.
(…) // 44 lines skipped
(…) // 394 lines skipped
Parametry opcjonalne
Pierwszym i najczęściej używanym parametrem opcjonalnym jest z pewnością Renderowanie JavaScript. Jest dostępny we wszystkich płatnych planach. Niektóre strony internetowe wyświetlają istotne elementy za pomocą JavaScript. Oznacza to, że przy początkowym ładowaniu strony niektóre treści mogą być niedostępne, co uniemożliwia ich zeskrobanie. Po włączeniu parametru render_js, API Scrapestack uzyska dostęp do sieci docelowej za pomocą przeglądarki bezgłowej (Google Chrome) i pozwoli na renderowanie elementów strony JavaScript przed dostarczeniem ostatecznego wyniku skrobania. Włączenie tej opcji polega na dodaniu parametru render_js do adresu URL żądania interfejsu API i ustawieniu go na 1.
https://api.scrapestack.com/scrape?access_key=YOUR_ACCESS_KEY&url=https://apple.com&render_js=1
Kolejnym przydatnym parametrem opcjonalnym jest możliwość określenia Lokalizacje proxy, dostępne również we wszystkich płatnych planach. API Scrapestack korzysta z puli ponad 35 milionów adresów IP na całym świecie. Domyślnie automatycznie obraca adresy IP w taki sposób, że ten sam adres IP nigdy nie będzie używany dwa razy z rzędu. Korzystając z opcjonalnego parametru proxy_location, możesz wybrać konkretny kraj, podając jego dwuliterowy kod kraju. Na przykład w poniższym przykładzie podano „au” (Australia) jako lokalizację proxy. Zapytanie zostanie zatem uruchomione z adresu IP z Australii.
https://api.scrapestack.com/scrape?access_key=YOUR_ACCESS_KEY&url=https://apple.com&proxy_location=au
Premium Proxy to kolejna interesująca opcja. Domyślnie API Scrapestack zawsze używa standardowych serwerów proxy (centrum danych) do zgrywania żądań. I chociaż są one najczęściej używanymi serwerami proxy w Internecie, są również znacznie bardziej prawdopodobne, że zostaną zablokowane podczas prób skrobania danych.
Jeśli subskrybujesz abonament profesjonalny lub wyższy, API Scrapestack umożliwia dostęp do serwerów proxy premium (mieszkaniowych). Są one związane z prawdziwymi adresami zamieszkania i dlatego znacznie mniej prawdopodobne jest ich zablokowanie podczas skrobania danych w Internecie. Podobnie jak inne parametry opcjonalne, użycie tej opcji polega jedynie na dodaniu parametru premium_proxy do żądania zgarniania i ustawieniu go na 1.
https://api.scrapestack.com/scrape?access_key=YOUR_ACCESS_KEY&url=https://apple.com&premium_proxy=1
Choć możemy kontynuować przez dłuższy czas, obejmując wiele opcji dostępnych w API Scrapestack, naszym celem jest sprawdzenie produktu, a nie napisanie instrukcji obsługi. Poza tym Kosz na śmieci Witryna ma bardzo dokładną dokumentację i powinna być głównym źródłem informacji na temat tego, jak to zrobić.
Informacje o cenie
API Scrapestack jest dostępne w ramach kilku planów cenowych. Na najniższym poziomie Bezpłatny plan oferuje sposób na zapoznanie się z interfejsem API. Ma podstawową funkcjonalność API i ograniczenie do 10 000 żądań API miesięcznie. Jeśli chcesz uruchomić więcej zapytań lub potrzebujesz bardziej zaawansowanego zestawu funkcji, takich jak współbieżne żądania czy dostęp do proxy premium, możesz wybrać jeden z dostępnych płatnych planów.
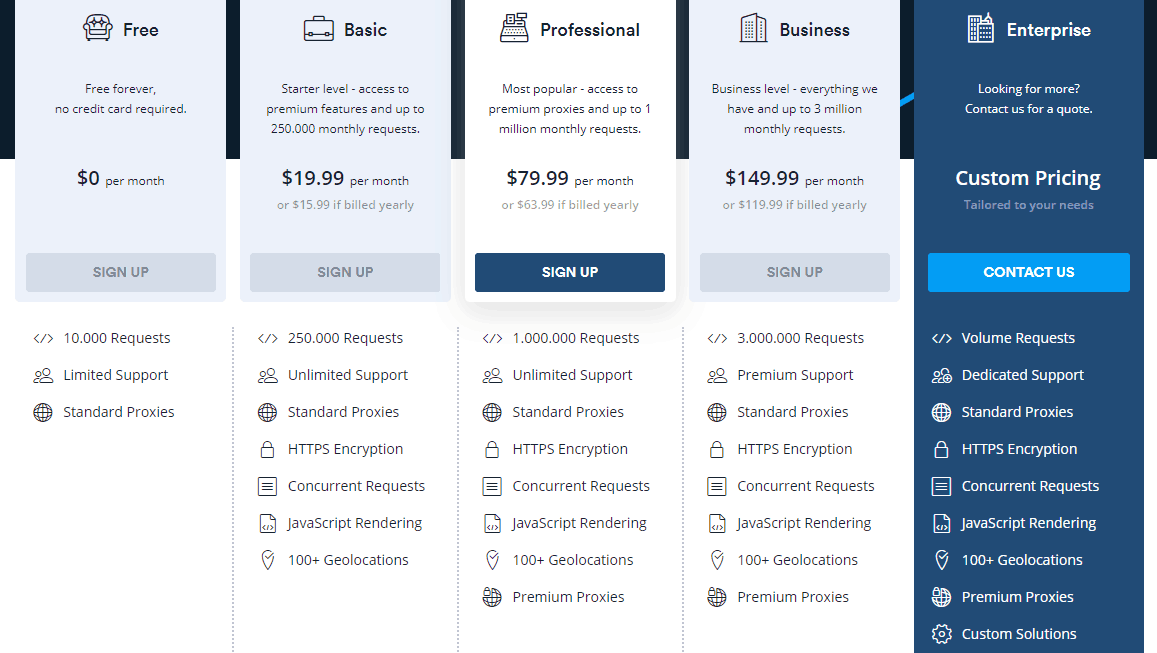
W przypadku większości płatnych planów oferujących podobny zestaw funkcji decydującym czynnikiem, jeśli chodzi o wymagania techniczne, będzie często liczba żądań interfejsu API, które należy składać co miesiąc. Płatności można dokonać kartą kredytową lub PayPal. Klienci korporacyjni i klienci o dużych obrotach mogą poprosić o włączenie rocznych płatności przelewem bankowym. Mówiąc o rocznej płatności, wybranie tej opcji uprawnia cię do 20% rabatu w porównaniu do płatności miesięcznych, dzięki czemu produkt staje się jeszcze bardziej przystępny. Jeśli nie masz pewności co do częstotliwości rozliczeń, pamiętaj, że możesz (względnie) łatwo przełączyć się z miesięcznego na roczny i z powrotem. Obejmuje to jednak najpierw obniżenie abonamentu bezpłatnego i natychmiastowe przejście do abonamentu płatnego.
Dolna linia
Bez względu na to, jak proste lub skomplikowane mogą być twoje potrzeby związane z skrobaniem sieci, API Scrapestack najprawdopodobniej pomoże ci osiągnąć cele w prosty i łatwy sposób. Z imponującą niezawodnością i skalowalnością, ta usługa w chmurze bezbłędnie dostosuje się do prawie każdej sytuacji. Ma wszystkie opcje, których możesz potrzebować, i oferuje środki, by sfałszować twoje próby zgarniania za milionami adresów IP.
Nadal nie jesteś pewien, czy API Scrapestack jest odpowiednie dla ciebie? Dlaczego nie skorzystasz z dostępnego bezpłatnego abonamentu i wypróbujesz usługę w wersji próbnej? Jestem niemal pewien, że zaskoczy cię jego ogólna użyteczność i wydajność.
newsblog.pl
Maciej – redaktor, pasjonat technologii i samozwańczy pogromca błędów w systemie Windows. Zna Linuxa lepiej niż własną lodówkę, a kawa to jego główne źródło zasilania. Pisze, testuje, naprawia – i czasem nawet wyłącza i włącza ponownie. W wolnych chwilach udaje, że odpoczywa, ale i tak kończy z laptopem na kolanach.