

Llama 2 to model dużego języka (LLM) o otwartym kodzie źródłowym opracowany przez firmę Meta. Jest to kompetentny model wielkojęzykowy o otwartym kodzie źródłowym, prawdopodobnie lepszy niż niektóre modele zamknięte, takie jak GPT-3.5 i PaLM 2. Składa się z trzech wstępnie wytrenowanych i precyzyjnie dostrojonych rozmiarów modeli tekstu generatywnego, w tym 7 miliardów, 13 miliardów i 70 miliardów modeli parametrów.
Poznasz możliwości konwersacyjne Llama 2, budując chatbota przy użyciu Streamlit i Llama 2.
Spis treści:
Zrozumienie Lamy 2: Funkcje i zalety
Czym różni się Llama 2 od swojego poprzednika, modelu dużego języka, Lamy 1?
- Większy rozmiar modelu: model jest większy i zawiera do 70 miliardów parametrów. Dzięki temu może nauczyć się bardziej skomplikowanych skojarzeń między słowami i zdaniami.
- Ulepszone możliwości konwersacji: Uczenie się ze wzmocnieniem na podstawie opinii ludzi (RLHF) poprawia możliwości aplikacji konwersacyjnych. Dzięki temu model może generować treści przypominające ludzkie nawet w skomplikowanych interakcjach.
- Szybsze wnioskowanie: wprowadza nowatorską metodę zwaną uwagą na zapytania grupowe, która przyspiesza wnioskowanie. Dzięki temu może tworzyć bardziej przydatne aplikacje, takie jak chatboty i wirtualni asystenci.
- Bardziej wydajny: jest bardziej wydajny pod względem pamięci i zasobów obliczeniowych niż jego poprzednik.
- Licencja typu open source i niekomercyjna: Jest to oprogramowanie typu open source. Badacze i programiści mogą używać i modyfikować Lamę 2 bez ograniczeń.
Llama 2 pod każdym względem znacząco przewyższa swoją poprzedniczkę. Te cechy sprawiają, że jest to potężne narzędzie do wielu zastosowań, takich jak chatboty, wirtualni asystenci i zrozumienie języka naturalnego.
Konfigurowanie usprawnionego środowiska do tworzenia chatbotów
Aby rozpocząć budowanie aplikacji, musisz skonfigurować środowisko programistyczne. Ma to na celu odizolowanie projektu od istniejących projektów na komputerze.
Najpierw zacznij od utworzenia środowiska wirtualnego przy użyciu biblioteki Pipenv w następujący sposób:
pipenv shell
Następnie zainstaluj niezbędne biblioteki, aby zbudować chatbota.
pipenv install streamlit replicate
Streamlit: Jest to platforma aplikacji internetowych o otwartym kodzie źródłowym, która szybko renderuje aplikacje do uczenia maszynowego i analizy danych.
Replikacja: jest to platforma chmurowa zapewniająca dostęp do dużych modeli uczenia maszynowego typu open source w celu wdrożenia.
Zdobądź swój token API Lamy 2 z replikacji
Aby otrzymać klucz tokena Replikuj, należy najpierw zarejestrować konto na Replika używając swojego konta GitHub.
Po uzyskaniu dostępu do panelu przejdź do przycisku Eksploruj i wyszukaj czat Llama 2, aby zobaczyć model czatu llama-2–70b.
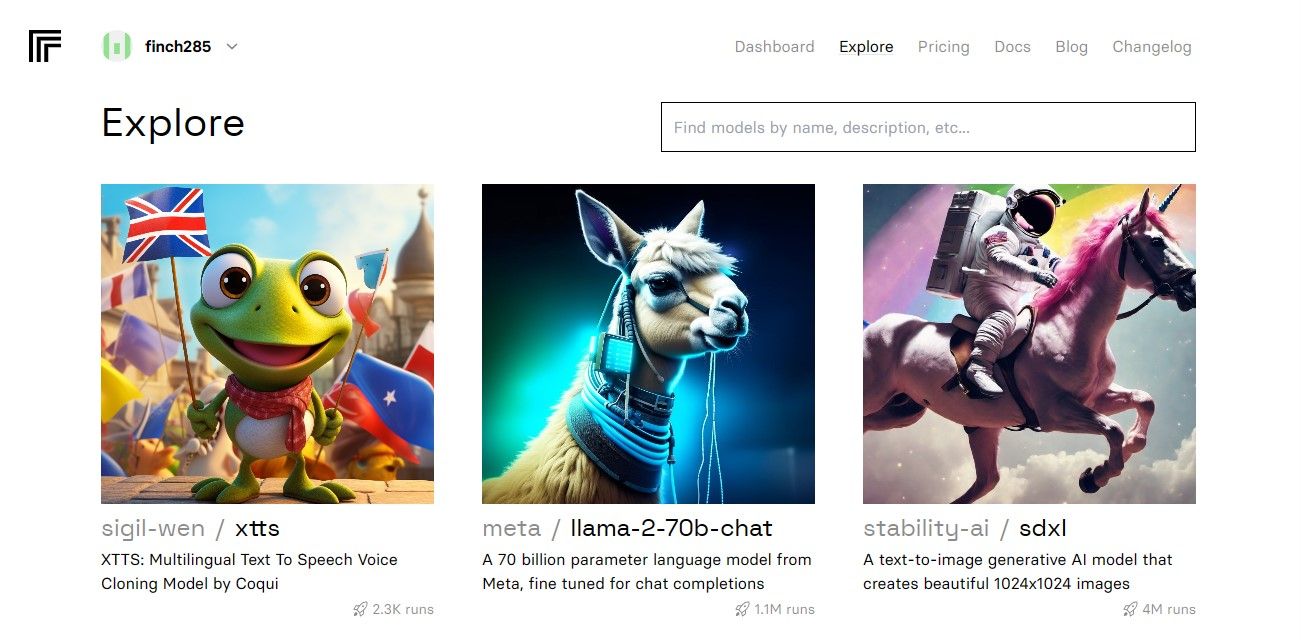
Kliknij model llama-2–70b-chat, aby wyświetlić punkty końcowe interfejsu API Lamy 2. Kliknij przycisk API na pasku nawigacyjnym modelu llama-2–70b-chat. W prawej części strony kliknij przycisk Python. Zapewni to dostęp do tokena API dla aplikacji Python.
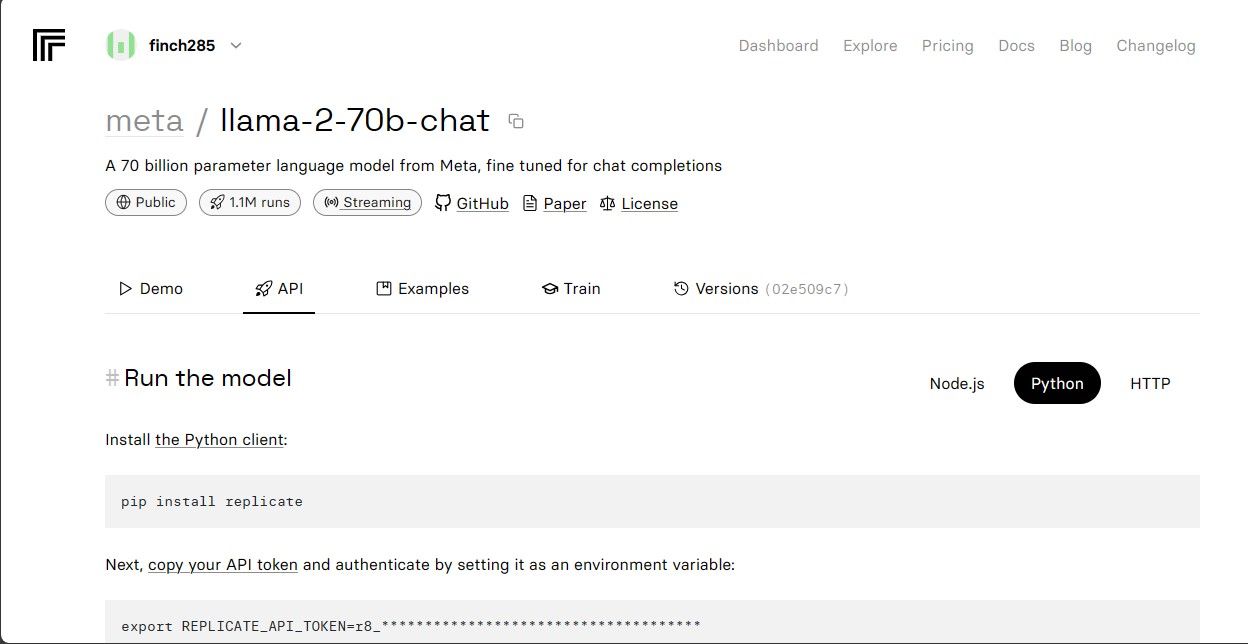
Skopiuj REPLICATE_API_TOKEN i przechowuj go w bezpiecznym miejscu do wykorzystania w przyszłości.
Budowa Chatbota
Najpierw utwórz plik Pythona o nazwie llama_chatbot.py i plik env (.env). Będziesz pisać swój kod w llama_chatbot.py i przechowywać tajne klucze i tokeny API w pliku .env.
W pliku llama_chatbot.py zaimportuj biblioteki w następujący sposób.
import streamlit as st
import os
import replicate
Następnie ustaw zmienne globalne modelu llama-2–70b-chat.
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default="")
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default="")
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default="")
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default="")
W pliku .env dodaj token replikacji i punkty końcowe modelu w następującym formacie:
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'
Wklej token replikacji i zapisz plik .env.
Projektowanie przebiegu konwersacji w Chatbocie
Utwórz monit wstępny, aby uruchomić model Lamy 2, w zależności od tego, jakie zadanie chcesz wykonać. W tym przypadku chcesz, aby model działał jako asystent.
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."
Skonfiguruj konfigurację strony dla swojego chatbota w następujący sposób:
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)
Napisz funkcję, która inicjuje i konfiguruje zmienne stanu sesji.
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPTdef setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)
Funkcja ustawia podstawowe zmienne, takie jak chat_dialogue, pre_prompt, llm, top_p, max_seq_len i temperatura w stanie sesji. Obsługuje również wybór modelu Llama 2 w oparciu o wybór użytkownika.
Napisz funkcję renderującą zawartość paska bocznego aplikacji Streamlit.
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPT
Funkcja wyświetla nagłówek i zmienne ustawień chatbota Llama 2 w celu dostosowania.
Napisz funkcję wyświetlającą historię czatów w głównym obszarze zawartości aplikacji Streamlit.
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])
Funkcja iteruje po chat_dialogue zapisanym w stanie sesji, wyświetlając każdą wiadomość z odpowiednią rolą (użytkownik lub asystent).
Obsługuj dane wejściowe użytkownika, korzystając z poniższej funkcji.
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)
Ta funkcja udostępnia użytkownikowi pole wejściowe, w którym może wpisać swoje wiadomości i pytania. Wiadomość zostanie dodana do chat_dialogue w stanie sesji z rolą użytkownika po przesłaniu wiadomości przez użytkownika.
Napisz funkcję, która generuje odpowiedzi z modelu Lamy 2 i wyświetla je w obszarze czatu.
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})
Funkcja tworzy ciąg historii konwersacji, który zawiera wiadomości zarówno użytkownika, jak i asystenta, przed wywołaniem funkcji debounce_replicate_run w celu uzyskania odpowiedzi asystenta. Stale modyfikuje odpowiedź w interfejsie użytkownika, aby zapewnić czat w czasie rzeczywistym.
Napisz główną funkcję odpowiedzialną za renderowanie całej aplikacji Streamlit.
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
Wywołuje wszystkie zdefiniowane funkcje w celu ustawienia stanu sesji, renderowania paska bocznego, historii czatów, obsługi danych wprowadzanych przez użytkownika i generowania odpowiedzi asystentów w logicznej kolejności.
Napisz funkcję wywołującą funkcję render_app i uruchamiającą aplikację po wykonaniu skryptu.
def main():
render_app()if __name__ == "__main__":
main()
Teraz Twoja aplikacja powinna być gotowa do wykonania.
Obsługa żądań API
Utwórz plik utils.py w katalogu projektu i dodaj poniższą funkcję:
import replicate
import time
last_call_time = 0
debounce_interval = 2def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)current_time = time.time()
elapsed_time = current_time - last_call_timeif elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return output
Funkcja wykonuje mechanizm odrzucania, aby zapobiec częstym i nadmiernym zapytaniom API z danych wejściowych użytkownika.
Następnie zaimportuj funkcję odpowiedzi na odrzucenie do pliku llama_chatbot.py w następujący sposób:
from utils import debounce_replicate_run
Teraz uruchom aplikację:
streamlit run llama_chatbot.py
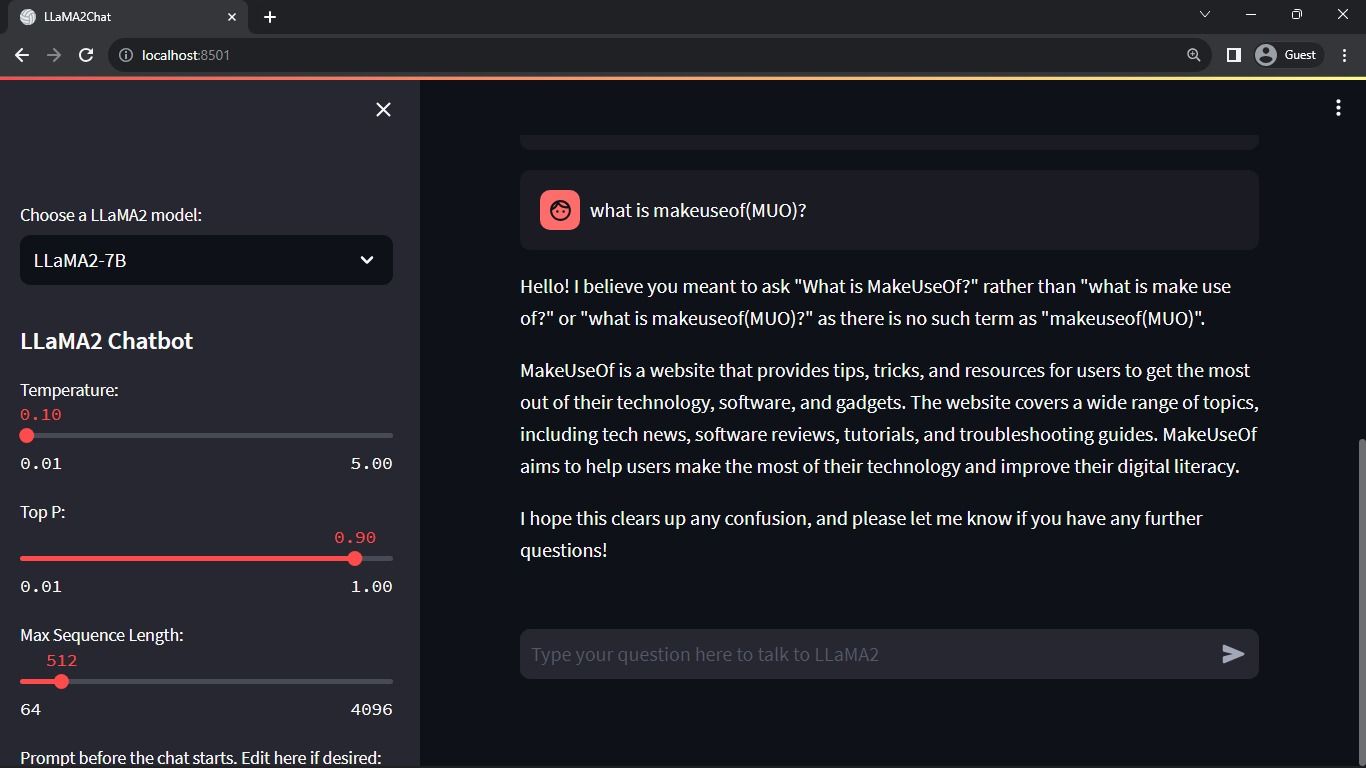
Oczekiwany wynik:
Wynik przedstawia rozmowę pomiędzy modelem a człowiekiem.
Zastosowania chatbotów Streamlit i Llama 2 w świecie rzeczywistym
Oto kilka rzeczywistych przykładów zastosowań Lamy 2:
- Chatboty: jego zastosowanie dotyczy tworzenia chatbotów reagujących na ludzi, które mogą prowadzić rozmowy w czasie rzeczywistym na kilka tematów.
- Wirtualni asystenci: jego zastosowanie dotyczy tworzenia wirtualnych asystentów, którzy rozumieją zapytania w języku ludzkim i odpowiadają na nie.
- Tłumaczenie językowe: jego użycie dotyczy zadań związanych z tłumaczeniem językowym.
- Podsumowanie tekstu: jego użycie ma zastosowanie przy podsumowywaniu dużych tekstów w krótkie teksty dla łatwego zrozumienia.
- Badania: Możesz zastosować Llamę 2 do celów badawczych, odpowiadając na pytania z różnych tematów.
Przyszłość sztucznej inteligencji
W przypadku zamkniętych modeli, takich jak GPT-3.5 i GPT-4, małym graczom jest dość trudno zbudować cokolwiek merytorycznego przy użyciu LLM, ponieważ dostęp do API modelu GPT może być dość kosztowny.
Udostępnienie społeczności programistów zaawansowanych, dużych modeli językowych, takich jak Llama 2, to dopiero początek nowej ery sztucznej inteligencji. Doprowadzi to do bardziej kreatywnego i innowacyjnego wdrażania modeli w zastosowaniach w świecie rzeczywistym, co doprowadzi do przyspieszonego wyścigu w kierunku osiągnięcia sztucznej superinteligencji (ASI).