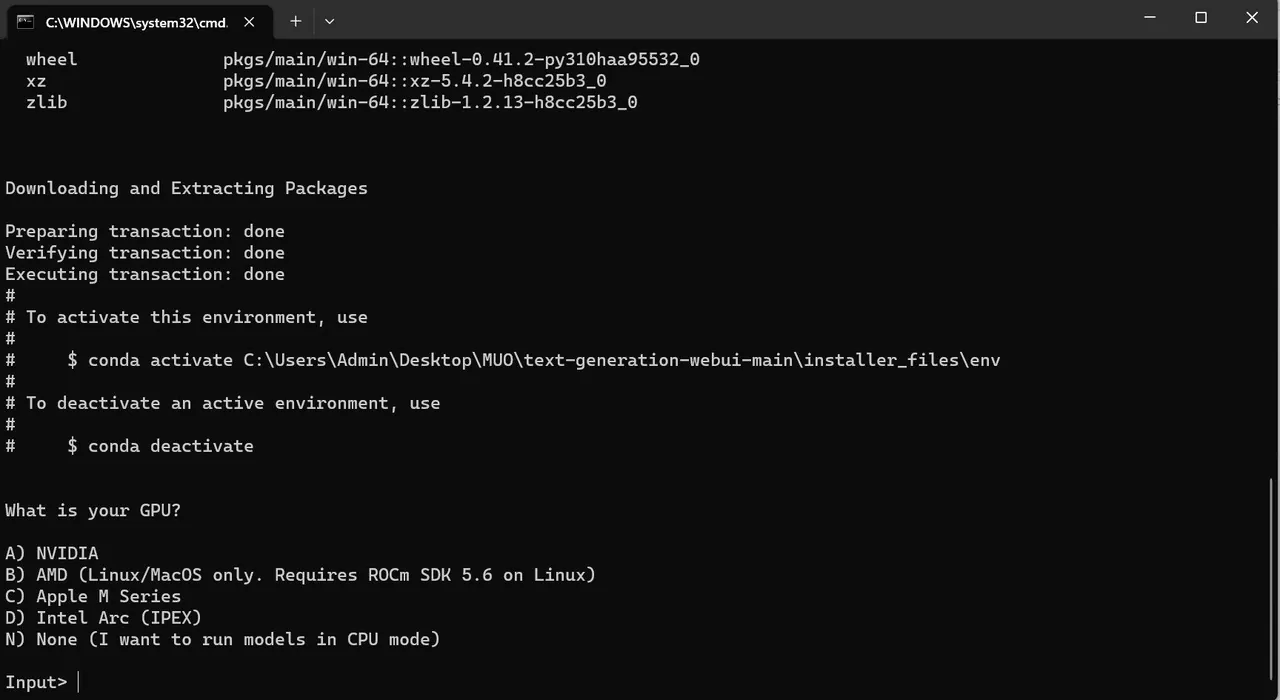
- Uruchomi się terminal i rozpocznie się konfiguracja. Instalacja zatrzyma się, prosząc o wybór rodzaju używanego procesora graficznego. Wybierz właściwy typ procesora graficznego zainstalowanego w komputerze i naciśnij klawisz Enter. Dla osób nie posiadających dedykowanej karty graficznej należy wybrać opcję "Brak (chcę uruchamiać modele na CPU)". Pamiętaj, że działanie w trybie CPU jest znacznie wolniejsze niż uruchamianie modelu z dedykowanym procesorem graficznym.
- Po zakończeniu konfiguracji można już uruchomić Text-Generation-WebUI lokalnie. Otwórz swoją ulubioną przeglądarkę internetową i wprowadź podany adres IP w pasku adresu.
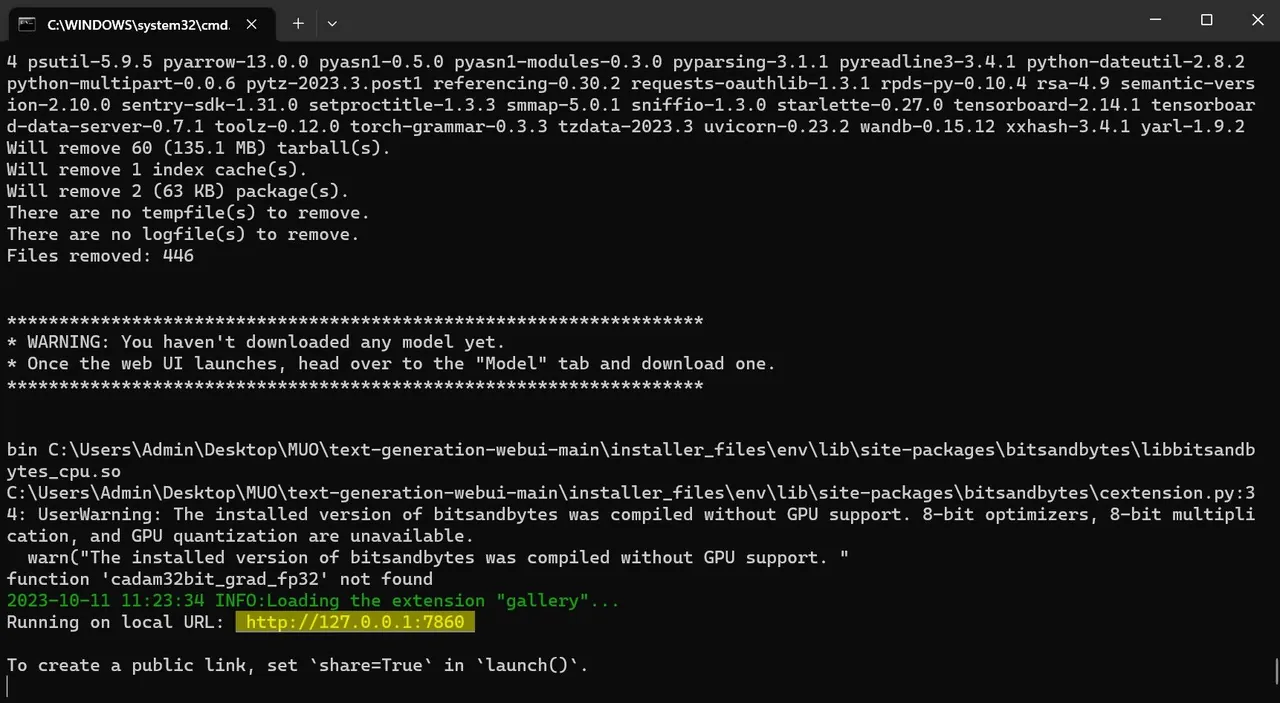
- Interfejs WebUI jest gotowy do użycia.
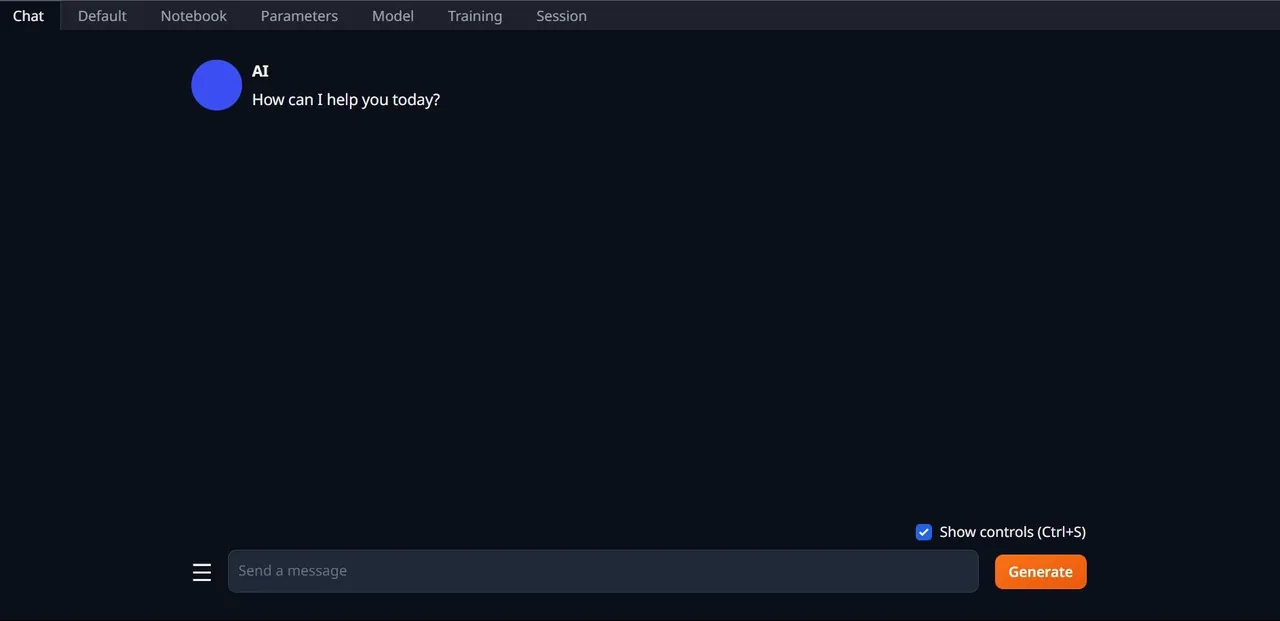
Jednak aplikacja służy jedynie do ładowania modeli. Musimy teraz pobrać model Llama 2, aby móc go uruchomić.
Krok 3: Pobranie modelu Llama 2
Przy wyborze odpowiedniej wersji modelu Llama 2, należy wziąć pod uwagę kilka istotnych czynników, takich jak parametry, kwantyzacja, optymalizacja pod kątem sprzętu, rozmiar i przeznaczenie. Wszystkie te informacje można odnaleźć w nazwie modelu.
- Parametry: Liczba parametrów użytych podczas uczenia modelu. Większa liczba parametrów pozwala uzyskać bardziej wydajne modele, jednak kosztem zwiększonego zapotrzebowania na zasoby.
- Przeznaczenie: Model może być standardowy lub dedykowany do czatu. Model przeznaczony do czatu jest zoptymalizowany pod kątem zastosowań takich jak chatboty (np. ChatGPT), natomiast model standardowy jest domyślną wersją modelu.
- Optymalizacja sprzętowa: Odnosi się do rodzaju sprzętu, na którym model działa najwydajniej. Oznaczenie GPTQ informuje, że model jest zoptymalizowany do pracy na dedykowanej karcie graficznej, podczas gdy GGML jest zoptymalizowany do pracy na procesorze CPU.
- Kwantyzacja: Oznacza precyzję wag i aktywacji w modelu. Precyzja q4 jest optymalna do wnioskowania.
- Rozmiar: Odnosi się do rozmiaru samego modelu.
Należy pamiętać, że nazewnictwo modeli może się różnić i niektóre z nich nie będą zawierały tych samych informacji. Niemniej jednak, konwencja nazewnictwa, którą tutaj opisaliśmy, jest często stosowana w bibliotece modeli HuggingFace, dlatego warto ją zrozumieć.
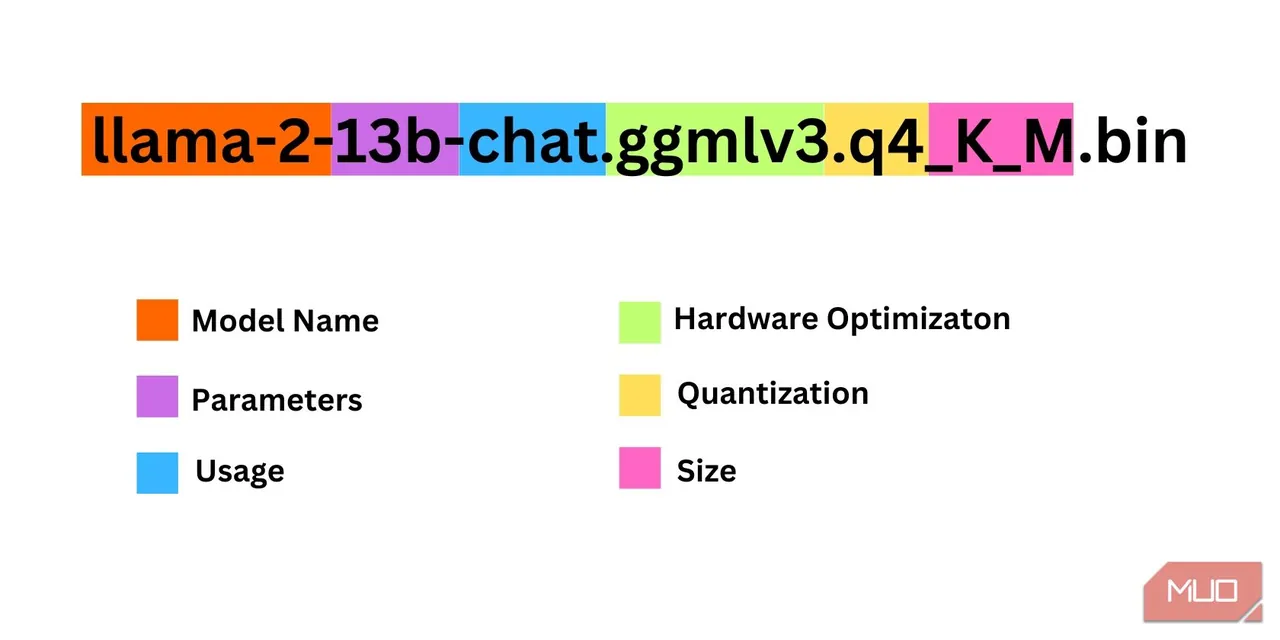
W powyższym przykładzie, model jest identyfikowany jako model średniej wielkości Llama 2, wytrenowany z użyciem 13 miliardów parametrów, zoptymalizowany do wnioskowania w kontekście czatu, z wykorzystaniem dedykowanego procesora graficznego.
Dla komputerów z dedykowanym procesorem graficznym wybierz model GPTQ, a dla tych z procesorem CPU, model GGML. Jeżeli chcesz porozmawiać z modelem tak, jak z ChatGPT, wybierz model do czatu. Jeśli zaś planujesz eksperymentować z pełnymi możliwościami modelu, wybierz model standardowy. Pamiętaj, że wybór większego modelu zapewni lepsze rezultaty, ale kosztem wydajności. Zalecamy rozpoczęcie od modelu 7B. Jeśli chodzi o kwantyzację, użyj q4, ponieważ jest ona przeznaczona do wnioskowania.
Pobierz: GGML (Bezpłatna wersja)
Pobierz: GPTQ (Bezpłatna wersja)
Teraz, gdy już wiesz, jakiej wersji modelu Llama 2 potrzebujesz, możesz pobrać odpowiedni plik.
W naszym przykładzie, wykorzystując ultrabooka, pobierzemy model GGML do czatu o nazwie llama-2-7b-chat-ggmlv3.q4_K_S.bin.
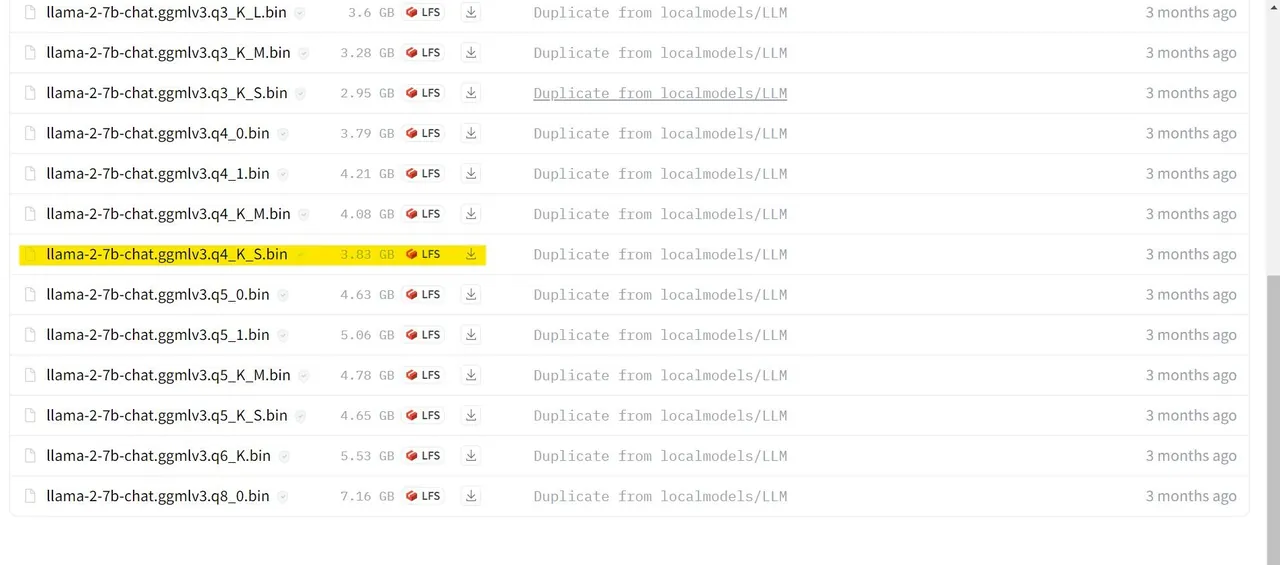
Po zakończeniu pobierania umieść model w folderze Text-Generation-webui-main > models.
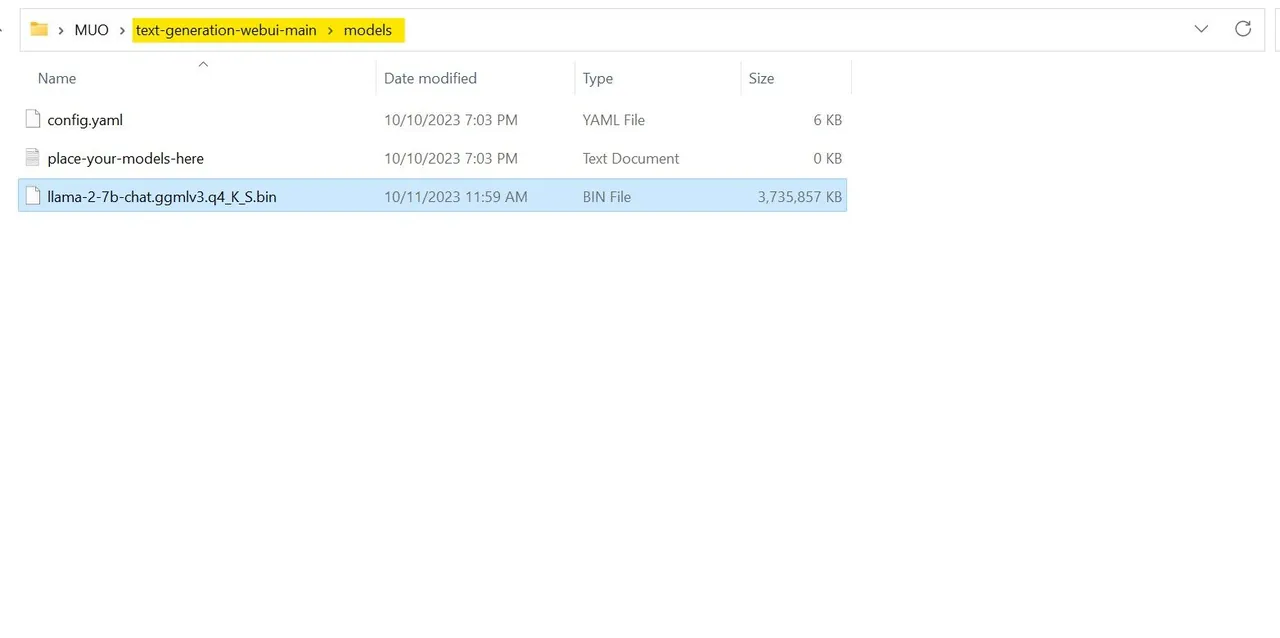
Po pobraniu i umieszczeniu modelu w odpowiednim folderze, możemy przejść do konfiguracji modułu ładującego.
Krok 4: Konfiguracja Text-Generation-WebUI
Przejdźmy do etapu konfiguracji.
- Uruchom ponownie Text-Generation-WebUI, wywołując plik start_(twój system operacyjny) (zgodnie z poprzednimi krokami).
- W zakładkach na górze interfejsu GUI kliknij zakładkę "Model". Rozwiń listę modeli przyciskiem odświeżenia i wybierz pobrany model.
- Następnie, w rozwijanej liście "Moduł ładujący model", wybierz "AutoGPTQ" dla modeli GTPQ i "ctransformers" dla modeli GGML. Na koniec kliknij przycisk "Załaduj", aby wczytać model.
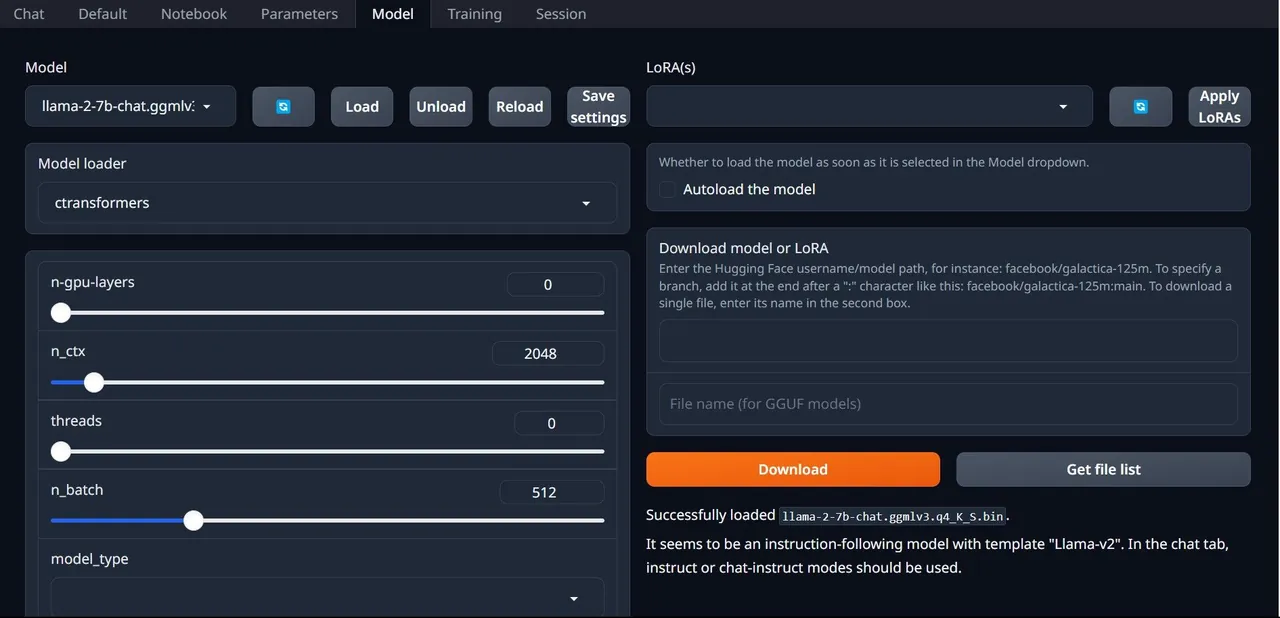
- Aby rozpocząć korzystanie z modelu, przejdź do zakładki "Czat" i zacznij testować model.
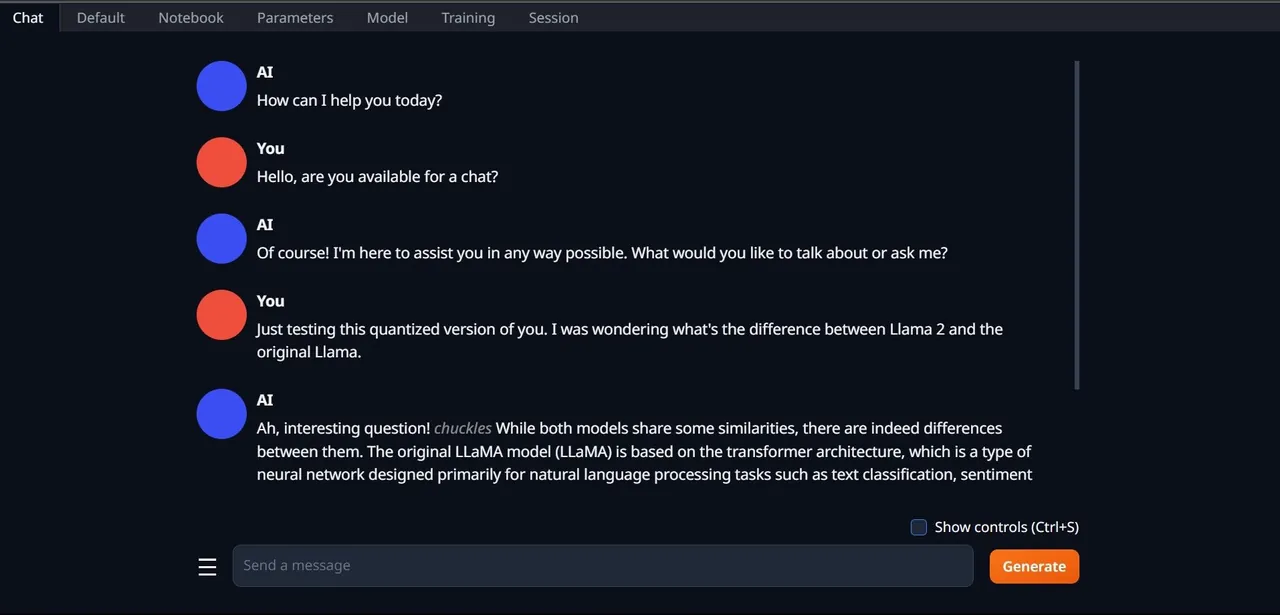
Gratulacje! Udało Ci się pomyślnie załadować model Llama 2 na swoim komputerze!
Wypróbuj inne LLM
Teraz, gdy już wiesz, jak uruchomić model Llama 2 lokalnie, przy użyciu Text-Generation-WebUI, możesz spróbować uruchomić również inne modele LLM. Pamiętaj o zasadach nazewnictwa i o tym, że na standardowych komputerach PC można uruchamiać tylko skwantowane wersje modeli (zwykle z precyzją q4). Wiele skwantowanych modeli LLM można znaleźć na HuggingFace. Aby znaleźć inne ciekawe modele, wyszukaj w bibliotece HuggingFace użytkownika "TheBloke".
