Polecenie curl systemu Linux może zrobić o wiele więcej niż pobieranie plików. Dowiedz się, do czego jest zdolny curl i kiedy powinieneś go używać zamiast wget.
Spis treści:
curl vs. wget: Jaka jest różnica?
Ludzie często mają trudności ze zidentyfikowaniem względnych mocnych stron poleceń wget i curl. Polecenia mają pewne funkcjonalne nakładanie się. Każdy z nich może pobierać pliki ze zdalnych lokalizacji, ale na tym kończy się podobieństwo.
wget jest fantastyczne narzędzie do pobierania treści i plików. Może pobierać pliki, strony internetowe i katalogi. Zawiera inteligentne procedury do przechodzenia przez łącza na stronach internetowych i rekurencyjnego pobierania treści z całej witryny. Jest niezrównany jako menedżer pobierania z wiersza poleceń.
curl spełnia zupełnie inna potrzeba. Tak, może pobierać pliki, ale nie może rekurencyjnie nawigować po witrynie w poszukiwaniu treści do pobrania. W rzeczywistości curl umożliwia interakcję ze zdalnymi systemami poprzez wysyłanie żądań do tych systemów oraz pobieranie i wyświetlanie ich odpowiedzi. Odpowiedzi te mogą obejmować treść i pliki strony internetowej, ale mogą również zawierać dane dostarczone za pośrednictwem usługi sieciowej lub interfejsu API w wyniku „pytania” zadanego w żądaniu curl.
A curl nie ogranicza się do witryn internetowych. curl obsługuje ponad 20 protokołów, w tym HTTP, HTTPS, SCP, SFTP i FTP. I prawdopodobnie dzięki lepszej obsłudze potoków Linuksa curl można łatwiej zintegrować z innymi poleceniami i skryptami.
Autor curl ma taką stronę internetową opisuje różnice, które widzi między curl i wget.
Instalowanie curl
Spośród komputerów używanych do badania tego artykułu Fedora 31 i Manjaro 18.1.0 miały już zainstalowane curl. curl musiał być zainstalowany na Ubuntu 18.04 LTS. W systemie Ubuntu uruchom to polecenie, aby je zainstalować:
sudo apt-get install curl

Wersja curl
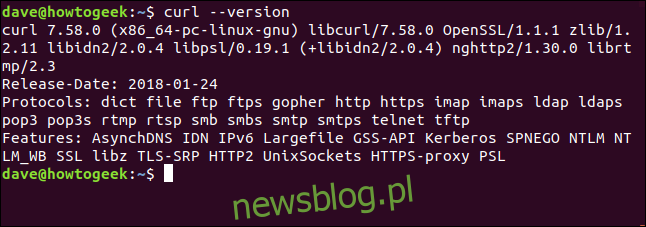
Opcja –version powoduje, że curl zgłasza swoją wersję. Zawiera również listę wszystkich obsługiwanych protokołów.
curl --version
Pobieranie strony internetowej
Jeśli wskażemy curl na stronie internetowej, zostanie on dla nas pobrany.
curl https://www.bbc.com

Ale jego domyślną akcją jest zrzucenie go do okna terminala jako kodu źródłowego.
Uwaga: jeśli nie powiesz curl, że chcesz coś zapisać jako plik, zawsze zrzuci to do okna terminala. Jeśli pobierany plik jest plikiem binarnym, wynik może być nieprzewidywalny. Powłoka może próbować interpretować niektóre wartości bajtów w pliku binarnym jako znaki sterujące lub sekwencje specjalne.
Zapisywanie danych do pliku
Powiedzmy curl, aby przekierował dane wyjściowe do pliku:
curl https://www.bbc.com > bbc.html

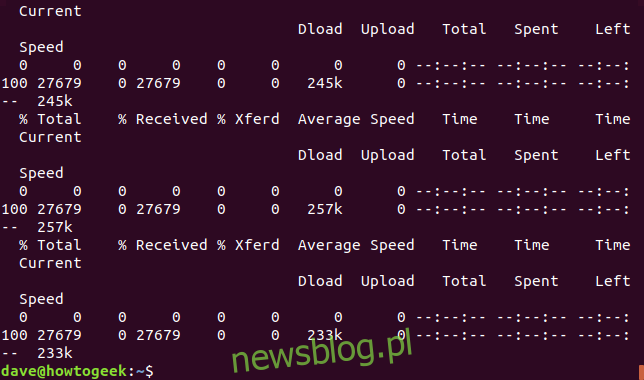
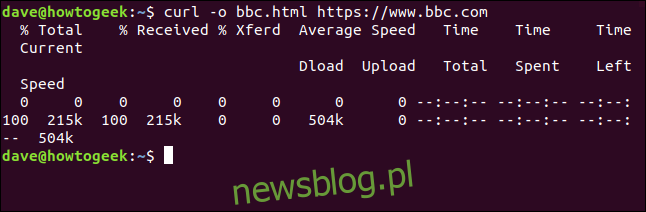
Podane informacje to:
% Razem: Całkowita kwota do pobrania.
% Odebranych: Procent i rzeczywiste wartości pobranych danych.
% Xferd: procent i rzeczywista liczba wysłanych, jeśli dane są przesyłane.
Średnia prędkość pobierania: Średnia prędkość pobierania.
Średnia prędkość wysyłania: Średnia prędkość wysyłania.
Całkowity czas: szacowany całkowity czas trwania transferu.
Spędzony czas: czas, jaki upłynął dotychczas dla tego transferu.
Pozostały czas: szacowany czas pozostały do zakończenia transferu
Current Speed: Aktualna prędkość transferu dla tego transferu.
Ponieważ przekierowaliśmy dane wyjściowe z curl do pliku, mamy teraz plik o nazwie „bbc.html”.

Dwukrotne kliknięcie tego pliku otworzy domyślną przeglądarkę i wyświetli pobraną stronę internetową.
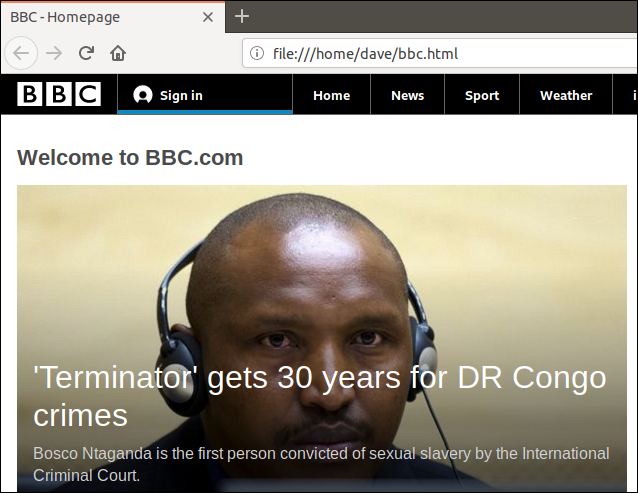
Zwróć uwagę, że adres w pasku adresu przeglądarki jest plikiem lokalnym na tym komputerze, a nie zdalną witryną internetową.
Nie musimy przekierowywać wyjścia, aby utworzyć plik. Możemy utworzyć plik, używając opcji -o (wyjście) i nakazując curlowi utworzenie pliku. Tutaj używamy opcji -o i podajemy nazwę pliku, który chcemy utworzyć „bbc.html”.
curl -o bbc.html https://www.bbc.com
Używanie paska postępu do monitorowania pobierania
Aby zastąpić tekstowe informacje o pobieraniu prostym paskiem postępu, użyj opcji – # (pasek postępu).
curl -x -o bbc.html https://www.bbc.com

Ponowne uruchamianie przerwanego pobierania
Ponowne uruchomienie pobierania, które zostało przerwane lub przerwane, jest łatwe. Zacznijmy pobieranie sporego pliku. Będziemy korzystać z najnowszej wersji systemu Ubuntu 18.04 ze wsparciem długoterminowym. Używamy opcji –output, aby określić nazwę pliku, w którym chcemy go zapisać: „ubuntu180403.iso”.
curl --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Pobieranie rozpoczyna się i zbliża do końca.
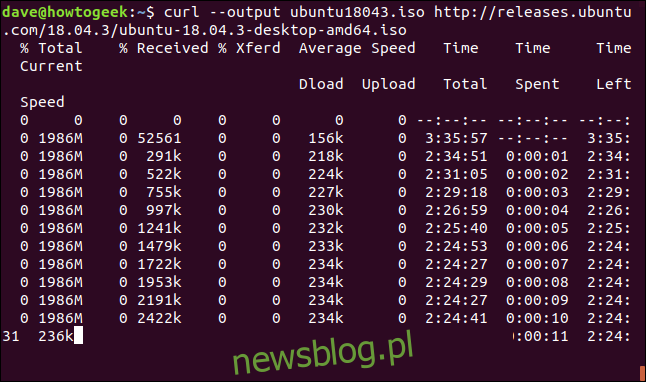
Jeśli na siłę przerwiemy pobieranie za pomocą Ctrl + C, wrócimy do wiersza poleceń, a pobieranie zostanie przerwane.
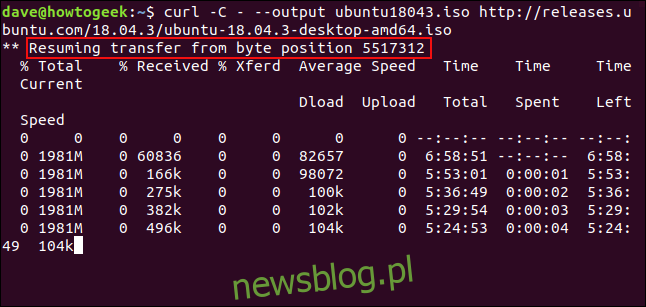
Aby ponownie uruchomić pobieranie, użyj opcji -C (kontynuuj o). Powoduje to, że curl ponownie uruchamia pobieranie w określonym punkcie lub przesunięciu w pliku docelowym. Jeśli użyjesz łącznika – jako przesunięcia, curl sprawdzi już pobraną część pliku i określi poprawne przesunięcie do użycia.
curl -C - --output ubuntu18043.iso http://releases.ubuntu.com/18.04.3/ubuntu-18.04.3-desktop-amd64.iso

Pobieranie zostanie wznowione. curl zgłasza przesunięcie, przy którym jest restartowany.
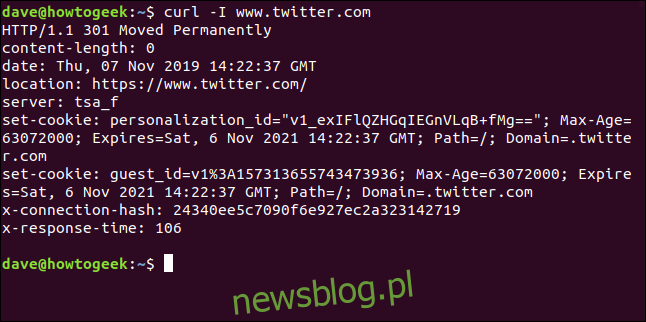
Pobieranie nagłówków HTTP
Z opcją -I (head) można pobrać tylko nagłówki HTTP. To jest to samo, co wysyłanie pliku Polecenie HTTP HEAD na serwer WWW.
curl -I www.twitter.com

To polecenie pobiera tylko informacje; nie pobiera żadnych stron internetowych ani plików.
Pobieranie wielu adresów URL
Za pomocą xargs możemy pobrać wiele plików Adresy URL od razu. Być może chcielibyśmy pobrać serię stron internetowych, które składają się na pojedynczy artykuł lub samouczek.
Skopiuj te adresy URL do edytora i zapisz je w pliku o nazwie „urls-to-download.txt”. Możemy użyć xargs do traktuj zawartość każdego wiersza pliku tekstowego jako parametr, który będzie podawany z kolei do curl.
https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#0 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#1 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#2 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#3 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#4 https://tutorials.ubuntu.com/tutorial/tutorial-create-a-usb-stick-on-ubuntu#5
To jest polecenie, którego musimy użyć, aby xargs przekazywał te adresy URL, aby zwijać je jeden po drugim:
xargs -n 1 curl -ONote that this command uses the -O (remote file) output command, which uses an uppercase “O.” This option causes curl to save the retrieved file with the same name that the file has on the remote server.
The -n 1 option tells xargs to treat each line of the text file as a single parameter.
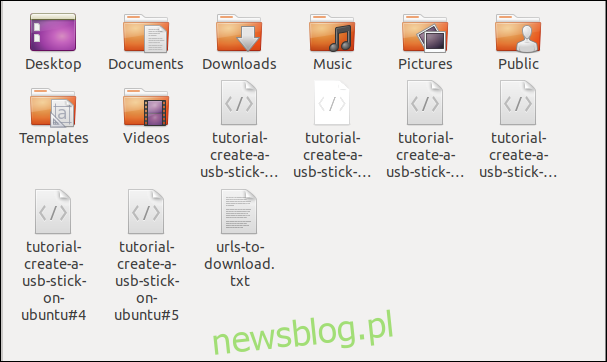
When you run the command, you’ll see multiple downloads start and finish, one after the other.
Checking in the file browser shows the multiple files have been downloaded. Each one bears the name it had on the remote server.
Pobieranie plików z serwera FTP
Używanie Curl z plikiem Protokół Przesyłania Plików Serwer (FTP) jest łatwy, nawet jeśli musisz uwierzytelnić się za pomocą nazwy użytkownika i hasła. Aby przekazać nazwę użytkownika i hasło za pomocą curl, użyj opcji -u (użytkownik) i wpisz nazwę użytkownika, dwukropek „:” i hasło. Nie umieszczaj spacji przed i po dwukropku.
To jest darmowy do testowania serwer FTP obsługiwany przez Rebex. Testowa witryna FTP ma wstępnie ustawioną nazwę użytkownika „demo”, a hasło to „hasło”. Nie używaj tego typu słabej nazwy użytkownika i hasła na produkcyjnym lub „prawdziwym” serwerze FTP.
curl -u demo: hasło ftp://test.rebex.net
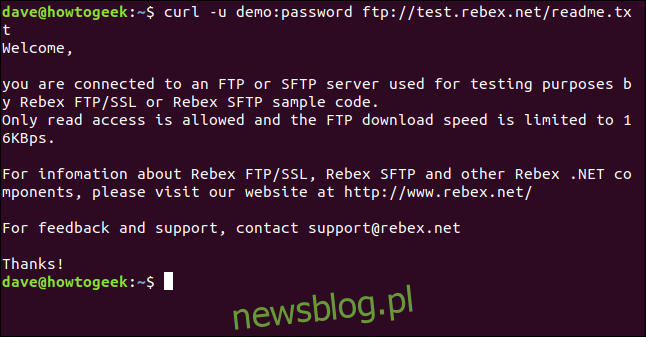
curl stwierdza, że wskazujemy go na serwer FTP i zwraca listę plików znajdujących się na serwerze.
Jedynym plikiem na tym serwerze jest plik „readme.txt” o długości 403 bajtów. Odzyskajmy to. Użyj tego samego polecenia, co przed chwilą, z dołączoną nazwą pliku:
curl -u demo:password ftp://test.rebex.net/readme.txt
Plik jest pobierany, a curl wyświetla jego zawartość w oknie terminala.
W prawie wszystkich przypadkach wygodniejsze będzie zapisanie pobranego pliku na dysk, a nie wyświetlenie go w oknie terminala. Jeszcze raz możemy użyć polecenia wyjścia -O (plik zdalny), aby zapisać plik na dysku z taką samą nazwą, jaką ma na serwerze zdalnym.
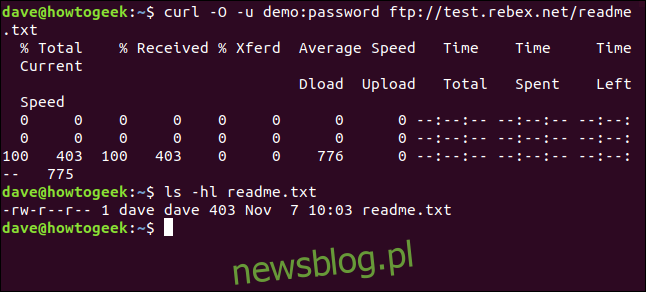
curl -O -u demo:password ftp://test.rebex.net/readme.txt
Plik zostanie pobrany i zapisany na dysku. Możemy użyć ls do sprawdzenia szczegółów pliku. Ma taką samą nazwę jak plik na serwerze FTP i ma taką samą długość, 403 bajty.
ls -hl readme.txt
Wysyłanie parametrów do serwerów zdalnych
Niektóre serwery zdalne akceptują parametry w wysyłanych do nich żądaniach. Parametry mogą służyć na przykład do formatowania zwracanych danych lub mogą być używane do wybrania dokładnych danych, które użytkownik chce pobrać. Często istnieje możliwość interakcji z siecią interfejsy programowania aplikacji (API) przy użyciu curl.
Jako prosty przykład, plik ipify strona internetowa ma interfejs API, można zapytać, aby ustalić zewnętrzny adres IP.
curl https://api.ipify.orgDodając do polecenia parametr format, o wartości „json” możemy ponownie zażądać naszego zewnętrznego adresu IP, ale tym razem zwrócone dane zostaną zakodowane w Format JSON.
curl https://api.ipify.org?format=json
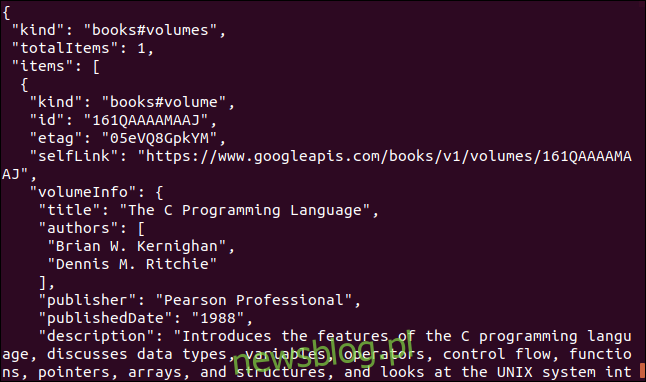
Oto kolejny przykład wykorzystujący interfejs API Google. Zwraca obiekt JSON opisujący książkę. Parametr, który musisz podać, to Międzynarodowy standardowy numer książki (ISBN) numer książki. Można je znaleźć na tylnej okładce większości książek, zwykle pod kodem kreskowym. Parametr, którego tutaj użyjemy, to „0131103628”.
curl https://www.googleapis.com/books/v1/volumes?q=isbn:0131103628
Zwracane dane są wyczerpujące:
Czasami zwijają się, czasami wget
Gdybym chciał pobrać zawartość ze strony internetowej i mieć strukturę drzewa witryny przeszukiwaną rekurencyjnie pod kątem tej treści, użyłbym wget.
Gdybym chciał wejść w interakcję ze zdalnym serwerem lub interfejsem API i ewentualnie pobrać jakieś pliki lub strony internetowe, użyłbym curl. Zwłaszcza jeśli protokół był jednym z wielu nieobsługiwanych przez wget.