

Czy jesteś gotowy, aby nauczyć się inżynierii funkcji na potrzeby uczenia maszynowego i analityki danych? Jesteś we właściwym miejscu!
Inżynieria funkcji to kluczowa umiejętność wydobywania cennych spostrzeżeń z danych. W tym krótkim przewodniku podzielę ją na proste, zrozumiałe fragmenty. Przejdźmy więc od razu do rzeczy i rozpocznijmy swoją podróż do opanowania ekstrakcji funkcji!
Spis treści:
Co to jest inżynieria cech?

Tworząc model uczenia maszynowego powiązany z problemem biznesowym lub eksperymentalnym, dostarczasz dane uczące w kolumnach i wierszach. W dziedzinie nauki o danych i rozwoju uczenia maszynowego kolumny są znane jako atrybuty lub zmienne.
Dane szczegółowe lub wiersze poniżej tych kolumn nazywane są obserwacjami lub instancjami. Kolumny lub atrybuty są elementami surowego zbioru danych.
Te surowe funkcje nie są wystarczające ani optymalne do trenowania modelu uczenia maszynowego. Aby zredukować szum zebranych metadanych i zmaksymalizować unikalne sygnały z funkcji, należy przekształcić lub przekonwertować kolumny metadanych na funkcje funkcjonalne poprzez inżynierię funkcji.
Przykład 1: Modelowanie finansowe
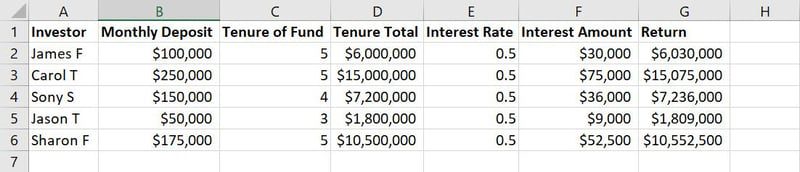 Surowe dane do szkolenia modelu ML
Surowe dane do szkolenia modelu ML
Na przykład na powyższym obrazie przykładowego zbioru danych kolumny od A do G to cechy. Wartości lub ciągi tekstowe w każdej kolumnie wzdłuż wierszy, takie jak nazwiska, kwota depozytu, lata depozytu, stopy procentowe itp., są obserwacjami.
W modelowaniu ML należy usuwać, dodawać, łączyć lub przekształcać dane, aby utworzyć znaczące funkcje i zmniejszyć rozmiar ogólnej bazy danych szkoleniowej modelu. To jest inżynieria funkcji.
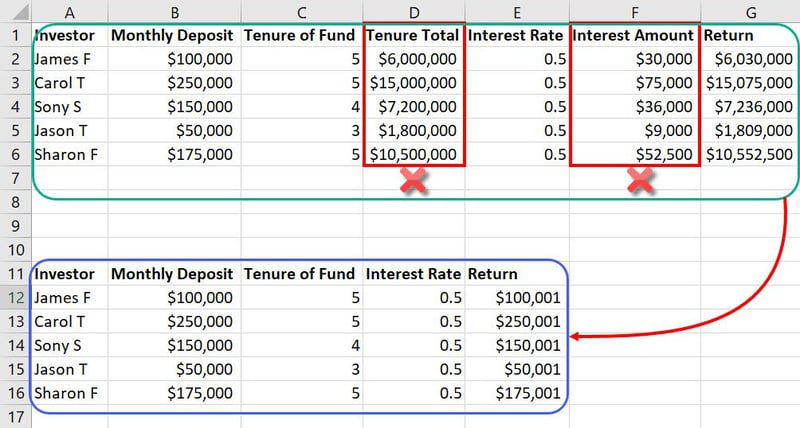 Przykład inżynierii cech
Przykład inżynierii cech
W tym samym zbiorze danych, o którym mowa wcześniej, funkcje takie jak całkowity staż i kwota odsetek są niepotrzebnymi danymi wejściowymi. Zajmą one po prostu więcej miejsca i zmylą model ML. Można zatem zredukować dwie funkcje z siedmiu funkcji.
Ponieważ bazy danych w modelach ML zawierają tysiące kolumn i miliony wierszy, ograniczenie dwóch funkcji ma duży wpływ na projekt.
Przykład 2: Tworzenie list odtwarzania muzyki AI
Czasami można utworzyć zupełnie nową funkcję z wielu istniejących funkcji. Załóżmy, że tworzysz model sztucznej inteligencji, który automatycznie utworzy listę odtwarzania muzyki i utworów według wydarzenia, gustu, trybu itp.
Zebrałeś teraz dane o piosenkach i muzyce z różnych źródeł i stworzyłeś następującą bazę danych:
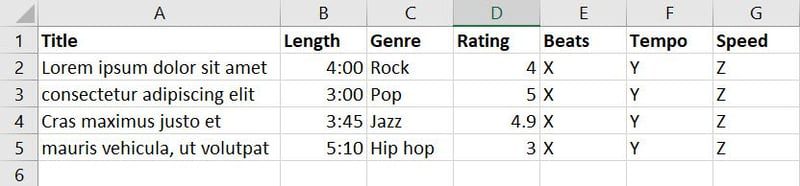
W powyższej bazie danych znajduje się siedem obiektów. Ponieważ jednak Twoim celem jest wytrenowanie modelu ML w celu decydowania, który utwór lub muzyka jest odpowiednia dla danego wydarzenia, możesz połączyć funkcje, takie jak gatunek, ocena, rytm, tempo i prędkość, w nową funkcję o nazwie Możliwość zastosowania.
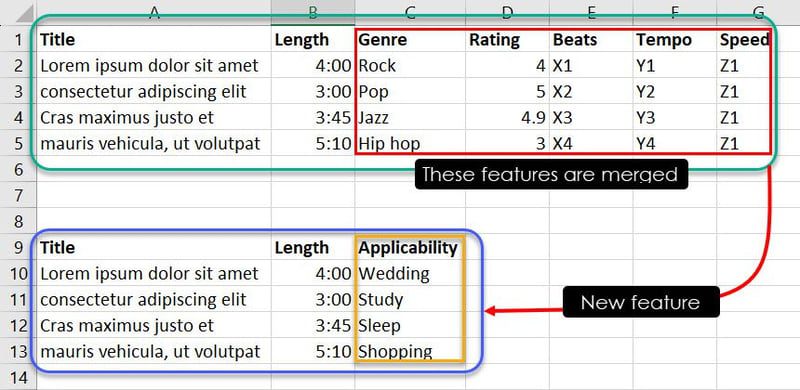
Teraz, dzięki specjalistycznej wiedzy lub identyfikacji wzorców, możesz połączyć pewne wystąpienia funkcji, aby określić, który utwór jest odpowiedni na dane wydarzenie. Na przykład obserwacje takie jak Jazz, 4.9, X3, Y3 i Z1 mówią modelowi ML, że piosenka Cras maximus justo et powinna znajdować się na liście odtwarzania użytkownika, jeśli szuka on utworu na sen.
Rodzaje funkcji w uczeniu maszynowym
Cechy kategoryczne
Są to atrybuty danych reprezentujące odrębne kategorie lub etykiety. Tego typu należy używać do oznaczania jakościowych zbiorów danych.
#1. Porządkowe cechy kategoryczne
Funkcje porządkowe mają kategorie o znaczącej kolejności. Na przykład poziomy wykształcenia, takie jak szkoła średnia, licencjat, magister itp., charakteryzują się wyraźnym rozróżnieniem w standardach, ale nie ma różnic ilościowych.
#2. Nominalne cechy kategoryczne
Cechy nominalne to kategorie bez żadnego wewnętrznego porządku. Przykładami mogą być kolory, kraje lub rodzaje zwierząt. Poza tym istnieją tylko różnice jakościowe.
Funkcje tablicowe
Ten typ funkcji reprezentuje dane zorganizowane w tablice lub listy. Analitycy danych i programiści ML często używają funkcji Array do obsługi sekwencji lub osadzania danych kategorycznych.
#1. Osadzanie funkcji tablicy
Osadzanie tablic konwertuje dane kategoryczne na gęste wektory. Jest powszechnie stosowany w systemach przetwarzania i rekomendacji języka naturalnego.
#2. Lista funkcji tablicy
Tablice list przechowują sekwencje danych, takie jak listy elementów w kolejności lub historię działań.
Funkcje numeryczne
Te funkcje szkoleniowe ML są używane do wykonywania operacji matematycznych, ponieważ te funkcje reprezentują dane ilościowe.
#1. Przedziałowe funkcje liczbowe
Funkcje interwałowe mają stałe odstępy między wartościami, ale nie mają prawdziwego punktu zerowego — na przykład dane z monitorowania temperatury. Tutaj zero oznacza temperaturę zamarzania, ale atrybut nadal tam jest.
#2. Stosunkowe cechy numeryczne
Funkcje proporcji mają stałe odstępy między wartościami a prawdziwym punktem zerowym. Przykładami mogą być wiek, wzrost i dochód.
Znaczenie inżynierii cech w ML i nauce danych
Następnie przeanalizujemy krok po kroku proces inżynierii cech.
Proces inżynierii funkcji krok po kroku

Następnie omówimy metody inżynierii cech.
Metody inżynierii cech
#1. Analiza głównych składowych (PCA)
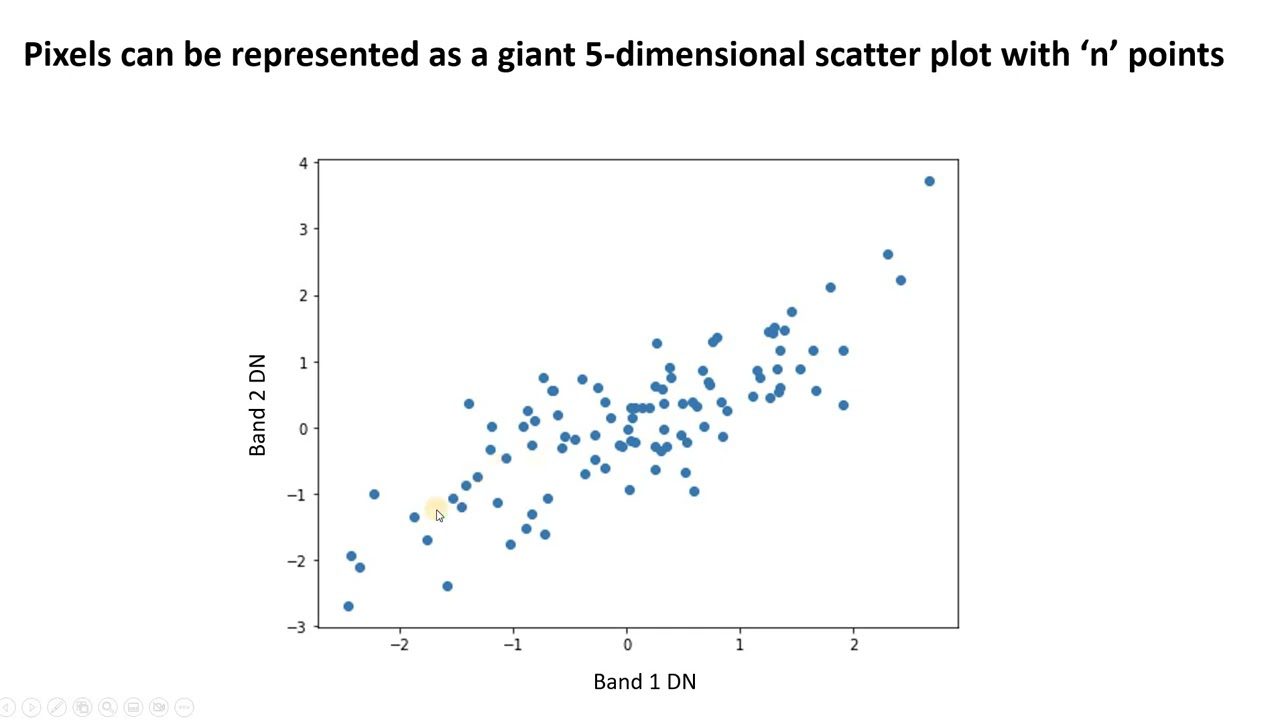
PCA upraszcza złożone dane, znajdując nowe, nieskorelowane funkcje. Nazywa się je głównymi składnikami. Można go użyć do zmniejszenia wymiarowości i poprawy wydajności modelu.
#2. Cechy wielomianowe
Tworzenie funkcji wielomianowych oznacza dodawanie mocy istniejących funkcji w celu uchwycenia złożonych relacji w danych. Pomaga Twojemu modelowi zrozumieć wzorce nieliniowe.
#3. Obsługa wartości odstających
Wartości odstające to nietypowe punkty danych, które mogą mieć wpływ na wydajność modeli. Aby zapobiec wypaczonym wynikom, należy identyfikować wartości odstające i zarządzać nimi.
#4. Przekształcenie dziennika
Transformacja logarytmiczna może pomóc w normalizacji danych o rozkładzie skośnym. Zmniejsza wpływ wartości ekstremalnych, dzięki czemu dane są bardziej przydatne do modelowania.
#5. t-rozproszone stochastyczne osadzanie sąsiada (t-SNE)
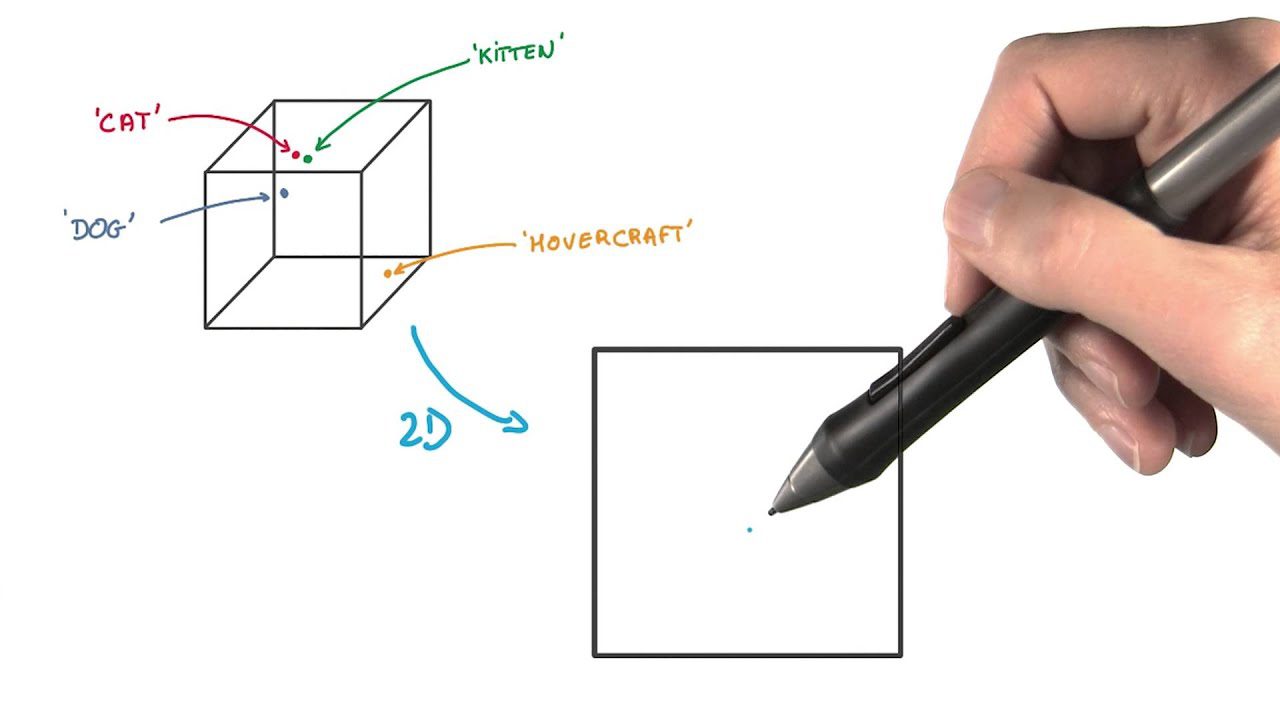
t-SNE jest przydatny do wizualizacji danych wielowymiarowych. Zmniejsza wymiarowość i sprawia, że klastry są bardziej widoczne, zachowując jednocześnie strukturę danych.
W tej metodzie ekstrakcji cech punkty danych są przedstawiane jako kropki w przestrzeni o niższych wymiarach. Następnie umieszcza się podobne punkty danych w oryginalnej przestrzeni wielowymiarowej i modeluje się je tak, aby znajdowały się blisko siebie w reprezentacji niskowymiarowej.
Różni się od innych metod redukcji wymiarowości zachowaniem struktury i odległości między punktami danych.
#6. Jedno-gorące kodowanie
Kodowanie One-Hot przekształca zmienne kategoryczne w format binarny (0 lub 1). Otrzymujesz więc nowe kolumny binarne dla każdej kategorii. Kodowanie typu „one-hot” sprawia, że dane kategoryczne są odpowiednie dla algorytmów ML.
#7. Kodowanie zliczeniowe
Kodowanie Count zastępuje wartości kategoryczne liczbą ich występowania w zbiorze danych. Może przechwytywać cenne informacje ze zmiennych kategorycznych.
W tej metodzie inżynierii cech częstotliwość lub liczba każdej kategorii jest używana jako nowa cecha liczbowa, zamiast używać oryginalnych etykiet kategorii.
#8. Standaryzacja funkcji

Cechy większych wartości często dominują nad cechami małych wartości. Zatem model ML może łatwo zostać obciążony. Standaryzacja zapobiega takim przyczynom błędów w modelu uczenia maszynowego.
Proces normalizacji zazwyczaj obejmuje następujące dwie popularne techniki:
- Standaryzacja Z-Score: Ta metoda przekształca każdą cechę tak, aby jej średnia (średnia) wynosiła 0, a odchylenie standardowe wynosiło 1. W tym przypadku odejmuje się średnią cechy od każdego punktu danych i dzieli wynik przez odchylenie standardowe.
- Skalowanie min.-maks.: Skalowanie min.-maks. przekształca dane w określony zakres, zazwyczaj od 0 do 1. Można to osiągnąć, odejmując minimalną wartość cechy od każdego punktu danych i dzieląc przez zakres.
#9. Normalizacja
Poprzez normalizację cechy numeryczne są skalowane do wspólnego zakresu, zwykle od 0 do 1. Zachowuje to względne różnice między wartościami i zapewnia, że wszystkie cechy mają równe szanse.

#1. Narzędzia funkcji
Narzędzia funkcji to framework Pythona typu open source, który automatycznie tworzy funkcje na podstawie tymczasowych i relacyjnych zbiorów danych. Można go używać z narzędziami, których już używasz do opracowywania potoków uczenia maszynowego.
Rozwiązanie wykorzystuje głęboką syntezę cech do automatyzacji inżynierii cech. Posiada bibliotekę funkcji niskiego poziomu do tworzenia funkcji. Featuretools posiada również API, które jest również idealne do precyzyjnego zarządzania czasem.
#2. CatBoost
Jeśli szukasz biblioteki typu open source, która łączy wiele drzew decyzyjnych w celu stworzenia potężnego modelu predykcyjnego, sięgnij po nią CatBoost. To rozwiązanie zapewnia dokładne wyniki przy domyślnych parametrach, dzięki czemu nie musisz spędzać godzin na dostrajaniu parametrów.
CatBoost umożliwia także wykorzystanie czynników nieliczbowych w celu poprawy wyników treningu. Dzięki niemu możesz także spodziewać się dokładniejszych wyników i szybszych przewidywań.
#3. Silnik funkcji
Silnik funkcji to biblioteka języka Python z wieloma transformatorami i wybranymi funkcjami, których można używać w modelach ML. Transformatory, które zawiera, mogą być używane do transformacji zmiennych, tworzenia zmiennych, funkcji daty i godziny, przetwarzania wstępnego, kodowania kategorycznego, ograniczania lub usuwania wartości odstających oraz przypisywania brakujących danych. Jest w stanie automatycznie rozpoznawać zmienne numeryczne, jakościowe i datetime.
Zasoby edukacyjne dotyczące inżynierii funkcji
Kursy online i zajęcia wirtualne

#1. Inżynieria funkcji dla uczenia maszynowego w Pythonie: Datacamp
Ten obóz danych kurs Inżynierii Cech w Uczeniu Maszynowym w Pythonie umożliwia tworzenie nowych funkcji, które poprawiają wydajność modelu uczenia maszynowego. Nauczy Cię inżynierii funkcji i przetwarzania danych w celu tworzenia zaawansowanych aplikacji ML.
#2. Inżynieria funkcji dla uczenia maszynowego: Udemy
Z Kurs Inżynieria funkcji dla uczenia maszynowegopoznasz takie tematy, jak imputacja, kodowanie zmiennych, ekstrakcja cech, dyskretyzacja, funkcjonalność daty i godziny, wartości odstające itp. Uczestnicy nauczą się także pracować ze zmiennymi wypaczonymi i radzić sobie z rzadkimi, niewidocznymi i rzadkimi kategoriami.
#3. Inżynieria funkcji: Pluralsight
Ten Wielowzroczność ścieżka edukacyjna obejmuje łącznie sześć kursów. Kursy te pomogą Ci poznać znaczenie inżynierii funkcji w przepływie pracy ML, sposobów stosowania jej technik oraz ekstrakcji funkcji z tekstu i obrazów.
#4. Wybór funkcji uczenia maszynowego: Udemy
Z pomocą tego Udemy Podczas kursu uczestnicy mogą nauczyć się tasowania funkcji, filtrowania, opakowywania i metod osadzonych, rekursywnej eliminacji funkcji i wyszukiwania wyczerpującego. Omówiono także techniki selekcji cech, w tym te z wykorzystaniem Pythona, Lasso i drzew decyzyjnych. Kurs zawiera 5,5 godziny filmów na żądanie i 22 artykuły.
#5. Inżynieria funkcji w uczeniu maszynowym: świetna nauka
Ten kurs od Wielka nauka wprowadzi Cię w inżynierię funkcji, ucząc Cię o nadmiernym i niedostatecznym próbkowaniu. Ponadto umożliwi Ci wykonanie praktycznych ćwiczeń związanych ze strojeniem modelu.
#6. Inżynieria funkcji: Coursera
Dołącz Kursra kurs korzystania z BigQuery ML, Keras i TensorFlow do wykonywania inżynierii funkcji. Ten kurs na poziomie średniozaawansowanym obejmuje również zaawansowane praktyki inżynierii funkcji.
Książki w wersji cyfrowej lub w twardej oprawie

#1. Inżynieria funkcji dla uczenia maszynowego
Z tej książki dowiesz się, jak przekształcać funkcje w formaty na potrzeby modeli uczenia maszynowego.
Uczy także zasad inżynierii funkcji i praktycznego zastosowania poprzez ćwiczenia.
#2. Inżynieria cech i selekcja
Czytając tę książkę, poznasz metody opracowywania modeli predykcyjnych na różnych etapach.
Można się z niego nauczyć technik znajdowania najlepszych reprezentacji predyktorów do modelowania.
#3. Inżynieria funkcji stała się prosta
Książka jest przewodnikiem po zwiększaniu mocy przewidywania algorytmów uczenia maszynowego.
Uczy projektowania i tworzenia wydajnych funkcji dla aplikacji opartych na uczeniu maszynowym, oferując dogłębny wgląd w dane.
#4. Obóz książkowy dotyczący inżynierii funkcji
W tej książce zawarto praktyczne studia przypadków, dzięki którym nauczysz się technik inżynierii funkcji zapewniających lepsze wyniki uczenia maszynowego i ulepszone przetwarzanie danych.
Przeczytanie tego sprawi, że będziesz w stanie uzyskać lepsze wyniki bez poświęcania dużej ilości czasu na dostrajanie parametrów ML.
#5. Sztuka inżynierii cech
Zasób jest niezbędnym elementem dla każdego analityka danych i inżyniera uczenia maszynowego.
W książce zastosowano podejście międzydziedzinowe do omówienia wykresów, tekstów, szeregów czasowych, obrazów i studiów przypadków.
Wniosek
W ten sposób można przeprowadzić inżynierię cech. Teraz, gdy znasz już definicję, etapowy proces, metody i zasoby edukacyjne, możesz wdrożyć je w swoich projektach ML i zobaczyć sukces!
Następnie zapoznaj się z artykułem na temat uczenia się przez wzmacnianie.