Naucz się inżynierii funkcji w zakresie analityki danych i uczenia maszynowego w 5 minut
Chcesz zgłębić tajniki inżynierii cech, kluczowego elementu uczenia maszynowego i analizy danych? Świetnie trafiłeś!
Inżynieria cech to niezwykle ważna umiejętność, która pozwala na wydobywanie wartościowych wniosków z surowych danych. W tym zwięzłym przewodniku przedstawimy ją w przystępny i zrozumiały sposób. Ruszajmy więc w podróż ku mistrzostwu w tworzeniu cech!
Czym właściwie jest inżynieria cech?

Podczas tworzenia modelu uczenia maszynowego, który ma rozwiązać konkretny problem biznesowy lub badawczy, dostarczasz dane w postaci tabeli z kolumnami i wierszami. W świecie nauki o danych oraz rozwoju uczenia maszynowego, kolumny te są określane mianem atrybutów lub zmiennych.
Szczegółowe dane, czyli wiersze znajdujące się pod tymi kolumnami, nazywamy obserwacjami lub instancjami. Kolumny, a więc atrybuty, stanowią podstawowy element surowego zbioru danych.
Jednak te surowe cechy często nie są wystarczające lub optymalne do skutecznego trenowania modeli uczenia maszynowego. Aby zredukować szum w zebranych metadanych i wydobyć jak najwięcej unikalnych sygnałów z cech, konieczna jest transformacja lub konwersja kolumn metadanych w funkcjonalne cechy – właśnie to jest istotą inżynierii cech.
Przykład 1: Modelowanie finansowe
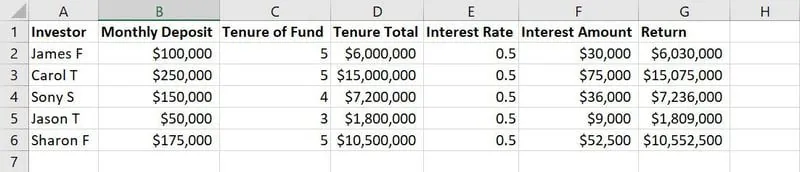 Surowe dane do trenowania modelu ML
Surowe dane do trenowania modelu ML
Na przykładzie powyższej tabeli, kolumny od A do G to cechy. Wartości lub teksty w każdej kolumnie, takie jak nazwiska, kwoty depozytów, lata trwania depozytów, stopy procentowe itp., to obserwacje.
W modelowaniu uczenia maszynowego, dane są modyfikowane – usuwane, dodawane, łączone lub przekształcane, aby wygenerować istotne cechy i zmniejszyć ogólną wielkość bazy danych treningowych modelu. Właśnie to jest inżynierią cech w praktyce.
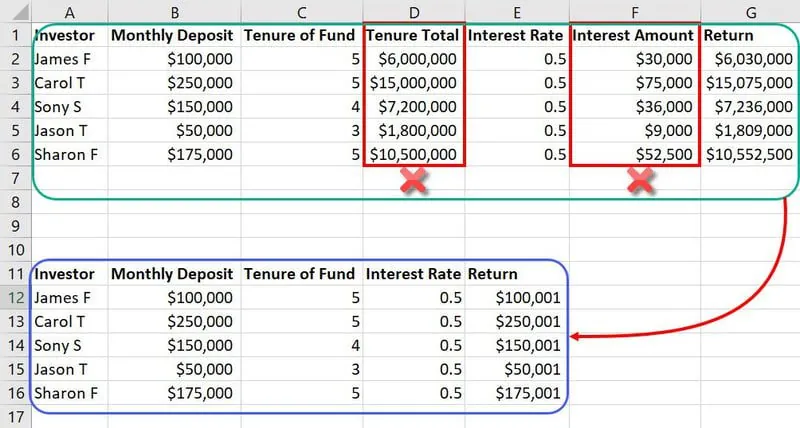 Przykład inżynierii cech
Przykład inżynierii cech
W kontekście wcześniejszego zbioru danych, cechy takie jak "całkowity staż" i "kwota odsetek" mogą okazać się zbędnymi danymi wejściowymi. Zajmują one dodatkowe miejsce i mogą wprowadzać zamieszanie do modelu ML. Dzięki inżynierii cech, można zredukować liczbę cech z siedmiu do pięciu.
Ponieważ bazy danych w modelach uczenia maszynowego często zawierają tysiące kolumn i miliony wierszy, ograniczenie nawet dwóch cech może mieć znaczący wpływ na projekt.
Przykład 2: Tworzenie playlist muzycznych za pomocą AI
Czasami istnieje możliwość utworzenia całkowicie nowej cechy na podstawie kilku już istniejących. Wyobraźmy sobie, że tworzysz model sztucznej inteligencji, który automatycznie tworzy playlisty muzyczne, dobierając utwory na podstawie wydarzenia, gustu, nastroju, itp.
Zgromadziłeś dane o piosenkach i muzyce z różnych źródeł i stworzyłeś poniższą bazę danych:
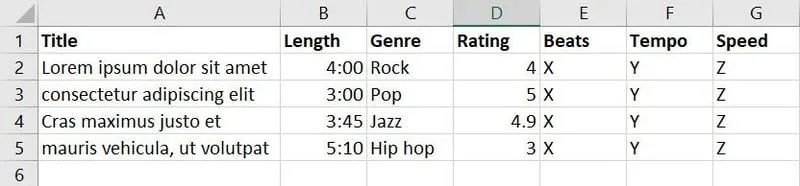
W tej bazie danych znajduje się siedem cech. Jednak Twoim celem jest wytrenowanie modelu ML, który zdecyduje, który utwór pasuje do danego wydarzenia. W tym celu możesz połączyć cechy takie jak gatunek, ocena, rytm, tempo i prędkość w nową cechę o nazwie "Przydatność".
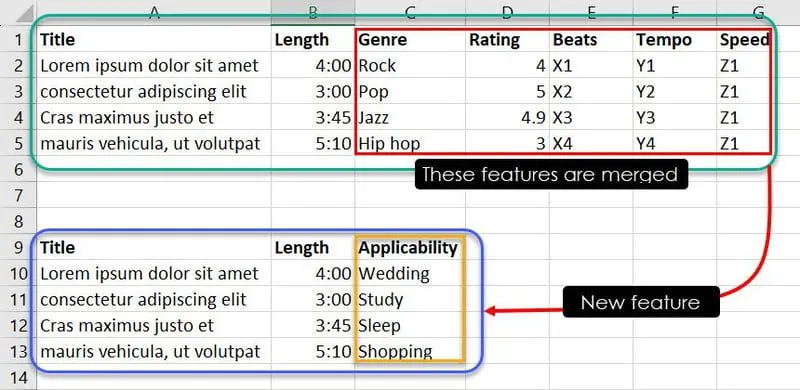
Dzięki specjalistycznej wiedzy lub rozpoznawaniu wzorców, możesz powiązać konkretne kombinacje cech, aby określić, który utwór jest odpowiedni na dane wydarzenie. Na przykład, obserwacje takie jak "Jazz, 4.9, X3, Y3, Z1" mogą sugerować modelowi ML, że utwór "Cras maximus justo et" powinien znaleźć się na playliście użytkownika, który szuka muzyki relaksacyjnej do snu.
Rodzaje cech w uczeniu maszynowym
Cechy kategoryczne
Są to atrybuty danych, które reprezentują odrębne kategorie lub etykiety. Ten typ cech jest wykorzystywany do opisywania danych jakościowych.
#1. Porządkowe cechy kategoryczne
Cechy porządkowe charakteryzują się kategoriami o określonym porządku. Na przykład, poziomy wykształcenia (szkoła średnia, licencjat, magister) mają ustaloną hierarchię, ale różnice między nimi nie są ilościowe.
#2. Nominalne cechy kategoryczne
Cechy nominalne to kategorie bez wewnętrznego porządku. Przykładami mogą być kolory, kraje lub rodzaje zwierząt. W tym przypadku występują tylko różnice jakościowe.
Cechy tablicowe
Ten typ cech reprezentuje dane zorganizowane w postaci tablic lub list. Analitycy danych i programiści ML często wykorzystują cechy tablicowe do przetwarzania sekwencji lub osadzania danych kategorycznych.
#1. Osadzanie cech tablicowych
Osadzanie tablic polega na konwersji danych kategorycznych na gęste wektory. Jest to powszechnie stosowane w systemach przetwarzania języka naturalnego i rekomendacyjnych.
#2. Listy cech tablicowych
Tablice list przechowują sekwencje danych, takie jak uporządkowane listy elementów lub historię zdarzeń.
Cechy numeryczne
Te cechy treningowe są wykorzystywane do wykonywania operacji matematycznych, ponieważ reprezentują dane ilościowe.
#1. Przedziałowe cechy numeryczne
Cechy interwałowe mają stałe odstępy między wartościami, ale nie posiadają prawdziwego punktu zerowego. Przykładem mogą być dane z pomiarów temperatury. Zero w tym przypadku oznacza temperaturę zamarzania, ale sam atrybut nadal istnieje.
#2. Stosunkowe cechy numeryczne
Cechy stosunkowe mają stałe odstępy między wartościami oraz posiadają prawdziwy punkt zerowy. Przykładami mogą być wiek, wzrost lub dochód.
Znaczenie inżynierii cech w uczeniu maszynowym i nauce o danych
- Efektywna inżynieria cech podnosi dokładność modeli, dzięki czemu prognozy stają się bardziej wiarygodne i wartościowe w procesie podejmowania decyzji.
- Staranny dobór cech eliminuje nieistotne lub zbędne atrybuty, upraszczając modele i oszczędzając zasoby obliczeniowe.
- Dobrze zaprojektowane cechy ujawniają ukryte wzorce w danych, co pozwala analitykom na lepsze zrozumienie złożonych zależności w zbiorze danych.
- Dostosowanie cech do konkretnych algorytmów pozwala na optymalizację wydajności modelu w różnych metodach uczenia maszynowego.
- Dobre cechy prowadzą do szybszego uczenia modeli i niższych kosztów obliczeniowych, co usprawnia cały proces uczenia maszynowego.
Teraz omówimy krok po kroku proces inżynierii cech.
Proces inżynierii cech krok po kroku

- Gromadzenie danych: Pierwszym krokiem jest zebranie surowych danych z różnorodnych źródeł, takich jak bazy danych, pliki lub interfejsy API.
- Czyszczenie danych: Po zebraniu dane muszą zostać poddane procesowi czyszczenia, który polega na identyfikacji i naprawie wszelkich błędów, niespójności lub wartości odstających.
- Obsługa brakujących wartości: Brakujące wartości mogą negatywnie wpływać na działanie modelu uczenia maszynowego. Ich zignorowanie może skutkować tendencyjnym modelem. Konieczne jest więc dokładne zbadanie i wprowadzenie brakujących wartości lub ostrożne ich pominięcie, tak aby nie wprowadzały zakłóceń do modelu.
- Kodowanie zmiennych kategorycznych: Zmienne kategoryczne muszą zostać przekształcone do formatu liczbowego, który jest zrozumiały dla algorytmów uczenia maszynowego.
- Skalowanie i normalizacja: Skalowanie zapewnia, że wszystkie cechy numeryczne mają spójną skalę, co zapobiega dominacji cech o dużych wartościach.
- Wybór cech: Ten krok ma na celu zidentyfikowanie i zachowanie najbardziej istotnych cech, co zmniejsza wymiarowość danych i poprawia wydajność modelu.
- Tworzenie cech: Czasami warto tworzyć nowe cechy na podstawie istniejących, aby uchwycić dodatkowe, wartościowe informacje.
- Transformacja cech: Techniki transformacji, takie jak logarytmowanie lub transformacje potęgowe, mogą uczynić dane bardziej przydatnymi do modelowania.
Teraz przejdziemy do omówienia konkretnych metod inżynierii cech.
Metody inżynierii cech
#1. Analiza Głównych Składowych (PCA)
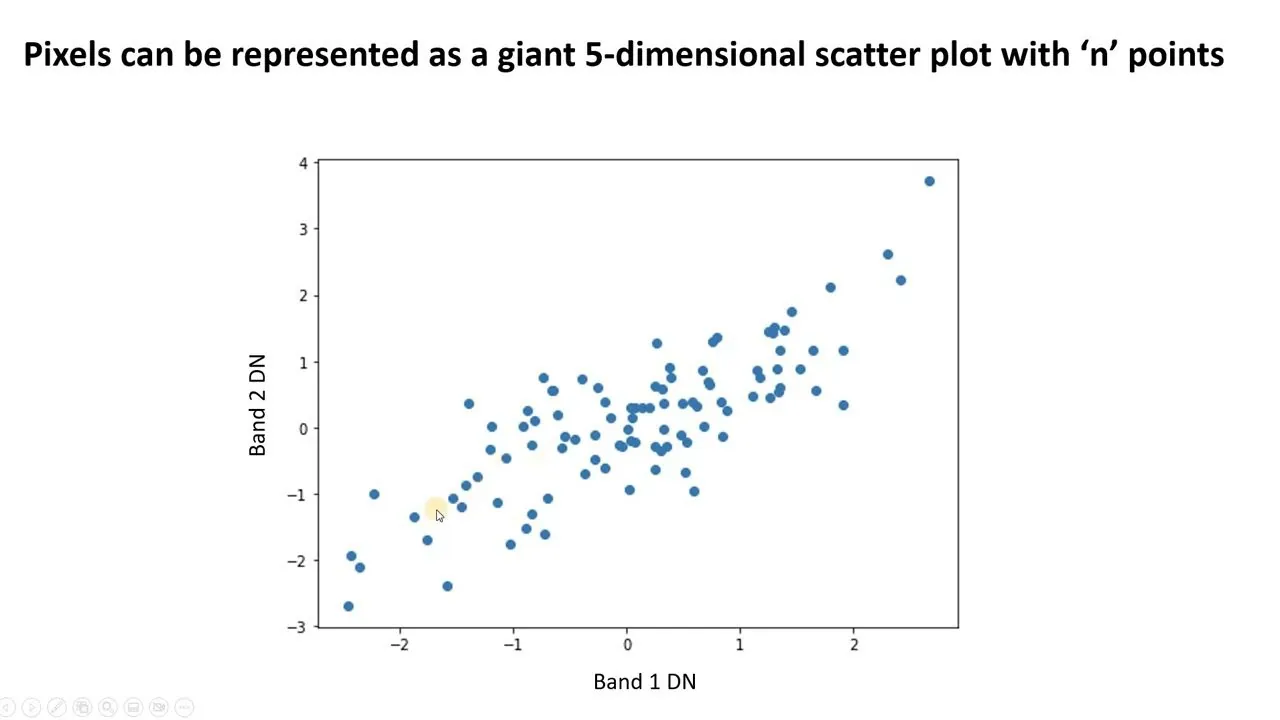
PCA upraszcza złożone dane, identyfikując nowe, nieskorelowane cechy, nazywane głównymi składowymi. Ta metoda pozwala na redukcję wymiarowości i poprawę wydajności modelu.
#2. Cechy wielomianowe
Tworzenie cech wielomianowych polega na dodawaniu potęg istniejących cech, co umożliwia uchwycenie bardziej złożonych zależności w danych. Pomaga to modelowi w zrozumieniu nieliniowych wzorców.
#3. Obsługa wartości odstających
Wartości odstające to nietypowe punkty danych, które mogą negatywnie wpływać na działanie modeli. Dlatego ważne jest, aby je identyfikować i odpowiednio nimi zarządzać, by uniknąć wypaczonych wyników.
#4. Transformacja logarytmiczna
Transformacja logarytmiczna pomaga w normalizacji danych o skośnym rozkładzie. Zmniejsza ona wpływ wartości ekstremalnych, dzięki czemu dane stają się bardziej przydatne do modelowania.
#5. t-rozproszone stochastyczne osadzanie sąsiada (t-SNE)
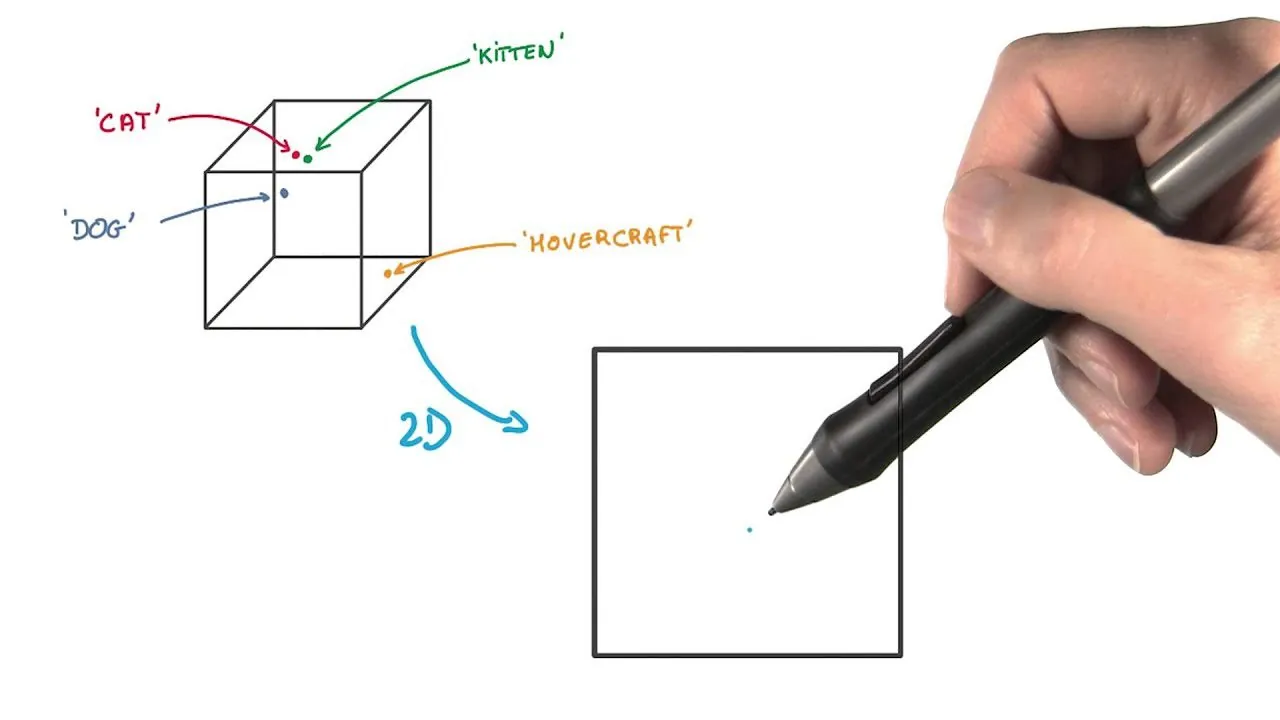
t-SNE jest użyteczne do wizualizacji danych wielowymiarowych. Redukuje wymiarowość i ułatwia dostrzeganie skupisk danych, przy jednoczesnym zachowaniu ich struktury.
W tej metodzie, punkty danych są przedstawiane jako punkty w przestrzeni o niższej liczbie wymiarów. Podobne punkty danych, które były blisko siebie w pierwotnej przestrzeni wielowymiarowej, są również modelowane tak, aby znajdowały się blisko siebie w reprezentacji niskowymiarowej.
W odróżnieniu od innych metod redukcji wymiarowości, t-SNE zachowuje strukturę i odległości między punktami danych.
#6. Kodowanie One-Hot
Kodowanie One-Hot przekształca zmienne kategoryczne na format binarny (0 lub 1). W rezultacie, dla każdej kategorii powstaje nowa kolumna binarna. Kodowanie typu "one-hot" sprawia, że dane kategoryczne stają się kompatybilne z algorytmami uczenia maszynowego.
#7. Kodowanie zliczeniowe
Kodowanie zliczeniowe zastępuje wartości kategoryczne liczbą ich wystąpień w zbiorze danych. W ten sposób można przechwycić istotne informacje z zmiennych kategorycznych.
W tej technice inżynierii cech, częstotliwość lub liczba każdej kategorii jest wykorzystywana jako nowa cecha numeryczna, zamiast oryginalnych etykiet kategorii.
#8. Standaryzacja cech

Cechy o większych wartościach często dominują nad cechami o mniejszych wartościach. W rezultacie, model ML może być łatwo obciążony. Standaryzacja zapobiega takim źródłom błędów w modelach uczenia maszynowego.
Proces normalizacji obejmuje zazwyczaj dwie popularne techniki:
- Standaryzacja Z-Score: Ta metoda przekształca każdą cechę tak, aby jej średnia (średnia arytmetyczna) wynosiła 0, a odchylenie standardowe wynosiło 1. W tym celu od każdego punktu danych odejmuje się średnią cechy i dzieli wynik przez odchylenie standardowe.
- Skalowanie min-max: Skalowanie min-max przekształca dane do określonego zakresu, zazwyczaj od 0 do 1. Jest to osiągane poprzez odjęcie minimalnej wartości cechy od każdego punktu danych, a następnie podzielenie przez zakres wartości cechy.
#9. Normalizacja
Dzięki normalizacji, cechy numeryczne są skalowane do wspólnego zakresu, zazwyczaj od 0 do 1. Zachowuje to względne różnice między wartościami i zapewnia, że wszystkie cechy mają równe szanse.

#1. Featuretools
Featuretools to otwartoźródłowy framework Pythona, który automatycznie tworzy cechy na podstawie tymczasowych i relacyjnych zbiorów danych. Można go używać z narzędziami, których już używasz w tworzeniu potoków uczenia maszynowego.
Rozwiązanie to wykorzystuje głęboką syntezę cech, aby automatyzować proces inżynierii cech. Posiada bibliotekę funkcji niskiego poziomu do tworzenia cech. Featuretools oferuje także API, które idealnie nadaje się do precyzyjnego zarządzania czasem.
#2. CatBoost
Jeżeli szukasz biblioteki open source, która łączy wiele drzew decyzyjnych, aby stworzyć potężny model predykcyjny, wybierz CatBoost. To narzędzie zapewnia dokładne wyniki przy domyślnych parametrach, dzięki czemu nie musisz poświęcać wielu godzin na ich dostrajanie.
CatBoost umożliwia także wykorzystanie czynników nieliczbowych w celu poprawy wyników treningu. Dzięki temu można oczekiwać dokładniejszych wyników i szybszych predykcji.
#3. Feature-engine
Feature-engine to biblioteka Pythona, która oferuje szeroki wybór transformatorów i selektorów cech, które można wykorzystać w modelach ML. Zawarte transformatory mogą być wykorzystane do transformacji zmiennych, tworzenia nowych zmiennych, obsługi funkcji daty i godziny, wstępnego przetwarzania danych, kodowania kategorycznego, ograniczania lub usuwania wartości odstających oraz przypisywania brakujących danych. Jest w stanie automatycznie rozpoznawać zmienne numeryczne, jakościowe i czasowe.
Zasoby edukacyjne dotyczące inżynierii cech
Kursy online i zajęcia wirtualne

#1. Inżynieria cech dla uczenia maszynowego w Pythonie: Datacamp
Ten kurs Datacamp z zakresu inżynierii cech w uczeniu maszynowym w Pythonie nauczy Cię tworzenia nowych cech, które poprawiają wydajność modeli uczenia maszynowego. Dowiesz się, jak przeprowadzać inżynierię cech i przetwarzać dane, aby tworzyć zaawansowane aplikacje ML.
#2. Inżynieria cech dla uczenia maszynowego: Udemy
Z kursu Udemy z inżynierii cech dla uczenia maszynowego, dowiesz się o takich zagadnieniach, jak imputacja, kodowanie zmiennych, ekstrakcja cech, dyskretyzacja, obsługa daty i godziny, wartości odstające, itp. Uczestnicy nauczą się także pracować ze zmiennymi o skośnym rozkładzie oraz radzić sobie z rzadkimi i niewidocznymi kategoriami.
#3. Inżynieria cech: Pluralsight
Ta ścieżka edukacyjna Pluralsight składa się z sześciu kursów. Pomogą Ci one zrozumieć znaczenie inżynierii cech w procesie ML, sposoby wykorzystania jej technik oraz wydobywanie cech z tekstu i obrazów.
#4. Wybór cech w uczeniu maszynowym: Udemy
Z pomocą tego kursu Udemy uczestnicy mogą nauczyć się metod mieszania cech, filtrowania, opakowywania oraz metod osadzonych, rekursywnej eliminacji cech i wyszukiwania wyczerpującego. Omówione zostaną także techniki selekcji cech, w tym te z wykorzystaniem Pythona, Lasso i drzew decyzyjnych. Kurs zawiera 5,5 godziny filmów na żądanie i 22 artykuły.
#5. Inżynieria cech w uczeniu maszynowym: Great Learning
Ten kurs Great Learning wprowadzi Cię w zagadnienia inżynierii cech, nauczając o nadpróbkowaniu i podpróbkowaniu. Dodatkowo, będziesz miał możliwość wykonania praktycznych ćwiczeń związanych z dostrajaniem modelu.
#6. Inżynieria cech: Coursera
Dołącz do kursu Coursera, aby nauczyć się wykorzystywać BigQuery ML, Keras i TensorFlow do wykonywania inżynierii cech. Kurs, przeznaczony dla osób o średnim poziomie zaawansowania, obejmuje również zaawansowane praktyki inżynierii cech.
Książki w wersji cyfrowej lub papierowej

#1. Inżynieria cech dla uczenia maszynowego
Z tej książki dowiesz się, jak przekształcać cechy do formatów zrozumiałych dla modeli uczenia maszynowego.
Uczy ona także zasad inżynierii cech oraz ich praktycznego zastosowania poprzez ćwiczenia.
#2. Inżynieria cech i selekcja
Czytając tę książkę, poznasz metody tworzenia modeli predykcyjnych na różnych etapach.
Dowiesz się z niej, jak znaleźć najlepsze reprezentacje predyktorów do modelowania.
#3. Inżynieria cech stała się prosta
Książka stanowi przewodnik po zwiększaniu mocy przewidywania algorytmów uczenia maszynowego.
Uczy, jak projektować i tworzyć efektywne cechy dla aplikacji opartych na uczeniu maszynowym, oferując dogłębny wgląd w dane.
#4. Obóz książkowy poświęcony inżynierii cech
W tej książce znajdziesz praktyczne studia przypadków, które pomogą Ci nauczyć się technik inżynierii cech, które zapewnią lepsze wyniki uczenia maszynowego i ulepszone przetwarzanie danych.
Po przeczytaniu tej książki będziesz w stanie osiągnąć lepsze wyniki bez poświęcania dużej ilości czasu na dostrajanie parametrów ML.
#5. Sztuka inżynierii cech
Ta pozycja jest niezbędnym źródłem wiedzy dla każdego analityka danych i inżyniera uczenia maszynowego.
W książce zastosowano podejście interdyscyplinarne do omówienia wykresów, tekstu, szeregów czasowych, obrazów i studiów przypadków.
Podsumowanie
Tak wygląda proces inżynierii cech. Teraz, gdy znasz definicję, proces krok po kroku, metody i zasoby edukacyjne, możesz śmiało wdrażać te umiejętności w swoich projektach ML i osiągnąć sukces!
Zachęcamy również do zapoznania się z artykułem na temat uczenia ze wzmocnieniem.
