Podłącz i wykonaj modele uczenia maszynowego dla anomalii wizualnych w architekturze AWS Serverless
Wyobraźmy sobie rozległą infrastrukturę, obejmującą różnorodne urządzenia, które wymagają systematycznej konserwacji i nadzoru, aby zapewnić ich bezpieczne funkcjonowanie oraz minimalizować negatywny wpływ na środowisko.
Jedną z metod utrzymania tej infrastruktury w odpowiednim stanie jest regularne wysyłanie personelu w teren w celu przeprowadzenia kontroli. Choć takie podejście jest w pewnym stopniu skuteczne, okazuje się być czasochłonne i kosztowne. W przypadku rozległej infrastruktury, jej pełne objęcie kontrolą w ciągu jednego roku może być wręcz niemożliwe.
Alternatywnym rozwiązaniem jest automatyzacja procesu weryfikacji, przenosząc go do chmury. Aby to osiągnąć, konieczne jest wykonanie kilku kluczowych kroków:
👉 **Szybkie pozyskiwanie zdjęć urządzeń:** Można wykorzystać personel do robienia zdjęć, ponieważ nadal jest to szybsze od manualnej weryfikacji każdego urządzenia. Można również zastosować zdjęcia z samochodów lub dronów, co znacznie przyspiesza i automatyzuje proces zbierania danych wizualnych.
👉 **Przesyłanie zdjęć do dedykowanej chmury:** Wszystkie zebrane fotografie powinny zostać zgromadzone w jednym, wyznaczonym miejscu w chmurze.
👉 **Automatyczne przetwarzanie w chmurze:** W chmurze uruchamiane jest zautomatyzowane zadanie, które pobiera zdjęcia i przetwarza je za pomocą modeli uczenia maszynowego. Modele te są specjalnie przeszkolone do rozpoznawania uszkodzeń lub nietypowych cech urządzeń.
👉 **Dostępność wyników dla użytkowników:** Rezultaty analizy muszą być udostępnione odpowiednim użytkownikom, aby umożliwić zaplanowanie naprawy urządzeń, które wykazują problemy.
Przyjrzyjmy się bliżej, jak można zrealizować wykrywanie anomalii na podstawie analizy obrazów w chmurze AWS. Amazon oferuje szereg gotowych modeli uczenia maszynowego, które można wykorzystać w tym celu.
Jak utworzyć model do identyfikacji anomalii wizualnych
Aby stworzyć model zdolny do wykrywania anomalii wizualnych, należy przejść przez następujące etapy:
Krok 1: **Precyzyjne zdefiniowanie problemu** oraz rodzaju anomalii, które mają być wykrywane. Ten krok pomaga w doborze odpowiedniego zbioru danych testowych, który będzie niezbędny do nauki modelu.
Krok 2: **Zgromadzenie obszernego zestawu danych** zawierającego obrazy przedstawiające zarówno normalne, jak i anomalne stany. Kluczowe jest oznaczenie każdego obrazu, wskazując, czy prezentuje on stan normalny, czy też anomalię.
Krok 3: **Wybór odpowiedniej architektury modelu**. Można zdecydować się na wykorzystanie wstępnie wytrenowanego modelu i dostosowanie go do konkretnego przypadku, lub stworzyć model od podstaw.
Krok 4: **Wytrenowanie modelu** przy użyciu przygotowanego zbioru danych i wybranego algorytmu. Często wykorzystuje się transfer uczenia, adaptując wstępnie wyszkolone modele, lub tworzy model od zera, stosując techniki takie jak konwolucyjne sieci neuronowe (CNN).
Jak przeprowadzić trening modelu uczenia maszynowego
Źródło: aws.amazon.com
Proces trenowania modeli uczenia maszynowego AWS, przeznaczonych do identyfikacji anomalii wizualnych, składa się z kilku istotnych kroków.
#1. Zbieranie danych
Na początku konieczne jest zgromadzenie i odpowiednie opisanie obszernego zbioru danych obrazów, przedstawiających zarówno standardowe warunki, jak i różnorodne anomalie. Większy i bardziej zróżnicowany zbiór danych umożliwia wytrenowanie dokładniejszego i skuteczniejszego modelu. Należy jednak pamiętać, że większa ilość danych wymaga również więcej czasu potrzebnego na trenowanie.
Zazwyczaj, aby rozpocząć proces trenowania z dobrym fundamentem, zaleca się posiadanie około 1000 zdjęć w zestawie testowym.
#2. Przygotowanie danych
Dane obrazowe muszą zostać odpowiednio przetworzone, aby model uczenia maszynowego mógł je efektywnie wykorzystać. Wstępne przetwarzanie obejmuje szereg działań, takich jak:
- Organizowanie obrazów wejściowych w uporządkowane foldery, porządkowanie metadanych.
- Zmiana rozmiaru zdjęć do formatu zgodnego z wymogami modelu.
- Podział obrazów na mniejsze fragmenty, co umożliwia efektywniejsze przetwarzanie równoległe.
#3. Wybór modelu
Następnym krokiem jest wybór odpowiedniego modelu, który najlepiej sprawdzi się w realizacji danego zadania. Można wykorzystać model wstępnie wytrenowany lub opracować model niestandardowy, precyzyjnie dopasowany do potrzeb wykrywania anomalii wizualnych.
#4. Ocena wyników
Po przetworzeniu zbioru danych przez model, należy dokładnie zweryfikować jego skuteczność. Należy również upewnić się, czy wyniki spełniają oczekiwania i potrzeby. Może to obejmować na przykład zapewnienie, że model poprawnie identyfikuje anomalie na ponad 99% danych wejściowych.
#5. Wdrożenie modelu
Po uzyskaniu satysfakcjonujących rezultatów i potwierdzeniu odpowiedniej wydajności, należy wdrożyć model w środowisku konta AWS, z konkretną wersją, aby procesy i usługi mogły z niego korzystać.
#6. Monitorowanie i udoskonalanie
Konieczne jest ciągłe monitorowanie działania modelu w różnych zadaniach testowych i na różnych zbiorach danych, aby upewnić się, że parametry odpowiedzialne za prawidłowe wykrywanie są nadal na odpowiednim poziomie.
W przypadku wykrycia nieprawidłowych wyników, należy przeprowadzić ponowne trenowanie modelu, uwzględniając nowe zbiory danych.
Modele uczenia maszynowego AWS
Przyjrzyjmy się teraz kilku konkretnym modelom, które można wykorzystać w chmurze Amazon.
AWS Rekognition
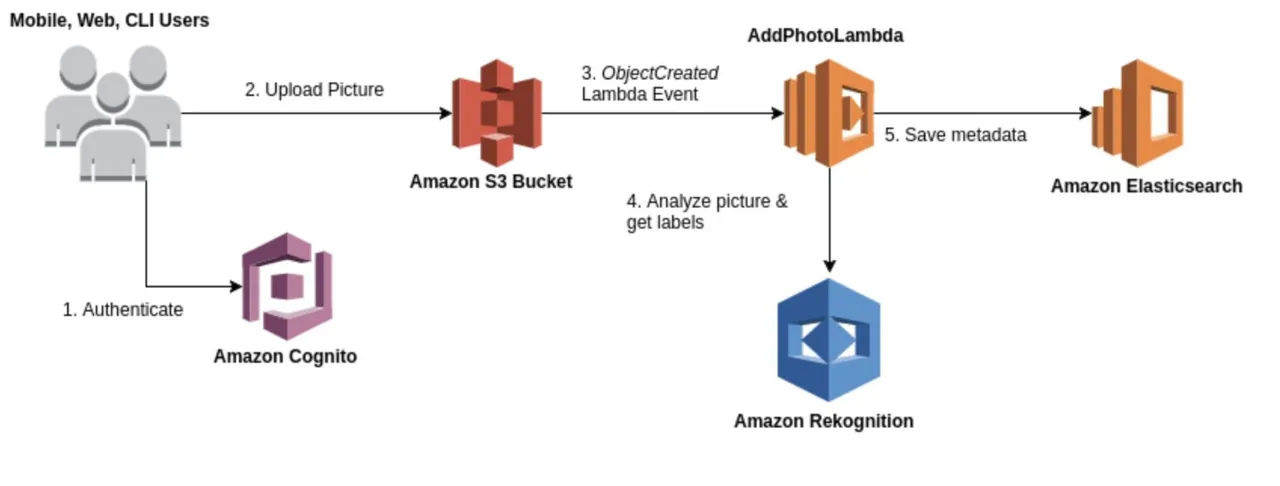 Źródło: aws.amazon.com
Źródło: aws.amazon.com
Rekognition to wszechstronne usługi analizy obrazów i wideo, które można wykorzystać w różnorodnych sytuacjach, takich jak rozpoznawanie twarzy, wykrywanie obiektów oraz rozpoznawanie tekstu. Model rozpoznawania często wykorzystywany jest do wstępnej analizy i generowania pierwotnych danych, które następnie są wykorzystywane do tworzenia jeziora danych z wykrytymi anomaliami.
Usługa udostępnia szereg gotowych modeli, które mogą być wykorzystane bez konieczności dodatkowego trenowania. Rekognition zapewnia również analizę obrazów i filmów w czasie rzeczywistym z dużą precyzją i niskim opóźnieniem.
Oto kilka typowych scenariuszy, w których Rekognition jest dobrym wyborem do wykrywania anomalii:
- Ogólne przypadki użycia, obejmujące wykrywanie anomalii na obrazach i filmach.
- Potrzeba przeprowadzania wykrywania anomalii w czasie rzeczywistym.
- Integracja modelu wykrywania anomalii z innymi usługami AWS, takimi jak Amazon S3, Amazon Kinesis lub AWS Lambda.
Oto przykłady konkretnych anomalii, które można wykryć za pomocą Rekognition:
- Nietypowe cechy twarzy, takie jak wyraz twarzy lub emocje odbiegające od normy.
- Brakujące lub nieprawidłowo umieszczone obiekty w scenie.
- Błędnie napisane słowa lub nietypowy układ tekstu.
- Nietypowe warunki oświetleniowe lub nieoczekiwane obiekty w kadrze.
- Nieodpowiednie lub obraźliwe treści na obrazach lub filmach.
- Nagłe zmiany w ruchu lub nietypowe wzorce poruszania się.
AWS Lookout dla wizji
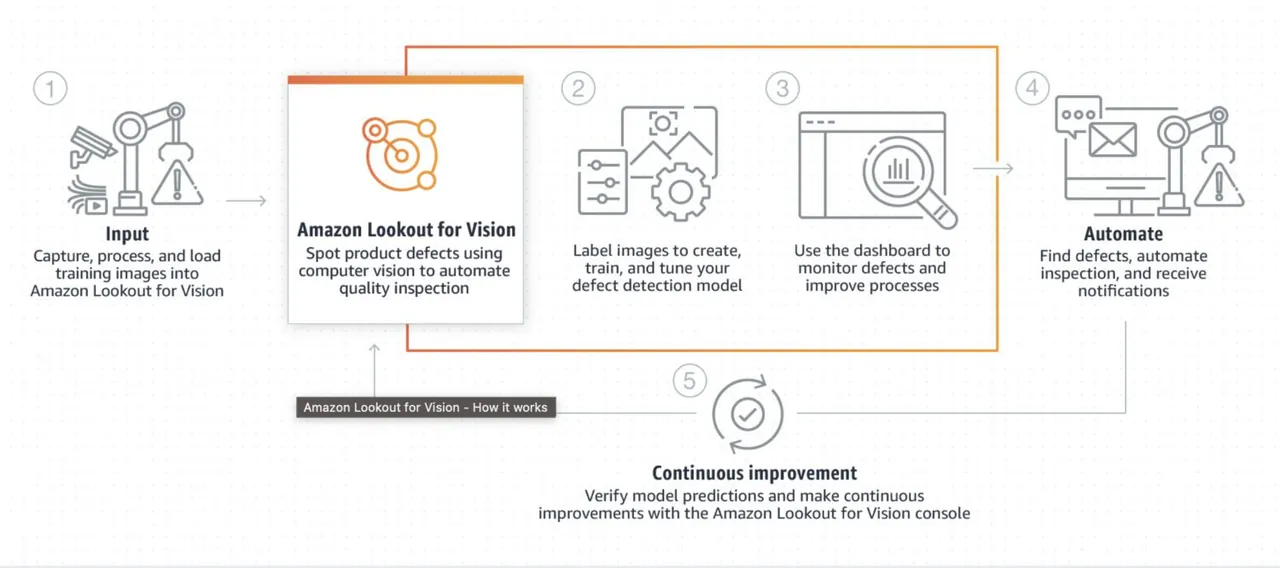 Źródło: aws.amazon.com
Źródło: aws.amazon.com
Lookout for Vision to model opracowany specjalnie do wykrywania anomalii w środowiskach przemysłowych, takich jak linie produkcyjne. Zazwyczaj wymaga on wstępnego i końcowego przetworzenia obrazu za pomocą kodu niestandardowego, najczęściej napisanego w języku Python. Model ten specjalizuje się w rozwiązywaniu specyficznych problemów związanych z analizą obrazów.
Wymaga on własnego trenowania na zestawie danych zawierającym zarówno normalne, jak i nietypowe obrazy, aby utworzyć model dostosowany do danego rodzaju anomalii. Nie jest on zorientowany na przetwarzanie w czasie rzeczywistym, lecz raczej na wsadowe przetwarzanie obrazów z naciskiem na dokładność i precyzję.
Oto sytuacje, w których Lookout for Vision jest odpowiednim wyborem:
- Wykrywanie defektów w wyprodukowanych produktach lub identyfikacja awarii urządzeń na linii produkcyjnej.
- Praca z dużym zbiorem danych obrazów.
- Identyfikacja anomalii w czasie rzeczywistym w procesie przemysłowym.
- Integracja wykrywania anomalii z innymi usługami AWS, takimi jak Amazon S3 czy AWS IoT.
Przykłady anomalii wykrywanych przez Lookout for Vision:
- Wady produkcyjne, takie jak rysy, wgniecenia lub inne niedoskonałości, które obniżają jakość produktu.
- Awarie maszyn na linii produkcyjnej, takie jak uszkodzone lub nieprawidłowo działające urządzenia, powodujące opóźnienia lub zagrożenia.
- Problemy z kontrolą jakości na linii produkcyjnej, wykrywanie produktów niespełniających norm.
- Zagrożenia bezpieczeństwa na linii produkcyjnej, np. niebezpieczne przedmioty lub materiały.
- Anomalie w procesie produkcyjnym, np. nieoczekiwane zmiany w przepływie materiałów lub produktów.
AWS Sagemaker
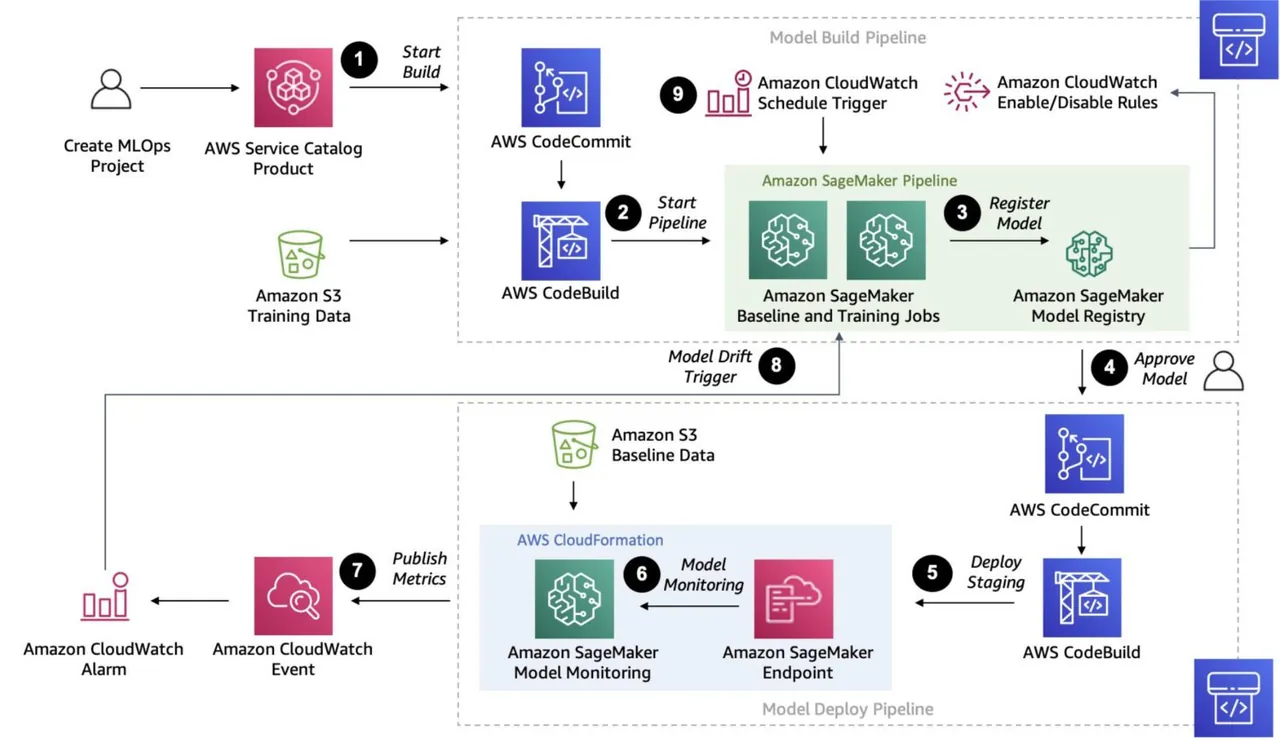 Źródło: aws.amazon.com
Źródło: aws.amazon.com
Sagemaker to kompleksowa platforma, umożliwiająca tworzenie, trenowanie i wdrażanie niestandardowych modeli uczenia maszynowego.
Jest to bardziej zaawansowane i elastyczne rozwiązanie. Umożliwia łączenie i wykonywanie złożonych, wieloetapowych procesów w ramach jednego zadania, podobnie jak funkcje krokowe AWS.
Ponieważ Sagemaker korzysta z instancji EC2 do przetwarzania danych, nie ma ograniczenia do 15 minut na jedno zadanie, jak w przypadku funkcji lambda AWS w AWS Step Functions.
Sagemaker umożliwia również automatyczne dostrajanie modeli, co jest jego unikalną cechą. Dodatkowo, model może być łatwo wdrożony w środowisku produkcyjnym.
Oto przypadki użycia, w których SageMaker jest dobrym wyborem:
- Gdy gotowe modele lub interfejsy API nie spełniają potrzeb, a konieczne jest zbudowanie modelu dostosowanego do konkretnych wymagań.
- Praca z dużymi zbiorami danych. Gotowe modele często wymagają wstępnego przetwarzania, ale Sagemaker może to zautomatyzować.
- Potrzeba wykrywania anomalii w czasie rzeczywistym.
- Integracja modelu z innymi usługami AWS, np. Amazon S3, Amazon Kinesis lub AWS Lambda.
Przykłady wykrywanych anomalii:
- Wykrywanie oszustw finansowych, np. nietypowe transakcje lub wzorce wydatków.
- Zagrożenia w cyberbezpieczeństwie, np. nieoczekiwane połączenia z serwerami zewnętrznymi.
- Diagnostyka medyczna na podstawie obrazów, np. wykrywanie guzów.
- Nieprawidłowości w działaniu sprzętu, np. zmiany wibracji lub temperatury.
- Kontrola jakości w procesie produkcyjnym, wykrywanie wad produktów.
- Nietypowe wzorce zużycia energii.
Jak włączyć modele do architektury bezserwerowej
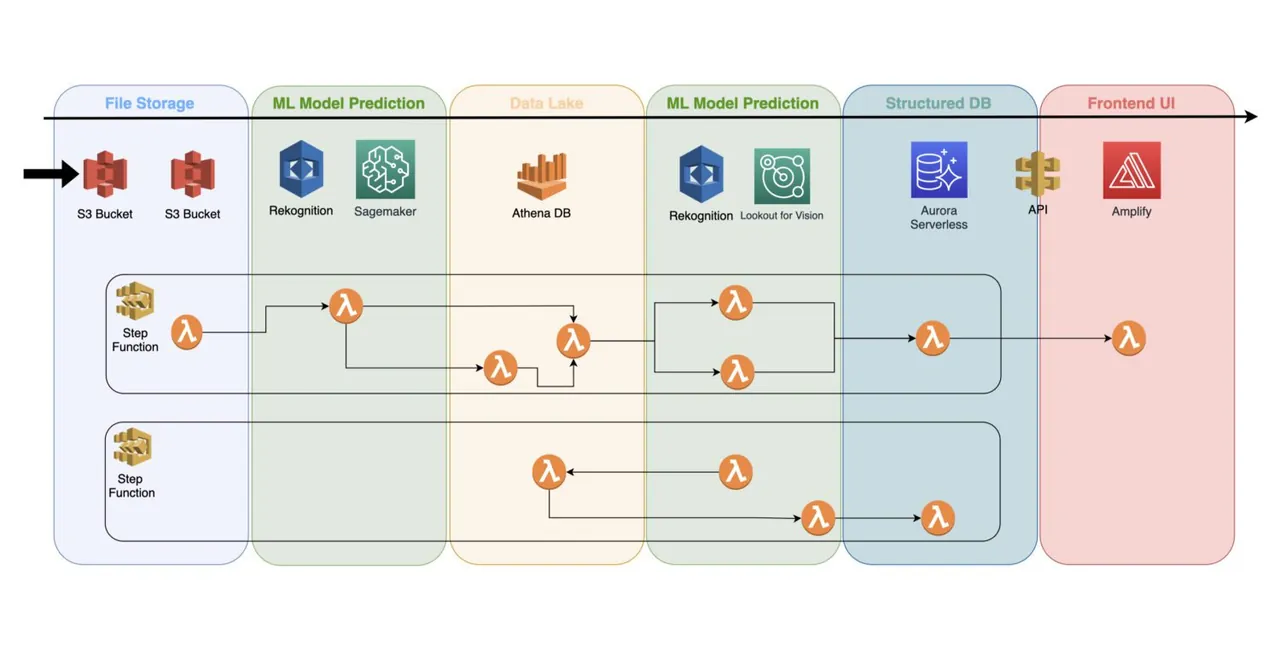
Wytrenowany model uczenia maszynowego to usługa działająca w chmurze, która nie korzysta z żadnych serwerów klastrowych. Dzięki temu łatwo można włączyć ją do istniejącej architektury bezserwerowej.
Automatyzacja procesów odbywa się za pomocą funkcji lambda AWS, połączonych w wieloetapowe zadanie za pomocą usługi AWS Step Functions.
Zazwyczaj, wstępne wykrywanie jest wymagane zaraz po zebraniu zdjęć i ich wstępnym przetworzeniu w zasobniku S3. Tam właśnie generowane jest pierwsze wykrycie anomalii na obrazach wejściowych, a wyniki są zapisywane w jeziorze danych, na przykład z wykorzystaniem bazy danych Athena.
W niektórych sytuacjach wstępne wykrycie może być niewystarczające. Wtedy może być konieczne przeprowadzenie bardziej szczegółowej analizy. Na przykład, początkowy model (np. Rekognition) może wykryć problem z urządzeniem, ale nie potrafi określić dokładnie, na czym on polega.
W takim przypadku można uruchomić inny model (np. Lookout for Vision) na podzbiorze obrazów, gdzie pierwszy model zidentyfikował problem.
To oszczędne rozwiązanie, ponieważ drugi model nie musi być uruchamiany na całym zestawie danych. Zamiast tego, przetwarza on tylko mniejszą, istotną grupę obrazów.
Funkcje AWS Lambda obsługują całe przetwarzanie, wykorzystując kod napisany w języku Python lub JavaScript. Konkretna implementacja zależy od charakteru procesów i liczby funkcji lambda, które będą potrzebne w przepływie. Ograniczenie czasu trwania wywołania lambda AWS (15 minut) determinuje liczbę kroków, jakie może zawierać taki proces.
Słowo na koniec
Praca z modelami uczenia maszynowego w chmurze to fascynujące wyzwanie. Z perspektywy wymaganych umiejętności i technologii, widać, że potrzebny jest zespół o zróżnicowanych kompetencjach.
Zespół musi rozumieć, jak trenować model, niezależnie od tego, czy jest to model gotowy, czy tworzony od podstaw. Oznacza to, że istotną rolę odgrywa wiedza matematyczna i znajomość algebry, aby zapewnić odpowiednią wiarygodność i wydajność wyników.
Niezbędne są również zaawansowane umiejętności programowania w języku Python lub JavaScript, a także znajomość baz danych i SQL. Po zakończeniu prac nad treścią, potrzebne są kompetencje DevOps, aby włączyć całość do potoku, który umożliwi zautomatyzowane wdrażanie i wykonywanie zadań.
Zdefiniowanie anomalii i wytrenowanie modelu to jedno. Jednak prawdziwym wyzwaniem jest integracja wszystkich tych elementów w jeden sprawnie działający system, który przetwarza wyniki modeli i zapisuje dane w zautomatyzowany i efektywny sposób, aby były one dostępne dla użytkowników końcowych.
Zachęcamy również do zapoznania się z informacjami na temat rozpoznawania twarzy dla firm.
