Jak wyodrębnić tekst, linki i obrazy z plików PDF za pomocą języka Python
Przetwarzanie danych z plików PDF za pomocą Pythona
Python, będąc językiem o szerokim zastosowaniu, często stawia programistów przed zadaniem obsługi różnorodnych plików i pozyskiwania z nich danych. Jednym z powszechnie spotykanych formatów, z którym każdy programista Pythona prędzej czy później się zetknie, jest PDF (Portable Document Format).
Pliki PDF mogą zawierać teksty, grafiki i hiperłącza. W procesie przetwarzania danych w Pythonie, nierzadko pojawia się potrzeba wydobycia informacji zawartych w dokumentach PDF. W przeciwieństwie do prostych struktur danych jak krotki, listy czy słowniki, dostęp do danych w PDF może wydawać się skomplikowany.
Na szczęście, istnieje szereg bibliotek, które ułatwiają interakcję z plikami PDF i pozyskiwanie z nich informacji. Aby zapoznać się z tymi narzędziami, przeanalizujemy proces wydobywania tekstu, linków oraz obrazów z plików PDF. W celu dalszego śledzenia tego przewodnika, pobierz przykładowy plik PDF i umieść go w tym samym katalogu, co plik Twojego programu Python.
Ekstrakcja tekstu z PDF
Do wyodrębnienia tekstu z plików PDF przy użyciu Pythona, posłużymy się biblioteką PyPDF2. Jest to bezpłatna, otwarta biblioteka Pythona, która pozwala na łączenie, przycinanie i transformację stron PDF, dodawanie niestandardowych danych, opcji przeglądania oraz haseł. Najważniejsze jest to, że PyPDF2 umożliwia pozyskiwanie tekstu z plików PDF.
Aby zacząć korzystać z PyPDF2 do wyodrębniania tekstu, należy najpierw zainstalować ją za pomocą pip, menadżera pakietów dla Pythona. Pip pozwala instalować różne biblioteki Pythona na Twoim komputerze:
1. Sprawdź, czy pip jest zainstalowany, wpisując w terminalu:
pip --version
Jeśli nie wyświetli się numer wersji, oznacza to, że pip nie jest zainstalowany.
2. Aby zainstalować pip, kliknij pobierz pip w celu pobrania skryptu instalacyjnego.
Powyższy link przekieruje Cię do strony ze skryptem instalacyjnym pip:
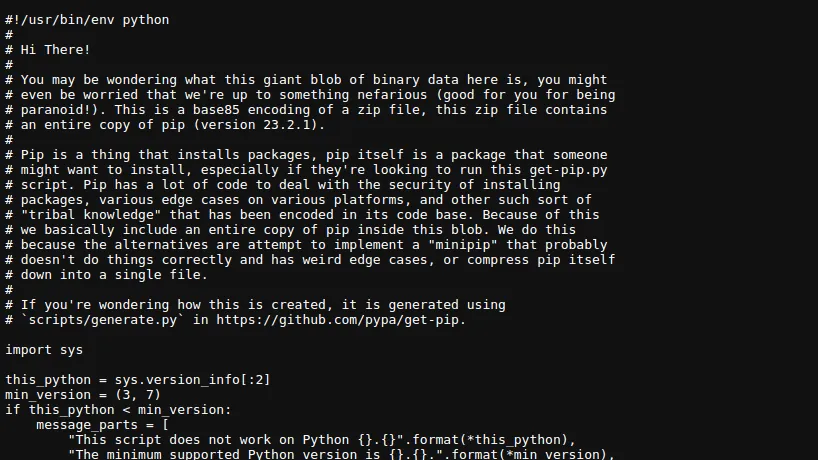
Kliknij stronę prawym przyciskiem myszy i wybierz "Zapisz jako", aby zapisać plik. Domyślna nazwa to get-pip.py.
Otwórz terminal, przejdź do folderu z zapisanym plikiem get-pip.py i wykonaj polecenie:
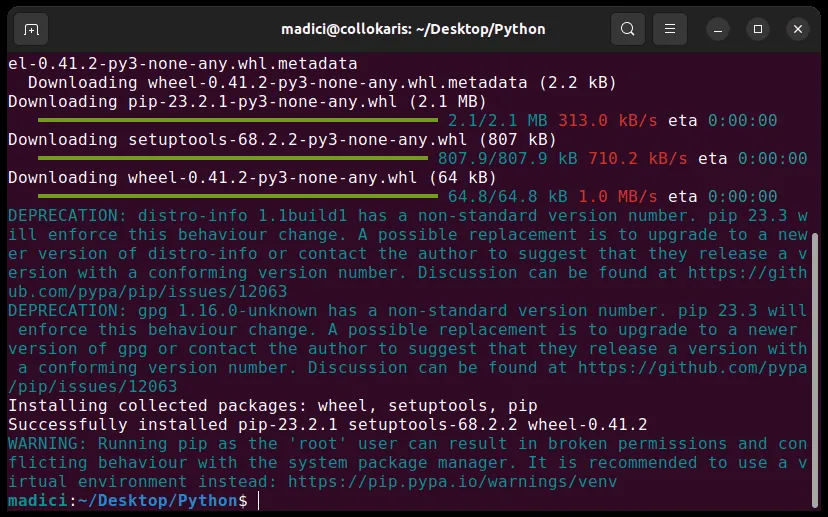
sudo python3 get-pip.py
Powinno to zainstalować pip, jak pokazano poniżej:
3. Sprawdź, czy pip został poprawnie zainstalowany, używając polecenia:
pip --version
W przypadku poprawnej instalacji, powinien pojawić się numer wersji:

Po zainstalowaniu pip, możemy rozpocząć pracę z PyPDF2.
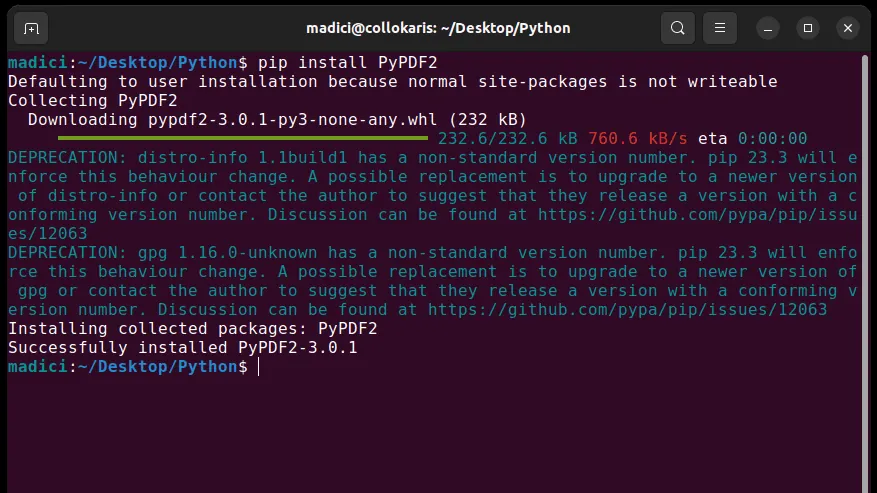
1. Zainstaluj PyPDF2, wpisując w terminalu:
pip install PyPDF2
2. Utwórz nowy plik Pythona i zaimportuj klasę PdfReader z biblioteki PyPDF2, używając poniższej linii kodu:
from PyPDF2 import PdfReader
Biblioteka PyPDF2 udostępnia różne klasy do pracy z plikami PDF. Jedną z nich jest klasa PdfReader, która umożliwia otwieranie plików PDF, odczytywanie ich zawartości i wyodrębnianie tekstu.
3. Aby zacząć pracę z plikiem PDF, należy go najpierw otworzyć. W tym celu, utwórz instancję klasy PdfReader i przekaż do niej ścieżkę do pliku PDF, z którym chcesz pracować:
reader = PdfReader('games.pdf')
Powyższa linia tworzy instancję klasy PdfReader, przygotowując ją do dostępu do zawartości pliku PDF. Instancja jest przechowywana w zmiennej o nazwie `reader`, za pomocą której będziemy mogli korzystać z metod i właściwości dostępnych w klasie PdfReader.
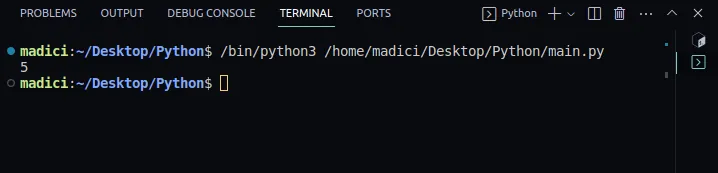
4. Aby upewnić się, że wszystko działa poprawnie, wyświetl liczbę stron w przekazanym pliku PDF, za pomocą poniższego kodu:
print(len(reader.pages))
Wynik:
5
5. Nasz przykładowy plik PDF ma 5 stron. Możemy uzyskać dostęp do każdej z nich. Numeracja stron zaczyna się od 0, tak jak indeksowanie w Pythonie. Zatem pierwsza strona ma indeks 0. Aby pobrać pierwszą stronę pliku PDF, dodaj poniższy wiersz do swojego kodu:
page1 = reader.pages[0]
Powyższa linia pobiera pierwszą stronę pliku PDF i zapisuje ją w zmiennej `page1`.
6. Aby wyodrębnić tekst z pierwszej strony pliku PDF, dodaj poniższą linię:
textPage1 = page1.extract_text()
Powyższa linia wydobędzie tekst z pierwszej strony pliku PDF i zapisze go w zmiennej o nazwie `textPage1`. Dzięki temu, będziesz miał dostęp do tekstu z pierwszej strony pliku PDF poprzez zmienną `textPage1`.
7. Aby potwierdzić, że wyodrębnianie tekstu przebiegło poprawnie, możesz wyświetlić zawartość zmiennej `textPage1`. Pełen kod, łącznie z wyświetleniem tekstu z pierwszej strony, prezentuje się następująco:
# import the PdfReader class from PyPDF2
from PyPDF2 import PdfReader
# create an instance of the PdfReader class
reader = PdfReader('games.pdf')
# get the number of pages available in the pdf file
print(len(reader.pages))
# access the first page in the pdf
page1 = reader.pages[0]
# extract the text in page 1 of the pdf file
textPage1 = page1.extract_text()
# print out the extracted text
print(textPage1)
Wynik:
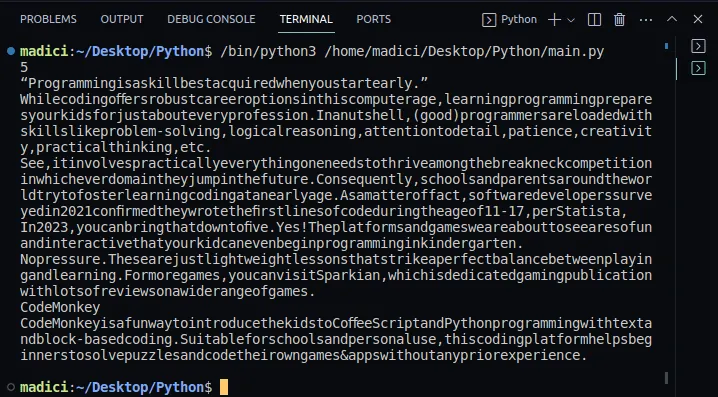
Ekstrakcja linków z PDF
Do wyodrębnienia linków z plików PDF, skorzystamy z biblioteki PyMuPDF, przeznaczonej do wyodrębniania, analizy, konwersji i manipulacji danymi zawartymi w dokumentach, takich jak pliki PDF. Aby móc korzystać z PyMuPDF, potrzebujesz Pythona w wersji 3.8 lub nowszej. Zaczynamy:
1. Zainstaluj PyMuPDF za pomocą następującego polecenia w terminalu:
pip install PyMuPDF
2. Zaimportuj PyMuPDF do swojego pliku Pythona, używając instrukcji:
import fitz
3. Aby uzyskać dostęp do pliku PDF, z którego chcesz wydobyć linki, musisz go najpierw otworzyć. Aby to zrobić, wprowadź następującą linię:
doc = fitz.open("games.pdf")
4. Po otwarciu pliku PDF, wyświetl liczbę stron w pliku PDF, za pomocą następującej linii:
print(doc.page_count)
Wynik:
5
4. Aby wydobyć linki ze strony w pliku PDF, musimy załadować stronę, z której chcemy je wydobyć. W tym celu użyjemy funkcji `load_page()`, której przekażemy numer strony, którą chcemy załadować:
page = doc.load_page(0)
Aby wydobyć linki z pierwszej strony, przekazujemy 0. Numerowanie stron zaczyna się od zera, podobnie jak w przypadku tablic i słowników.
5. Wyodrębnij linki ze strony, używając następującej linii:
links = page.get_links()
Wszystkie linki na danej stronie, w naszym przypadku na stronie 1, zostaną wyodrębnione i zapisane w zmiennej `links`.
6. Aby zobaczyć zawartość zmiennej `links`, wyświetl ją w następujący sposób:
print(links)
Wynik:
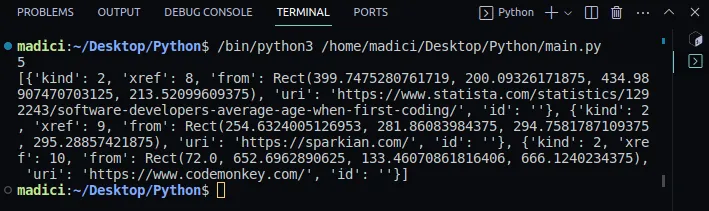
Zauważ, że na wyjściu linki są reprezentowane przez listę słowników, gdzie każdy słownik reprezentuje link na stronie. Rzeczywisty link znajduje się pod kluczem "uri".
7. Aby pobrać same linki z listy obiektów, iterujemy po liście za pomocą pętli `for` i wyświetlamy linki zapisane pod kluczem "uri". Cały kod prezentuje się następująco:
import fitz
# Open the PDF file
doc = fitz.open("games.pdf")
# Print out the number of pages
print(doc.page_count)
# load the first page from the PDF
page = doc.load_page(0)
# extract all links from the page and store it under - links
links = page.get_links()
# print the links object
#print(links)
# print the actual links stored under the key "uri"
for obj in links:
print(obj["uri"])
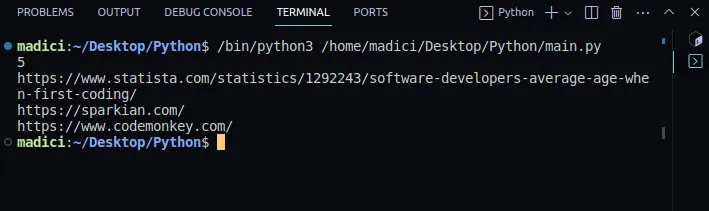
Wynik:
5 https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/
8. Aby nasz kod był bardziej uniwersalny, możemy go zrefaktoryzować i wydzielić funkcję wyodrębniającą wszystkie linki z pliku PDF oraz funkcję wyświetlającą te linki. Dzięki temu, będziesz mógł wywołać te funkcje dla dowolnego pliku PDF. Kod realizujący to zadanie przedstawia się następująco:
import fitz
# Extract all the links in a PDF document
def extract_link(path_to_pdf):
links = []
doc = fitz.open(path_to_pdf)
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
page_links = page.get_links()
links.extend(page_links)
return links
# print out all the links returned from the PDF document
def print_all_links(links):
for link in links:
print(link["uri"])
# Call the function to extract all the links in a pdf
# all the return links are stored under all_links
all_links = extract_link("games.pdf")
# call the function to print all links in the PDF
print_all_links(all_links)
Wynik:
https://www.statista.com/statistics/1292243/software-developers-average-age-when-first-coding/ https://sparkian.com/ https://www.codemonkey.com/ https://scratch.mit.edu/ https://www.tynker.com/ https://codecombat.com/ https://lightbot.com/ https://sparkian.com
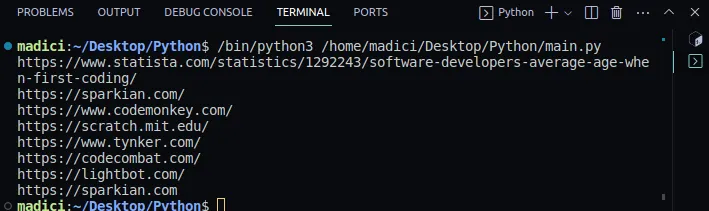
W powyższym kodzie, funkcja `extract_link()` przyjmuje ścieżkę do pliku PDF, przegląda wszystkie strony w pliku, wyodrębnia linki i zwraca je. Wynik tej funkcji jest przechowywany w zmiennej `all_links`.
Funkcja `print_all_links()` przyjmuje wynik z `extract_link()`, iteruje po nim i wyświetla wszystkie linki znalezione w pliku PDF.
Ekstrakcja obrazów z PDF
Do wyodrębnienia obrazów z plików PDF, nadal będziemy używać biblioteki PyMuPDF. Dodatkowo, wykorzystamy biblioteki `io` i PIL (Python Imaging Library). PIL udostępnia narzędzia do tworzenia i zapisywania obrazów, natomiast `io` pozwala na efektywną obsługę danych binarnych.
1. Zaimportuj biblioteki PyMuPDF, io oraz PIL:
import fitz from io import BytesIO from PIL import Image
2. Otwórz plik PDF, z którego chcesz wyodrębnić obrazy:
doc = fitz.open("games.pdf")
3. Załaduj stronę, z której chcesz wydobyć obrazy:
page = doc.load_page(0)
4. PyMuPDF identyfikuje obrazy w pliku PDF za pomocą numeru odniesienia (xref), który jest liczbą całkowitą. Każdy obraz ma unikalny numer xref. Aby wydobyć obraz, musimy najpierw uzyskać ten numer. W tym celu użyjemy funkcji `get_images()`:
image_xref = page.get_images() print(image_xref)
Wynik:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')]
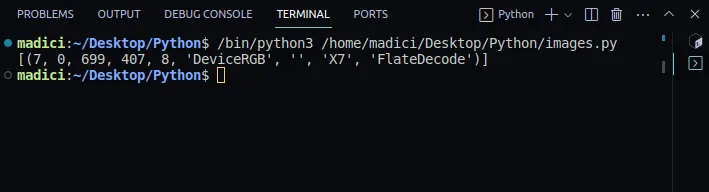
Funkcja `get_images()` zwraca listę krotek z informacjami o obrazie. Ponieważ na pierwszej stronie mamy tylko jeden obraz, jest tylko jedna krotka. Pierwszy element krotki to numer xref. Zatem xref obrazu na pierwszej stronie wynosi 7.
5. Aby wydobyć wartość xref z listy krotek, użyjemy poniższego kodu:
# get xref value of the image xref_value = image_xref[0][0] print(xref_value)
Wynik:
[(7, 0, 699, 407, 8, 'DeviceRGB', '', 'X7', 'FlateDecode')] 7
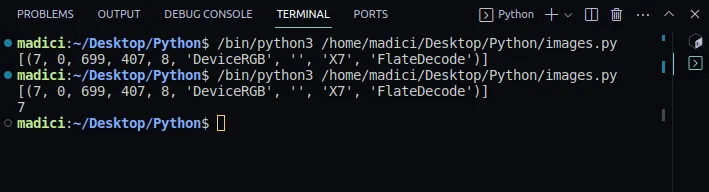
6. Posiadając xref obrazu, możemy wyodrębnić go za pomocą funkcji `extract_image()`:
img_dictionary = doc.extract_image(xref_value)
Funkcja ta nie zwraca samego obrazu, lecz słownik zawierający między innymi binarne dane obrazu oraz metadane.
7. Sprawdź rozszerzenie pliku wyodrębnionego obrazu w słowniku zwróconym przez `extract_image()`. Rozszerzenie pliku znajduje się pod kluczem "ext":
# get file extenstion img_extension = img_dictionary["ext"] print(img_extension)
Wynik:
png
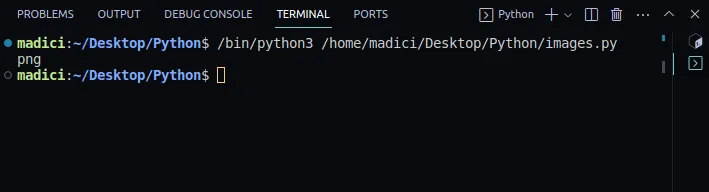
8. Wydobądź binarne dane obrazu ze słownika zapisanego w `img_dictionary`. Dane binarne znajdują się pod kluczem "image":
# get the actual image binary data img_binary = img_dictionary["image"]
9. Utwórz obiekt `BytesIO` i zainicjalizuj go binarnymi danymi obrazu. Umożliwia to bibliotekom Pythona, takim jak PIL, przetworzenie danych i zapisanie obrazu.
# create a BytesIO object to work with the image bytes image_io = BytesIO(img_binary)
10. Otwórz i przeanalizuj dane obrazu zapisane w obiekcie `BytesIO` za pomocą PIL. Pozwoli to PIL określić format obrazu, w tym przypadku PNG. Następnie PIL stworzy obiekt obrazu, którym można manipulować za pomocą różnych funkcji i metod, takich jak `save()`:
# open the image using Pillow image = Image.open(image_io)
11. Określ ścieżkę, w której chcesz zapisać obraz:
output_path = "image_1.png"
Ponieważ powyższa ścieżka zawiera tylko nazwę pliku z rozszerzeniem, obraz zostanie zapisany w tym samym katalogu, co plik Pythona zawierający ten kod. Obraz zostanie zapisany jako `image_1.png`. Rozszerzenie PNG jest ważne, aby pasowało do oryginalnego rozszerzenia obrazu.
12. Zapisz obraz i zamknij obiekt `ByteIO`:
# save the image image.save(output_path) # Close the BytesIO object image_io.close()
Poniżej przedstawiono cały kod wyodrębniający obraz z pliku PDF:
import fitz
from io import BytesIO
from PIL import Image
doc = fitz.open("games.pdf")
page = doc.load_page(0)
# get a cross reference(xref) to the image
image_xref = page.get_images()
# get the actual xref value of the image
xref_value = image_xref[0][0]
# extract the image
img_dictionary = doc.extract_image(xref_value)
# get file extenstion
img_extension = img_dictionary["ext"]
# get the actual image binary data
img_binary = img_dictionary["image"]
# create a BytesIO object to work with the image bytes
image_io = BytesIO(img_binary)
# open the image using PIL library
image = Image.open(image_io)
#specify the path where you want to save the image
output_path = "image_1.png"
# save the image
image.save(output_path)
# Close the BytesIO object
image_io.close()
Uruchom powyższy kod, a w folderze z plikiem Pythona powinien pojawić się wyodrębniony obraz o nazwie `image_1.png`:
Podsumowanie
Aby lepiej zrozumieć proces wydobywania linków, obrazów i tekstu z plików PDF, spróbuj zrefaktoryzować kod z przykładów, tak by był bardziej uniwersalny, jak to pokazano w przykładzie z linkami. W ten sposób, wystarczy przekazać plik PDF, a program wyodrębni z niego wszystkie linki, obrazy i tekst. Powodzenia w kodowaniu!
Możesz również zapoznać się z innymi interfejsami API plików PDF, które mogą być przydatne w kontekście Twojej działalności.
