Najlepsze biblioteki Pythona dla naukowców zajmujących się danymi
Ten artykuł przybliża i omawia wybrane, kluczowe biblioteki Pythona, które są nieocenione dla specjalistów analizujących dane oraz zespołów pracujących nad uczeniem maszynowym.
Python, dzięki swojemu bogatemu ekosystemowi bibliotek, stał się językiem pierwszego wyboru w tych dynamicznie rozwijających się dziedzinach.
Wysoka popularność Pythona wynika z dostępności bibliotek dedykowanych do operacji wejścia/wyjścia danych, ich analizy, a także innych form manipulacji, które są nieodzowne w pracy analityków danych i ekspertów od uczenia maszynowego.
Czym są biblioteki Pythona?
Biblioteka Pythona to rozbudowany zbiór gotowych modułów, które zawierają skompilowany kod, w tym klasy i metody. Dzięki temu programiści nie muszą tworzyć kodu od podstaw, co znacznie przyspiesza proces tworzenia oprogramowania.
Rola Pythona w analizie danych i uczeniu maszynowym
Python oferuje znakomity wybór bibliotek, które są szczególnie cenione przez specjalistów od uczenia maszynowego i analityki danych.
Jego przejrzysta i prosta składnia umożliwia efektywne implementowanie nawet najbardziej zaawansowanych algorytmów uczenia maszynowego. Co więcej, łatwość nauki języka Python sprawia, że jest on dostępny dla szerokiego grona odbiorców.
Python to także idealne narzędzie do szybkiego prototypowania i testowania nowych aplikacji.
Aktywna i liczna społeczność Pythona to nieocenione wsparcie dla naukowców danych, którzy w razie potrzeby mogą szybko znaleźć odpowiedzi na swoje pytania.
Jak przydatne są biblioteki Pythona?
Biblioteki Pythona są fundamentem tworzenia aplikacji i modeli w dziedzinie uczenia maszynowego i analizy danych.
Umożliwiają one programistom efektywne ponowne wykorzystanie kodu. Zamiast wymyślać koło na nowo, można po prostu zaimportować bibliotekę, która zawiera już potrzebną funkcjonalność.
Biblioteki Pythona w uczeniu maszynowym i analizie danych
Eksperci w dziedzinie Data Science polecają szereg bibliotek Pythona, które powinien znać każdy, kto interesuje się tą tematyką. Biblioteki te, w zależności od swojego przeznaczenia, dzielą się na te służące do implementacji modeli, pozyskiwania danych, przetwarzania oraz wizualizacji.
Ten artykuł przedstawia niektóre z najpopularniejszych bibliotek Pythona używanych w analizie danych i uczeniu maszynowym.
Zapraszamy do dalszej lektury i poznania tych narzędzi.
Numpy
Numpy, czyli Numerical Python, to biblioteka zbudowana na bazie zoptymalizowanego kodu C. Jest ceniona przez naukowców danych za swoje zaawansowane możliwości obliczeń matematycznych i naukowych.
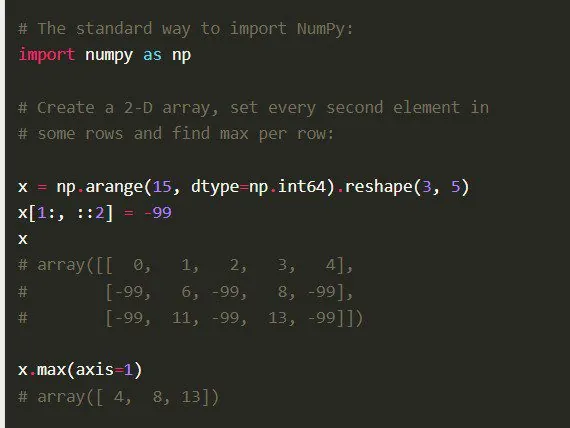
Charakterystyka
- Numpy charakteryzuje się prostą i intuicyjną składnią, co ułatwia pracę programistom o różnym poziomie zaawansowania.
- Wysoka wydajność biblioteki jest efektem zastosowania dobrze zoptymalizowanego kodu C.
- Oferuje szeroki wachlarz narzędzi do obliczeń numerycznych, w tym transformacje Fouriera, algebrę liniową i generatory liczb losowych.
- Jako oprogramowanie open-source, Numpy stale się rozwija dzięki wkładowi licznej społeczności programistów.
Numpy posiada również zaawansowane funkcje, takie jak wektoryzacja operacji matematycznych, indeksowanie oraz kluczowe koncepcje w implementacji tablic i macierzy.
Pandas
Pandas to popularna biblioteka do uczenia maszynowego, która oferuje zaawansowane struktury danych i narzędzia do analizy dużych zbiorów danych. Pozwala ona na wykonywanie złożonych operacji na danych za pomocą kilku prostych poleceń.
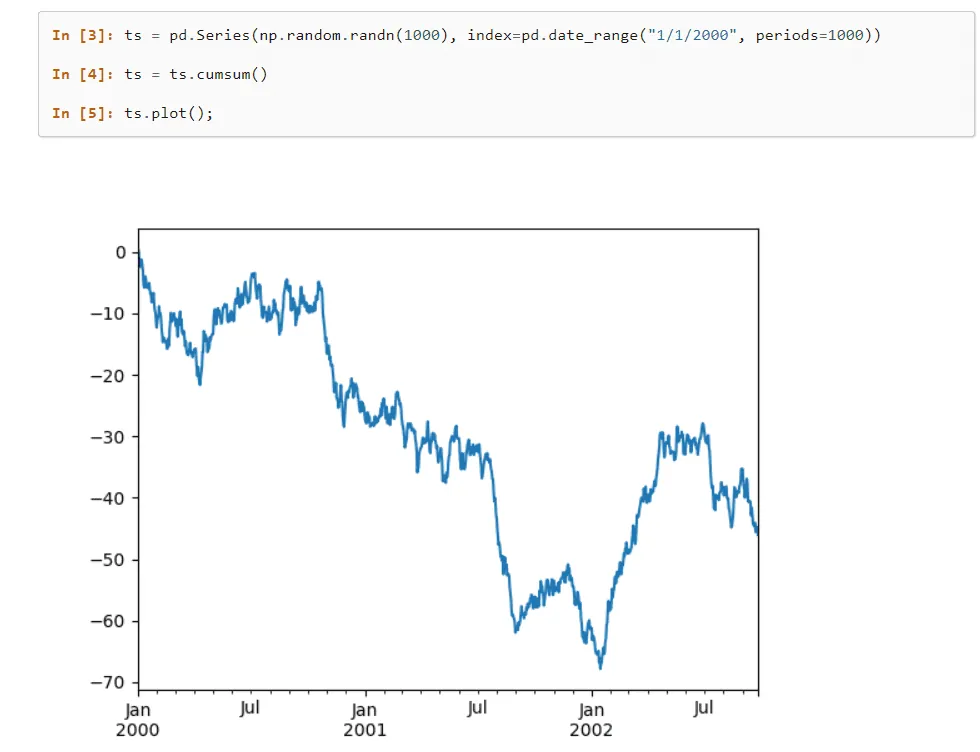
Biblioteka ta zawiera liczne wbudowane metody, które umożliwiają grupowanie, indeksowanie, pobieranie, dzielenie, restrukturyzację i filtrowanie danych, a także ich umieszczanie w tabelach jedno- i wielowymiarowych.
Najważniejsze cechy Pandy
- Pandy ułatwiają etykietowanie danych w tabelach, automatycznie je wyrównując i indeksując.
- Biblioteka umożliwia szybkie wczytywanie i zapisywanie danych w różnych formatach, takich jak JSON i CSV.
Pandy charakteryzuje wysoka wydajność, elastyczność i rozbudowana funkcjonalność analizy danych.
Matplotlib
Matplotlib to biblioteka Pythona do tworzenia wykresów 2D, która obsługuje dane z różnych źródeł. Umożliwia generowanie statycznych, animowanych i interaktywnych wizualizacji, które można dowolnie powiększać i dostosowywać pod względem układu i stylu.
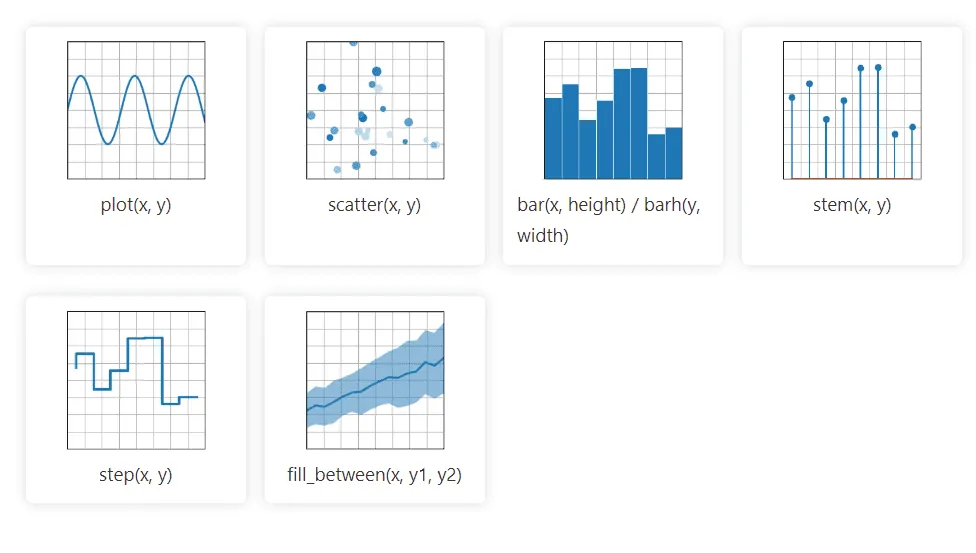
Matplotlib jest open-source i posiada bogatą dokumentację oraz liczne narzędzia ułatwiające implementację wizualizacji.
Biblioteka importuje także pomocnicze klasy do obsługi danych czasowych (rok, miesiąc, dzień, tydzień), co znacznie ułatwia ich manipulację.
Scikit-learn
Jeśli potrzebujesz biblioteki do pracy z złożonymi danymi, Scikit-learn będzie idealnym wyborem. Jest ona powszechnie wykorzystywana przez ekspertów uczenia maszynowego i współpracuje z takimi bibliotekami jak NumPy, SciPy i Matplotlib. Oferuje zarówno nadzorowane, jak i nienadzorowane algorytmy uczenia, które można stosować w aplikacjach produkcyjnych.
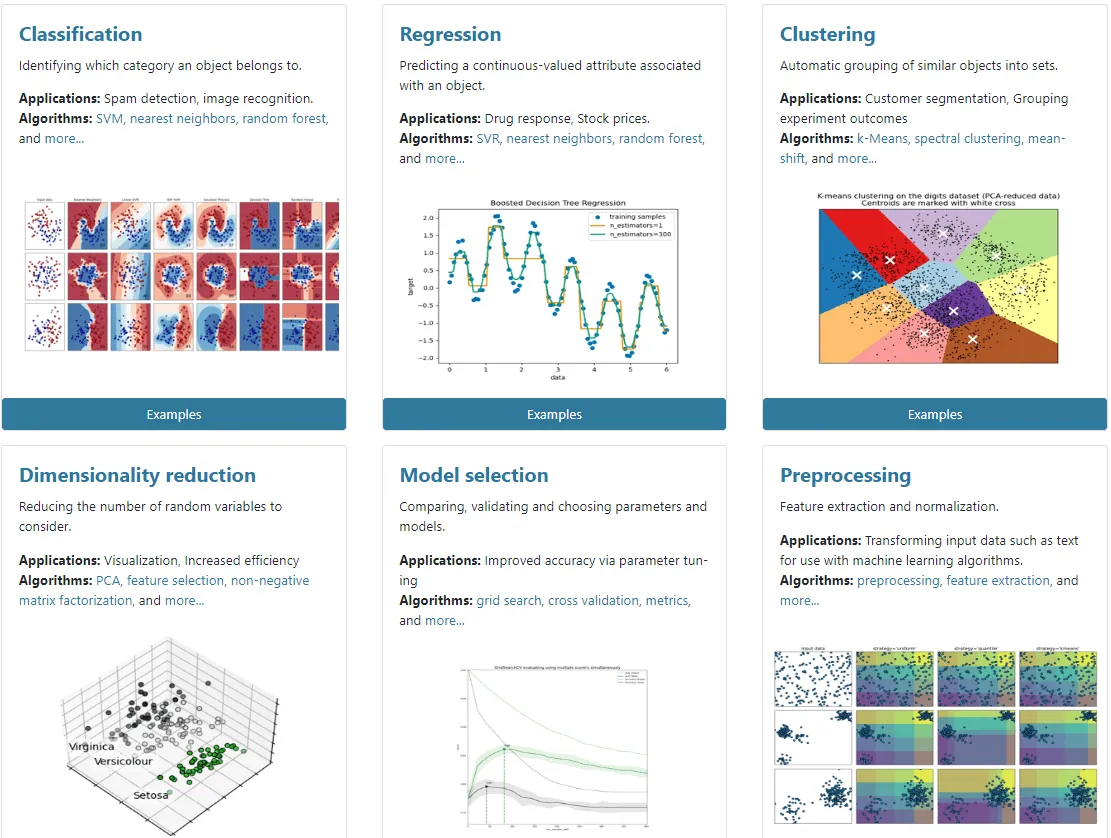
Funkcje Scikit-learn
- Identyfikacja kategorii obiektów (np. za pomocą algorytmów SVM i lasu losowego w rozpoznawaniu obrazów).
- Przewidywanie atrybutów o wartościach ciągłych (regresja).
- Ekstrakcja cech.
- Redukcja wymiarowości danych.
- Grupowanie podobnych obiektów w zbiory.
Scikit-learn jest wydajny w ekstrakcji cech z danych tekstowych i graficznych. Ponadto umożliwia sprawdzanie dokładności modeli na niewidzianych danych oraz oferuje szeroki wybór algorytmów do analizy danych i uczenia maszynowego.
SciPy
SciPy (Scientific Python) to biblioteka oferująca moduły do zaawansowanych obliczeń matematycznych i algorytmów, które znajdują szerokie zastosowanie. Biblioteka ta umożliwia rozwiązywanie równań algebraicznych, interpolację, optymalizację, obliczenia statystyczne i całkowanie.
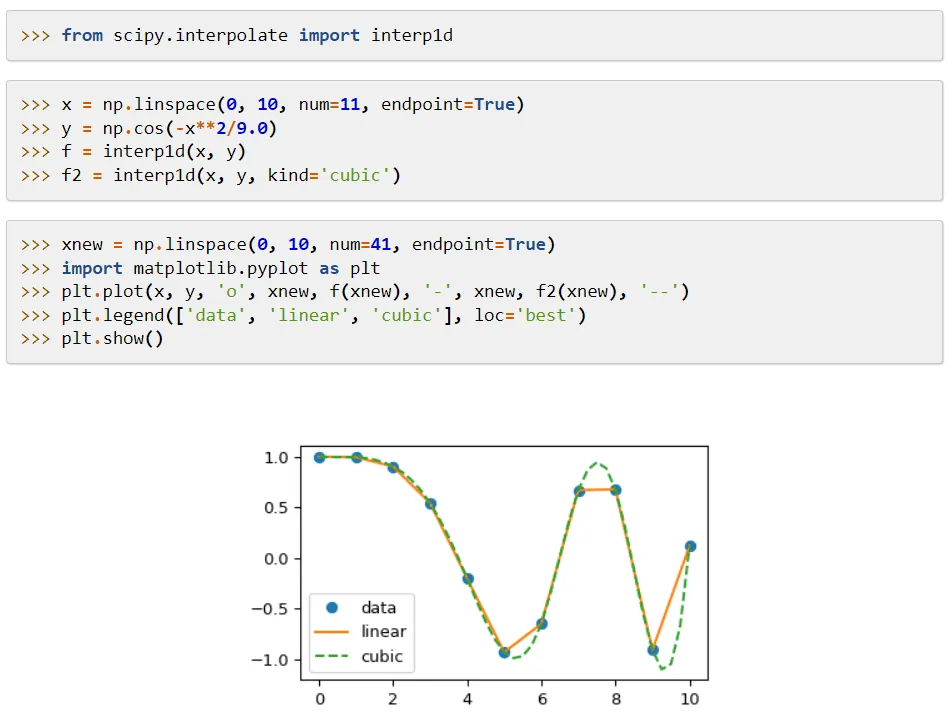
Jej kluczową cechą jest rozszerzenie funkcjonalności NumPy o narzędzia do rozwiązywania funkcji matematycznych i struktury danych, takie jak macierze rzadkie.
SciPy wykorzystuje polecenia i klasy wysokiego poziomu do manipulacji i wizualizacji danych. Jej możliwości przetwarzania danych i prototypowania sprawiają, że jest to wyjątkowo efektywne narzędzie.
Dodatkowo, składnia SciPy jest prosta i intuicyjna, co ułatwia korzystanie z niej programistom o różnym poziomie doświadczenia.
Jedyną wadą SciPy jest jej koncentracja na obiektach numerycznych i algorytmach, przez co nie oferuje funkcji związanych z kreśleniem wykresów.
PyTorch
PyTorch to wszechstronna biblioteka do uczenia maszynowego, która efektywnie implementuje obliczenia tensorowe z akceleracją GPU, generuje dynamiczne wykresy obliczeniowe oraz umożliwia automatyczne obliczenia gradientów. Jest to biblioteka open-source, która powstała na bazie biblioteki Torch napisanej w C.
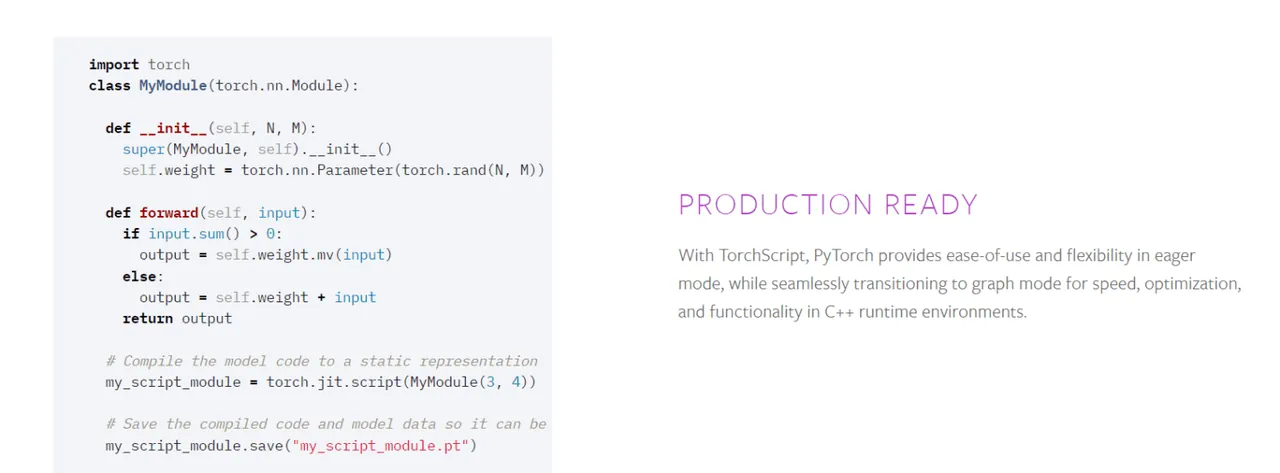
Kluczowe cechy PyTorch
- Umożliwia sprawny rozwój i skalowanie aplikacji dzięki wsparciu dla głównych platform chmurowych.
- Posiada bogaty ekosystem narzędzi i bibliotek, które wspierają rozwój w obszarze widzenia komputerowego i przetwarzania języka naturalnego (NLP).
- Umożliwia płynne przejście między trybami ekspertyzy i grafu za pomocą Torch Script oraz przyspiesza proces wdrażania w środowisku produkcyjnym dzięki TorchServe.
- Rozproszony backend Torch umożliwia rozproszone szkolenie modeli i optymalizację wydajności w badaniach i w środowisku produkcyjnym.
PyTorch jest szeroko stosowany w tworzeniu aplikacji z zakresu NLP.
Keras
Keras to otwarta biblioteka Pythona do uczenia maszynowego, która jest wykorzystywana do eksperymentowania z głębokimi sieciami neuronowymi.
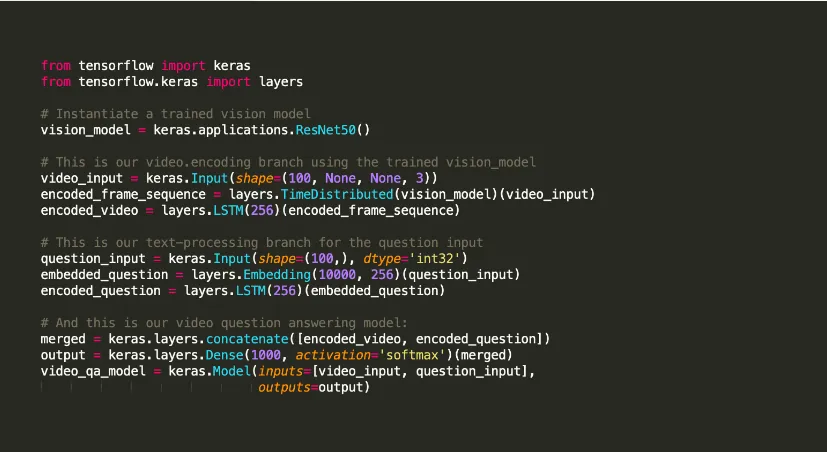
Keras oferuje narzędzia, które wspierają kompilację modeli i wizualizację wykresów. Biblioteka wykorzystuje Tensorflow jako swoje zaplecze. Alternatywnie, można także skorzystać z Theano lub CNTK. Infrastruktura zaplecza pomaga w tworzeniu wykresów obliczeniowych używanych do implementacji operacji.
Najważniejsze funkcje Keras
- Keras może wydajnie działać zarówno na CPU, jak i GPU.
- Debugowanie jest uproszczone dzięki oparciu o język Python.
- Keras jest modułowy, dzięki czemu jest elastyczny i wyrazisty.
- Keras można wdrożyć w dowolnym miejscu, eksportując moduły do JavaScript i uruchamiając je w przeglądarce.
Keras oferuje elementy składowe sieci neuronowych (warstwy, cele) oraz inne narzędzia ułatwiające pracę z obrazami i danymi tekstowymi.
Seaborn
Seaborn to kolejne przydatne narzędzie do wizualizacji danych statystycznych.
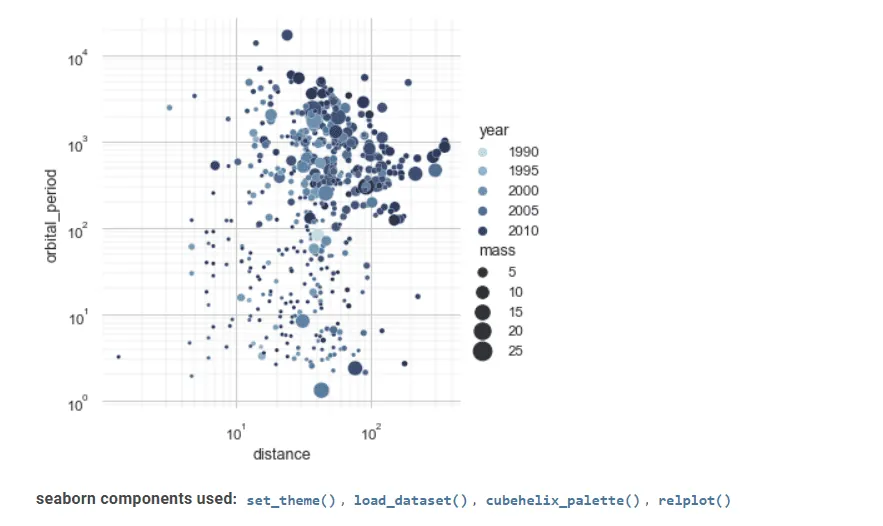
Jego zaawansowany interfejs umożliwia tworzenie atrakcyjnych i informatywnych wykresów statystycznych.
Plotly
Plotly to internetowe narzędzie do wizualizacji 3D, oparte na bibliotece Plotly JS. Obsługuje wiele typów wykresów, takich jak liniowe, punktowe i pudełkowe.
Plotly jest wykorzystywany m.in. do tworzenia internetowych wizualizacji danych w notatnikach Jupyter.
Plotly umożliwia wykrywanie wartości odstających na wykresie za pomocą narzędzia „najechania kursorem”. Użytkownik ma także możliwość dostosowania wyglądu wykresów do swoich potrzeb.
Wadą Plotly jest nieaktualna dokumentacja, która może utrudnić naukę i korzystanie z narzędzia. Dodatkowo, konieczność nauki wielu funkcji i opcji może stanowić wyzwanie dla niektórych użytkowników.
Funkcje Plotly
- Wykorzystuje wykresy 3D, które umożliwiają interakcję z danymi na wielu poziomach.
- Posiada przejrzystą i uproszczoną składnię.
- Pozwala na zachowanie prywatności kodu podczas dzielenia się punktami na wykresie.
SimpleITK
SimpleITK to biblioteka do analizy obrazów, która udostępnia interfejs do Insight Toolkit (ITK). Biblioteka oparta jest na C++ i jest open-source.
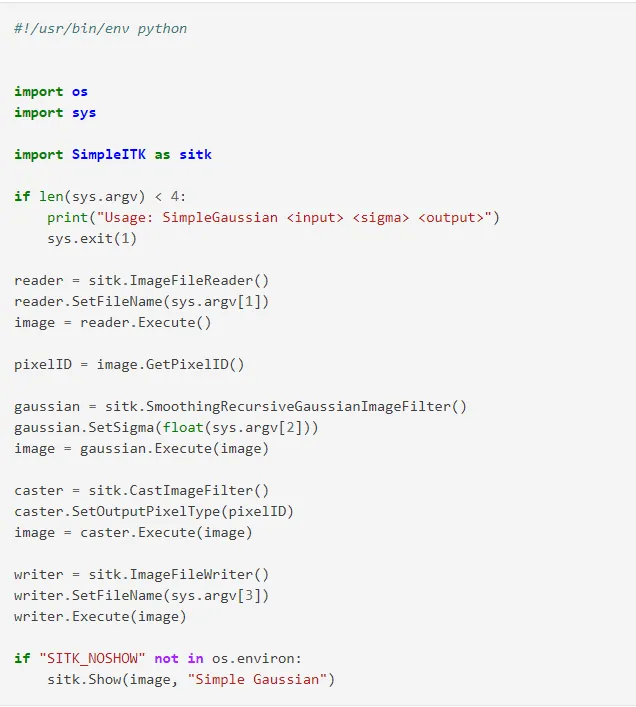
Funkcje SimpleITK
- Obsługuje wiele formatów plików graficznych (ok. 20), w tym JPG, PNG i DICOM, umożliwiając konwersję między nimi.
- Oferuje liczne filtry do segmentacji obrazów, w tym Otsu, zestawy poziomów i zlewiska.
- Interpretuje obrazy jako obiekty przestrzenne, a nie tylko zbiór pikseli.
Uproszczony interfejs biblioteki jest dostępny w różnych językach programowania, takich jak R, C#, C++, Java i Python.
Statsmodels
Statsmodels umożliwia szacowanie modeli statystycznych, przeprowadzanie testów statystycznych i eksplorację danych za pomocą klas i funkcji.
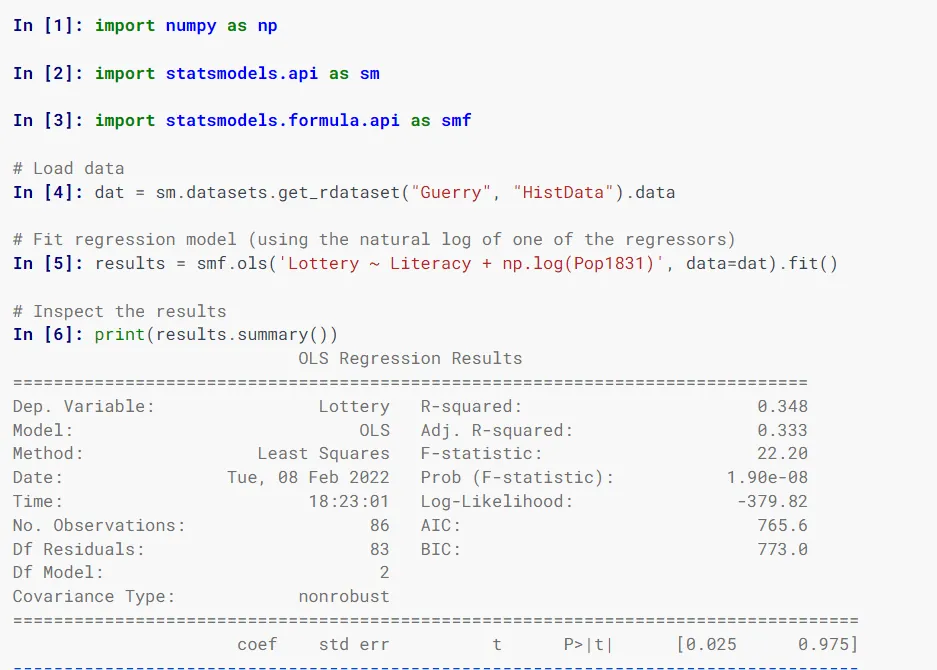
Do określania modeli wykorzystuje się formuły w stylu R, tablice NumPy i ramki danych Pandas.
Scrapy
Scrapy to pakiet open-source, który jest wykorzystywany do pobierania i indeksowania danych ze stron internetowych. Jest asynchroniczny, co przekłada się na relatywnie wysoką szybkość. Scrapy posiada architekturę i funkcje, które czynią go wydajnym.
Instalacja biblioteki jest uzależniona od systemu operacyjnego. Scrapy nie może być używany na stronach zbudowanych w JS. Dodatkowo, działa jedynie z Pythonem w wersji 2.7 lub nowszej.
Specjaliści od Data Science wykorzystują Scrapy w eksploracji danych i automatycznym testowaniu.
Główne cechy Scrapy
- Umożliwia eksport kanałów w formatach JSON, CSV i XML oraz ich zapis w różnych bazach danych.
- Posiada wbudowaną funkcjonalność do pobierania i ekstrakcji danych ze źródeł HTML/XML.
- Dostępne API pozwala na rozszerzanie funkcjonalności Scrapy.
Pillow
Pillow to biblioteka Pythona do przetwarzania i manipulacji obrazami.
Rozszerza możliwości interpretera Pythona o funkcje przetwarzania obrazu, obsługuje różne formaty plików i oferuje doskonałą reprezentację wewnętrzną obrazów.
Pillow umożliwia łatwy dostęp do danych w różnych formatach plików.
Podsumowanie
To podsumowuje nasze omówienie najlepszych bibliotek Pythona dla analityków danych i ekspertów od uczenia maszynowego.
Jak pokazuje ten artykuł, Python oferuje wiele przydatnych pakietów do uczenia maszynowego i analizy danych, a także wiele innych bibliotek, które mogą być wykorzystywane w innych obszarach.
Może Cię także zainteresować lista najlepszych notatników do analizy danych.
Życzymy owocnej nauki!
