

Skrobanie sieci to potężna technika wydobywania informacji ze stron internetowych i automatycznego ich analizowania. Chociaż można to zrobić ręcznie, może to być żmudne i czasochłonne zadanie. Narzędzia do skrobania sieci sprawiają, że proces jest szybszy i wydajniejszy, a jednocześnie kosztuje mniej.
Co ciekawe, Arkusze Google mogą stać się kompleksowym narzędziem do zbierania danych z Internetu dzięki funkcji IMPORTXML. Dzięki IMPORTXML możesz łatwo pobierać dane ze stron internetowych i używać ich do analiz, raportowania lub innych zadań opartych na danych.
Spis treści:
Funkcja IMPORTXML w Arkuszach Google
Arkusze Google udostępniają wbudowaną funkcję o nazwie IMPORTXML, która umożliwia importowanie danych z formatów internetowych, takich jak XML, HTML, RSS i CSV. Ta funkcja może zmienić zasady gry, jeśli chcesz zbierać dane ze stron internetowych bez uciekania się do skomplikowanego kodowania.
Oto podstawowa składnia IMPORTXML:
=IMPORTXML(url, xpath_query)
- url: Adres URL strony internetowej, z której chcesz pobrać dane.
- xpath_query: Zapytanie XPath definiujące dane, które chcesz wyodrębnić.
XPath (XML Path Language) to język używany do nawigacji w dokumentach XML, w tym HTML, umożliwiający określenie lokalizacji danych w strukturze HTML. Zrozumienie zapytań XPath jest niezbędne do prawidłowego korzystania z IMPORTXML.
Zrozumienie XPath
XPath udostępnia różne funkcje i wyrażenia umożliwiające nawigację i filtrowanie danych w dokumencie HTML. Obszerny przewodnik po XML i XPath wykracza poza zakres tego artykułu, dlatego poprzestaniemy na kilku podstawowych koncepcjach XPath:
- Wybór elementu: Możesz wybierać elementy za pomocą / i // do oznaczenia ścieżek. Na przykład /html/body/div zaznacza wszystkie elementy div w treści dokumentu.
- Wybór atrybutu: Aby wybrać atrybuty, możesz użyć @. Na przykład //@href wybiera wszystkie atrybuty href na stronie.
- Filtry predykatów: Możesz filtrować elementy za pomocą predykatów ujętych w nawiasy kwadratowe ([ ]). Na przykład /div[@class=”container”] wybiera wszystkie elementy div z kontenerem klasy.
- Funkcje: XPath udostępnia różne funkcje, takie jak zawiera(), zaczyna się od() i tekst(), aby wykonywać określone działania, takie jak sprawdzanie zawartości tekstowej lub wartości atrybutów.
Jak na razie znasz składnię IMPORTXML, znasz adres URL witryny i wiesz, który element chcesz wyodrębnić. Ale jak uzyskać XPath elementu?
Nie musisz znać na pamięć struktury witryny internetowej, aby wyodrębnić jej dane za pomocą IMPORTXML. Tak naprawdę każda przeglądarka ma przydatne narzędzie, które umożliwia natychmiastowe skopiowanie ścieżki XPath dowolnego elementu.
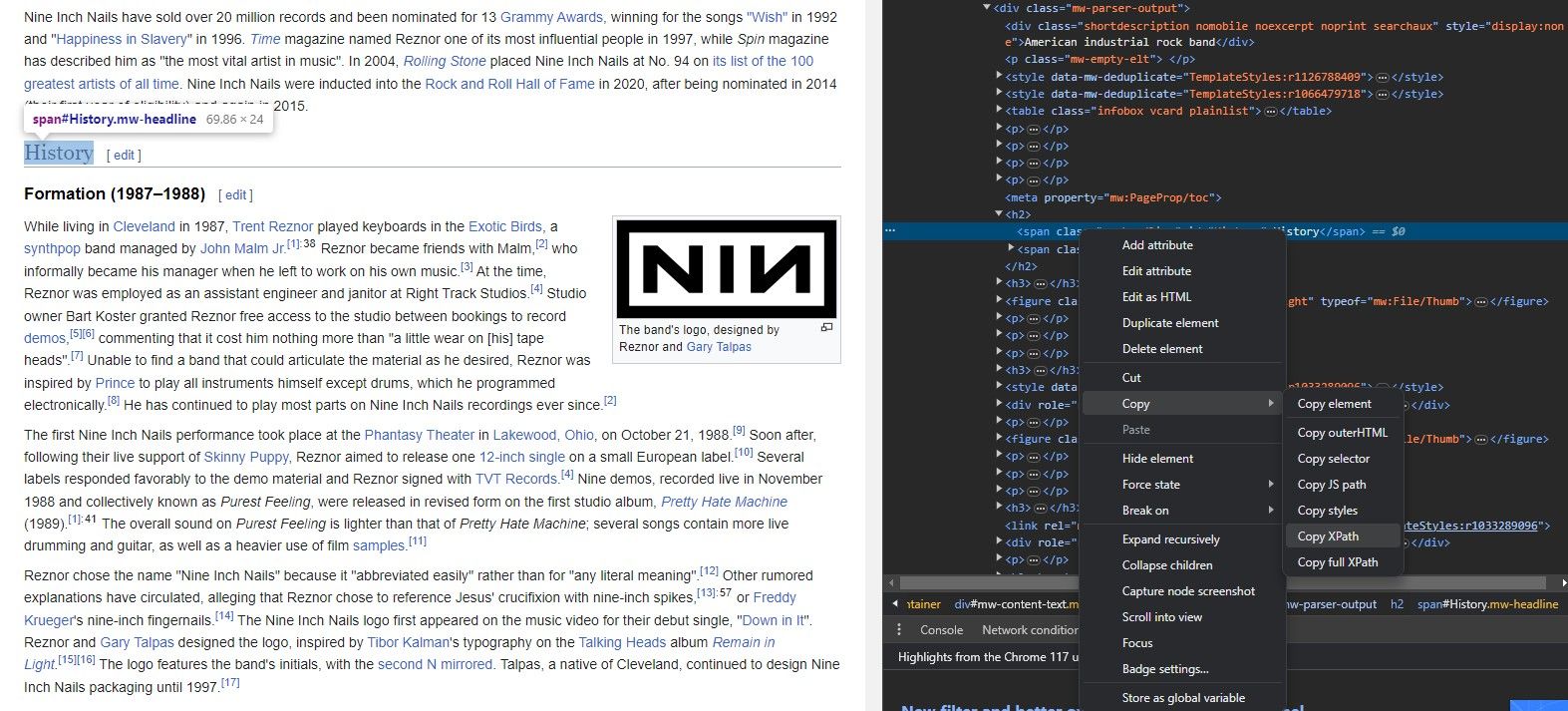
Narzędzie Sprawdź element umożliwia wyodrębnienie ścieżki XPath z elementów witryny internetowej. Oto jak:
Teraz, gdy masz już wszystko, czego potrzebujesz, czas zobaczyć IMPORTXML w akcji i zeskrobać kilka linków.
Jak zeskrobać linki ze strony internetowej za pomocą IMPORTXML
Możesz użyć IMPORTXML do zeskrobania wszelkiego rodzaju danych ze stron internetowych. Obejmuje to linki, filmy, obrazy i prawie każdy element witryny. Linki są jednym z najważniejszych elementów analizy sieciowej i można się wiele dowiedzieć o witrynie internetowej, analizując strony, do których prowadzą linki.
IMPORTXML umożliwia szybkie pobieranie linków z Arkuszy Google, a następnie ich dalszą analizę przy użyciu różnych funkcji oferowanych przez Arkusze Google.
1. Skrobanie wszystkich linków
Aby zeskrobać wszystkie linki ze strony internetowej, możesz użyć następującej formuły:
=IMPORTXML(url, "//a/@href")
To zapytanie XPath wybiera wszystkie atrybuty href elementów, skutecznie wyodrębniając wszystkie linki na stronie.
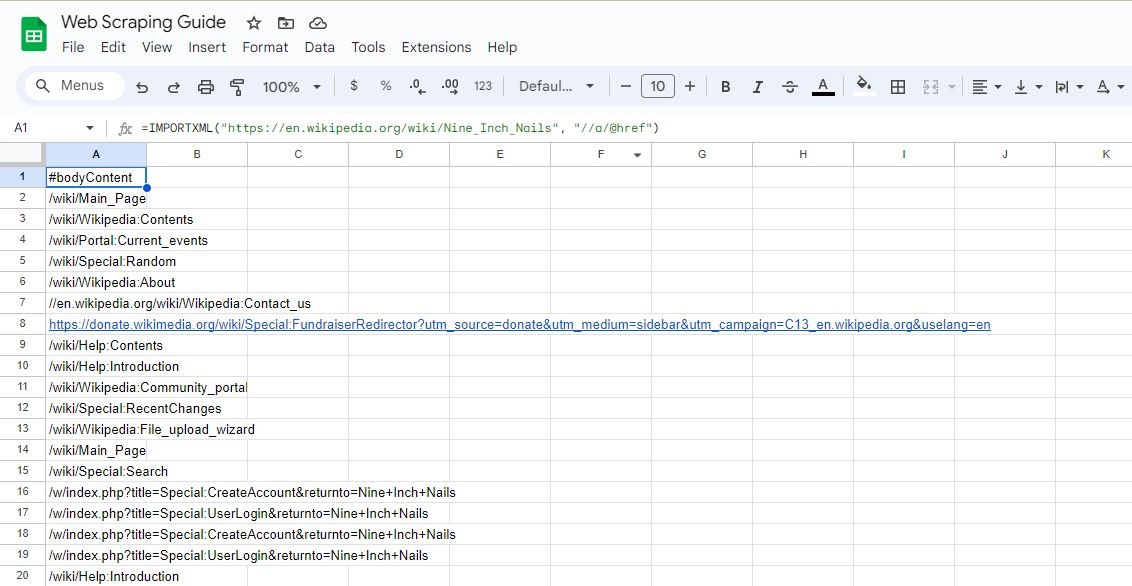
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")
Powyższa formuła usuwa wszystkie linki z artykułu w Wikipedii.
Dobrym pomysłem jest wprowadzenie adresu URL strony internetowej w osobnej komórce, a następnie odwołanie się do tej komórki. Dzięki temu formuła nie stanie się zbyt długa i nieporęczna. To samo możesz zrobić z zapytaniem XPath.
2. Skrobanie wszystkich tekstów linków
Aby wyodrębnić tekst linków wraz z ich adresami URL, możesz użyć:
=IMPORTXML(url, "//a")
To zapytanie wybiera wszystkie elementy, a z wyników można wyodrębnić tekst łącza i adresy URL.
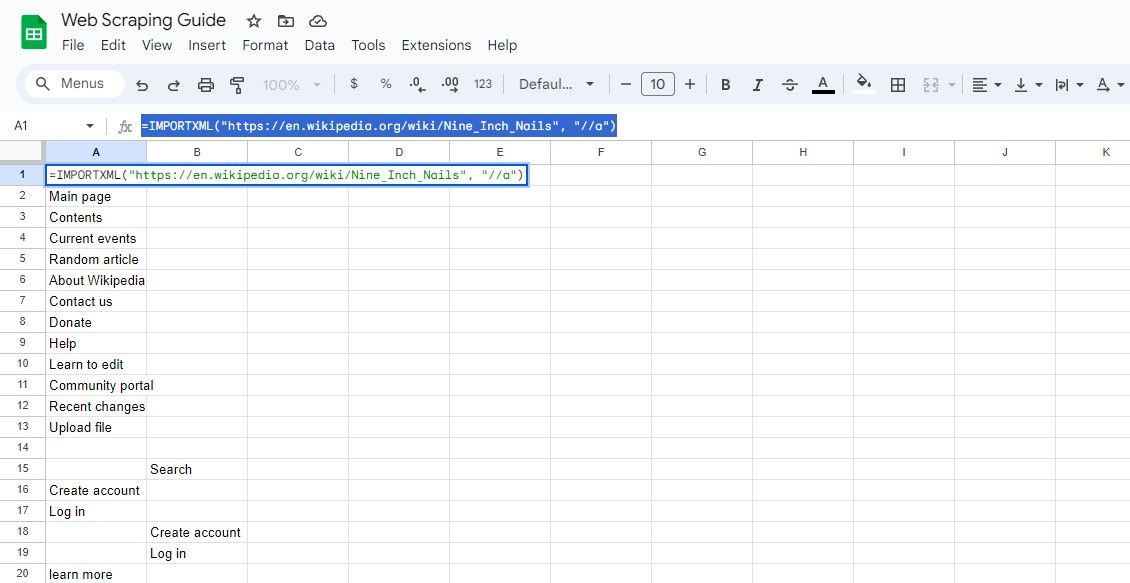
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a")
Powyższa formuła pobiera teksty linków w tym samym artykule w Wikipedii.
Jak zeskrobać określone linki ze strony internetowej za pomocą IMPORTXML
Czasami może być konieczne zeskrobanie określonych linków w oparciu o kryteria. Na przykład możesz być zainteresowany wyodrębnieniem linków zawierających określone słowo kluczowe lub linków znajdujących się w określonej sekcji strony.
Dzięki odpowiedniej znajomości XPath możesz wskazać dowolny element, którego szukasz.
1. Skrobanie linków zawierających słowo kluczowe
Aby zeskrobać linki zawierające określone słowo kluczowe, możesz użyć funkcji XPath zawiera() :
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")
To zapytanie wybiera atrybuty href elementów, w których href zawiera określone słowo kluczowe.
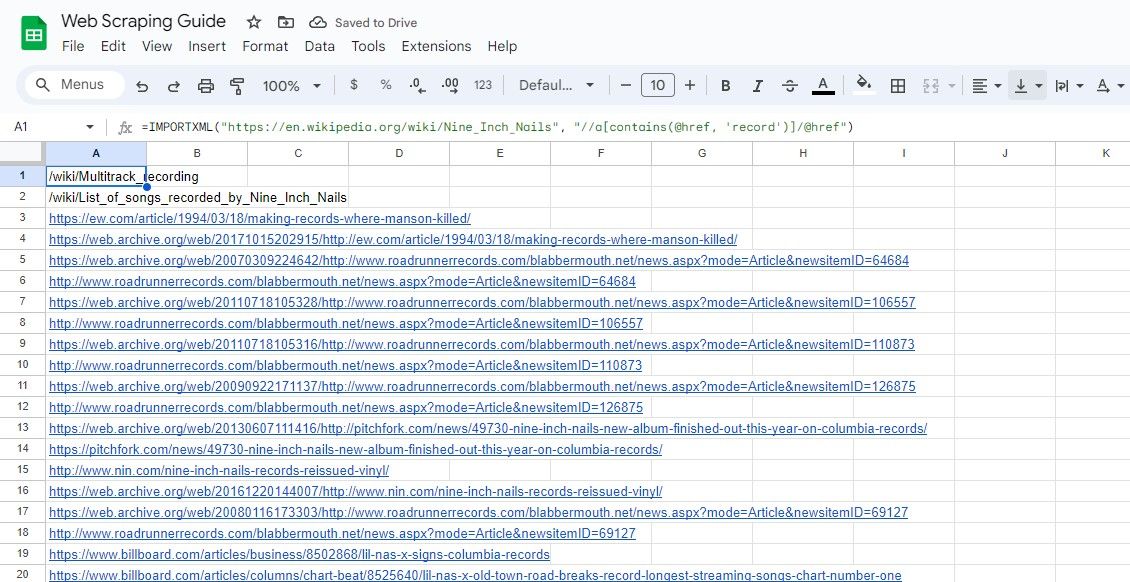
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")
Powyższa formuła usuwa wszystkie linki zawierające słowo rekord w tekście w przykładowym artykule w Wikipedii.
2. Skrobanie linków w sekcji
Aby pobrać linki z określonej sekcji strony, możesz określić XPath sekcji. Na przykład:
=IMPORTXML(url, "//div[@class="section"]//a/@href")
To zapytanie wybiera atrybuty href elementów znajdujących się w elementach div z klasą „sekcja”.
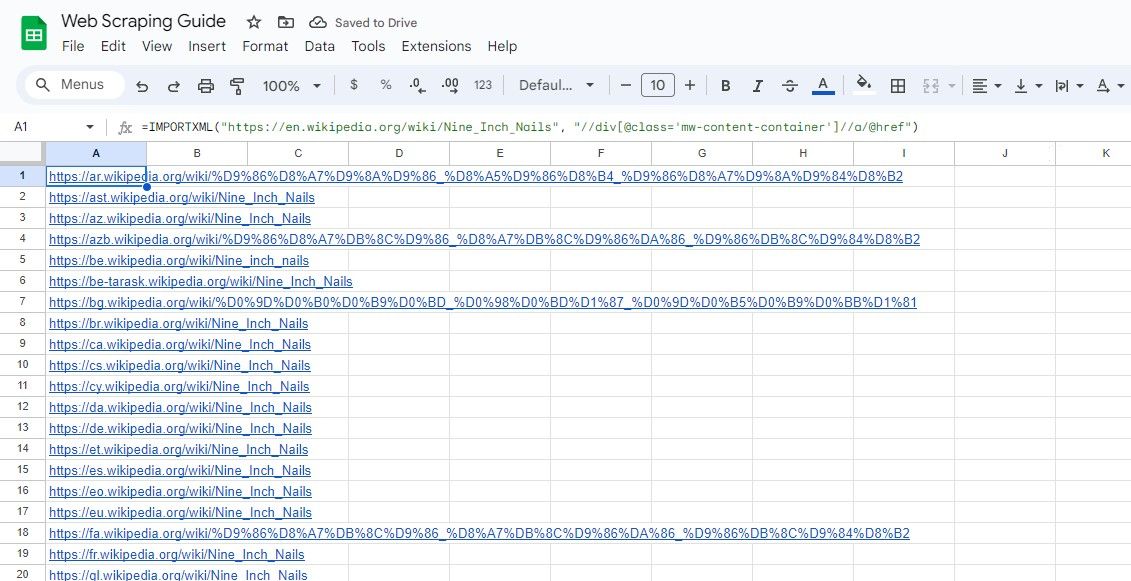
Podobnie poniższa formuła wybiera wszystkie linki w klasie div, które mają klasę mw-content-container:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class="mw-content-container"]//a/@href")
Warto zauważyć, że IMPORTXML można używać nie tylko do skrobania stron internetowych. Za pomocą rodziny funkcji IMPORT możesz importować tabele danych ze stron internetowych do Arkuszy Google.
Chociaż Arkusze Google i Excel mają wspólną większość funkcji, rodzina funkcji IMPORT jest dostępna wyłącznie w Arkuszach Google. Należy rozważyć inne metody importowania danych z witryn internetowych do programu Excel.
Uprość przeglądanie Internetu za pomocą Arkuszy Google
Skrobanie sieci za pomocą Arkuszy Google i funkcji IMPORTXML to wszechstronny i przystępny sposób gromadzenia danych ze stron internetowych.
Opanowując XPath i rozumiejąc, jak tworzyć efektywne zapytania, możesz odblokować pełny potencjał IMPORTXML i uzyskać cenne informacje z zasobów sieciowych. Zacznij więc skrobanie i przenieś analizę sieci na wyższy poziom!