Rozpoznawanie podmiotów nazwanych (NER) wyjaśnione w przystępnych terminach
Rozpoznawanie nazwanych jednostek (NER) stanowi doskonałe narzędzie do analizy danych tekstowych, pozwalając na wyodrębnienie konkretnych informacji i przypisanie im odpowiednich kategorii. Dzięki temu, proces zrozumienia zawartości tekstu staje się znacznie bardziej precyzyjny i efektywny.
System NER umożliwia identyfikację i klasyfikację różnorodnych elementów, od nazwisk i dat, po nazwy organizacji i lokalizacji. W ten sposób, otwiera nowe możliwości w analizie języka, pozwalając na głębsze zrozumienie kontekstu wypowiedzi.
Wiele przedsiębiorstw przetwarza ogromne ilości danych, takich jak teksty, informacje osobowe, opinie klientów czy specyfikacje produktów. Dlatego szybkie i efektywne wyszukiwanie w tych zasobach jest niezwykle ważne.
Tradycyjne metody wyszukiwania informacji mogą być czasochłonne, angażować wiele zasobów i generować wysokie koszty. Szczególnie dotkliwe jest to w przypadku bardzo rozległych baz danych.
W celu zapewnienia firmom skutecznego rozwiązania do przeszukiwania i lokalizowania właściwych danych, NER okazuje się być idealnym rozwiązaniem.
W niniejszym artykule szczegółowo omówię zagadnienie NER, włączając w to jego koncepcje matematyczne, różnorodne zastosowania, oraz inne ważne aspekty.
Zacznijmy!
Czym jest rozpoznawanie nazwanych jednostek?
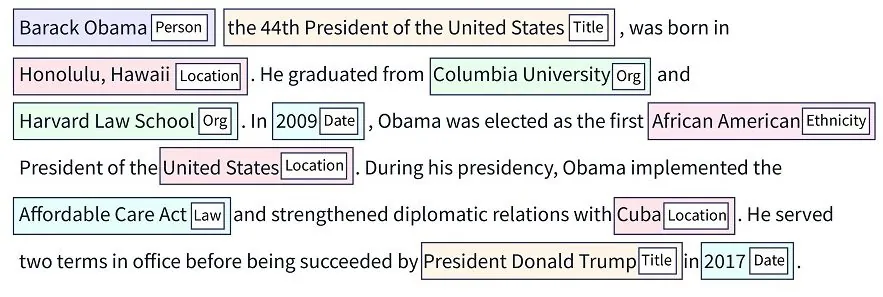
Rozpoznawanie nazwanych jednostek, w skrócie NER, to zaawansowana technika przetwarzania języka naturalnego (NLP). Jej głównym celem jest lokalizacja i kategoryzacja określonych jednostek w tekście, który nie ma ustrukturyzowanej formy.
Jednostki te mogą przyjmować różną postać, włączając w to nazwy firm, miejsc, imiona i nazwiska osób, wartości numeryczne, daty i inne. Dzięki NER, komputery są w stanie wyodrębniać te elementy, co czyni tę technologię cennym narzędziem w wielu dziedzinach, np. w tłumaczeniach, systemach odpowiadania na pytania, czy w różnych gałęziach przemysłu.
 Źródło: Skaler
Źródło: Skaler
NER dąży do zlokalizowania i sklasyfikowania różnych elementów tekstu, które nie są ustrukturyzowane, do wcześniej zdefiniowanych kategorii, takich jak nazwy organizacji, kody medyczne, liczby, imiona, wartości procentowe, waluty, czy określenia czasu.
Dla lepszego zrozumienia, posłużmy się przykładem:
[Jan] nabył nieruchomość od firmy [X Corp.] w roku [2023]. W tym przypadku, wyrażenia w nawiasach kwadratowych to jednostki rozpoznane przez NER. Są one przypisane do następujących kategorii:
- Jan – Imię osoby
- X Corp. – Nazwa organizacji
- 2023 – Określenie czasu
NER jest szeroko wykorzystywane w różnych obszarach sztucznej inteligencji, w tym w uczeniu głębokim, uczeniu maszynowym (ML) i sieciach neuronowych. Stanowi kluczowy element systemów NLP, takich jak narzędzia do analizy sentymentu, wyszukiwarki internetowe i chatboty. Znajduje również zastosowanie w finansach, obsłudze klienta, edukacji, służbie zdrowia, zarządzaniu zasobami ludzkimi i analizie mediów społecznościowych.
W uproszczeniu, NER identyfikuje, kategoryzuje i wydobywa kluczowe informacje z nieustrukturyzowanego tekstu bez konieczności interwencji człowieka. Umożliwia szybkie wyodrębnianie istotnych danych z obszernych zbiorów danych.
Co więcej, NER dostarcza Twojej organizacji niezbędnych informacji na temat produktów, trendów rynkowych, klientów i konkurencji. Na przykład, w placówkach medycznych NER wykorzystuje się do wyodrębniania istotnych danych z dokumentacji pacjentów. Wiele firm korzysta z tej technologii, aby monitorować wzmianki o swojej marce w publikacjach.
Kluczowe koncepcje NER

Zrozumienie podstawowych pojęć związanych z NER jest niezwykle istotne. Przyjrzyjmy się zatem kilku terminom, które warto znać.
- Nazwana jednostka: Dowolne słowo lub fraza odnosząca się do miejsca, organizacji, osoby lub innej rozpoznawalnej encji.
- Korpus: Zbiór różnych tekstów, wykorzystywanych do analizy językowej i trenowania modeli NER.
- Tagowanie POS: Proces przypisywania słowom odpowiedniej kategorii gramatycznej, takiej jak przymiotnik, czasownik czy rzeczownik.
- Dzielenie na fragmenty: Metoda grupowania słów w logiczne frazy na podstawie ich struktury syntaktycznej i części mowy.
- Uczenie i testowanie danych: Proces wykorzystywany do trenowania modelu na oznaczonych danych oraz do oceny jego skuteczności na odrębnym zbiorze danych.
Zastosowanie NER w NLP

NER znajduje szerokie zastosowanie w przetwarzaniu języka naturalnego, włączając w to analizę sentymentu, systemy rekomendacji, odpowiadanie na pytania, ekstrakcję informacji i wiele innych.
- Analiza sentymentu: NER jest wykorzystywane do określania nastroju, jaki wyrażany jest w zdaniu lub akapicie w stosunku do konkretnej jednostki, takiej jak produkt czy usługa. Dane te są wykorzystywane w celu poprawy jakości obsługi klienta i identyfikacji obszarów wymagających udoskonalenia.
- Systemy rekomendacji: NER pomaga w identyfikacji preferencji i zainteresowań użytkowników na podstawie nazwanych jednostek, które występują w ich interakcjach online lub zapytaniach wyszukiwania. Te dane służą do personalizacji rekomendacji, co przekłada się na lepsze doświadczenia użytkowników.
- Odpowiadanie na pytania: NER jest używane do wyodrębniania konkretnych elementów z tekstu, które następnie wykorzystywane są do udzielania odpowiedzi na zapytania. Technika ta jest powszechnie stosowana w wirtualnych asystentach i chatbotach.
- Ekstrakcja informacji: NER umożliwia wyodrębnienie kluczowych informacji z obszernych zbiorów nieustrukturyzowanych danych, takich jak posty w mediach społecznościowych, recenzje internetowe czy artykuły prasowe. Uzyskane w ten sposób dane mogą być wykorzystane do generowania wartościowych wniosków i podejmowania decyzji opartych na faktach.
Koncepcje matematyczne NER
Proces NER opiera się na różnych koncepcjach matematycznych, takich jak uczenie maszynowe, uczenie głębokie, teoria prawdopodobieństwa i wiele innych. Poniżej przedstawiam kilka z nich:
- Ukryte modele Markowa: Ukryte Modele Markowa (HMM) to podejście statystyczne do zadań klasyfikacyjnych sekwencji, takich jak NER. Polega na przedstawieniu sekwencji słów w tekście jako serii stanów, gdzie każdy stan reprezentuje określoną jednostkę. Poprzez analizę prawdopodobieństw, możliwe jest zidentyfikowanie wymienionych jednostek na podstawie tekstu.
- Uczenie głębokie: Techniki uczenia głębokiego, w tym sieci neuronowe, są wykorzystywane w zadaniach NER. Umożliwia to skuteczne i precyzyjne rozpoznawanie i klasyfikowanie nazwanych jednostek.
- Warunkowe pola losowe: Są to modele graficzne wykorzystywane w zadaniach sekwencyjnego tagowania. Umożliwiają warunkowe modelowanie prawdopodobieństwa każdego tagu w sekwencji słów, co pozwala na identyfikację nazwanych jednostek w tekście.
Jak działa NER?
 Źródło: Publikacje ACS
Źródło: Publikacje ACS
Rozpoznawanie nazwanych jednostek (NER) działa na zasadzie wyodrębniania informacji. Jego działanie można podzielić na kilka kluczowych etapów:
#1. Wstępne przetwarzanie tekstu
Pierwszym krokiem w procesie NER jest przygotowanie informacji tekstowych do analizy. Proces ten zazwyczaj obejmuje takie zadania jak tokenizacja, czyli dzielenie tekstu na mniejsze jednostki, zanim NER rozpocznie identyfikację jednostek.
Na przykład, frazę "Bill Gates założył Microsoft" można podzielić na tokeny, takie jak "Bill", "Gates", "założył" i "Microsoft".
#2. Identyfikacja jednostek
Potencjalne nazwane jednostki są identyfikowane przy pomocy metod statystycznych lub reguł językowych. Ten krok obejmuje rozpoznawanie wzorców, takich jak określone formaty (daty) lub wielkie litery w nazwiskach ("Bill Gates"). Po zakończeniu etapu wstępnego przetwarzania, algorytmy NER skanują tekst w poszukiwaniu słów lub sekwencji słów, które odpowiadają jednostkom.
#3. Klasyfikacja jednostek
Po zidentyfikowaniu jednostek, NER przypisuje je do określonych kategorii, klas lub grup. Typowe kategorie to: organizacja, data, lokalizacja, osoba i inne. Proces ten realizowany jest przy pomocy modeli uczenia maszynowego, które są trenowane na oznaczonych danych.
Na przykład, "Bill Gates" zostanie zaklasyfikowany jako "osoba", a "Microsoft" jako "organizacja".
#4. Analiza kontekstowa
NER nie ogranicza się wyłącznie do rozpoznawania i klasyfikowania jednostek. Często uwzględnia kontekst, aby zwiększyć dokładność. Na tym etapie bierze się pod uwagę otoczenie, w którym pojawiają się jednostki, co zapewnia precyzyjniejszą kategoryzację.
Na przykład, w zdaniu "Bill Gates założył firmę Microsoft", kontekst pozwala systemowi rozpoznać, że "Bill" jest imieniem osoby, a nie np. rachunkiem.
#5. Przetwarzanie końcowe
Po wstępnej identyfikacji i kategoryzacji, konieczne jest przetworzenie danych, aby doprecyzować ostateczne wyniki. Obejmuje to rozwiązywanie niejasności, wykorzystywanie baz wiedzy, łączenie jednostek składających się z wielu tokenów i inne działania w celu ulepszenia danych.
Warto podkreślić, że NER potrafi interpretować i analizować nieustrukturyzowane teksty, w których znajdują się cenne dane dla przedsiębiorstw. System ten pozyskuje informacje z artykułów prasowych, stron internetowych, publikacji naukowych, postów w mediach społecznościowych i wielu innych źródeł.
Rozpoznając i kategoryzując nazwane jednostki, NER nadaje dodatkową warstwę znaczenia i struktury w obszarze tekstowym.
Metody NER

Najczęściej stosowane metody to:
#1. Metoda oparta na nadzorowanym uczeniu maszynowym
Metoda ta wykorzystuje modele uczenia maszynowego, które są trenowane na danych tekstowych, gdzie nazwane jednostki zostały wcześniej oznaczone przez ludzi.
W tym podejściu wykorzystuje się algorytmy, w tym maksymalną entropię i warunkowe pola losowe, w celu uzyskania złożonych modeli języka statystycznego. Metoda ta jest skuteczna w rozwiązywaniu problemów ze zrozumieniem znaczeń językowych i innych zawiłości, ale wymaga dużej ilości danych treningowych.
#2. Systemy oparte na regułach
Metoda ta opiera się na różnorodnych regułach gromadzenia informacji, np. na tytulaturze lub wielkich literach. W tym podejściu, konieczna jest duża interwencja człowieka w celu wprowadzania, monitorowania i modyfikacji zasad. Może to powodować pominięcie niuansów tekstowych, które nie są ujęte w adnotacjach treningowych. Dlatego systemy oparte na regułach mogą mieć trudności ze złożonością i nie dorównują modelom uczenia maszynowego.
#3. Systemy oparte na słownikach
W tej metodzie, do identyfikacji nazwanych jednostek wykorzystywany jest słownik zawierający dużą liczbę synonimów i zbiór terminologii. Metoda ta napotyka problemy w kategoryzowaniu nazwanych jednostek, które wykazują różnice w pisowni.
Istnieje również wiele innych, nowo powstających metod NER. Przyjrzyjmy się im również:
#4. Nienadzorowane systemy uczenia maszynowego
Te systemy ML korzystają z modeli, które nie są wcześniej trenowane na danych tekstowych. Modele uczenia bez nadzoru radzą sobie z bardziej złożonymi zadaniami niż modele nadzorowane.
#5. Systemy ładowania początkowego
Systemy ładowania początkowego, znane również jako systemy samonadzorowane, klasyfikują nazwane jednostki w oparciu o cechy gramatyczne, takie jak części mowy, wielkość liter oraz inne wcześniej wyuczone kategorie.
Następnie, człowiek modyfikuje system, oznaczając przewidywania jako poprawne lub niepoprawne i dodając właściwe informacje do nowego zbioru treningowego.
#6. Systemy sieci neuronowych
System ten tworzy model rozpoznawania nazwanych jednostek przy wykorzystaniu architektury dwukierunkowych modeli uczenia (dwukierunkowe reprezentacje koderów z transformatorów), sieci neuronowych i technik kodowania. Metoda ta minimalizuje potrzebę interakcji z ludźmi.
#7. Systemy statystyczne
Metoda ta korzysta z modeli probabilistycznych, które uczą się relacji i wzorców w tekście, co pozwala na przewidywanie nazwanych jednostek na podstawie nowych danych tekstowych.
#8. Semantyczne systemy etykietowania ról
System ten wstępnie przetwarza model rozpoznawania nazwanych jednostek z wykorzystaniem technik semantycznych, które uczą się relacji między kategoriami a kontekstem.
#9. Systemy hybrydowe
Ta interesująca metoda łączy elementy kilku różnych podejść.
Korzyści płynące z NER
Modele NER oferują szereg korzyści:
- Automatyzują proces wyodrębniania danych, szczególnie w przypadku dużych zbiorów danych.
- Mogą być stosowane w każdej branży do pozyskiwania kluczowych informacji z nieustrukturyzowanego tekstu.
- Oszczędzają czas i zasoby pracowników podczas wykonywania zadań wyodrębniania danych.
- Podnoszą dokładność procesów i zadań NLP.
- Zapewniają bezpieczeństwo danych, umożliwiając hostowanie niestandardowych modeli NER, co eliminuje konieczność udostępniania poufnych informacji zewnętrznym podmiotom.
- Umożliwiają obsługę nowych typów jednostek i terminologii, w miarę rozwoju danej dziedziny.
Wyzwania NER
- Dwuznaczność: Wiele słów w tekście może być mylących. Na przykład, słowo "Amazonka" może odnosić się do firmy, rzeki lub lasu. Rozróżnienie poprawnego znaczenia jest możliwe na podstawie kontekstu, co czyni proces rozpoznawania jednostek trudniejszym.
- Zależność od kontekstu: Znaczenie słów może zależeć od otaczającego kontekstu. Na przykład, "Apple" w kontekście technologicznym odnosi się do firmy, a w kontekście spożywczym do owocu. Rozpoznanie dokładnej jednostki nie jest zawsze oczywiste.
- Rzadkość danych: Metody NER, oparte na uczeniu maszynowym, wymagają dużej dostępności oznaczonych danych, które mogą być trudno dostępne, zwłaszcza w przypadku specjalistycznych domen lub mniej popularnych języków.
- Różnice językowe: Ludzkie języki różnią się w zależności od dialektów, regionów i slangu. Wyodrębnianie tekstu w obcym języku może być trudnym wyzwaniem.
- Generalizacja modelu: Modele NER mogą znakomicie klasyfikować jednostki w jednej dziedzinie, ale mogą mylić się w uogólnianiu do innej dziedziny. Modele NER mogą działać inaczej w zależności od domeny.
Aby sprostać tym wyzwaniom, konieczne jest połączenie zaawansowanych algorytmów, wiedzy językowej i wysokiej jakości danych. W miarę rozwoju technologii NER, zespoły badawczo-rozwojowe muszą udoskonalać różne techniki, aby sprostać tym wyzwaniom.
Przykłady zastosowań NER
#1. Kategoryzacja treści

Wydawnictwa i portale informacyjne generują ogromne ilości treści online. Efektywne zarządzanie tymi zasobami jest niezwykle ważne, aby w pełni wykorzystać potencjał każdego artykułu lub newsa.
Funkcja rozpoznawania nazw automatycznie skanuje całą zawartość i wyodrębnia istotne dane, takie jak nazwy organizacji, lokalizacje i nazwiska osób. Znajomość niezbędnych tagów dla każdego artykułu ułatwia kategoryzację treści w uporządkowanej hierarchii, co usprawnia jej dystrybucję.
#2. Algorytmy wyszukiwania
Załóżmy, że masz wewnętrzny algorytm wyszukiwania dla swojej witryny, która zawiera miliony artykułów. Przy każdym zapytaniu, algorytm ten zbiera wszystkie słowa z tych artykułów, co jest procesem czasochłonnym.
Jeśli natomiast zastosujesz NER, system ten z łatwością pobierze i zapisze osobno niezbędne elementy z wszystkich artykułów, co znacznie przyspieszy proces wyszukiwania.
#3. Rekomendacje treści
Automatyzacja procesu rekomendacji jest kluczowym przypadkiem zastosowania NER. Systemy rekomendacji pomagają w odkrywaniu nowych treści i pomysłów.
Najlepszym przykładem jest Netflix. Dowodzi to, że zbudowanie skutecznego systemu rekomendacji może znacząco zwiększyć zaangażowanie użytkowników.
W przypadku wydawców wiadomości, NER skutecznie poleca podobne artykuły. Można to zrobić, zbierając tagi z danego artykułu i proponując inne treści, które zawierają podobne elementy.
#4. Obsługa klienta

Obsługa klienta jest priorytetem dla każdej organizacji. Istnieje wiele sposobów na usprawnienie tego procesu. NER jest jednym z nich. Posłużmy się przykładem.
Załóżmy, że klient przekazuje opinię: "Personel w sklepie Adidas w San Diego jest niedoinformowany na temat obuwia sportowego". W tym przypadku NER wyodrębnia tagi "San Diego" (lokalizacja) i "obuwie sportowe" (produkt).
NER jest wykorzystywany do klasyfikowania skarg i kierowania ich do odpowiedniego działu w organizacji w celu rozwiązania problemu. Można stworzyć bazę danych opinii podzielonych na różne działy i analizować każdą z nich.
#5. Artykuły naukowe
Witryny internetowe publikujące czasopisma lub artykuły naukowe zawierają wiele prac badawczych. Można tam znaleźć setki artykułów o podobnej tematyce, ale z niewielkimi modyfikacjami. Uporządkowanie tych danych w sposób zorganizowany może być skomplikowanym zadaniem.
Aby uprościć ten proces, można posegregować dokumenty na podstawie odpowiednich tagów.
Istnieją tysiące publikacji na temat uczenia maszynowego. Aby odnaleźć artykuł, który wspomina o użyciu splotowych sieci neuronowych (CNN), należy nadać jednostkom odpowiednie znaczniki. Pomoże to szybko znaleźć artykuł, który spełnia wymagania.
Podsumowanie
Rozpoznawanie nazwanych jednostek (NER), jako technika NLP, pozwala na identyfikację określonych jednostek w nieustrukturyzowanym tekście i klasyfikację ich do zdefiniowanych kategorii, takich jak lokalizacje, imiona osób, produkty i inne.
Głównym celem NER jest przekształcenie nieustrukturyzowanych informacji w uporządkowaną formę, która jest łatwa do odczytania i analizy. Technologia ta opiera się na różnorodnych modelach i procesach, przynosząc liczne korzyści dla profesjonalistów i firm. NER znajduje również zastosowanie w wielu obszarach poza NLP.
Mam nadzieję, że powyższe wyjaśnienia dotyczące tej techniki pomogą Ci w jej wdrożeniu w Twojej firmie i umożliwią Ci terminowe uzyskiwanie wartościowych informacji.
Zachęcam również do zapoznania się z najlepszymi kursami NLP, aby zgłębić wiedzę na temat przetwarzania języka naturalnego.
